Cpp_Algorithm
1.프로그래머스/lv2/131701. 연속 부분 수열 합의 개수

길이가 n 까지인 연속 부분 수열까지 구해야 하기 때문에 외부 루프엔 vector의 크기만큼 반복하였고, 내부 루프엔 길이가 n인 연속 부분 수열의 모든 경우의 수를 찾기 위해 vector의 크기만큼 반복한다. 중복되지 않게 값을 저장하기 위해 메모 할 m이라는 배
2.프로그래머스/lv2/131127. 할인 행사

처음 보자 마자 든 생각은 std::Map을 사용해서 물건과 물건 개수를 쌍으로 넣은 뒤 루프를 돌며 mapdiscount에 해당하는 Value를 하나씩 내리고 모든 Value가 0이라면 cnt를 하나씩 올려서 return할 생각이였는데,map에 익숙치 않아서 Vect
3.프로그래머스/lv2/17680. [1차]캐시 2018 KAKAO BLIND RECRUITMENT

처음 보는 문제였다. 캐시는 컴퓨터구조 시간에 배웠었고 LRU 방식에 대해서도 한번 배운 기억이 났다. LRU는 (Least Recently Used) 라는 뜻인데, 이 알고리즘은 캐시 메모리의 용량이 제한되어 있고 새로운 데이터가 캐시에 적재될 때 기존 데이터 중 어
4.프로그래머스/lv2/42578. 의상

복잡하게 하지 않고 쉽게 푸는 방법이 무엇이 있을까 고민하다가, 이산수학을 배울 때 쓰던 조합 공식을 써야하는 줄 알았는데,머리를 싸매다가 찾아보니 간단한 공식이 있었다.옷들의 조합을 구하는 공식은 확률론 및 조합론의 기본 원리에 따른 것이다. 이 공식은 "별개의 사건
5.프로그래머스/lv2/42587. 프로세스

location의 프로세스가 몇번째로 실행되는지 찾는 문제였는데, 인덱스가 유동적으로 움직이기 때문에 내가 찾는 원소의 인덱스가 뭔지 기억하고 있는다고 될 문제가 아니였다. 그래서 내가 찾는 원소가 맞는지 확인할 수 있도록 Vector에 pair형
6.프로그래머스/lv2/17677.[1차]뉴스 클러스터링 2018 KAKAO BLIND RECRUITMENT

2개의 문자열을 대소문자 구분이 없으니 소문자로 바꿔준 다음, 문자열을 2칸씩 자르고, 2칸이 모두 알파벳이라면 각각 중복이 허용되는 multiset인 set1, set2에 넣어준다.그 다음 두 set의 교집합을 구하는 set_intersection함수와 합
7.프로그래머스/lv1/161989. 덧칠하기

인덱스가 1부터 시작하니 n+1 크기의 동적배열 wall을 생성하고, wall에 모든 원소를 0으로 초기화 했다.그 다음 반복문을 돌면서 section에 나타난 페인트가 벗겨진 곳을 1로 설정하고,마지막 반복문을 돌면서 만약 빈 곳이 있다면 내부루프로 벽
8.프로그래머스/lv2/138476. 귤 고르기

귤의 종류(크기)를 담을 배열 arr을 선언하고 그곳에 tangerine배열의 원소값 인덱스를 올려준다.그리고 오름차순으로 정렬 한 후, 반복문을 돌며 answer의 크기가 k를 넘어선다면 인덱스 + i 를 return해준다.크기가 작은 값부터 더하며, 그 값이 k를
9.프로그래머스/lv1/140108. 문자열 나누기
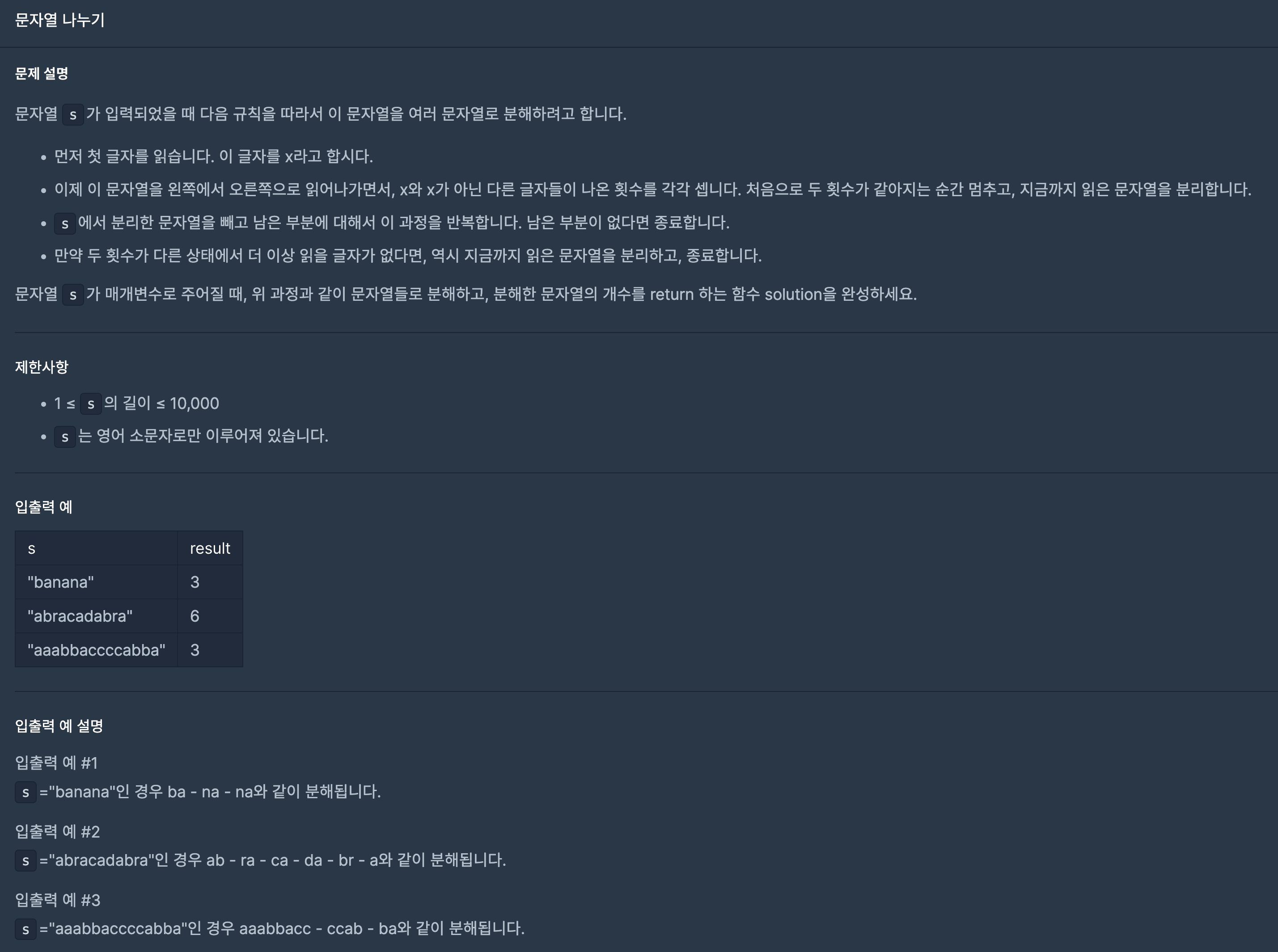
문제 그대로 첫 글자 x를 두고, 인덱스가 x라면 fir++, 아니라면 sec++로 증가하면서 처음으로 두 횟수가 같아지면 문자열을 잘라주고, 인덱스와 문자 개수를 세는 변수들을 0으로 초기화 해준 뒤 continue로 빠져나간다. 만약 s의 길이가 1 이하라면 문자열
10.프로그래머스/lv1/133499. 옹알이(2)
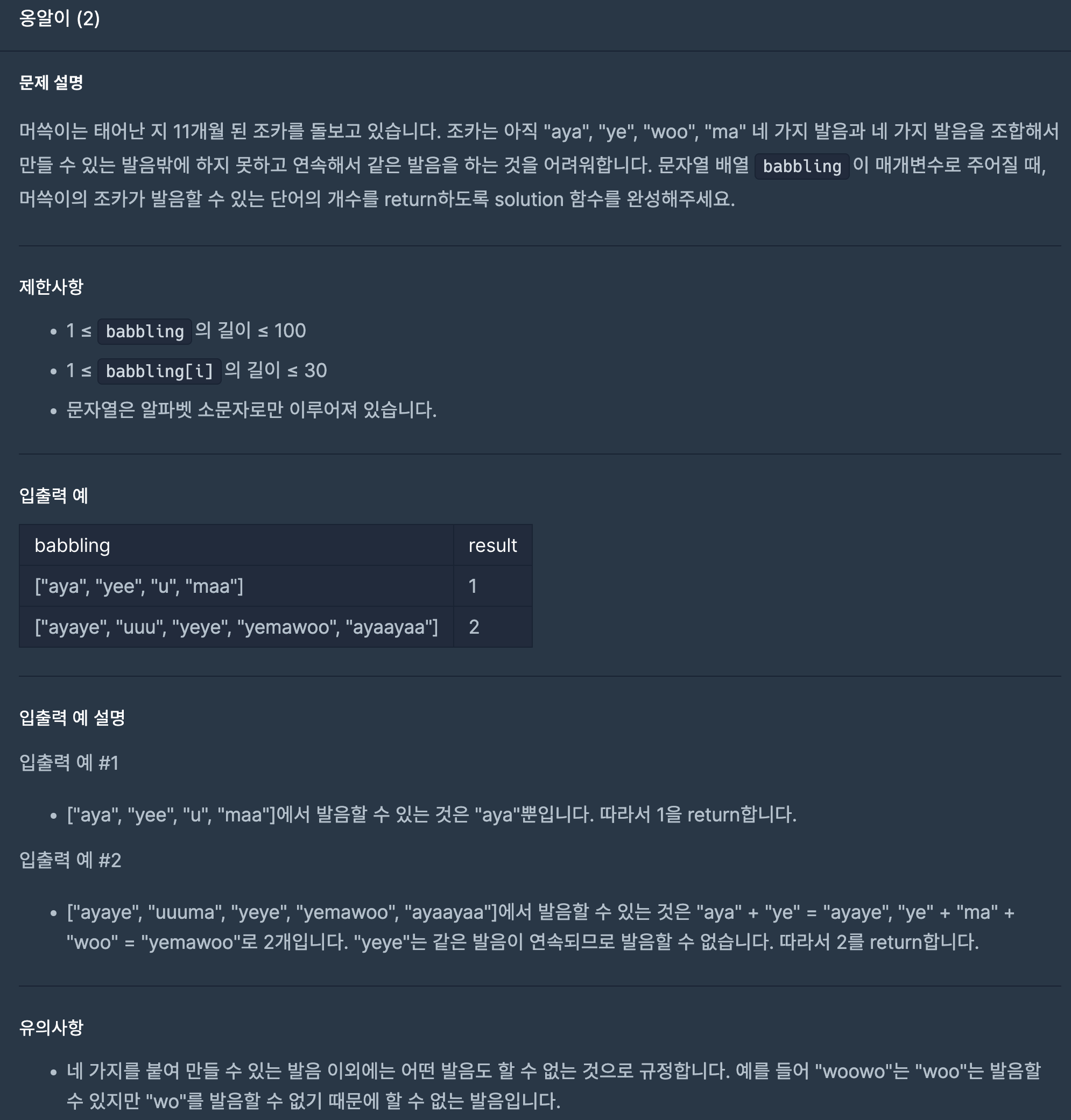
파라미터로 받은 vector의 크기만큼 for문을 돌고 가능한 발음을 찾기위해 v에 있는 가능한 모든 발음을 찾아서 지워준다. 옹알이 (1) 에서는 발음을 한번씩 조합해서 가능한 것을 찾는 문제였는데, 옹알이 (2)에서는 발음을 여러번 조합하되, 연속 발음이 가능하지
11.프로그래머스/lv1/160586. 대충 만든 자판
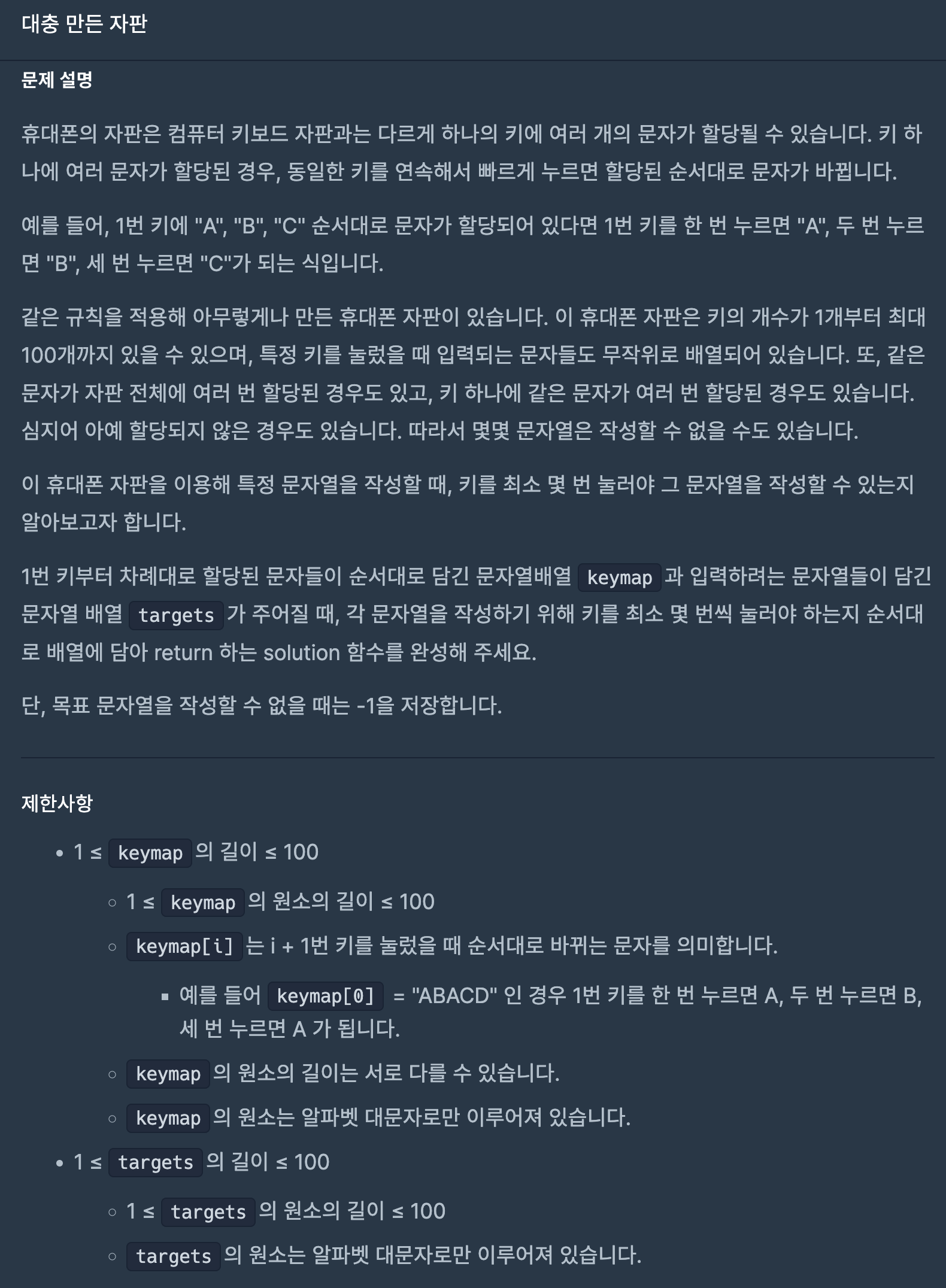
targets의 크기만큼 반복, 내부 루프에서는 temp에 targets의 원소를 하나씩 담으면서 temp의 각각의 알파벳을 k루프에서 찾는다. find함수에서 npos가 아니라면 그 인덱스를 Vector에 넣어주고, 만약 찾지 못한다면 check를 한개씩 올려준다.왜
12.프로그래머스/lv1/155652. 둘만의 암호
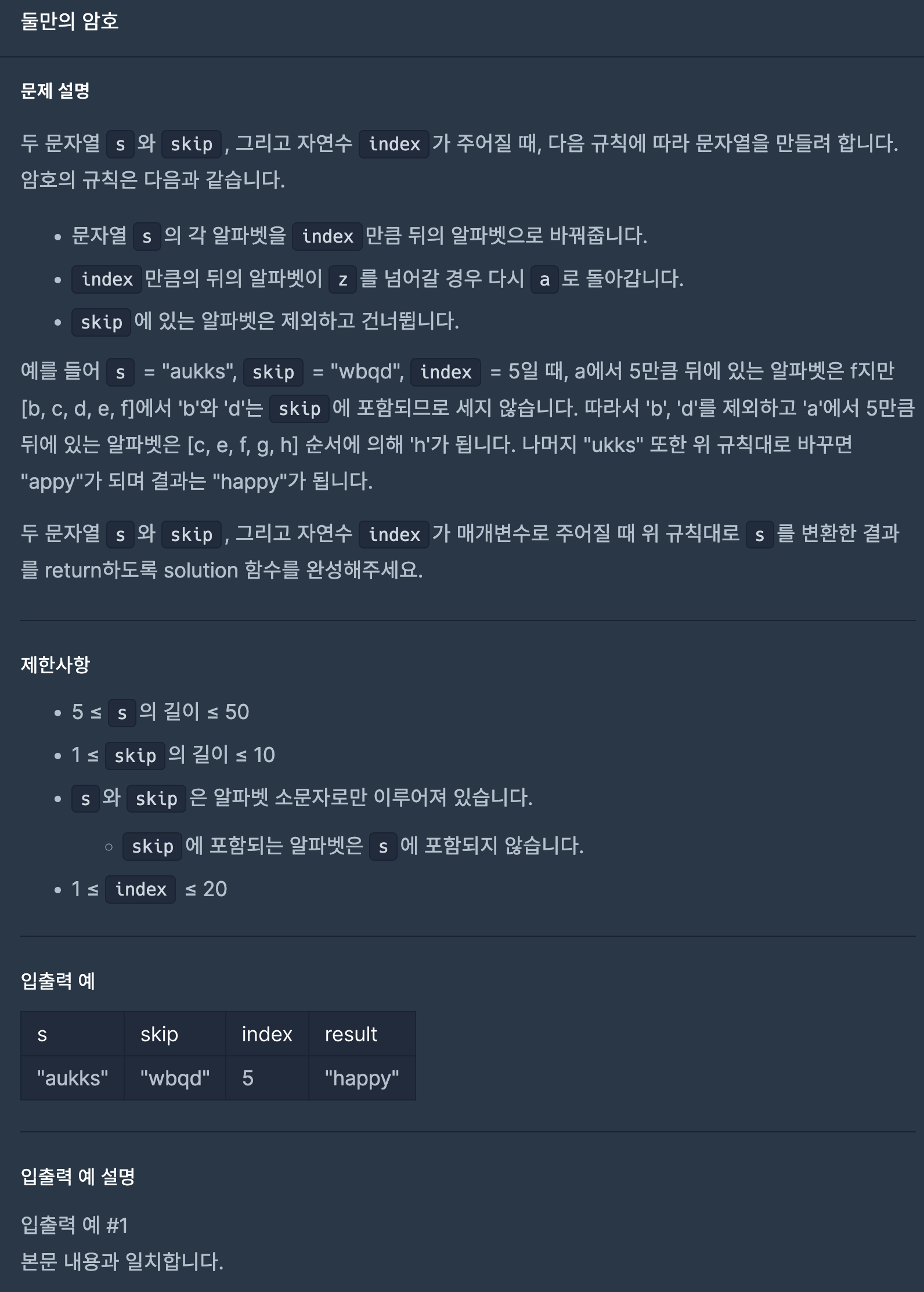
단순하게 s의 인덱스만큼 for문을 돌며 temp에 s의 인덱스를 할당해주고, 건너 뛸 때 사용할 while 루프의 조건에 들어갈 k를 index만큼 할당해준다.while문을 돌면서 temp를 증가시키고, 아스키코드 122를 넘는다면 97로 바꿔주며 lotate해주고,
13.프로그래머스/lv1/133502. 햄버거 만들기

