
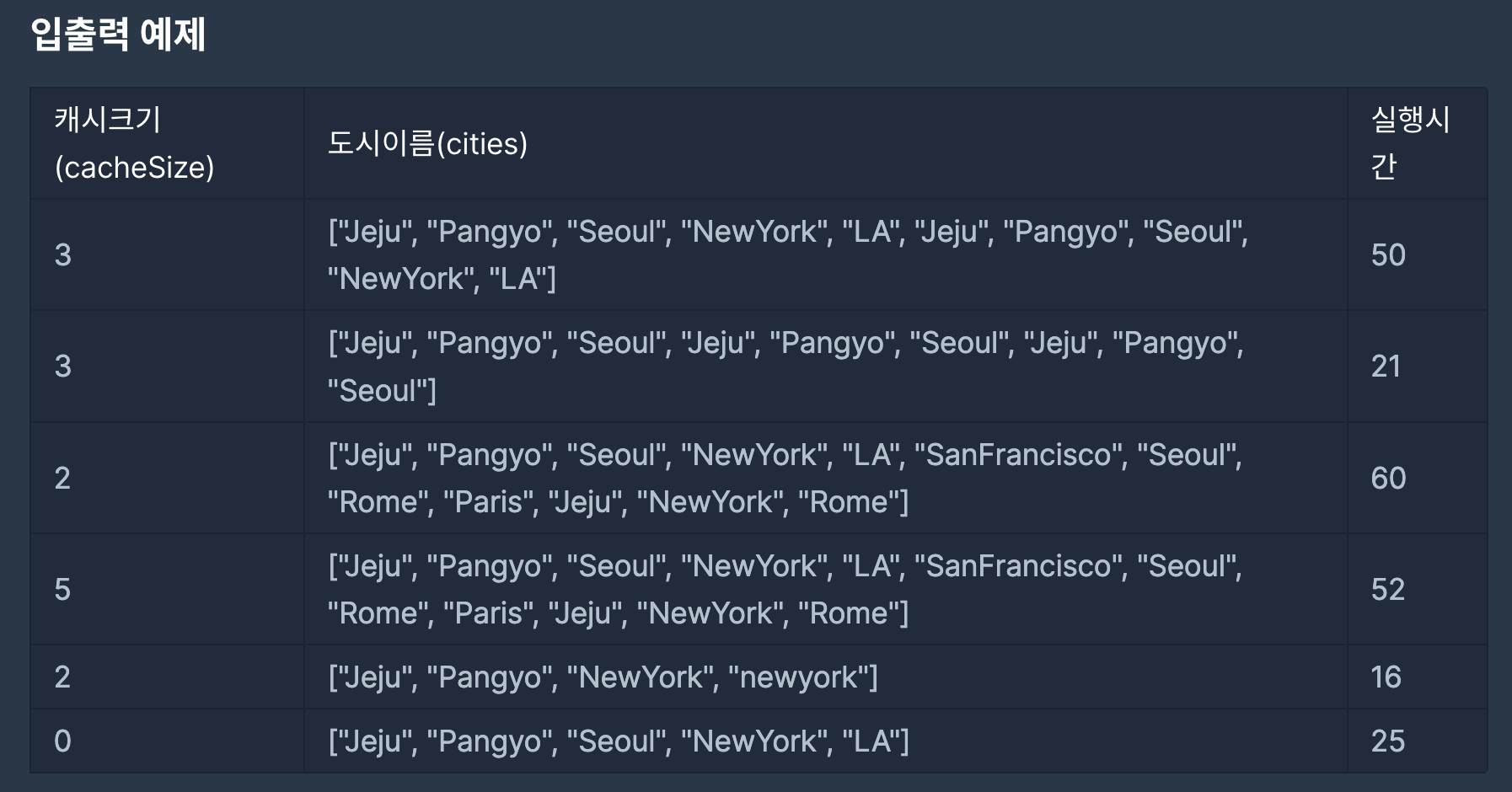
처음 보는 문제였다. 캐시는 컴퓨터구조 시간에 배웠었고 LRU 방식에 대해서도 한번 배운 기억이 났다.
LRU는 (Least Recently Used) 라는 뜻인데, 이 알고리즘은 캐시 메모리의 용량이 제한되어 있고 새로운 데이터가 캐시에 적재될 때 기존 데이터 중 어떤 것을 교체할지 결정하는 데 사용된다.
