[AI 미션코스 WEEK3]
RNN(Recurrent Neural Network)이
어떻게 순서 정보를 반영할 수 있는지, 내부 구조와 함께 동작 원리를 정리
- RNN은 입력을 ‘시퀀스 단위’
-> 즉 시간순서에 따라 처리하면서 이전 시간의 정보를 다음 시간 계산에 그대로 전달한다. - RNN = '현재 입력 + 이전 시점의 은닉상태'를 함께 사용해 출력과 다음 은닉상태를 만든다.
-> 이러한 구조로 인해 시간 순서가 모델 내부에 포함되게 된다.
[원리]
1) 은닉 상태 h가 “메모리” 역할을 한다.
-> 매 시점마다 이전 모든 입력의 압축된 정보를 은닉 벡터 ℎ 하나에 담고 계속 업데이트한다.
2) 동일한 가중치(W)를 시간 전체에서 반복 사용한다.
-> t=1, t=2, t=3 ... 일 때 모두 동일한 가중치를 가진다.
3) 시간축을 따라 Backpropagation Through Time 수행한다.
Dense 기반 모델과 RNN 모델의
예측 차이가 의미하는 바를 두 모델의 차이점과 함께 정리
Dense 기반 모델(MLP)
- 입력을 “한 번에” 받는다.
- 각각의 feature 간 순서 정보를 고려하지 않는다.
- 모든 입력을 독립된 변수처럼 취급하고, 순서/시간 흐름이 중요한 문제에 적합하지 않다.
RNN 기반 모델
- 입력을 순서대로 처리
- 이전 정보를 다음 예측에 반영
- 순서·문맥·시간 흐름을 모델 내부에 자연스럽게 저장한다.
예측 차이는 다음을 의미↓
① Dense 모델이 순서 의존적인 패턴을 반영하지 못했다.
② RNN 모델은 시계열·문맥·연속적인 패턴을 반영한다.
RNN의 한계에 대해서 설명
-
장기 의존성 문제
입력 시퀀스가 길어지면, 과거의 중요한 정보가 현재 시점까지 제대로 전달되지 못하고 소실되는 문제입니다.
이는 기울기 소실/폭주(Vanishing/Exploding Gradient) 현상으로 인해 발생합니다.
순환 신경망의 역전파 과정에서 가중치가 반복적으로 곱해지면서,
기울기가 매우 작아지거나(소실) / 매우 커져서(폭주) 학습이 제대로 이루어지지 않습니다. -
느린 학습 속도
RNN은 데이터를 한 번에 하나씩 순차적으로 처리하는 구조를 가집니다.
이 때문에 병렬 처리가 불가능하여, 시퀀스 길이가 길어질수록 학습 시간이 오래 걸립니다. -
깊은 신경망의 한계
입력 시퀀스의 길이에 따라 신경망이 깊어져서(시간 축이 길어져서),
얕은 신경망에서 발생하는 문제들이 그대로 적용될 수 있습니다.
LSTM(Long Short-Term Memory)이
어떻게 장기기억을 할 수 있는지, 동작 원리를 정리
- 기존 RNN이 가진 장기 의존성 문제로 인한 소실 때문에,
이를 해결하기 위해 LSTM이 고안됐다.
LSTM은 정보를 선택적으로 저장·삭제·출력 할 수 있는 ‘게이트(Gate)’ 구조를 도입했다.
1) 망각 게이트(Forget Gate): 이전 기억 중 어떤 것을 버릴지 결정.
오래된 정보 중 불필요한 것 제거 → 노이즈 누적 방지
2) 입력 게이트(Input Gate): 현재 입력을 cell state에 얼마나 반영할지 결정.
3) 출력 게이트(Output Gate): cell state의 어느 부분을 출력으로 내보낼지 결정.
Cell State: 정보가 사라지지 않고 흐르는 “기억 통로” 역할.
