
1. 데이터 분석 방법론
데이터의 가치를 찾아가는 체계적인 절차와 방법
1.1 용어 정리
1.1.1 Data Science
적절한 질문을 정의하고, 데이터로부터 새로운 지식과 통찰을 탐색하는 다학제적 연구 영역
→ “어떤 질문을 해야 할까?”를 고민하며, 다양한 기법(통계, ML 등)을 폭넓게 사용
1.1.2 Data Analytics
구체적인 문제 해결을 위해 데이터를 분석하고 실행 가능한 인사이트를 도출하는 과정
→ “이 문제를 해결하려면 데이터를 어떻게 써야 할까?”를 고민
1.1.3 Data Mining
대규모 데이터에서 자동으로 패턴과 관계를 발견하여 유용한 정보나 예측 모델을 도출하는 기술
→ “데이터 속에 어떤 숨겨진 패턴이 있을까?”를 컴퓨터가 찾아냄
1.2 Data Mining의 중요성
- ✅ 전략적 의사결정의 핵심 도구
- ✅ 운영 효율성 향상
- ✅ 신규 비즈니스 기회 발굴
- ✅ 수익 증대
1.3 CRISP-DM
(Cross Industry Standard Process for Data Mining)
- 다양한 산업 분야에서 사용할 수 있는 표준 데이터 분석 방법론
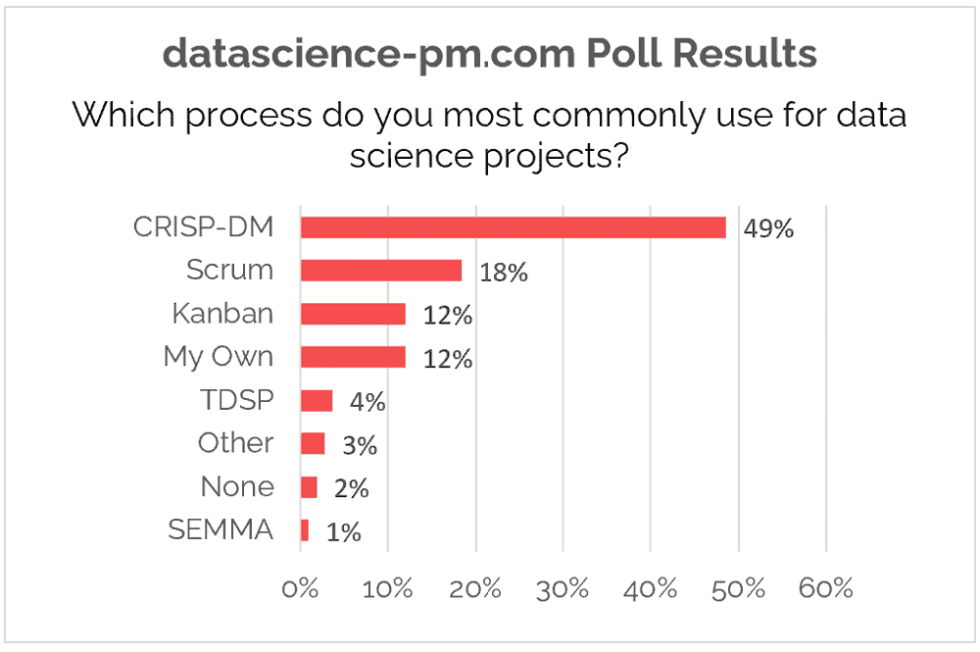
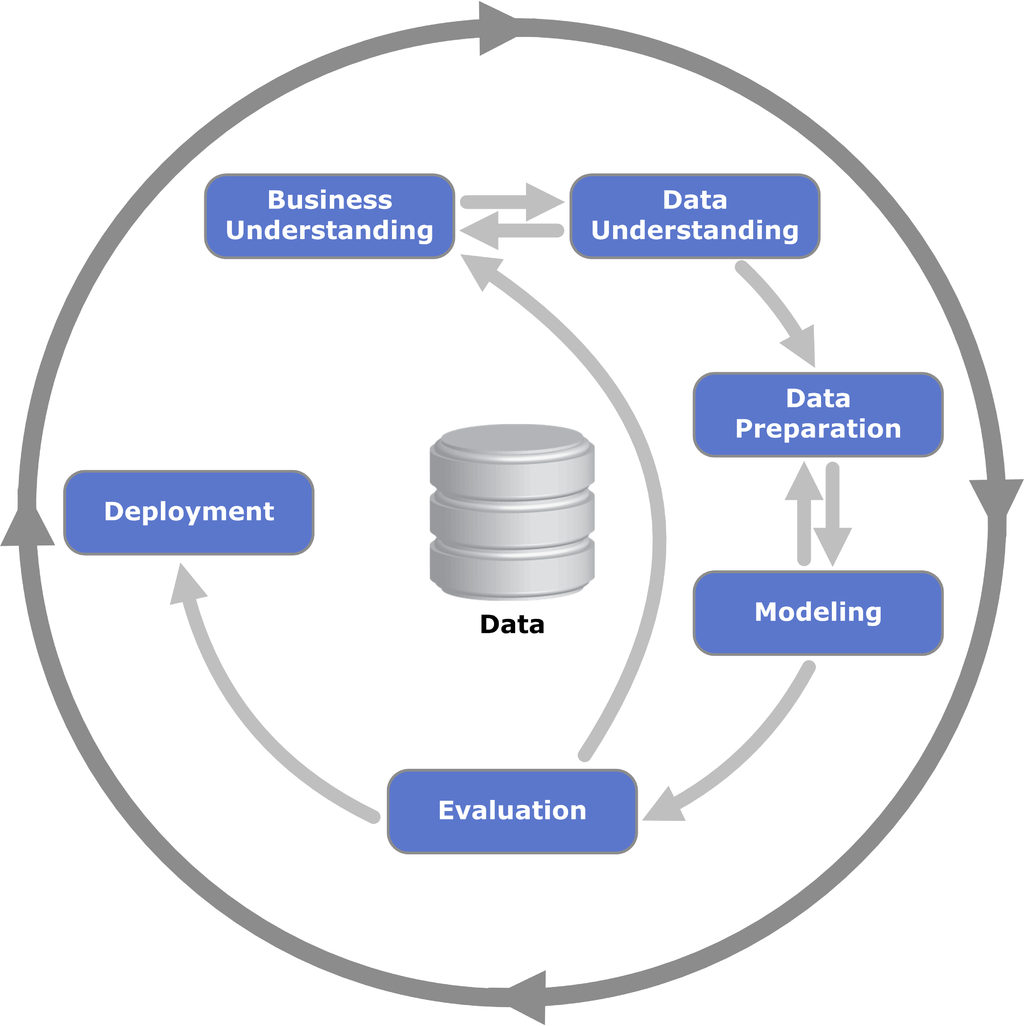
1.4 CRISP-DM 6 Phase
1.4.1 Business Understanding
사업 관점에서 프로젝트의 목적과 요구사항을 이해하기 위한 단계
- 사업 목적 설정
- 현황 평가
- Data Mining 목표 설정
- 프로젝트 계획 수립
1.4.2 Data Understanding
초기 통찰력, 숨겨진 정보에 대한 가설 등을 얻을 수 있도록 데이터를 수집하고 친숙해지는 단계
- 초기 데이터 수집
- 데이터 기술
- 데이터 탐색
- 데이터 품질 검증
1.4.3 Data Preparation
초기 원시 데이터로부터 최종 Dataset을 구하는 단계
- Select Data
- Clean Data
- Construct Data
- Integrate Data
- Format Data