빵 야채 고기 빵 -> 1 2 3 1 패턴이므로 v를 문자열로 전환해서 풀면 좋겠다고 생각했다.문자열로 전환한 후에 while루프를 돌며 1231을 찾고, 찾았다면 answer를 올린 뒤 찾은 위치부터 4개를 삭제하는 방식으로 하면 쉽게 풀리는 문제였지만, 맨 처음엔
14.프로그래머스/lv1/161990. 바탕화면 정리

간단히 좌표상의 조건으로 답을 구할 수 있다.x축의 가장 작은 값, y축의 가장 작은 값 그리고 x축의 가장 큰 값, y축의 가장 큰 값을 구해야한다.가장 작은 윗면 좌표 -> 0,1가장 작은 왼쪽면 좌표 -> 1,0가장 큰 오른쪽면 좌표 -> 2,8가장 큰 아랫면
15.프로그래머스/lv1/150370. 개인정보 수집 유효기간 2023 KAKAO BLIND RECRUITMENT

처음에 든 생각은 class를 만들어서 만료일까지 계산하여 인스턴스 멤버로 저장하려고 했는데, 그렇게 코딩을 하던 와중에 갑자기 든 생각이 있었다.만약 그렇게 코딩을 한다면 반복문도 많이 돌 것이고, 직접 날짜를 더하고 빼는 과정에서 내림 올림 연산이 많아지기에 번거로
16.프로그래머스/lv1/178871. 달리기 경주
선수 이름이 호명 된다면 그 선수가 앞 선수를 추월 한 것이므로, 그 둘을 swap하면서 최종적인 결과를 return하는 문제다. 현재 등수와 선수의 달리기 상황을 나타내는 p와 차례로 호명되는 리스트를 나타내는 c가 입력으로 주어진다. 단순히 호명되는 선수의 인덱스를
17.프로그래머스/lv1/172928. 공원 산책
나동빈님의 알고리즘 유튜브에서 구조체 배열을 이용한 좌표값을 구해 체스 문제를 푸는 방법을 다시 기억해내서 풀어보았다. 미로 좌표 문제는 몇 문제 풀어 본 적이 없어서 이리저리 찾아보며 하느라 조금 오래 걸리긴 했는데 아주 오랜만에 좌표를 이용한 문제를 다시 상기시키는
18.백준/Silver/1003. 피보나치 함수
일반적 재귀로 풀면 시간초과가 발생해서 dp memoization 방식으로 다시 풀었다.단순히 피보나치의 특성 상 n이라는 숫자에 0과 1을 출력하는 횟수는 fibo(n-1) , fibo(n)과 같기에 피보나치를 dp로 바꾸고, print에서 n-1, n 2개를 이용해
19.프로그래머스/lv2/87946. 피로도
완전탐색 (Brute Force )문제였다. 던전 사이즈의 제약조건이 1부터 8밖에 되지 않기에 next_permutation() 을 사용해 모든 경우의 수를 체크하면 되는 문제였다.index를 저장할 idx를 만들어주고, do while문을 돌면서 perm
20.프로그래머스/lv3/42628. 이중우선순위큐
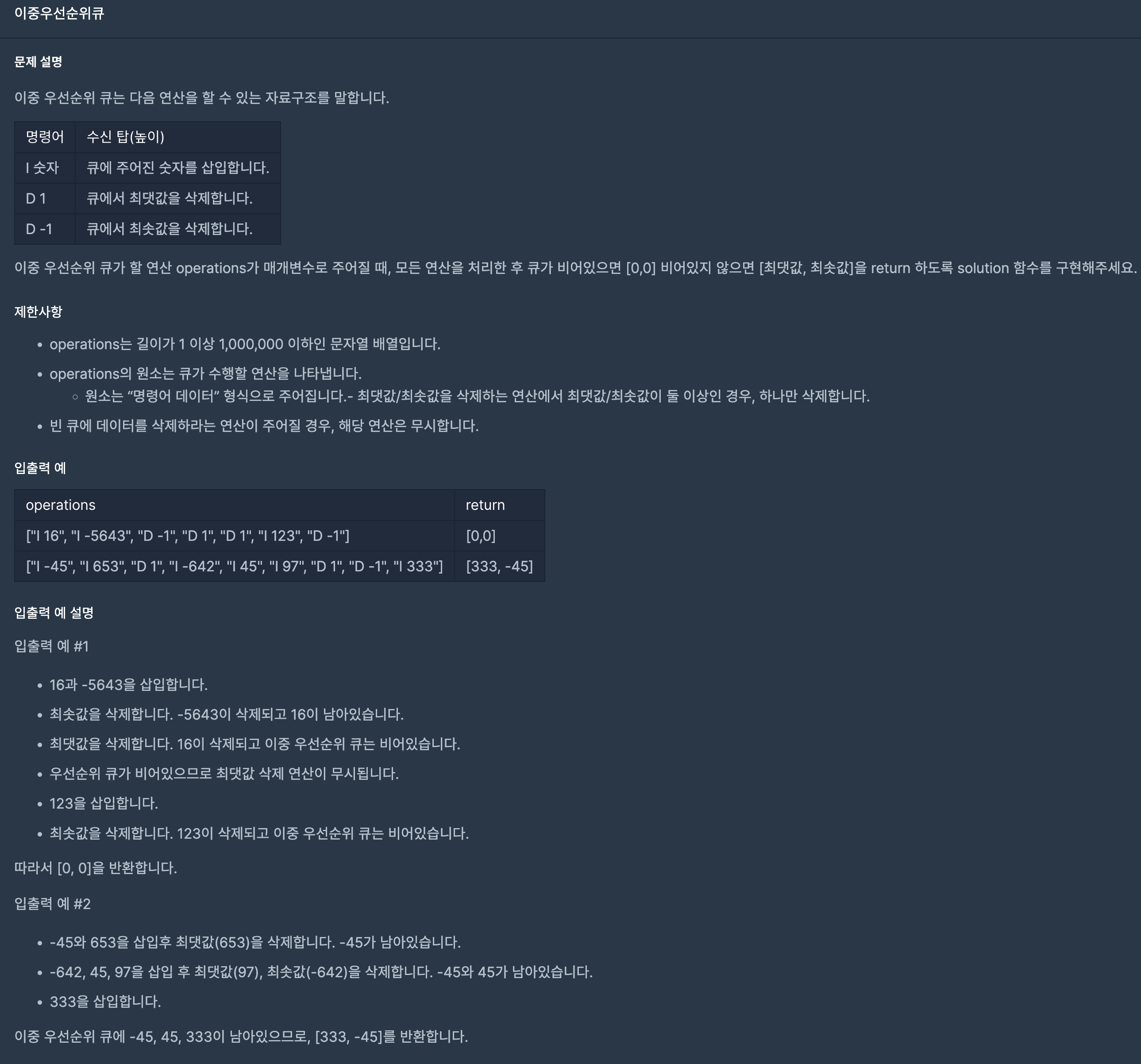
vector나 multiset을 활용해서 풀어도 됐을 것 같은데 문제 분류가 Heap이라 2개의 Priority Queue로 풀었다. MaxHeap, MinHeap인 2개의 우선순위 큐를 만들고 'I' 명령어가 들어온다면 모든 Heap에 push한다.그리고 최솟값을 삭
21.프로그래머스/lv3/43105. 정수 삼각형

