1. NumPy
1.1 NumPy는
The fundamental package for scientific computing in Python.
- NumPy가 제공하는 것
- 다차원 배열: ndarray
- 다양한 파생 객체: masked arrays, matrices
- 빠른 연산을 가능하게 하는 여러가지 기본 도구 모음
- NumPy array의 특징
- 생성될 때 정해지는 크기
- 동일한 데이터 타입 => 동일한 메모리
- 대용량 데이터를 가지고 빠른 수학적/과학적 계산이 가능
1.1.1 배열 모양
다음 배열에서 24의 위치는?
array([[[ 1, 2, 3],
[ 4, 5, 6],
[ 7, 8, 9],
[10, 11, 12]],
[[13, 14, 15],
[16, 17, 18],
[19, 20, 21],
[22, 23, 24]]])1.1.2 백터화 (Vectorization)
import numpy as np
# 1차원 배열 (Python 리스트) - for문 방식
a_1d = [1, 2, 3, 4]
b_1d = [10, 20, 30, 40]
c_1d = []
for i in range(len(a_1d)):
c_1d.append(a_1d[i] * b_1d[i])
print("1D for문 결과:", c_1d)
# 2차원 배열 - 중첩 for문 방식
a_2d = [[1, 2], [3, 4]]
b_2d = [[10, 20], [30, 40]]
rows = len(a_2d)
columns = len(a_2d[0])
c_2d = [[0]*columns for _ in range(rows)]
for i in range(rows):
for j in range(columns):
c_2d[i][j] = a_2d[i][j] * b_2d[i][j]
print("2D 이중 for문 결과:", c_2d)
# NumPy 벡터화 방식 (1D & 2D)
a_np_1d = np.array(a_1d)
b_np_1d = np.array(b_1d)
c_np_1d = a_np_1d * b_np_1d
print("NumPy 1D 벡터화 결과:", c_np_1d)
a_np_2d = np.array(a_2d)
b_np_2d = np.array(b_2d)
c_np_2d = a_np_2d * b_np_2d
print("NumPy 2D 벡터화 결과:\n", c_np_2d)
'''
1D for문 결과: [10, 40, 90, 160]
2D 이중 for문 결과: [[10, 40], [90, 160]]
NumPy 1D 벡터화 결과: [ 10 40 90 160]
NumPy 2D 벡터화 결과:
[[ 10 40]
[ 90 160]]
'''1.1.3 브로드캐스팅 (Broadcasting)
- 두 차원은 다음과 같을 때 호환 가능
- 각 차원의 크기가 같거나
- 한 쪽 차원이 1일 때 (자동 확장 가능)
왼쪽에서부터 맞춰보며 뒤쪽(오른쪽) 차원부터 비교
import numpy as np
# ✅ 예제 1: 두 배열의 shape가 같을 때 → 그냥 element-wise 연산
a1 = np.array([[1, 2], [3, 4]]) # shape: (2, 2)
b1 = np.array([[10, 20], [30, 40]]) # shape: (2, 2)
# 두 shape가 완전히 같음 → 브로드캐스팅 없이 곱셈 가능
print("예제 1 결과 (2x2 vs 2x2):\n", a1 * b1) # 출력 shape: (2, 2)
# ✅ 예제 2: 한쪽 shape에 1이 있는 경우 → 자동 확장 (브로드캐스팅 발생)
a2 = np.array([[1, 2], [3, 4]]) # shape: (2, 2)
b2 = np.array([10, 20]) # shape: (2,) → 내부적으로 (1, 2)로 처리됨
# b2가 (1, 2)로 변하고 a2의 (2, 2)와 연산 → OK
print("예제 2 결과 (2x2 vs 1x2):\n", a2 * b2) # 출력 shape: (2, 2)
# ✅ 예제 3: 차원이 다르지만 뒤에서부터 맞으면 가능 (자동 확장)
a3 = np.ones((2, 3, 4)) # shape: (2, 3, 4)
b3 = np.array([10, 20, 30, 40]) # shape: (4,) → 내부적으로 (1, 1, 4)로 확장됨