1.4.4 Modeling
다양한 모델링 기법을 적용하여 모델을 구축하고 평가하는 단계
- 모델링 기법 선택
- 테스트 설계
- 모델 생성
- 모델 평가
1.4.5 Evaluation
모델이 사업 목적을 달성할지 평가하는 단계
- 결과 평가
- 프로세스 회고
- 다음 단계 결정
1.4.6 Deployment
모델을 적용하여 고객이 그 결과를 이용할 수 있도록 하는 단계
- 배포 계획
- 모니터링 및 유지보수 계획
- 최종 보고서 작성
- 프로젝트 회고
2. Python 데이터 분석 환경 구축
2.1. Conda / VS Code
https://www.anaconda.com/
C:\Users\User\anaconda3
C:\Users\User\anaconda3\Library
C:\Users\User\anaconda3\Scripts
conda --version
conda create -n py313 python=3.13
https://code.visualstudio.com/
VS Code Extension
- Python
- Python Debugger
- Jupyter2.2. 개발 환경 확인
test.ipynb
- Kernel 선택: Python Environments > py313
pip install -U ipykernel2.3. Python Packages
pypi.org
- 데이터 전처리: numpy, pandas
- 데이터 시각화: matplotlib, seaborn, folium, wordcloud
- 웹 크롤링: requests, beautifulsoup, selenium
- 시계열 데이터 분석: statsmodels
- 한글 처리: konlpy, kss, kiwi
- 이미지 처리: opencv-python
Package 설치 방법
pip install <package>
conda install [-c <channel>] <package>2.4. AI 시대에 Programming 학습
코드를 작성하는 데 그치지 않고, 시스템을 이해하고 책임지는 엔지니어가 되어야 한다.

기술과 비즈니스를 잇는 파트너가 되고자 합니다.