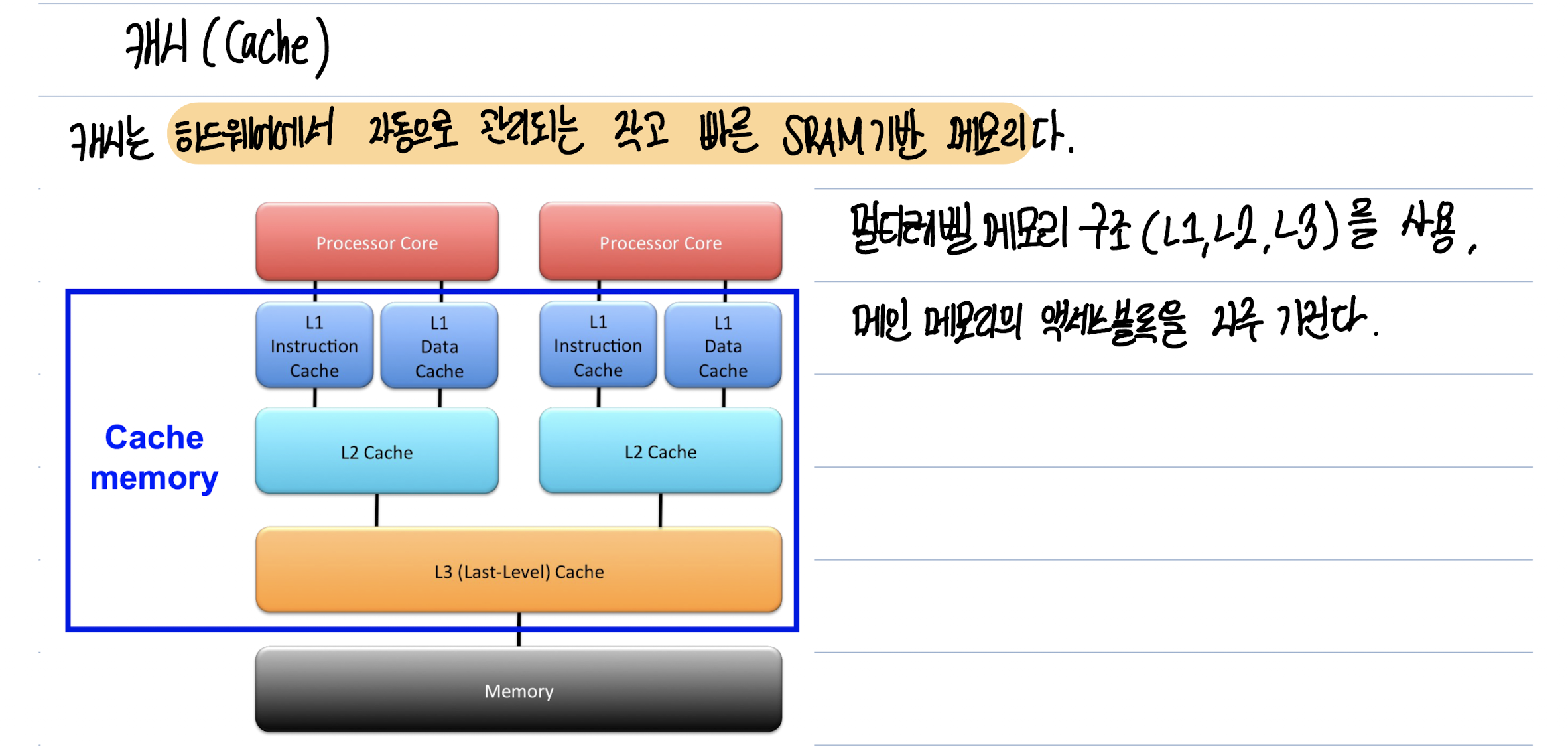
아래의 사진들은 3학년1학기 컴퓨터구조 강의를 듣고 필기 한 내용이다.


#include <string>
#include <vector>
#include <unordered_map>
#include <list>
#include <boost/algorithm/string.hpp>
using namespace std;
class LRUcache
{
public:
LRUcache(int cacheSize)
{
maxSize = cacheSize;
}
int get(string city)
{
auto it = cache.find(city);
if (it != cache.end()) // 캐시에 있다면 갱신 후 1 리턴
{
update(it->second);
return 1;
}
else // 캐시에 없다면, 추가 후 5 리턴
{
if (data.size() >= maxSize) // 캐시가 가득 찼을 때는 가장 오래된 데이터 삭제
{
cache.erase(data.back());
data.pop_back();
}
data.push_front(city); // 추가
cache[city] = data.begin();
return 5;
}
}
private:
int maxSize;
list<string> data;
unordered_map<string, list<string>::iterator> cache;
void update(list<string>::iterator it)
{
data.splice(data.begin(), data, it);
}
};
int solution(int cacheSize, vector<string> cities) {
int answer = 0;
LRUcache cache(cacheSize);
if (!cacheSize) // 캐시의 Size가 0일 수 있으므로 예외처리
return cities.size() * 5;
for (int i = 0; i < cities.size(); i++)
{
boost::algorithm::to_lower(cities[i]);
answer += cache.get(cities[i]);
}
return answer;
}만약 캐시에 데이터를 찾을 때, 만약 캐시에 존재하지 않다면 Cache Miss이므로 5를 리턴해 answer에 더하고,
캐시에 존재한다면 가장 오랫동안 사용되지 않는 데이터를 삭제한 뒤 캐시의 맨 앞에 새로운 데이터를 적재해준다.
cache.get으로 문자열을 넘겨주면, class에서 구현한 방식대로 it이라는 변수에 위치를 찾아주고, 만약 캐시에 해당 자료가 있다면 update함수로 위치를 맨 앞으로 갱신해준다. 그리고 1을 Return하여 Cache Hit를 알려준다.
그리고 만약 반복자가 == cache.end(), 즉 해당 자료가 없다면, Cache Miss 절차를 밟는다. 캐시의 크기가 OverFlow된다면 LRU 알고리즘의 방식대로 가장 오랫동안 사용되지 않은 데이터(맨 뒤)를 삭제하고, 그 다음엔 다시 캐시의 맨 앞에 들어온 데이터를 넣어준다. 그리고 Cache Miss를 알리는 5를 Return한다.
캐시 개념을 사용하는 문제는 처음이였는데 다시 한번 캐시 메모리의 개념을 상기시켜주는 좋은 문제였다고 생각한다.

·ᴗ·