# (2, 3, 4) * (1, 1, 4) → OK
print("예제 3 결과 shape (2x3x4 vs 4, broadcasted):", (a3 * b3).shape) # (2, 3, 4)
# ❌ 예제 4: 브로드캐스팅 불가능한 경우 → 에러 발생
a4 = np.array([1, 2, 3]) # shape: (3,)
b4 = np.array([10, 20, 30, 40]) # shape: (4,)
# shape (3,) vs (4,) → 브로드캐스팅 조건 위배 → ValueError
try:
print("예제 4 결과 (3 vs 4):", a4 * b4)
except ValueError as e:
print("예제 4 오류:", e)
'''
예제 1 결과 (2x2 vs 2x2):
[[ 10 40]
[ 90 160]]
예제 2 결과 (2x2 vs 1x2):
[[10 40]
[30 80]]
예제 3 결과 shape (2x3x4 vs 4, broadcasted): (2, 3, 4)
예제 4 오류: operands could not be broadcast together with shapes (3,) (4,)
'''1.1.4 배열의 자료형
- 논리형, 정수형, 실수형, 복소수형, String/Bytes
1.1.5 배열 인덱스
import numpy as np
# 3차원 배열 정의 (2개 블록, 각 블록은 4x3 행렬)
x = np.array([
[[ 1, 2, 3],
[ 4, 5, 6],
[ 7, 8, 9],
[10, 11, 12]],
[[13, 14, 15],
[16, 17, 18],
[19, 20, 21],
[22, 23, 24]]
])
# ▶ 1. 개별 요소 접근
print("x[0, 1, 2] =", x[0, 1, 2]) # 첫 번째 블록, 두 번째 행, 세 번째 열 → 6
print("x[-1, -1, -1] =", x[-1, -1, -1]) # 마지막 블록, 마지막 행, 마지막 열 → 24
# ▶ 2. 블록 전체 가져오기
print("x[0] =\n", x[0]) # 첫 번째 블록 전체 (4x3 행렬)
# ▶ 3. 조건 인덱싱: 짝수 값만 선택
print("x[x % 2 == 0] =", x[x % 2 == 0]) # 배열 전체에서 짝수만 필터링
# ▶ 4. 불리언 인덱싱: 첫 번째 블록만 선택
print("x[[True, False]] =\n", x[[True, False]]) # shape (1, 4, 3)1.1.6 배열 슬라이스
import numpy as np
# 동일한 배열 다시 정의 (shape = 2 x 4 x 3)
x = np.array([
[[ 1, 2, 3],
[ 4, 5, 6],
[ 7, 8, 9],
[10, 11, 12]],
[[13, 14, 15],
[16, 17, 18],
[19, 20, 21],
[22, 23, 24]]
])
# ▶ 1. 모든 블록, 모든 행, 첫 번째 열
print("x[:, :, 0] =\n", x[:, :, 0]) # shape: (2, 4)
# ▶ 2. Ellipsis (…)를 이용한 동일 접근
print("x[..., 0] =\n", x[..., 0]) # 위와 동일 결과 (2, 4)
# ▶ 3. 모든 블록에서 첫 번째 행만 선택
print("x[:, 0] =\n", x[:, 0]) # shape: (2, 3)
# ▶ 4. 슬라이스와 step 사용: 첫 번째 블록, 첫 번째 행, 열 0~2 중 2 step
print("x[0, 0, 0:3:2] =", x[0, 0, 0:3:2]) # 결과: [1, 3]
# ▶ 5. 첫 번째 블록, 모든 행, 열 0~2 중 2 step
print("x[0, :, 0:3:2] =\n", x[0, :, 0:3:2]) # shape: (4, 2)
# ▶ 6. 첫 번째 블록, 0~1행까지, 두 번째 열
print("x[0, 0:2, 1] =", x[0, 0:2, 1]) # 결과: [2, 5]1.2 배열 생성
6가지 방식이 있음
- 다른 Python 구조 (list, tuple 등) 에서 변환
- NumPy 자체 제공 함수로 생성: arange, ones, zeros
- 기존의 배열을 복제하거나, 결합 또는 수정
- Disk에서 배열 불러오기
- 문자열이나 버퍼를 이용해 Raw Bytes로부터 배열 생성
- 특수 라이브러리 함수 사용: SciPy, pandas, Open