삼각형을 2차원 배열 관점으로 본다면 아래와 같은 모양이 된다. 규칙 상 삼각형의 맨 위에서 아래로 내려갈 때는 왼쪽 대각선과 오른쪽 대각선 아래로 내려갈 수 있다고 했다.이 규칙의 뜻은 2차원 배열의 관점으로 봤을 때 현재
22.프로그래머스/lv2/17684.[3차]압축 2018 KAKAO BLIND RECRUITMENT
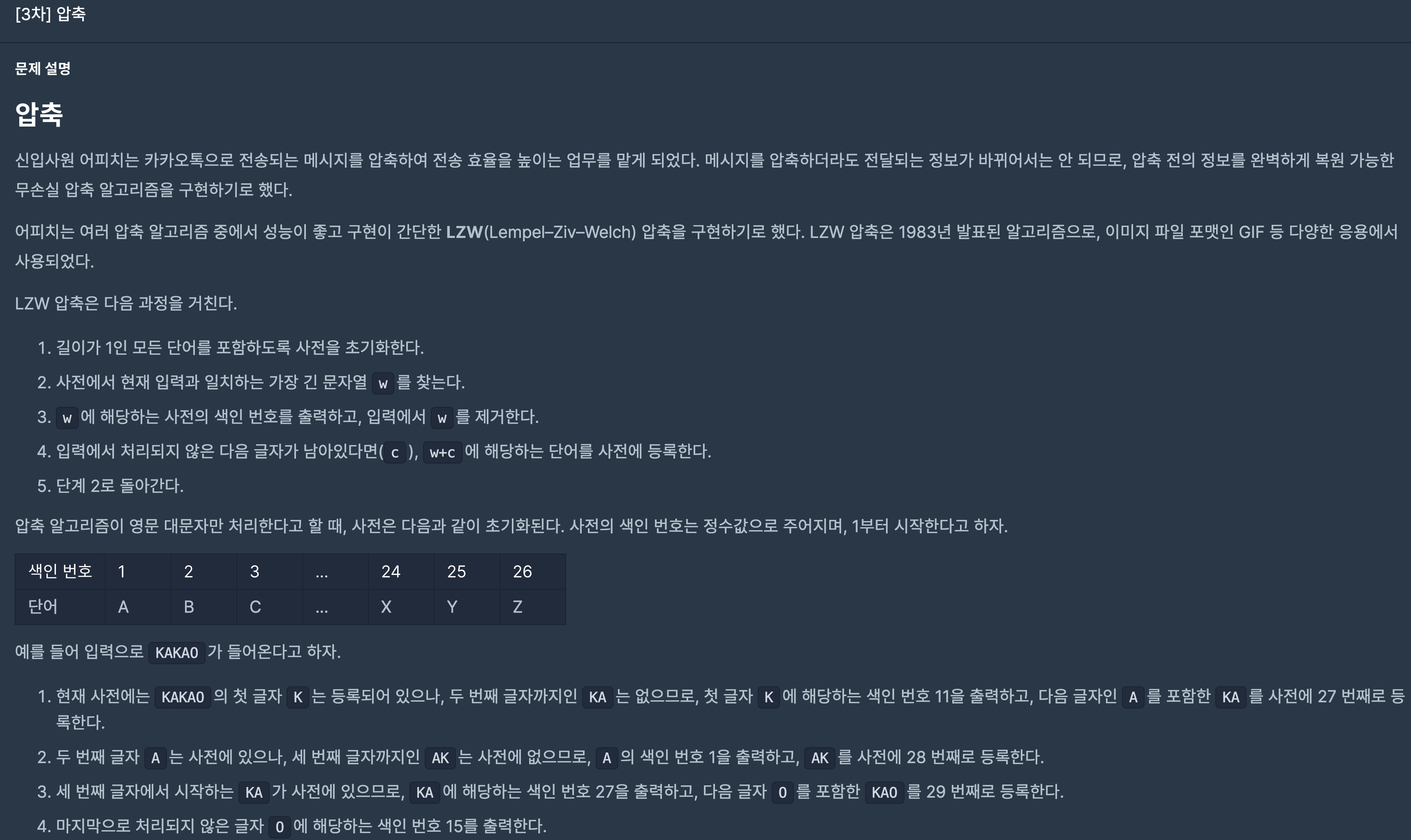
간단히 map에 기본적인 한자리 알파벳을 정의하고, 한개씩 읽어들이면서 temp에 넣어준다.매 횟수마다 map을 체크하여 value값이 있다면 넘어간다.그러나 value가 없는 문자열 key temp일 때, 그 값은 만들어서 넣어주어야 하는 문자열이기 때문에 answe
23.프로그래머스/lv3/43162. 네트워크