Forget Gate: 불필요 정보르 제거
Input Gate: 새로운 정보 선택적 저장
Output Gate: 필요한 만큼만 출력
Gradient vanishing: 문제를 구조적으로 완화
RNN_model과 LSTM_model을 예시로 직접 비교
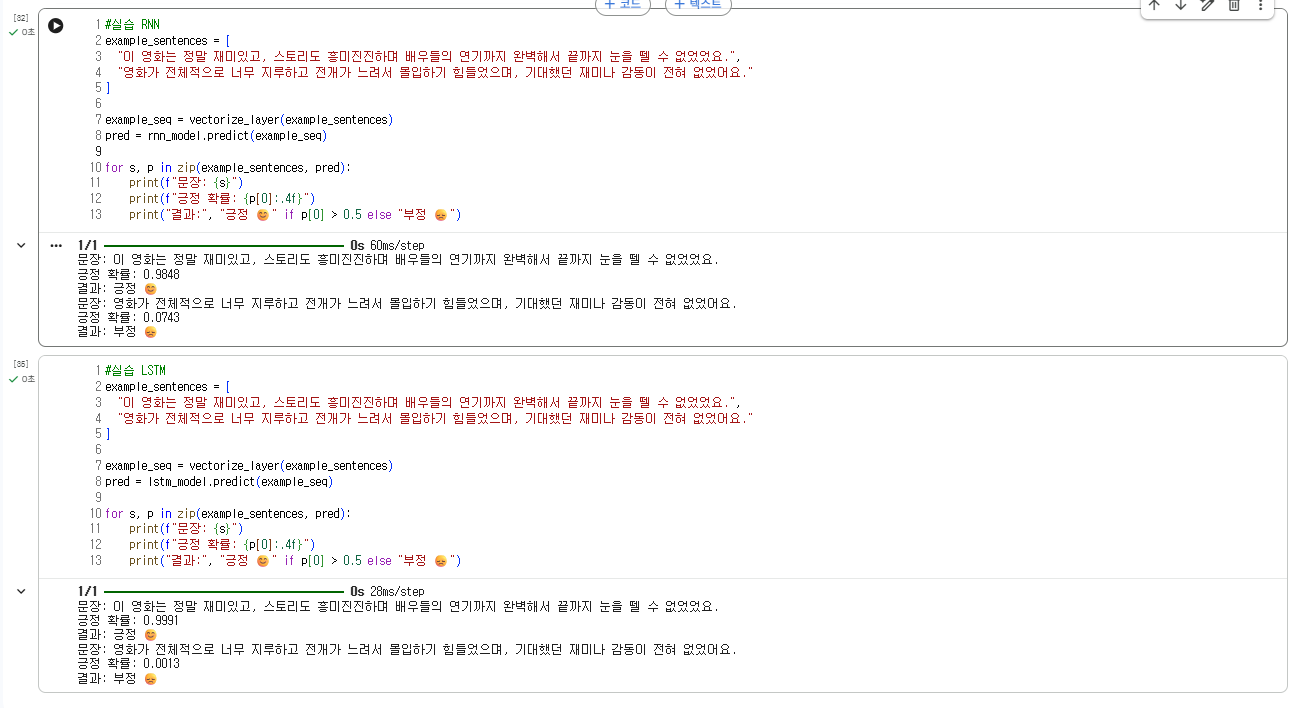
RNN 모델과 LSTM 모델의 예측 차이가 의미하는 바를
두 모델의 차이점과 함께 정리
- RNN(SimpleRNN)
- 입력을 순서대로 처리하지만, 오래된 정보를 저장하는 능력이 약함.
- '은닉 상태' 하나만 유지
타임스텝이 길어질수록 gradient vanishing(기울기 소실)이 심각함.
앞부분 정보가 뒷부분에 전달되지 않음.
RNN은 “단기적 패턴”에 강하고 “장기 기억”에는 취약함.
- LSTM(Long Short-Term Memory)
- RNN의 구조를 확장해 장기 기억력을 강화한 모델.
- '은닉 상태 + 셀 상태' 두 가지 상태를 가짐
Forget/Update/Output 게이트를 통해,
필요한 정보는 유지하고 필요 없는 정보는 지우는 구조.
LSTM은 “장기적 패턴”까지 안정적으로 학습할 수 있음.
[예측 결과가 다르게 나올 때 의미하는 바]
두 모델의 예측이 다르다는 것은, 해당 문제에 “장기 시퀀스 정보”가 중요한 영향을 미친다는 증거이다.
더 구체적으로 보면 다음 두 경우로 나눠서 해석할 수 있다.
1. LSTM이 훨씬 더 정확한 경우 → “장기 의존성이 중요한 문제”
2. 두 모델이 비슷한 예측한 경우 → “장기 시퀀스 정보가 중요하지 않다”
