
앞에서는 SELECT문을 이용해서 데이터를 조회하는 것을 알아보았다.
이제 조회한 데이터에서 중복되는 부분을 제거하는 방법과 데이터를 정렬하는 법을 알아보자
1. 중복 데이터를 삭제하는 DISTINCT 🙂
일반적으로 SELECT문을 사용해서 데이터를 조회하면 데이터의 중복과 상관없이 해당 컬럼의 내용을 모두 조회한다. 이때 DISTINCT를 사용하면 불필요한 중복 데이터를 제거하여 확인하게 해준다.
DISTINCT : 구별하는, 별개의
(1) 문법
SELECT DISTINCT 컬럼명 from 테이블명;
기본적인 양식은 SELECT문 안에 사용된다.
(2) 사용 예시
DISTINCT를 사용한 경우와 아닌 경우를 비교해보면
DNO : 부서번호를 말함
1) DISTINCT를 사용하지 않은 경우 중복되는 데이터들이 모두 조회되는 것을 확인 할 수 있다.

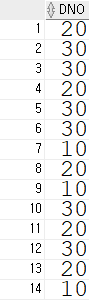
2) DISTINCT를 사용한 경우 중복된 데이터를 제외하고 조회된 것을 확인 할 수 있다.
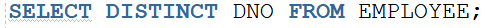

(3) 모든 데이터를 출력하는 ALL
ALL은 DISTINCT과 반대되는 개념으로 데이터 중복을 제거하지 않고 그대로 출력한다.
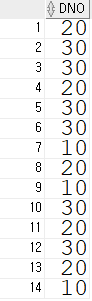
위의 사용 예시를 보면 단순히 SELECT문을 사용한 경우와 같은 결과를 볼 수 있을 것이다.
이것은 SELECT문에서 따로 중복 설정이 없을 경우에는 ALL을 기본적으로 사용하기 때문에 일반적인 SELECT문을 사용했을 때와 ALL을 추가 했을 때와 결과 값이 같은 것이다. 다시 말해 중복에 상관없이 모든 데이터를 출력하고 싶을때 사용하는 ALL은 생략 가능하다!
2. 데이터의 정렬을 도와주는 ORDER BY 😉
여러 데이터를 예쁘게 정렬하고 싶을 때 사용 할수 있는게 ORDER BY이다.
ORDER BY는 SELECT문을 작성할 때 사용할 수 있는 여러 절 중에서 가장 마지막에 사용한다.
(1) 문법
ORDER BY [컬럼명] [정렬옵션];
ORDER BY를 사용하여 정렬하고자 하는 컬럼명과 정렬옵션을 적어주면 된다.
대체로 정렬 옵션은 오름차순(asc)과 내림차순(desc)이 있다.
(2) 사용 예시
ORDER BY를 사용하여 사원의 급여를 조회하는 SELECT문을 적어보자
1) 오름차순 사용


ORDER BY를 사용하여 예쁘게 정렬된 데이터를 볼 수 있다.
2) 내림차순 사용


3) 정렬 옵션 동시 사용
더 나아가 해당 컬럼을 오름차순으로 정렬하지 내림차순으로 정렬하지 정하여 정렬 옵션을 동시에 사용 할 수도 있다.
예시로 사원 테이블의 모든 컬럼을 조회하되 급여는 오름차순, 부서 번호는 내림차순으로 정렬하여 보자

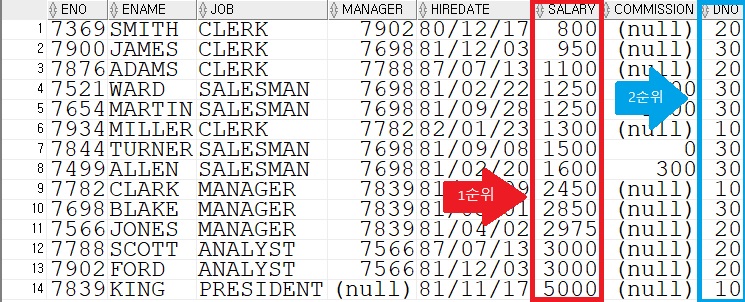
정렬 옵션을 동시에 사용 할 경우에는 ORDER BY절의 정렬 순서에 따라 우선 순위가 정해지고, 그에 따라 정렬이 되는 것을 알 수 있다. 예시에서는 급여가 부서번호 보다 먼저 명시되었으므로 급여가 우선 순위가 된 것이다. 그렇게 급여가 오름차순으로 정렬된 뒤에 부서번호가 내림차순으로 정렬된 것을 볼 수 있다.
(3) ORDER BY를 사용 할때 주의 할 점
ORDER BY절은 데이터를 정렬하여 보는 이의 가독성을 높게 한다는 장점이 있지만, 데이터 양이 많아지면 많아질수록 단순히 해당 데이터를 출력만 하는 것 보다 일정한 기준에 맞게 정렬하여 출력하는 경우가 시간이 더 오래 걸릴 수 있으므로 데이터 출력의 효율을 생각하면서 사용하는게 중요하다!
마무리 🤩
DISTINCT와 ORDER BY 모두 적절하게 사용한다면 데이터 조회에 보다 도움이되고 편리한 기능을 하는 것 같다. 하지만 무분별하게 사용하면 오히려 데이터 출력이 효율을 떨어뜨릴 수 있으므로 필요한 경우에만 사용 할 수 있도록 잘 조절 해야될 것 같다.