UnionFind 알고리즘을 이용하여 모든 노드를 Union시키고Parent의 숫자 개수를 찾으면 되는 문제다.UnionFind알고리즘은 자신의 인덱스가 어떤 숫자와 연결되어 있다면, 더 숫자가 작은 노드를 가리킨다. 그 수는 더 작은 노드의 번호다. 만약 예제 2번과
24.프로그래머스/lv2/42577. 전화번호 목록
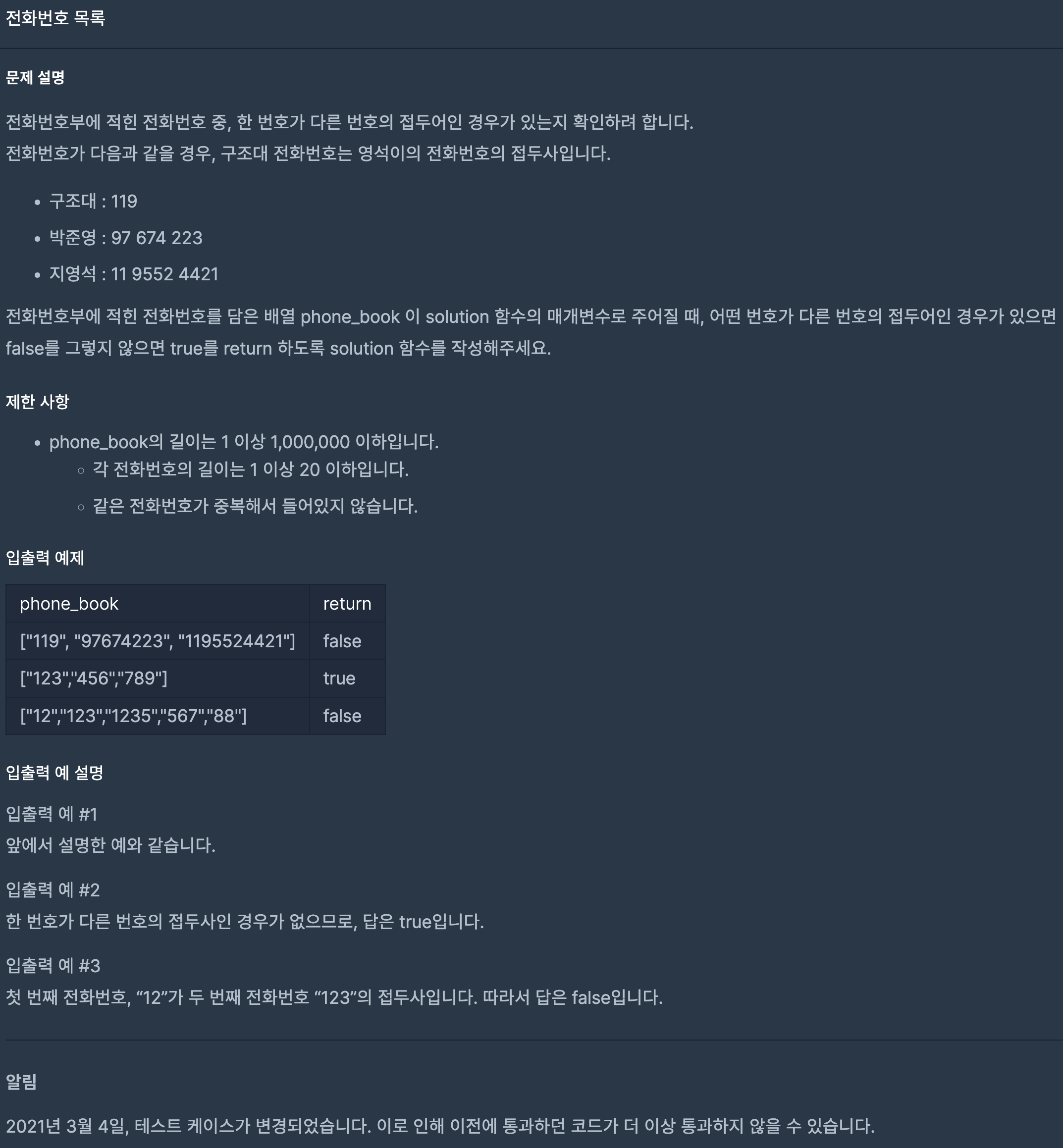
배열을 Lexicographic order(사전식 순서)로 정렬하게 된다면, 굳이 해시를 사용하지 않아도 이 문제를 해결할 수 있다. 사전식 순으로 정렬한다면 바로 옆끼리 비교를 해서 접두사가 있는 지 알 수 있기 때문에 sort로 정렬을 하면 길이가 짧은 순으로 오름
25.프로그래머스/lv2/42626. 더 맵게
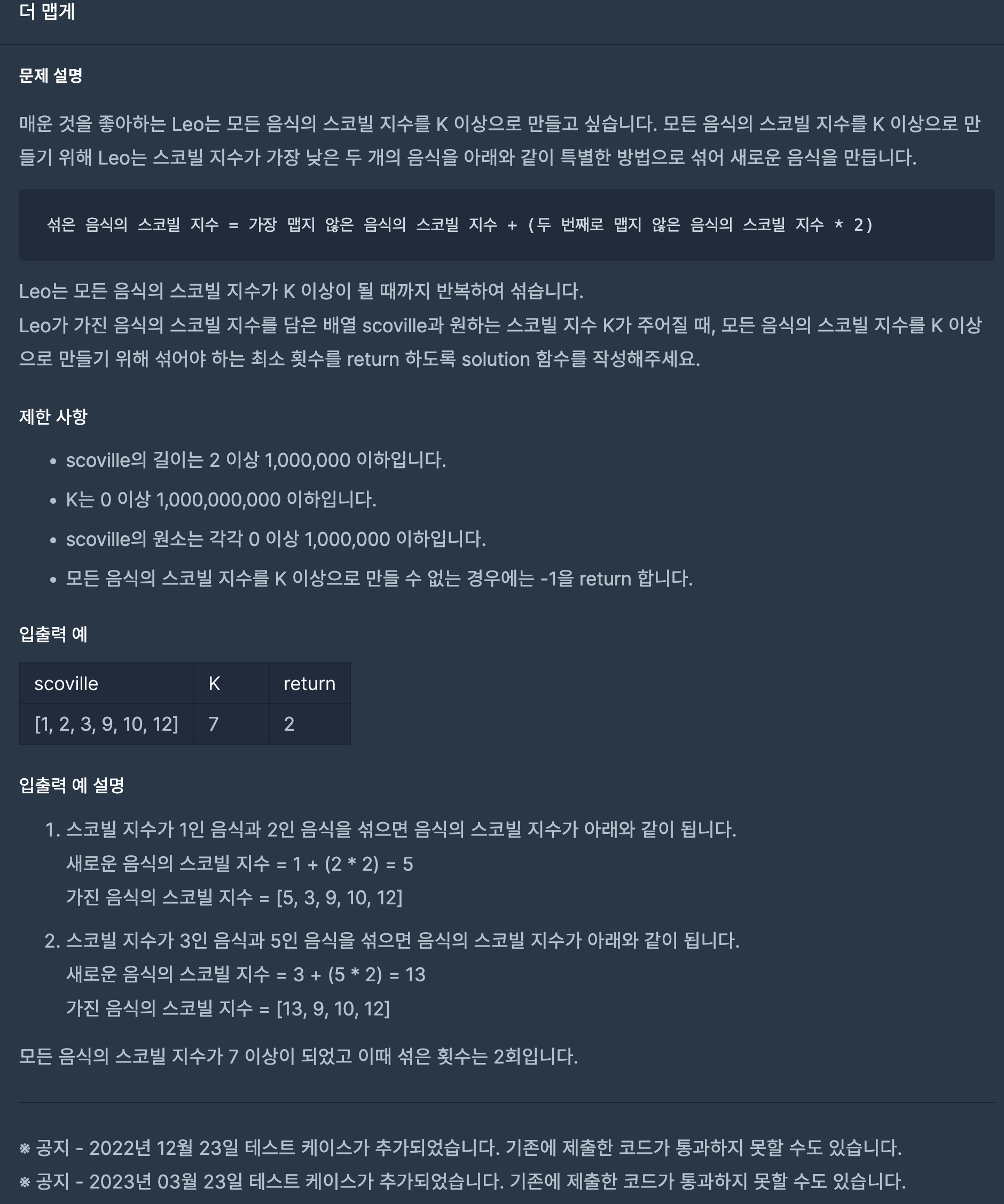
간단히 priority_queue를 min_heap으로 만들어서 위 로직을 따르면 된다.모든 음식의 스코빌 지수를 k 이상으로 만들어야 하기 때문에 최소 힙이 필요하고, Queue의 top이 k보다 작다면 모든 음식의 스코빌 지수가 k 이상이 아니기 때문에 2개를 꺼내
26.프로그래머스/lv3/43163. 단어 변환
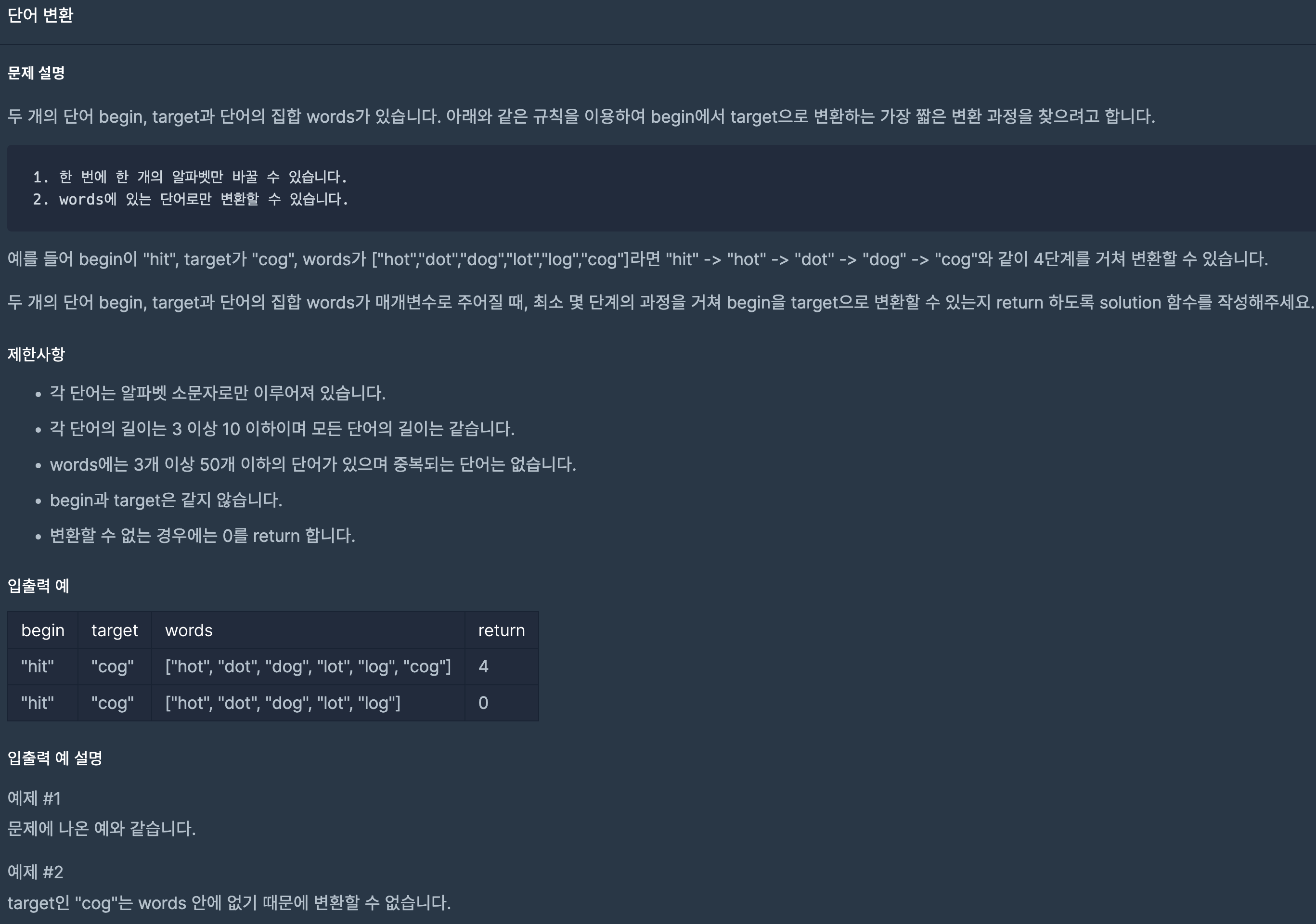
BFS를 로직을 이용해 while문을 돌면서 String(문자열), int(탐색횟수) pair형태로 돌려준다.q가 empty가 될 때 까지 반복하며 tmp, tmpCnt로 문자열과 탐색횟수를 저장하고, target과 일치하다면 탐색횟수를 return한다.핵심로직은 한
27.프로그래머스/lv3/12927. 야근 지수
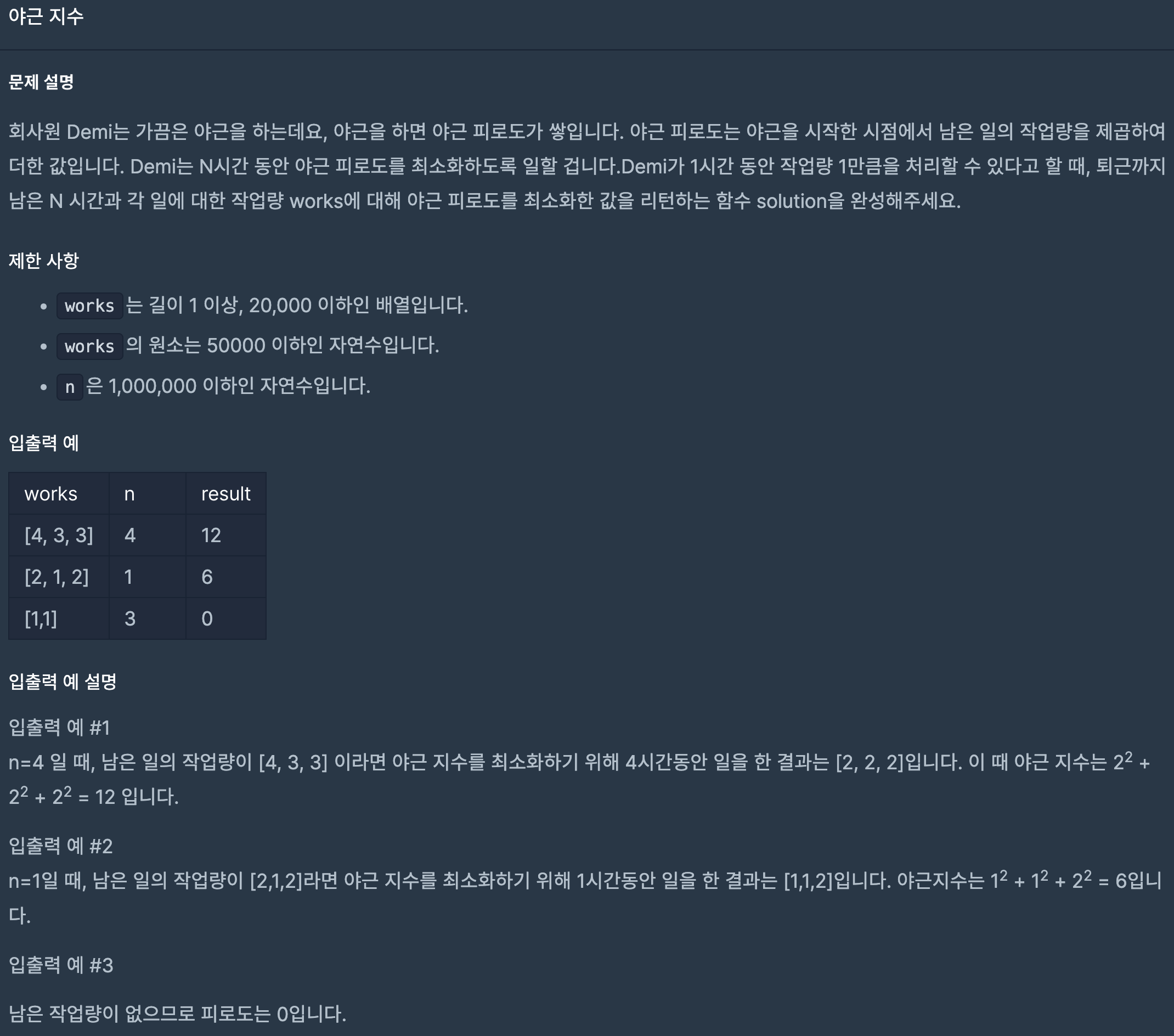
평균값을 최대한 줄여야 제곱을 더하는 과정에서 가장 작은 값을 만들 수 있다. 그러므로 우선순위 큐를 사용해서 works의 모든 값을 할당해주고, k에 works의 모든 값을 더해 야근이 필요없을 때를 예외처리하기 위해 할당했다.퇴근까지 남은 시간이 모두 소진될 때 까
28.프로그래머스/lv2/84512. 모음 사전
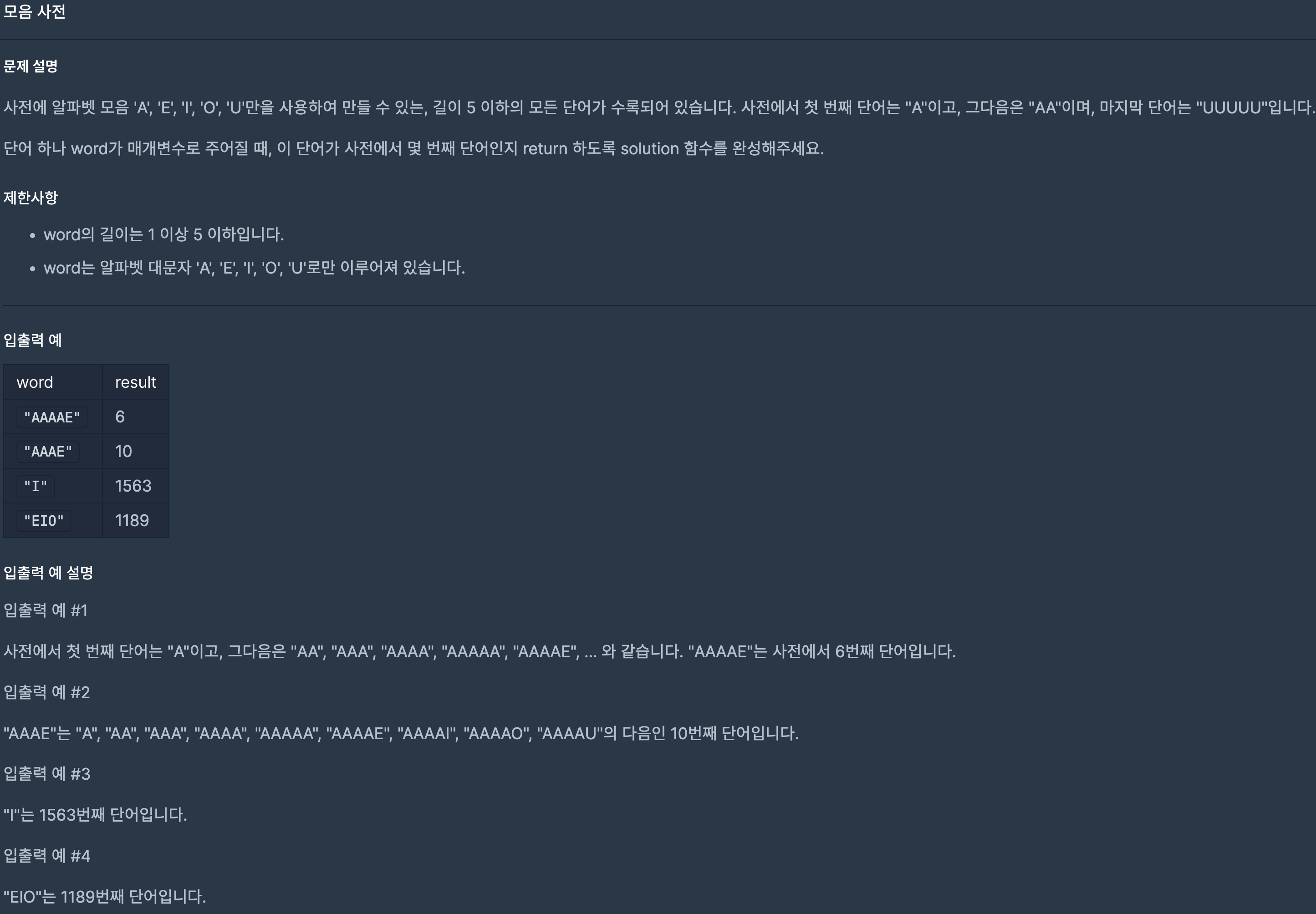
문자가 5개니 5중 for문으로 가능한 모든 경우의 수를 push하고 정렬한 뒤 찾아서 그 index를 return한다
29.프로그래머스/lv2/154539. 뒤에 있는 큰 수 찾기
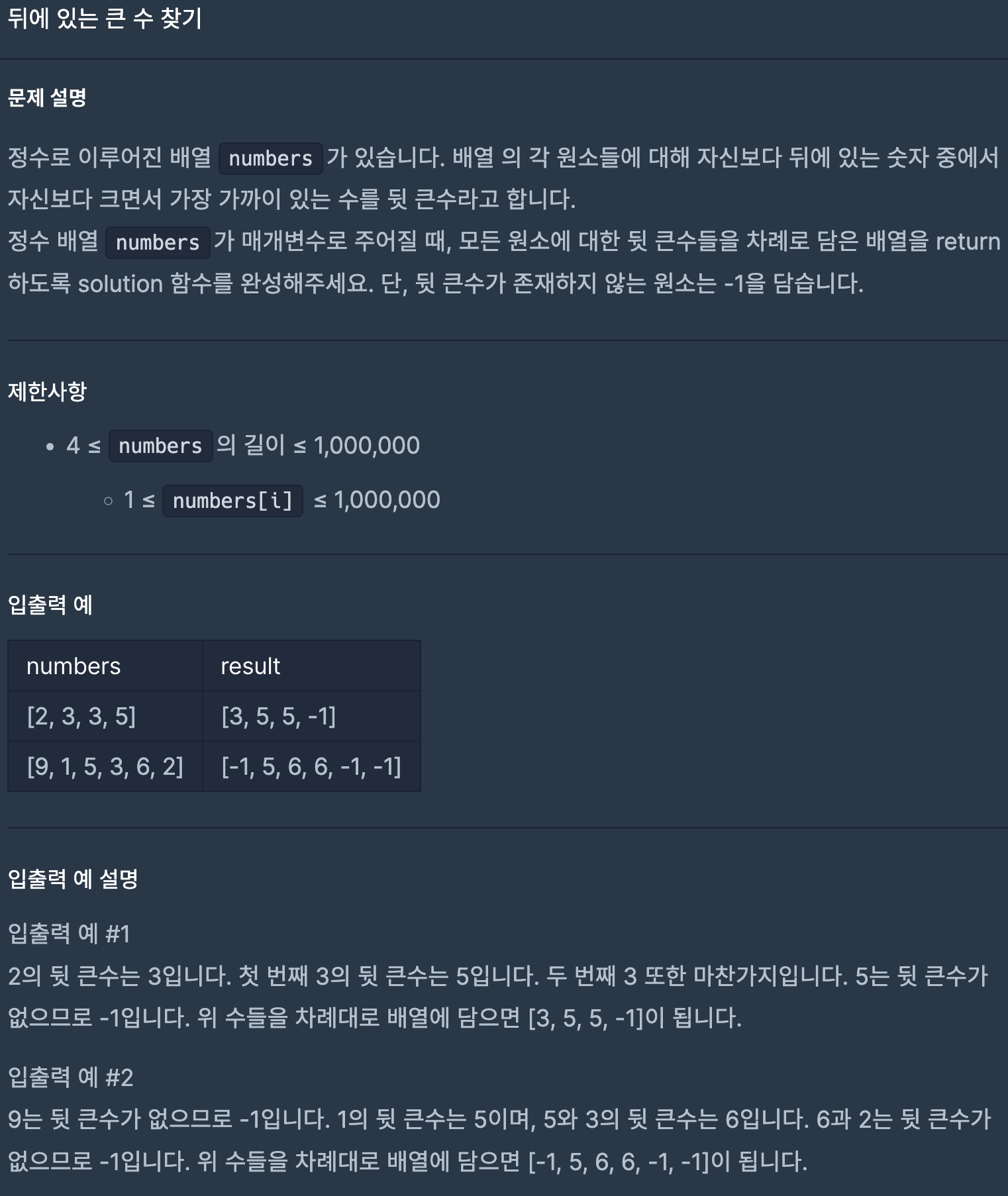
인덱스 별로 직접 찾는 순회하며 큰 값을 찾는 방식이 아닌 stack에 저장해두었다가 인덱스를 돌며 stack의 top -> 최근 지난 인덱스의 값보다 현재 값이 더 크면 answers.top에 현재 인덱스의 값을 넣는 방식이다.answer은 -1로 numbers의 크
30.프로그래머스/lv2/12945. 피보나치 수

