VGGNet/ Very Deep Convolutional Networks for Large-Scale Image Recognition(1)
이번에 소개할 논문은 Very Deep Convolutional Networks for Large-Scale Image Recognition이라는 논문입니다. ILSVRC에서 이전 우승 모델들의 성능보다 훨씬 좋은 성능으로 2014년 준우승을 차지한 모델로 VGGNet이라 불립니다. 이 논문의 핵심은 Deep depth(CNN 깊이)와 Small Receptive Filed(3x3 Conv filters)를 이용한 것이 주요 아이디어입니다.
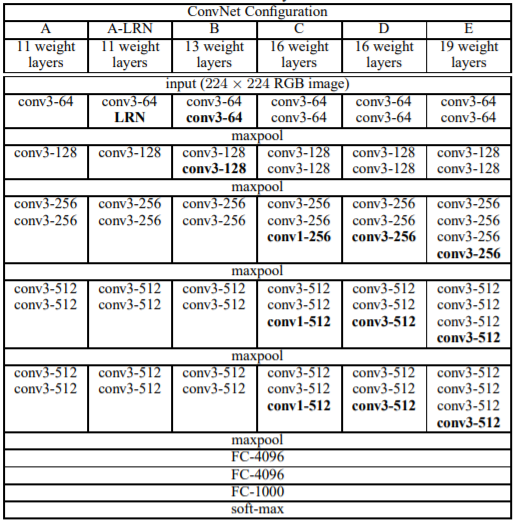 VGGNet은 깊은 네트워크 구조를 가지고 있습니다. VGGNet은 총 16개의 계층(layer)로 구성되어 있으며, 이를 VGG16이라고도 합니다. 각 계층은 컨볼루션 계층과 풀링 계층으로 이루어져 있습니다. 컨볼루션 계층은 입력 이미지에 커널을 적용하여 특징을 추출하는 역할을 합니다. VGGNet에서는 주로 3x3 크기의 작은 필터를 사용하여 컨볼루션 연산을 수행합니다. 이 작은 필터를 여러 번 쌓아서 깊은 네트워크를 구성하면서, 이미지의 다양한 특징을 효과적으로 학습할 수 있습니다. 풀링 계층은 컨볼루션 계층의 출력을 다운샘플링하여 공간적인 크기를 줄이는 역할을 합니다. VGGNet에서는 주로 2x2 크기의 풀링 윈도우와 스트라이드 2를 사용하여 픽셀을 절반으로 줄입니다.
VGGNet은 깊은 네트워크 구조를 가지고 있습니다. VGGNet은 총 16개의 계층(layer)로 구성되어 있으며, 이를 VGG16이라고도 합니다. 각 계층은 컨볼루션 계층과 풀링 계층으로 이루어져 있습니다. 컨볼루션 계층은 입력 이미지에 커널을 적용하여 특징을 추출하는 역할을 합니다. VGGNet에서는 주로 3x3 크기의 작은 필터를 사용하여 컨볼루션 연산을 수행합니다. 이 작은 필터를 여러 번 쌓아서 깊은 네트워크를 구성하면서, 이미지의 다양한 특징을 효과적으로 학습할 수 있습니다. 풀링 계층은 컨볼루션 계층의 출력을 다운샘플링하여 공간적인 크기를 줄이는 역할을 합니다. VGGNet에서는 주로 2x2 크기의 풀링 윈도우와 스트라이드 2를 사용하여 픽셀을 절반으로 줄입니다.
VGGNet은 16개의 계층으로 구성된 VGG16 모델과 19개의 계층으로 구성된 VGG19 모델로 나뉩니다. VGG16은 13개의 컨볼루션 계층과 3개의 완전 연결 계층으로 이루어져 있으며, VGG19는 16개의 컨볼루션 계층과 3개의 완전 연결 계층으로 이루어져 있습니다. 모델의 깊이가 깊어질수록 더 많은 계층을 통해 이미지의 특징을 추출할 수 있어서 보다 복잡한 패턴을 학습할 수 있습니다. 그러나 깊은 모델은 많은 파라미터를 가지고 있기 때문에 훈련에 많은 계산량과 데이터가 필요합니다.