1.2.1 다른 Python 구조에서 변환
단순 List/Tuple => 1D array, List of Lists => 2D array, 중첩 List => ND array
import numpy as np
a1D = np.array([1, 2, 3, 4])
a2D = np.array([[1, 2], [3, 4]])
a3D = np.array([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])numpy.array를 사용할 때에는 dtype을 사용
>>> np.array([127, 128, 129], dtype=np.int8)
Traceback (most recent call last):
…
OverflowError: Python integer 128 out of bounds for int8a = np.array([1, 2, 3, '4'])
print(a, a.dtype)a = np.array([2, 3, 4], dtype=np.uint32)
b = np.array([5, 6, 7], dtype=np.uint32)
c_unsigned32 = a - b
print('unsigned c:', c_unsigned32, c_unsigned32.dtype)
c_signed32 = a - b.astype(np.int32)
print('signed c:', c_signed32, c_signed32.dtype)1.2.2 NumPy 자체 제공 함수
40 여개의 Built-in 함수 제공
np.arange(10)
np.arange(2, 10, dtype=float)
np.arange(2, 3, 0.1)
np.linspace(1., 4., 6)np.eye(3)
np.eye(3, 5)
np.diag([1, 2, 3])
np.diag([1, 2, 3], 1)
a = np.array([[1, 2], [3, 4]])
np.diag(a)
np.vander(np.linspace(0, 2, 5), 2)
np.vander([1, 2, 3, 4], 2)
np.vander((1, 2, 3, 4), 4)np.zeros((2, 3))
np.zeros((2, 3, 2))
np.ones((2, 3))
np.ones((2, 3, 2))
from numpy.random import default_rng
default_rng(42).random((2,3))
default_rng(42).random((2,3,2))>>> np.indices((3,3))
array([[[0, 0, 0],
[1, 1, 1],
[2, 2, 2]],
[[0, 1, 2],
[0, 1, 2],
[0, 1, 2]]])1.2.3 기존 배열 복제/결합/수정
a = np.array([1, 2, 3, 4, 5, 6])
b = a[:2]
b += 1
print('a =', a, '; b =', b)a = np.array([1, 2, 3, 4])
b = a[:2].copy()
b += 1
print('a = ', a, 'b = ', b)A = np.ones((2, 2))
B = np.eye(2, 2)
C = np.zeros((2, 2))
D = np.diag((-3, -4))
np.block([[A, B], [C, D]])a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
np.vstack((a,b))
a = np.array([[1], [2], [3]])
b = np.array([[4], [5], [6]])
np.vstack((a,b))a = np.array((1,2,3))
b = np.array((4,5,6))
np.hstack((a,b))
a = np.array([[1],[2],[3]])
b = np.array([[4],[5],[6]])
np.hstack((a,b))1.2.4 Disk에서 배열 불러오기
CSV 읽기
- loadtxt: 빠진 값이 없는 정형화된 자료, float/int 중심
- genfromtxt: 값이 빠진 경우, 복잡한 dtype 지정, 결측값 처리 등 유연성 높음
>>> s = io.StringIO("1,2,3\n4,,6\n7,8,9")
>>> np.genfromtxt(s, delimiter=",")
array([[ 1., 2., 3.],
[ 4., nan, 6.],
[ 7., 8., 9.]])