일반적인 Recursive 방식으로 풀게 된다면 시간초과가 나게 된다.이 뜻은 DP로 memoization해야한다는 뜻이다. Recursize 방식으로 풀게 된다면 값이 커졌을 때 계산한 부분에 대해서 또 계산을 하게 되므로 시간 손실이 많이 일어난다. 그래서 F의 값
31.프로그래머스/lv3/42579. 베스트앨범
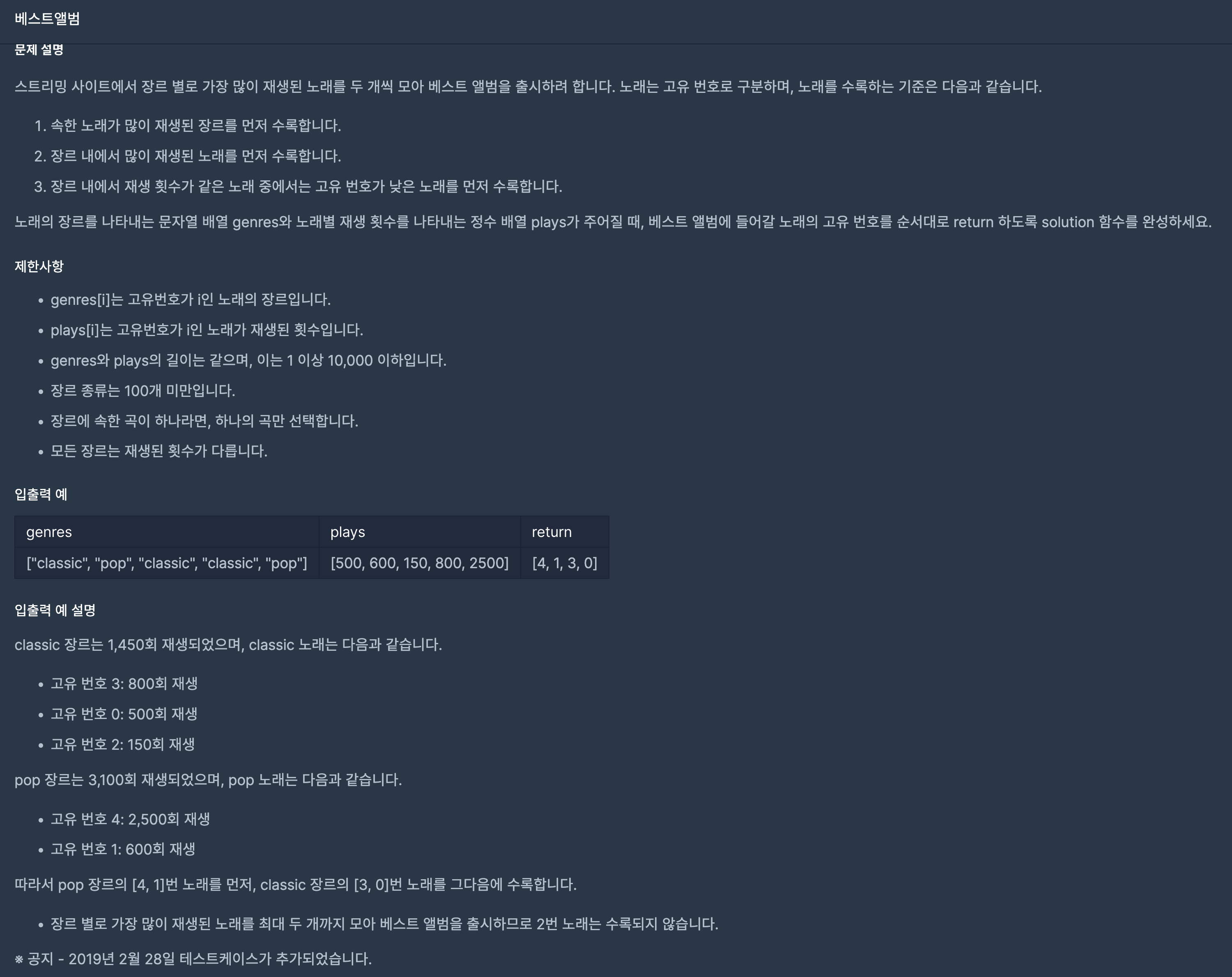
조건이 많은 문제였다. 장르명 / 그 장르의 총 재생횟수 / 노래의 고유 번호, 노래의 재생된 횟수까지 4개가 있었다.노래 정보는 구조체로 묶고 연산자 오버로딩을 통해 multiset 안에서 재생 횟수가 많은 순으로 자동 정렬되게 만들었다.장르 별 총 재생 횟수는 pa
32.프로그래머스/lv2/12953. N개의 최소공배수

