3강 DKT Baseline, EDA idea
EDA idea
- timestamp 변수 이용해서 주말 혹은 요일 관련 전처리 생각해보기
- 각 id의 최근 10개 문제 풀이의 정답률을 하나의 feature로 추가하는 것 생각해보기
- 예측 시점에서 최근 10개 문제 풀이의 정답률을 넣어줘야함
- 각 id의 평균 문제 풀이 시간과 해당 문제 풀이 시간을 비교해서 넣어준다.
- (가설) 문제 풀이 시간이 평소보다 길어지면 오답률이 증가할 것이다
- (가설) 문제 풀이 시간이 평소보다 지나치게 빠르면 찍었다고 간주할 것이다.\
- 문제를 푼 시점에서의 사용자의 적중률 (이전 문제까지의 정답 비율)
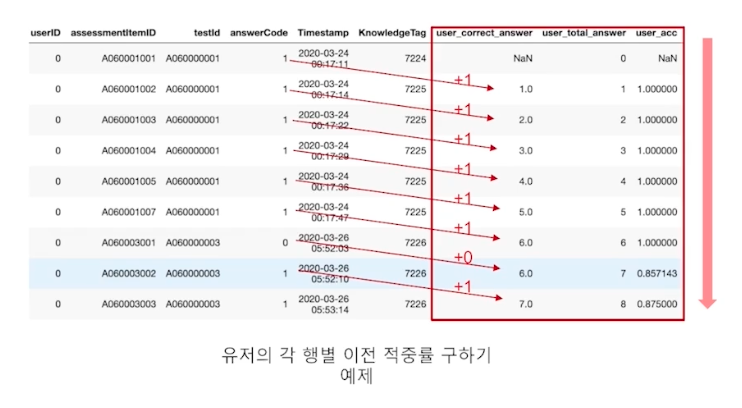
- 문제 및 시험, 태그 별 난이도 설정 : (문제를 맞힌 경우의 수 / 문제를 푼 경우의 수)
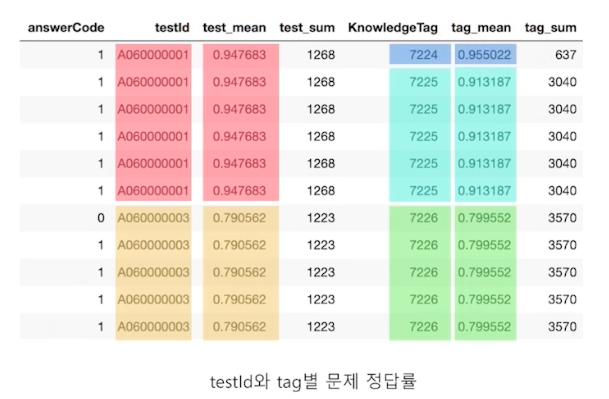
데이터 알아보기
- train_data.csv와 test_data.csv는 user_id 기준으로 split 되어 있다 (즉, train,test 동시에 존재하는 유저는 없다.)
- 우리는 train_data를 토대로 sequence data를 학습하여 test_data에 있는 각 유저들(744명)의 마지막 문제 풀이 값을 예측해야 한다.
- test_data에 각 유저들의 마지막 값은 현재 -1로 표시되어있는 상태이다
4강 Sequence Data 문제 정의에 맞는 Transformer Architecture 설계
Transformer는 bias가 없다고 고려하기 때문에 (CNN : locality, RNN : Sequence에 대한 bias 존재)
데이터가 많아야 좋은 효과를 보이며, 오히려 작은 단위 혹은 작은 규모일 때는 다른 딥러닝 모델이 더 성능이 좋을 수도 있다.
또한 모델의 구조가 아주 많은 양의 연산량을 요구하기도 하기 때문에 적절한 변환이 필요할 때가 많다.
따라서 캐글 대회 예시를 가져와서 어떠한 데이터일 때 어떤 방식으로 모델의 구조를 바꿔서 사용해 좋은 성능을 선보였는지에 대해 알아보자
Riiid
우리 대회랑 비슷한 데이터를 다룬다. (I-scream과 비슷한 데이터)
전체 interaction의 수가 1억개 (100M) : 굉장히 많다 → 트랜스포머에 유용
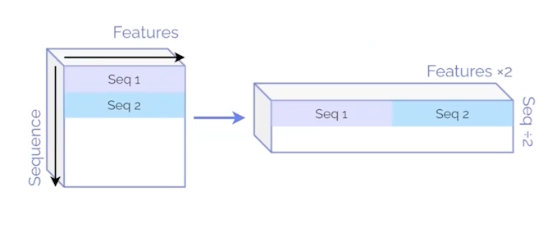
데이터가 상당히 많기 때문에 self-attention의 시간복잡도 O(n^2*d)를 줄이기 위한 아이디어로 Sequence의 길이인 n을 줄이고 임베딩 차원인 d를 늘리는 방법 고안
임베딩된 2개의 Sequence를 하나로 이어붙이면, Sequence의 개수가 반으로 줄고, 대신 임베딩 차원인 d는 두배로 늘어나게 된다.
