딥러닝을 통해 텍스트에 담긴 감성을 분석하는 방법이다. IMDB나 네이버 영화리뷰텍스트에 담긴 이용자의 감성이 긍정적인지 부정적인지 분류할 수 있는 딥러닝 모델을 구축하는 노드였다.
SNS 등에서 광범위한 분량의 텍스트를 쉽게 얻을 수 있다. 이 데이터에는 소비자들의 개인적, 감성적 반응이 담겨 있고, 실시간으로 트렌드를 빠르게 반영한다.
텍스트 감성분석 접근법은 크게 2가지로 나눌 수 있는데, 기계학습 기반 접근법과 감성사전 기반 접근법이다. 기계학습 기반 접근법의 경우, 데이터마다의 라벨이 부여되어 있고, 이를 학습시켜 예측하는 기법이다. 감성사전 기반 접근법의 경우, 미리 정의된 감성사전으로 데이터를 분석하기 때문에 라벨이 필요하지 않다. 대신 감성사전의 경우 분석 대상에 따라 단어의 감성 정도(점수)가 달라질 수 있다. 즉 같은 단어라도 대상에 따라 부정적일수도, 긍정적일 수도 있다는 의미이다. 또한 단순 긍부정을 넘어 그 원인이 되는 대상 속성 기반의 감성 분석이 어렵다.
텍스트 데이터는 순서가 중요하다. 이러한 순서를 워드 임베딩을 통해 전달하게 된다.
이런 식으로 말이다.
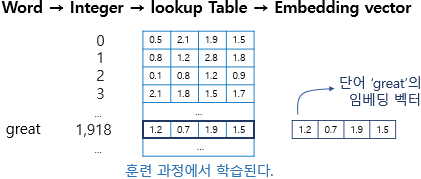
대략적으로 자연어처리의 과정을 살펴보면
-
단어를 쪼개고 그 단어마다 인덱스를 부여한다.
즉, 수치화를 시킨다. -
부여된 인덱스를 가지고 벡터를 만든다.
인덱스만으로는 단어의 의미를 전달하기 어렵기 때문에 이 과정이 필요하다.
이를 워드임베딩이라고 한다. -
임베딩 벡터를 가지고 머신/딥러닝 모델에 적용시켜 분석한다.
모델로 RNN, 1-D CNN을 이용했다.
또한 전이학습을 이용했다. 전이학습이란 특정 문제를 풀기 위해 학습한 모델을
다른 문제를 해결하는 데에 재사용하는 것을 의미한다.
사람도 무언가를 배우기 위해 제로베이스에서 시작하지 않고 자신이 지닌 이전의 경험과 지식을 동원하는 것처럼, 광범위한 데이터를 통해 미리 학습해 놓은 임베딩속에 녹아있는 의미, 문법 등의 부가적인 정보를 내가 만드려는 모델이 활용할 수 있는 피쳐로 활용하는 것이 훨씬 빠르고 정확하게 학습할 수 있는 방법이 된다.
그래서 이번 노드에선 사전에 학습된 Word2Vec 등의 임베딩 모델을 활용하여 학습을 진행했다. 영어 데이터의 경우에는 이 전이학습의 전후 차이가 극명했는데, 한국어 데이터의 경우, 영어데이터에 비해 단어의 수도 너무 적고, 전처리를 따로 해줘야했기 때문에 더 복잡했다. 전처리에서도 단어사전을 만드는 것 외에, 정규화 작업이 필요할 것 같다. 단어사전에 '.'이나 'ㅋㅋ', '...' 이런 쓸모없는 단어들이 너무 많았다.
노드는 하루안에 끝내려고 하지 말고 이것저것 시도해보는 시간이 필요할 것 같다.