유클리드 알고리즘을 이용하면 쉽게 lcm(최소공배수)를 구할 수 있다.
33.프로그래머스/lv2/12951. JadenCase 문자열 만들기

string의 가장 처음 문자를 대문자로 바꾸고, 그 뒤 빈칸 앞의 문자는 대문자로 바꾸기만 하면 된다
34.프로그래머스/lv2/49993. 스킬트리
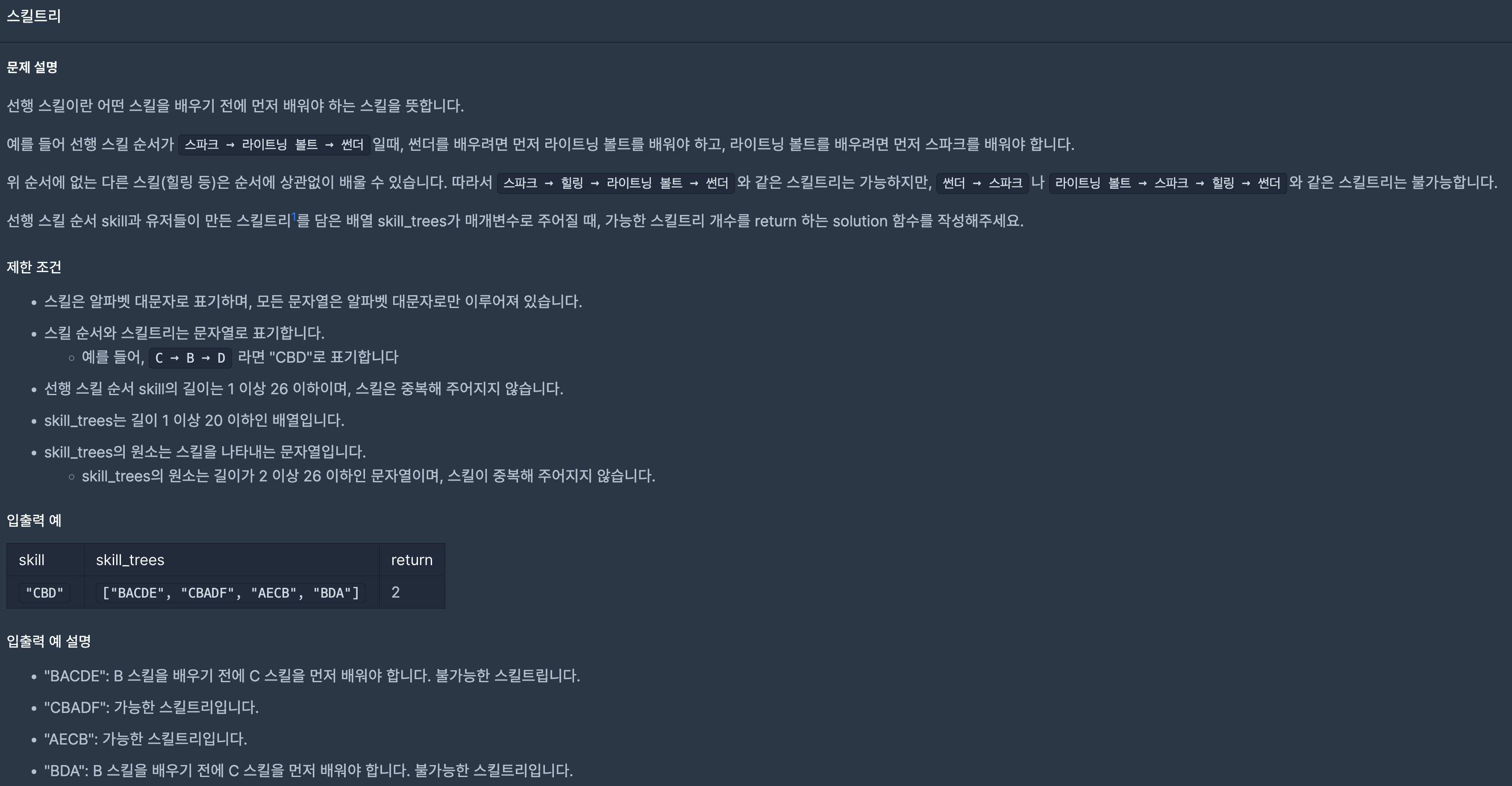
선행 스킬트리는 따로 인덱스를 지정해준다.idx를 지정하고 만약 현재 스킬 st i 가 선행 스킬트리를 요구하는 스킬이고,선행 스킬트리의 첫번째를 나타내는 idx와 같다면 idx++,같지 않다면 현재 배워야하는 스킬트리는 선행 스킬트리를 배우지 못하는 스킬트리이기 때문
35.프로그래머스/lv2/42888. 오픈채팅방 2019 KAKAO BLIND RECRUITMENT
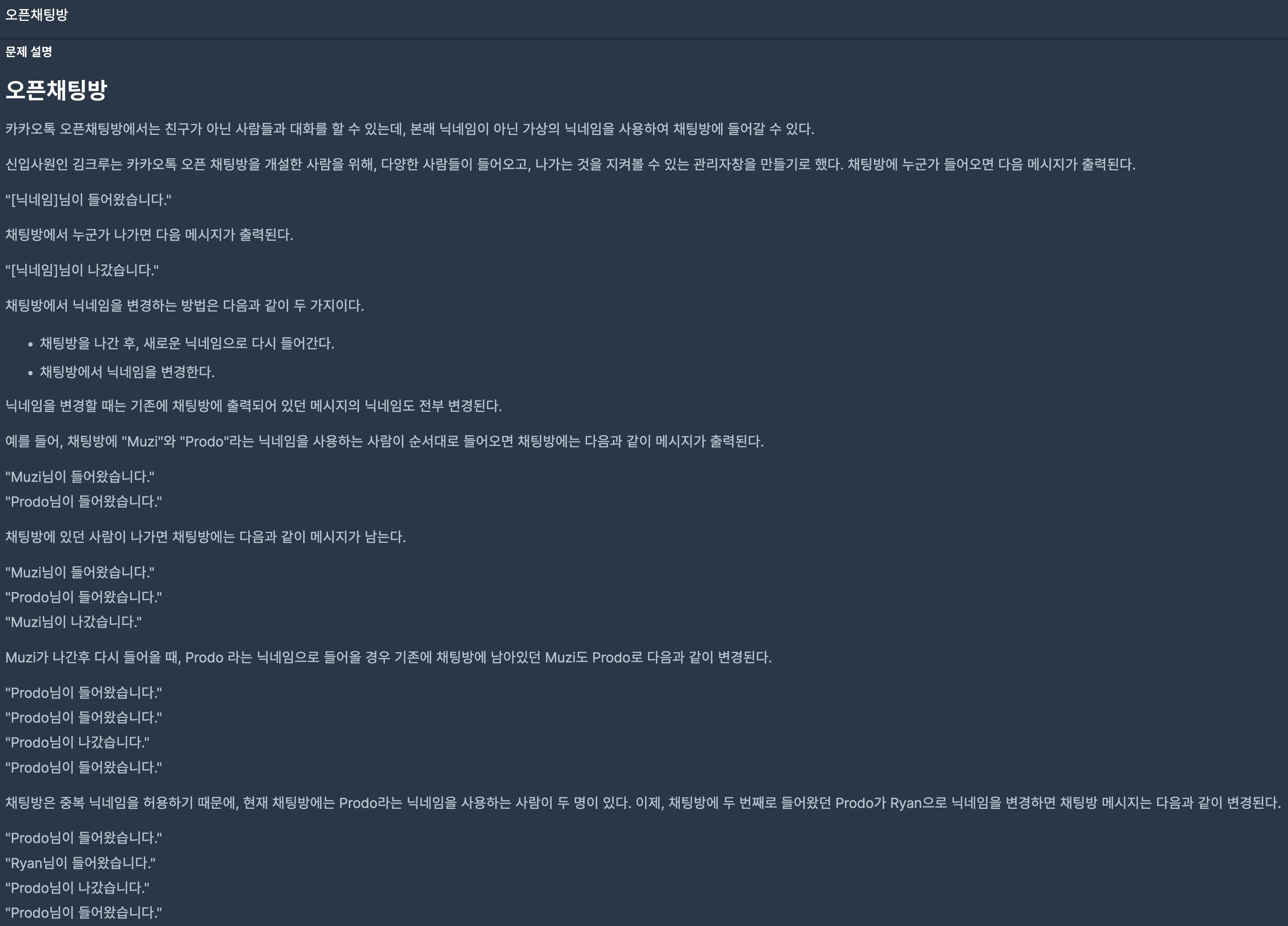
해결해야 하는 문제는 최종적으로 진행되고 난 결과를 나타내야 하는 문제다.또한 유저는 닉네임을 바꿀 수 있기 때문에 닉네임이 바뀌어도 어떤 일을 했는지 구분할 수 있는 방법을 찾아야 한다.유저의 ID는 변하지 않는다. 그러나 닉네임은 변할 수 있기 때문에 Map에 Ke
36.프로그래머스/lv2/42746. 가장 큰 수
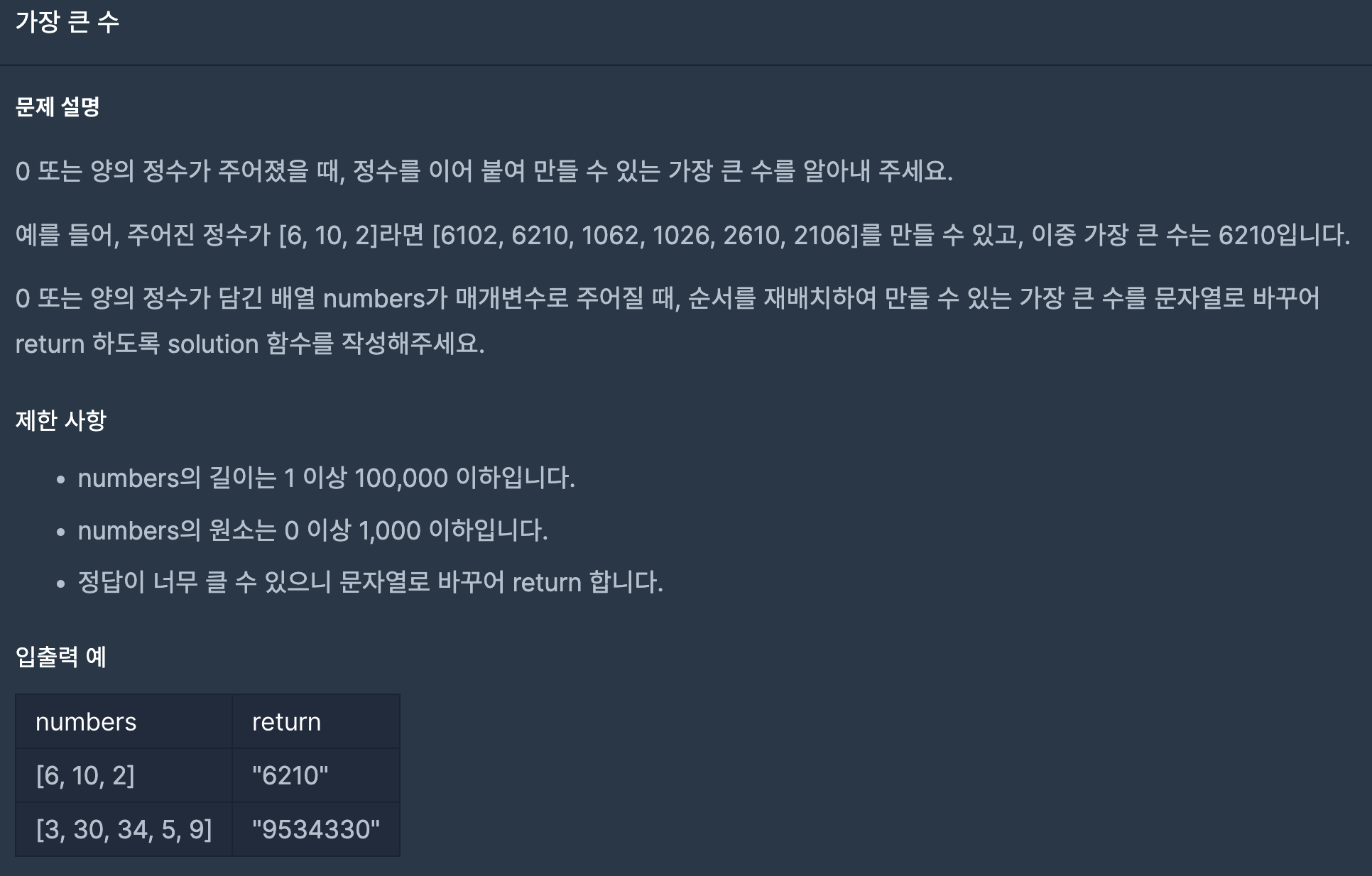
간단히 생각해야 하는 문제다.처음엔 자릿수마다 모든 값을 큰 순서로 stack을 만들려고 했지만,가장 쉬운 방법은 문자열을 이용하는 방식으로 정렬 방식을 지정해주면 된다.해당 문제의 실제 두 번째 테스트 케이스인 3, 30, 34, 5, 9을 기준으로 살펴보면,comp