5강 : 4강에서 살펴본 4개 대회 데이터 전처리 과정 따라가보기
전반적으로 transformer에 들어가는 embedding, input, output 차원들에 대해서 잘 이해할 수 있는 강의
CFG (configuration) 클래스를 만들어서 parameter 관리하면 편하다!
ex)
class CFG:
seed=7
batch_size=16
…
→ CFG.batch_size
- DMBS
category, continous 변수들 자동으로 임베딩 차원 맞춰주게끔 하는 자동화 코드
→ 현재 baseline 코드에서는 각 범주별 임베딩을 각자 짜주고, 나중에 concat
→ 수정할 코드에서는 강의 내용 11분~14분을 참고하여서 (변수 개수) * (임베딩 차원)으로 한 번에 임베딩 레이어 생성, 이후에 projection하여 반은 category, 반은 continous로 hidden layer 채우기
- Riiid
Sequence 데이터를 잘게 쪼개는 augmentation 이용하여서 전체 interaction 수가 10000개 였음에도 sequence 데이터를 9700개 가량 확보 (원래 10개의 interaction이 1개의 sequence를 이룬다고 하면, 1000개 정도 밖에 생성이 안됨)
sequence 길이를 줄이고 embedding 차원을 늘리면서 시간복잡도 해결
6강 : Riiid Winner Solution
Feature Engineering : Top Down vs Bottom Up
- Bottom Up : 데이터 기반으로 시각화해보고, 특징을 잡아서 FE를 진행해보자
- Top Down : 배경지식 기반으로 가설을 세우고 FE를 진행해보자
공통점 : CV와 LB가 같은 방향으로 흘러가는지 (에러 감소, 성능 개선) 확인 꼭 해봐야한다.
Feature가 숫자형인지, 범주형인지 구분해서 맞춰서 EDA 및 FE
ex) 사용자별 문항을 푸는 패턴을 파악해보자
-
정답을 하나로 찍거나
-
문항을 연속으로 잘 맞춘다거나
- 정답률 추이를 MA로 확인
-
이전에 풀었던 문항은 유독 잘 맞춘다거나
- 같은 시험지내에서 같은 태그의 문항을 더 잘 풀것이다
-
원래 풀던 평균 시간 보다 더 오래걸리거나 빠를 경우에는?
- ex) 토익 듣기를 놓치면 푸는 시간이 더 오래걸림 → 오답률 상승
- 해당 문항을 맞춘 학생들의 평균 풀이 시간 vs 해당 문항을 틀린 학생들의 평균 풀이 시간 : EDA 확인해보기
-
각 문항의 정답률을 하나의 feature로 넣어보자 (쉬운 문항이면 대부분 잘 풀 수도 있음)
문제의 난이도를 이용해 ELO, IRT(Item Response Theory) 적용하기
0.766의 AUC 달성할 정도로 꽤 괜찮은 성능 → 나중에 앙상블 기법에 넣어줘도 될 듯?

1등 솔루션
- LGBM, DNN의 단점 : FE를 통해 많은 Feature와 유의미한 Feature를 찾아낼 수 있어야만 한다.
- Transformer의 단점 : 아주 많은양의 데이터가 필요하며, sequence길이의 제곱에 비례해 시간 복잡도가 있기 때문에, 사용하기엔 부담스러운 점이 있다.
한 유저가 1,2 번 단점을 해결한 방법으로 1등 차지
-
다수의 Feature를 사용하지 않았다.
모델에 다양한 시간을 투자, Transformer Encoder에 Feature extraction을 맡긴다.
-
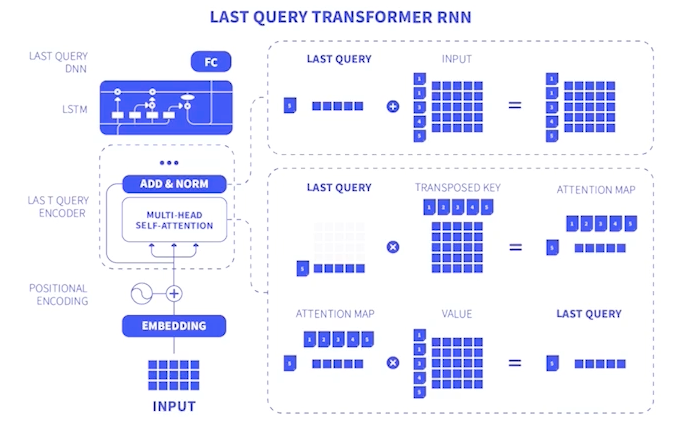
Transformer에서, 시간 복잡도를 낮추기 위해서 마지막 Query만 사용한다.
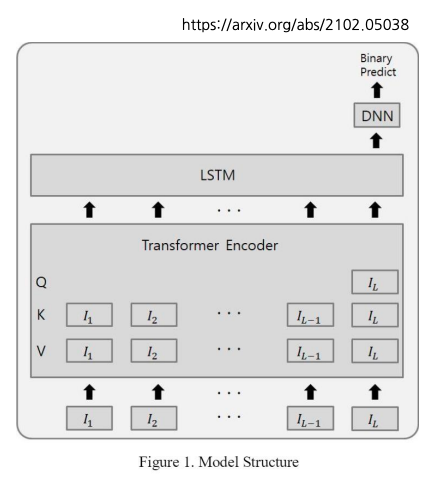
마지막 Query만 사용해서 계산하기 때문에 시간 복잡도를 낮출 수 있다.
⇒ Q행렬의 차원 : (1,d) ⇒ 시간 복잡도 O(Ld) (선형으로 바뀜) ⇒ 많은 Sequence (L) 사용 가능해짐
⇒ 많은 Sequence 사용으로 성능을 높였다.
7강:
위 자료는 부스트캠프 AI Tech 4기 강의를 참고하여 만들었습니다.
