VGGNet/ Very Deep Convolutional Networks for Large-Scale Image Recognition(2)
지난 블로그에 이어 VGGNet 논문 리뷰 마무리해보도록 하겠습니다.
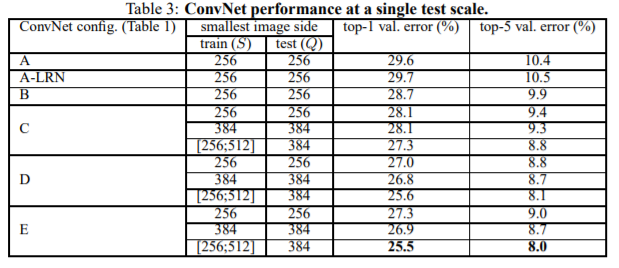 VGGNet은 ImageNet Large Scale Visual Recognition Challenge (ILSVRC)에서 우수한 성적을 거두었습니다. ILSVRC는 대규모 이미지 데이터셋인 ImageNet을 기반으로 한 컴퓨터 비전 대회로, 이미지 분류 작업을 포함한 여러 가지 작업이 있습니다. VGGNet은 2014년 ILSVRC에서 분류 작업(classification task)에서 2위를 차지하며, 이후의 연구에서도 여러 작업에서 좋은 성능을 보여주었습니다. VGGNet은 깊은 모델 구조와 작은 필터 크기를 통해 다양한 이미지 특징을 잘 학습할 수 있어서 높은 정확도를 달성할 수 있습니다. 또한, VGGNet은 다른 CNN 모델과의 비교에서도 일반적으로 좋은 성능을 보여주어 널리 사용되고 있습니다.
VGGNet은 ImageNet Large Scale Visual Recognition Challenge (ILSVRC)에서 우수한 성적을 거두었습니다. ILSVRC는 대규모 이미지 데이터셋인 ImageNet을 기반으로 한 컴퓨터 비전 대회로, 이미지 분류 작업을 포함한 여러 가지 작업이 있습니다. VGGNet은 2014년 ILSVRC에서 분류 작업(classification task)에서 2위를 차지하며, 이후의 연구에서도 여러 작업에서 좋은 성능을 보여주었습니다. VGGNet은 깊은 모델 구조와 작은 필터 크기를 통해 다양한 이미지 특징을 잘 학습할 수 있어서 높은 정확도를 달성할 수 있습니다. 또한, VGGNet은 다른 CNN 모델과의 비교에서도 일반적으로 좋은 성능을 보여주어 널리 사용되고 있습니다.
결론적으로, VGGNet의 핵심 아이디어는 깊은 신경망을 구성함으로써 이미지의 특징을 더 잘 추출할 수 있다는 점입니다. VGGNet은 이를 위해 작은 3x3 크기의 필터를 사용하여 컨볼루션을 진행하는 전략을 채택합니다. 이 방식은 두 가지 이점을 가지고 있습니다. 첫째, 여러 개의 작은 필터를 쌓음으로써 큰 필터를 사용한 것과 동일한 receptive field를 가질 수 있습니다. 예를 들어, 3개의 3x3 필터를 적용하면 7x7 필터를 적용한 것과 동일한 receptive field를 갖는 것입니다. 둘째, 작은 필터를 사용하면 파라미터 수가 큰 필터보다 적어지기 때문에 모델의 크기와 계산량을 줄일 수 있습니다.
추가적으로 설명하자면 VGGNet은 VGG16과 VGG19로 구성된 기본 모델 외에도 몇 가지 변형 모델이 있습니다. 이러한 변형 모델은 기본 모델의 구조를 수정하거나 추가적인 기법을 도입하여 성능을 개선한 것입니다. 예를 들어, VGGNet에는 Batch Normalization, Dropout, Fully Connected Layer 등의 기법을 추가한 모델이 있습니다. Batch Normalization은 각 계층의 입력을 정규화하여 학습을 안정화시키고, Dropout은 일부 뉴런을 임의로 제거하여 과적합을 방지합니다. Fully Connected Layer는 최종 분류를 위한 완전히 연결된 계층입니다. 또한, VGGNet을 기반으로 다른 작업에 맞게 수정된 모델들도 있습니다. 예를 들어, VGGFace는 얼굴 인식 작업을 위해 VGGNet을 변형한 모델입니다.