37.프로그래머스/lv2/92341. 주차 요금 계산 2022 KAKAO BLIND RECRUITMENT
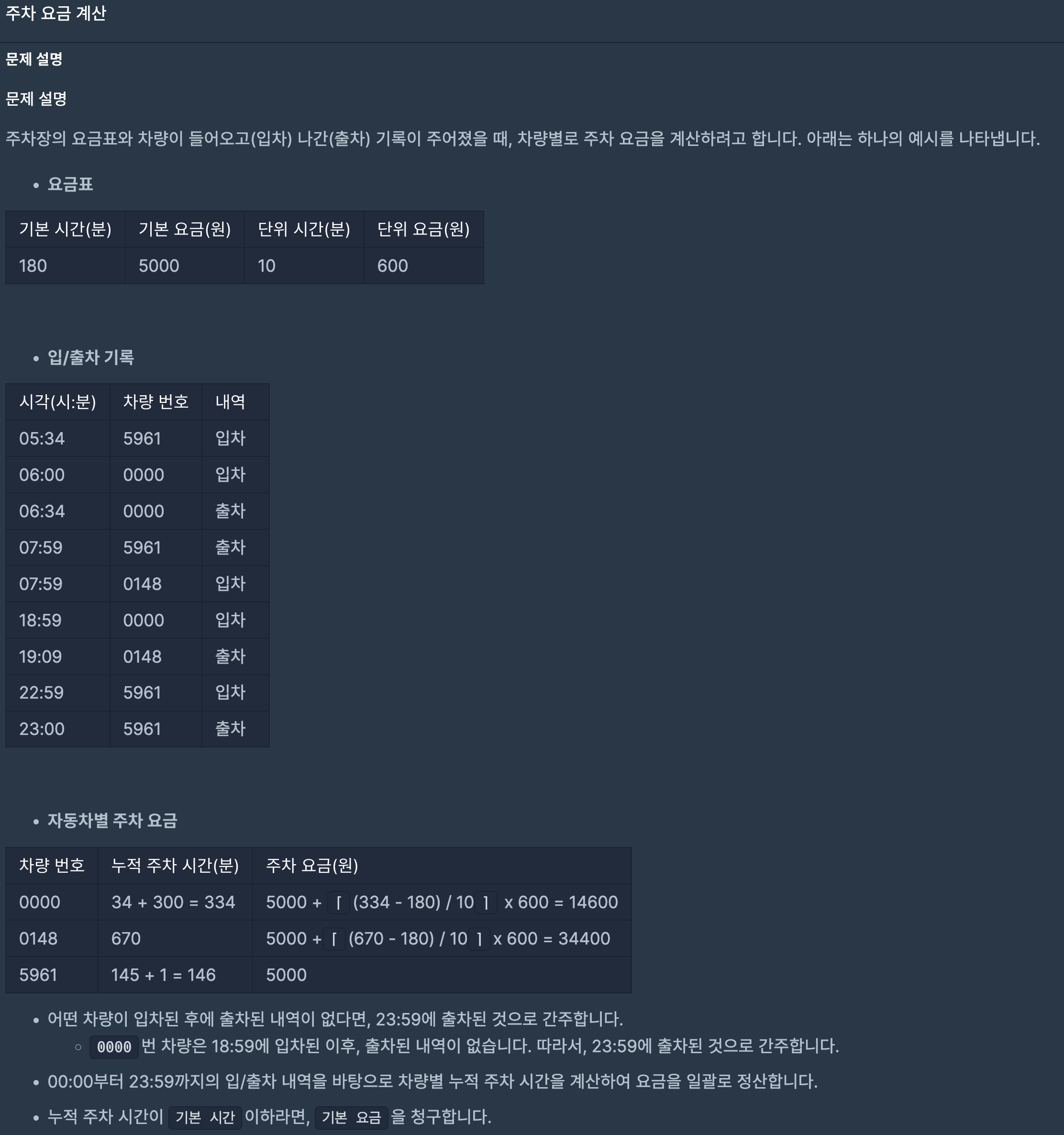
차가 들어올 때는 차량 번호와 들어간 시간을 저장하는 Cars에 할당하고,차가 나갈 때는 차량 번호와 머무른 시간을 저장하는 stayed_time에 총 머무른 시간을 저장한다.그리고 차가 나간다면 차량이 들어올 때 저장했던 Cars에서 삭제한다.만약 Cars의 사이즈가
38.프로그래머스/lv2/42583. 다리를 지나는 트럭
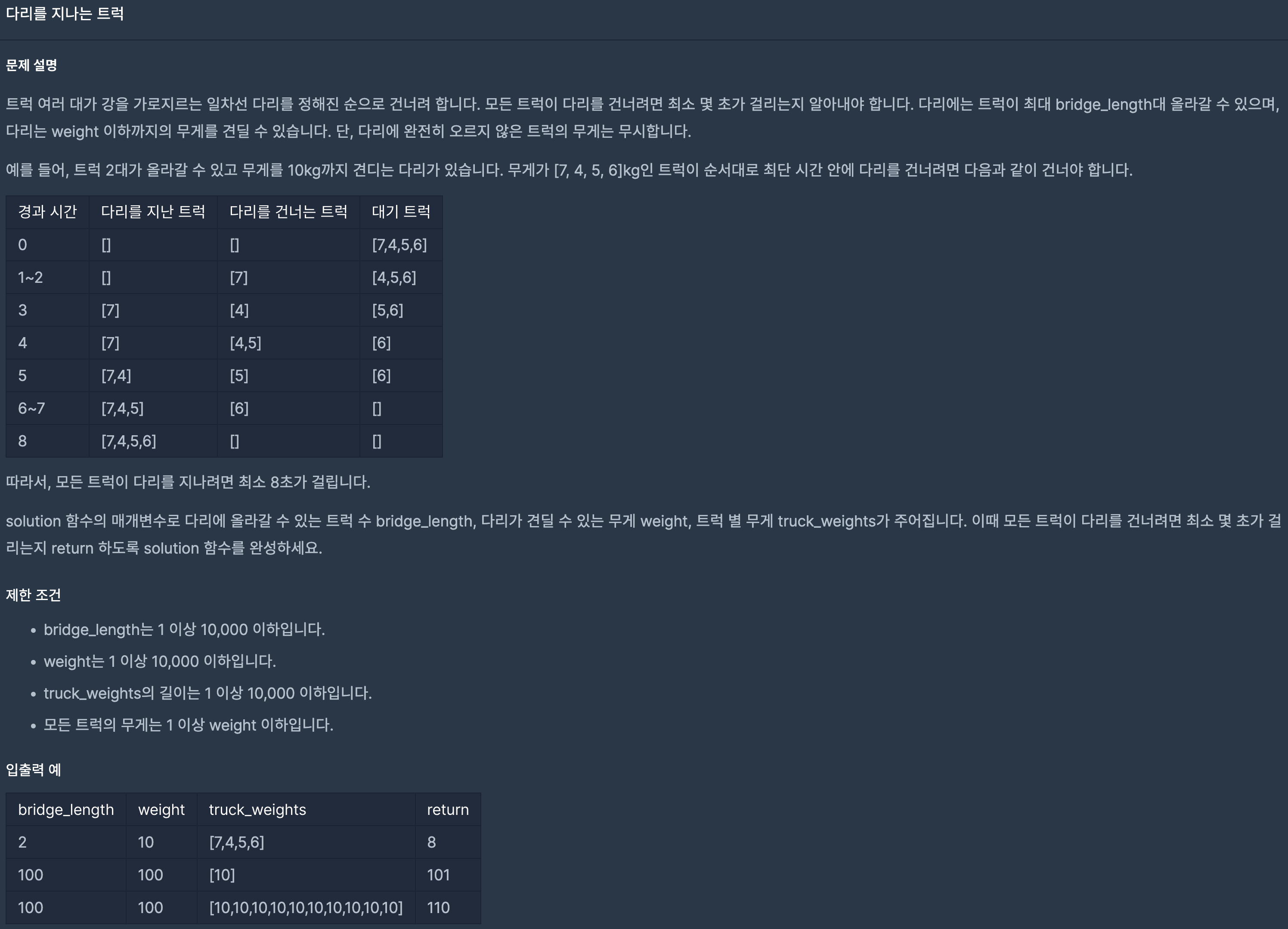
말 그대로 구현을 하면 되지만 구현이 헷갈리는 문제였다.시간의 흐름을 따라 계산해야 하는 문제이기 때문에 시간을 1초씩 올리면서 다리에 올라간 트럭들의 출입 시간을 기록하고,지금 시간이 Queue의 맨 앞 트럭이 나갈 시간이라면 가용 하중을 저장하는 max에서 빼주고
39.프로그래머스/lv2/17686.[3차]파일명 정렬 2018 KAKAO BLIND RECRUITMENT
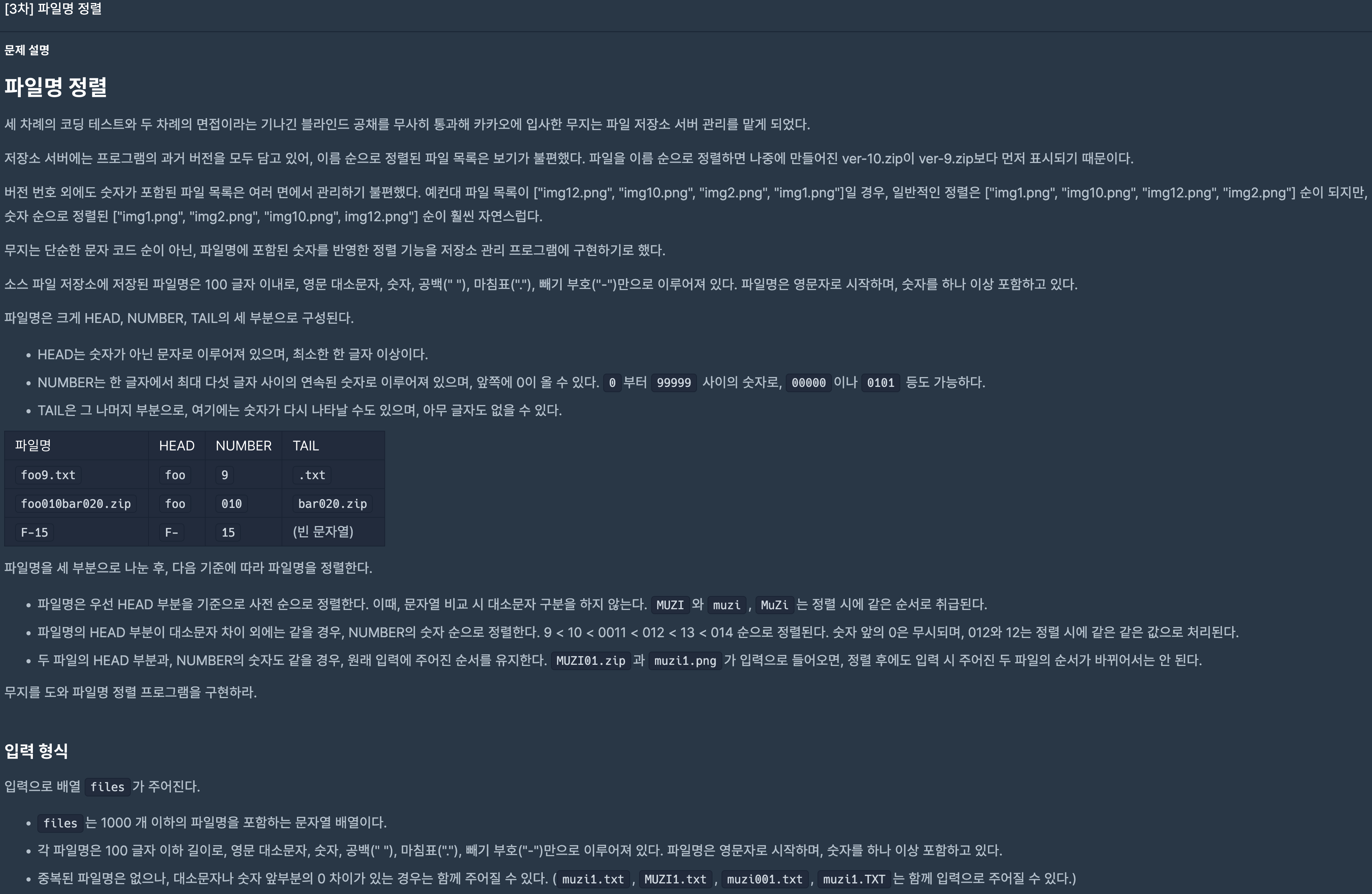
처음에 Regular expression까지는 괜찮았는데 통과가 되지않았는데, 아무리 생각해봐도 안 될 이유가 없었다.1 -> (^0-9+) : 숫자가 아닌 문자로 이루어진 "head"를 찾음.2 -> (0\*(0-9{1,5})) : 0으로 시작할 수 있고, 0부터
40.프로그래머스/lv2/17679.[1차]프렌즈4블록 2018 KAKAO BLIND RECRUITMENT