>>> s.seek(0)
>>> np.genfromtxt(s, delimiter=",", filling_values=0)
array([[1., 2., 3.],
[4., 0., 6.],
[7., 8., 9.]])-
JSON file
- NumPy는 JSON serializable 하지 않음
- json.JSONEncoder 사용
-
pickle file
- 사용 지양할 것
- pickle은 잘못 생성된 데이터에 안전하지 못함
- numpy.save, numpy.load를 사용할 때 allow_pickle=False 설정
1.3 NumPy 함수
1.3.1 reshape
numpy.reshape(a, newshape, order='C')
import numpy as np
# 1D 배열 생성 (총 12개 원소)
a = np.arange(12) # [0, 1, 2, ..., 11]
print("원본 배열:\n", a)
# 1. (3, 4) 형태로 변경
b = np.reshape(a, (3, 4))
print("\nreshape (3, 4):\n", b)
# 2. (2, 2, 3) 형태로 변경
c = a.reshape((2, 2, 3))
print("\nreshape (2, 2, 3):\n", c)
# 3. -1 사용: 자동 계산 (단 한 개의 차원만 -1 가능)
d = a.reshape((4, -1)) # → (4, 3)
print("\nreshape (4, -1):\n", d)
# 4. order='F' 사용: 열 우선 (Fortran-style)
e = a.reshape((3, 4), order='F')
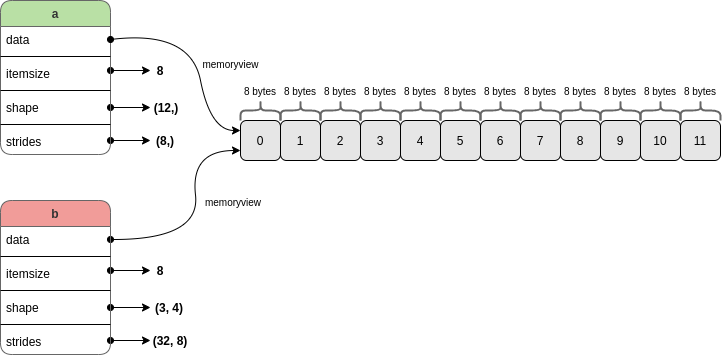
print("\nreshape (3, 4) with order='F':\n", e)1.3.2 flatten, ravel, flat, and reshape
a.flatten(order='C')
numpy.ravel(a, order='C')
a.flat # 이터레이터 객체
import numpy as np
# ▶ 예제 배열 생성: 2x3 형태의 2차원 배열
a = np.array([[1, 2, 3],
[4, 5, 6]])
print("원본 배열 a:\n", a) # shape: (2, 3)
# ✅ 1. reshape() - 배열의 형태를 바꾸지만 원본 데이터를 공유할 수 있음 (view or copy)
# reshape(-1): 모든 원소를 1차원으로 자동 전개 (원소 수는 유지)
b = a.reshape(-1)
print("\n1. reshape(-1):", b)
b[0] = 100 # reshape는 일반적으로 view이므로 원본 배열도 영향받음
print("reshape 후 a:\n", a)
# ✅ 2. flatten() - 항상 **복사본**을 반환 (원본과 완전히 독립적인 1차원 배열)
c = a.flatten()
print("\n2. flatten():", c)
c[0] = 200 # flatten은 복사이므로 원본 a는 변화 없음
print("flatten 수정 후 a:\n", a)
# ✅ 3. ravel() - **가능하면 view**, 불가능하면 copy (flatten보다 빠름)
d = a.ravel()
print("\n3. ravel():", d)
d[0] = 300 # 이 경우도 view이므로 원본에 영향
print("ravel 수정 후 a:\n", a)
# ✅ 4. flat - 배열의 모든 요소를 1차원 순서대로 반복할 수 있는 이터레이터 반환
print("\n4. flat 이터레이터 출력:")
for item in a.flat:
print(item, end=' ') # 1차원처럼 순회 가능
print("\n(flat은 수정용 인덱스 접근도 가능: a.flat[2] = 999 등)")1.3.3 transpose, moveaxis, swapaxes
numpy.transpose(a, axes=None)
numpy.moveaxis(a, source, destination)
numpy.swapaxes(a, axis1, axis2)
1.3.4 min, max, sum
numpy.min(a, axis=None, keepdims=False)
numpy.max(a, axis=None, keepdims=False)
numpy.sum(a, axis=None, keepdims=False, dtype=None)

기술과 비즈니스를 잇는 파트너가 되고자 합니다.