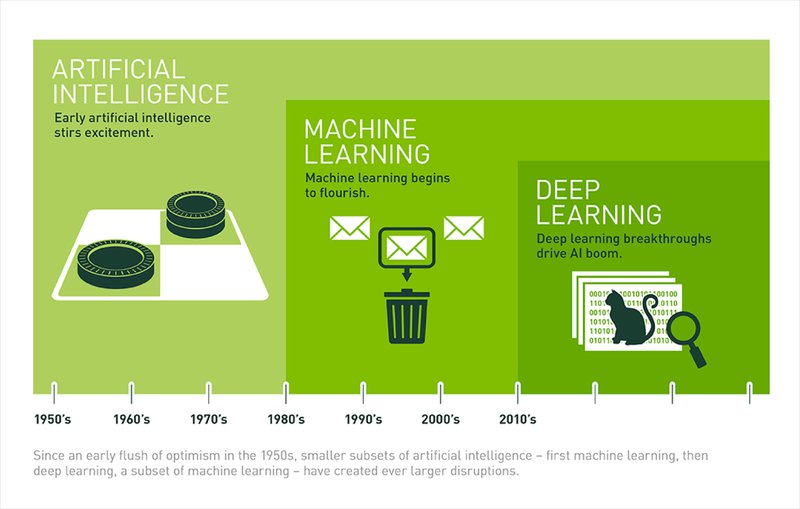
인공지능이란
사람이 직접 프로그래밍한 내용이 아니라 기계가 자체 규칙 시스템을 구축하는 과학을 의미한다.
그 중에서도 머신러닝은
데이터를 통해 스스로 학습하는 방법론을 말한다. 데이터를 분석하고, 데이터 안에 있는 패턴을 학습하며, 학습한 내용을 토대로 판단이나 예측을 한다.
딥러닝은
머신러닝의 하위 집합으로 볼 수 있는데, 학습하는 모델의 형태가 신경망인 방법론을 말한다.
조슈아 벤지오는 딥러닝을 다음과 같이 정의했다.
Deep learning is inspired by neural networks of the brain to build learning machines which discover rich and useful internal representations, computed as a composition of learned features and functions.
의역하면, '뇌의 신경구조로부터 영감을 받아 신경망 형태로 설계된 딥러닝의 목표는,
합성된 함수를 학습시켜서 풍부하면서도 내재적 표현을 찾아내는 machine을 구축하는 것이다.' 이다.
여기서 내재적 표현이란 무엇일까?
딥러닝에서는 표현(Representation)이라는 개념을 중요하게 여긴다.
예를 들어 아래와 같은 물체가 있다고 해보자.

이 꽃은 다양한 방법으로 '표현'될 수 있다.
-
분자형태로, 실제 데이터(꽃) 그 자체로의 표현이다.
-
이미지로도 표현할 수 있다. 컴퓨터에서 이미지를 표현할 때 특정 사이즈를 가지는 2차원 배열로 표현이 된다. 이 2차원 배열에서 색상 (RGB)이 더해지면 3차원의 배열로 표현이 된다.
-
표로 나타내는 방법도 있다. 해당 데이터가 가진 특징(featrue)들을 각 열마다 나타내고 어떤 값을 가지는 지 표현하는 것이다. 이렇게 표로 표현하는 방식은 해당 데이터의 어떤 특징을 표현할 것인지, 그 내용을 적합한 것들로 정의하는 과정이 필요하다. 꽃을 표현하는 데 머리카락의 색과 같은 열이 있으면 안되는 것처럼 말이다. 즉, 사람이 개입하게 된다.
-
마지막 표현 방법은 카테고리이다. 카테고리는 머신러닝에서 주로 '예측하고자 하는 값'으로 사용되기도 한다. 데이터를 카테고리로 표현하려면 '어떤 카테고리가 있는지'와 '그 중 어떤 카테고리에 속하는지'를 정하는 과정이 필요하다. 예를 들어 카테고리에 ['무궁화', '목련', '개나리']등이 있다고 했을 때, 위의 데이터는 '무궁화'라는 카테고리로 표현할 수 있는 것이다. 하지만 만일 카테고리가 ['강아지','고양이','여우']등이라면 이 중에서 선택해봤자 데이터를 표현하기 어렵다. 즉, 이 카테고리를 활용해 데이터를 표현할 때에도 사람의 개입이 강하게 들어간다.
이처럼, 분자형태와 이미지의 표현은 raw한 감각적인 표현이다. 그저 감각기관만으로 받아들일 수 있는 데이터이다.
반면, 표와 카테고리의 표현방식은 매우 추상적이고 내재적인 표현들이다. 사람의 개입이 강하게 들어가며, 그렇기 때문에 함축적으로 표현을 할 수 있게 된다.
위에서 언급한 조슈아의 딥러닝에 대한 정의를 보면,
결국 딥러닝의 궁극적인 목표는 학습된 함수를 이용하여 유용한 내재적 표현을 뽑아내는 것이다. 즉, 표나 카테고리와 같은 표현들을 사람의 개입 없이 딥러닝만으로 나타낼 수 있는 모델을 학습시키고자 하는 것이 목적이다.
딥러닝의 본질은 데이터의 표현을 학습하고, 데이터로부터 내재된 표현을 추출해내는 것이다.