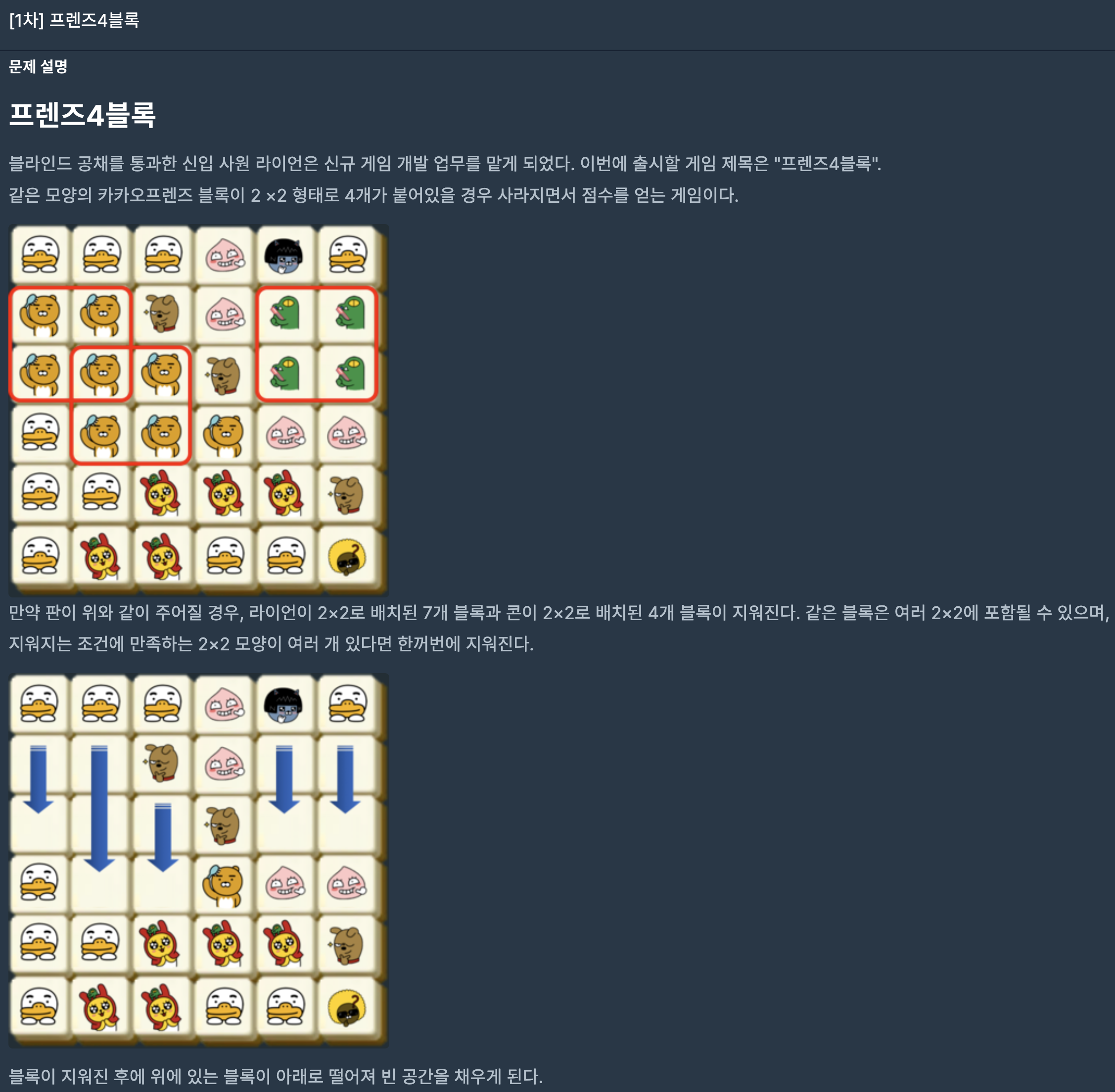
사각형 기준 왼쪽 위부터 검사해 4개의 블록이 같으면 pair형태로 Queue에 좌표를 저장해준다. Queue에 저장한 좌표를 기준으로 오른쪽, 아래, 오른쪽 아래를 빈칸으로 바꾼다. 몇개의 블록이 빈칸으로 변환됐는지 알아야하기에
41.프로그래머스/lv2/132265. 롤케이크 자르기
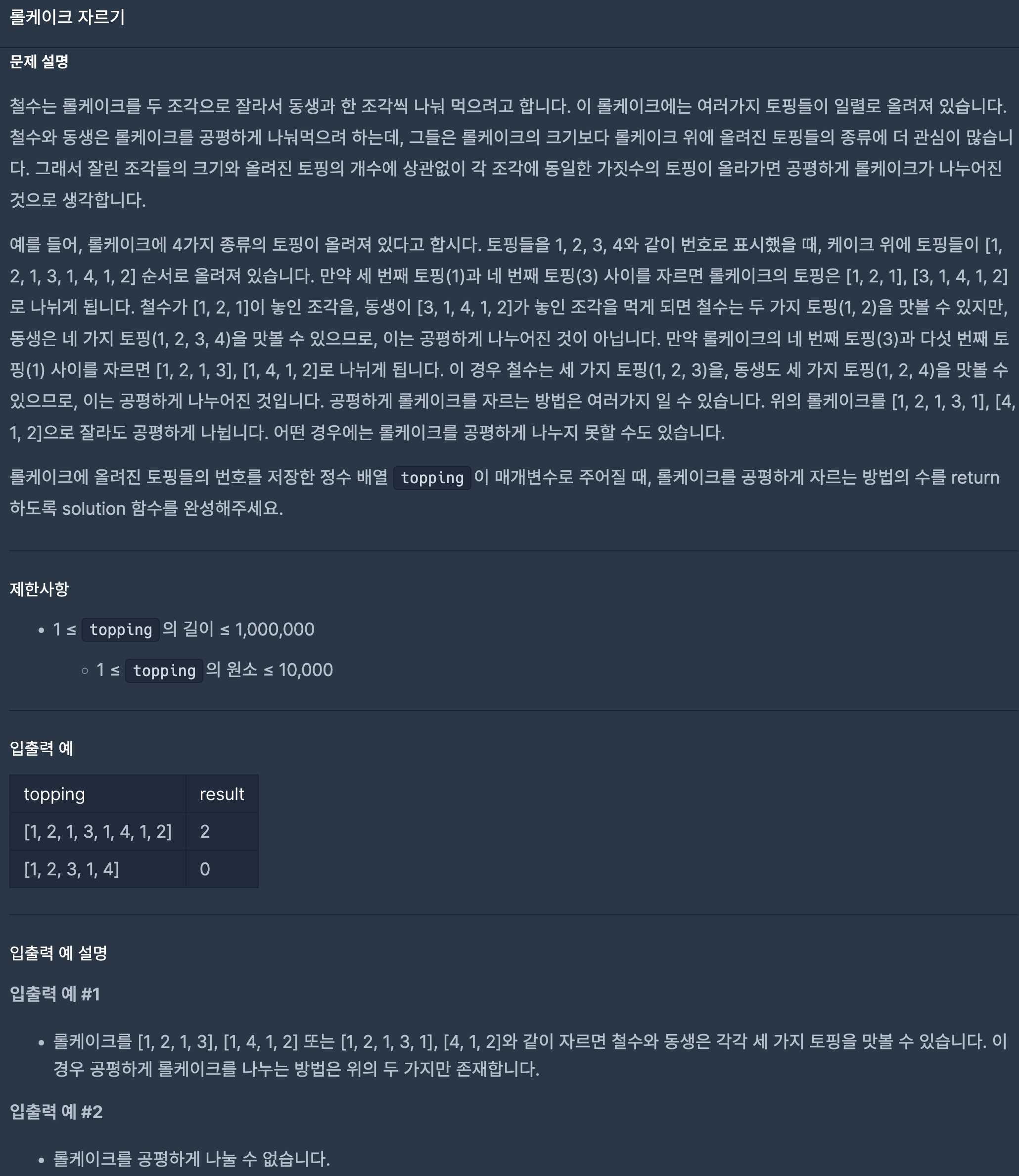
원소마다 개수를 세는 arr을 따로 선언하고, 먼저 첫 번째 set에 미리 모든 원소를 넣는다.그리고 비교하기 위한 두 번째 set을 만든 뒤 for문을 돌면서 첫 번째 set엔 원소를 지우고,두 번째 set엔 원소를 추가하며 size를 비교하며 size가 같으면 an
42.프로그래머스/lv2/49994. 방문 길이
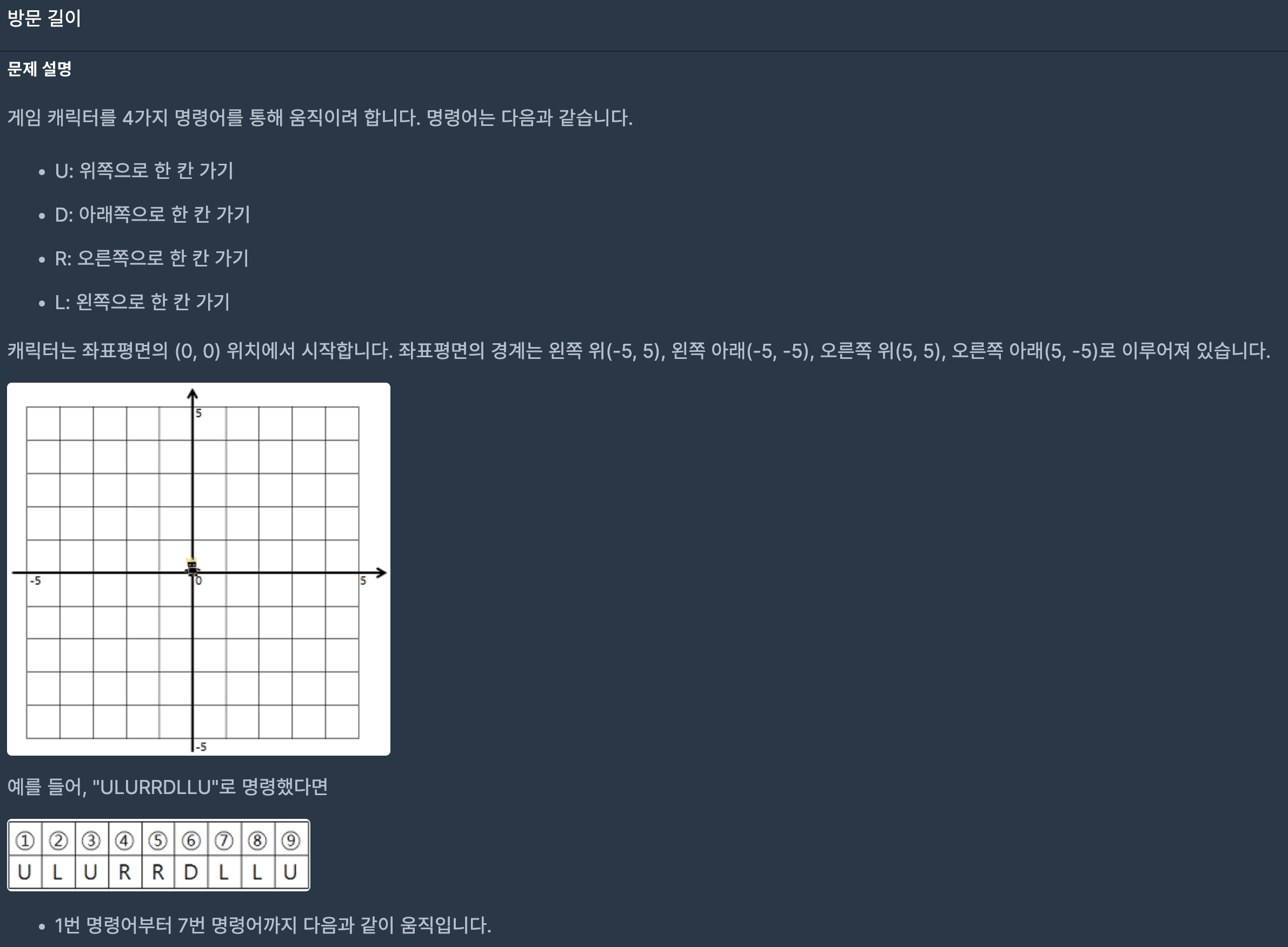
10X10 좌표평면에서 지나간 길이 몇개인지 찾는 문제다.시작점 0,0에서 시작하고, U D L R 4가지 방향을 map과 mov로 정의한 후, 좌표평면 밖으로 나가지 않는다면 체크한다.여기서 주의해야 할 점은 donePath에 지나온 길을 기록할 때 양방향
43.백준/Silver/1629. 곱셈
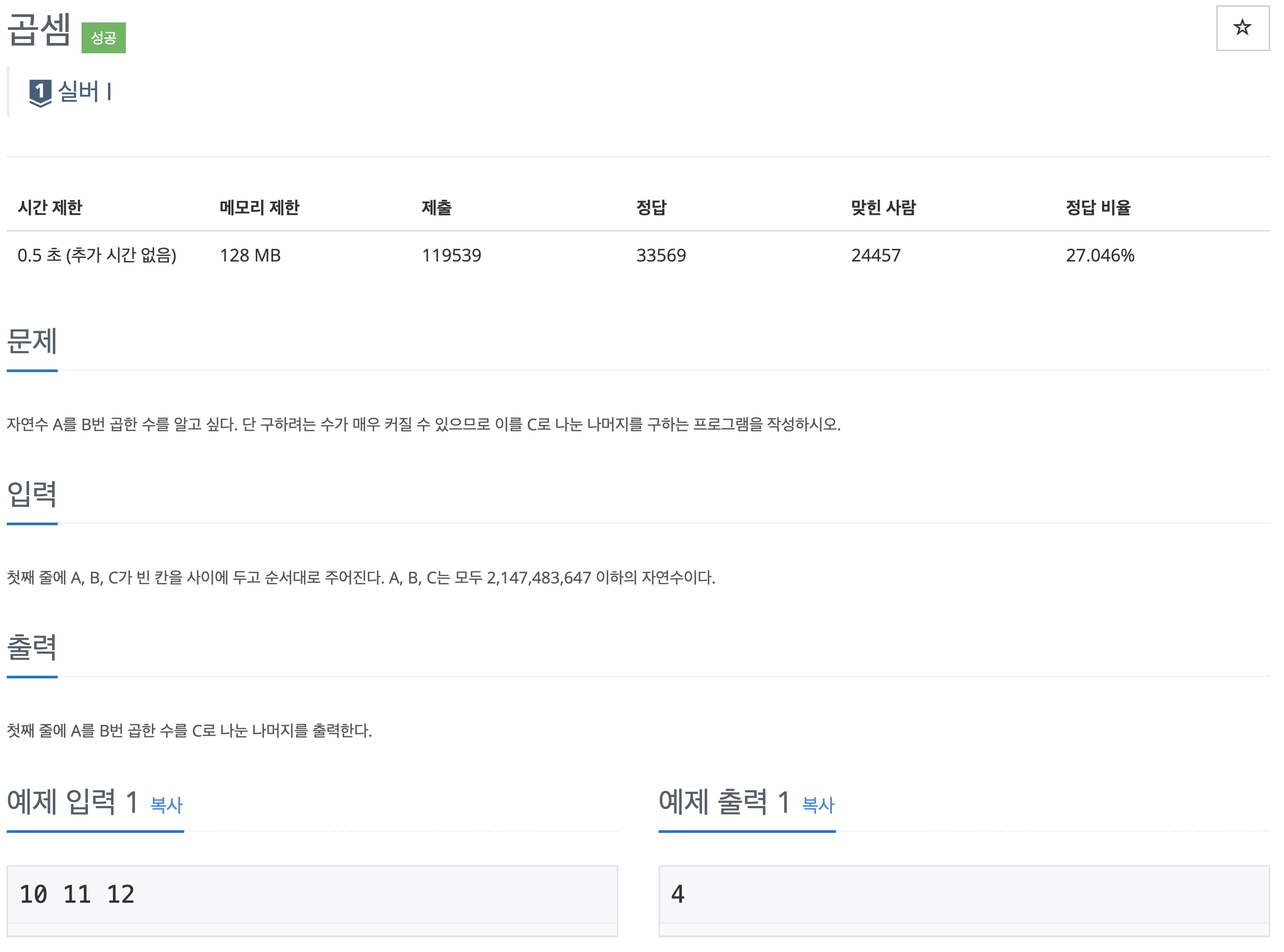
분할 정복을 이용한 거듭제곱을 사용해야하는 문제 Input이 많기 때문에 일반적인 곱셈을 이용한다면 시간초과가 발생2^4 -> 2^2 x 2^22^8 -> 2^4 x 2^4위와 같은 방식으로 계산량을 log2로 줄이는 방법임계산을 64번 해야한다면64 -> 32 32