pyplot 방식과 객체지향 API 방식
그래프 그리는 방법에는 두 가지가 있는데, matplotlib.pyplot에 있는 함수를 사용하는 pyplot 방식, 명시적으로 피겨 객체와 서브플롯 객체를 만들고 이 객체의 메서드를 사용하는 객체지향 API 방식이다.
# 그래프 잘 보이도록 해상도 높이기.
import matplotlib.pyplot as plt
plt.rcParams['figure.dpi'] = 100pyplot 방식으로 그래프 그리기
matplotlib.pyplot에 있는 함수를 사용하면 함수들이 하나의 피겨 객체에 대한 상태를 공유한다. 즉, 다응ㅁ과 같이 간단한 선 그래프를 그리면 plot() 함수와 title() 함수는 동일한 피겨 객체에 적용된다. plot() 함수에 리스트 형태로 데이터를 전달하고, title() 함수에는 그래프 제목을 넣어 그려보자.
plt.plot([1, 4, 9, 16])
plt.title('simple line graph')
plt.show()
>>>
plot() 함수에 전달한 리스트의 인덱스가 x축, 원소가 y축인 선 그래프가 그려진다. 제목은 그래프 상단에 출력됐다!
+ plot() 함수에 하나의 리스트만 전달해도 그래프가 그려지나요?
일반적으로 plot() 함수를 사용할 때 x축과 y축 값을 리스트나 배열로 전달한다. 만약 하나의 리스트만 전달한다면 plot() 함수는 원소를 y축의 값이라고 인식하고 이 리스트의 인덱스를 x축의 값으로 사용한다. 따라서 앞의 예의 경우 [1, 4, 9, 16]는 y축 값이며, x축의 값은 [0, 1, 2, 3]이 된다.
객체지향 API 방식으로 그래프 그리기
동일한 그래프를 피겨 객체와 Axes 객체를 사용하는 객체지향 API 방식으로 다시 그리면 다음과 같다.
fig, ax = plt.subplots()
ax.plot([1, 4, 9, 16])
ax.set_title('simple line graph')
fig.show()
>>>
pyplot 방식으로 그렸을 때처럼 똑같이 그려졌다. 이처럼 두 가지 방식 중 어떤 것을 사용해도 괜찮다. 하지만 복잡한 그래프를 그리는 경우에는 객체지향 방식을 사용하는 것이 좋다! 톡히 하나의 피겨에 여러 개의 서브 플롯을 추가하는 경우가 그렇다.
이 책에서는 두 방식을 혼용하여 사용한다. 간단한 경우에는 pyplot 방식의 함수를 사용하고, 피겨 객체의 설정을 바꾸거나 서브플롯을 추가하는 경우에는 객체지향 API를 사용한다.
그래프에 한글 출력하기
객체지향 API로 본격적으로 그래프를 꾸며보기 전에 그래프 설정 하나를 더 배우자!
앞서 그래프를 그릴 때 그래프 제목이나 축 이름을 추가했다. 그런데 한글로 작성했을 때 문자가 제대로 출력되지 않아 영문으로만 작성했다. 맷플롯립의 기본 폰트가 한글을 지원하지 않기 떄문이다. 이제 한글 텍스트를 제대로 표시하는 방법을 알아보자!
우선 https://hangeul.naver.com/font에서 '나눔바른고딕' 폰트를 설치한다.
# 노트북이 코랩에서 실행 중인지 체크합니다.
import sys
if 'google.colab' in sys.modules:
!echo 'debconf debconf/frontend select Noninteractive' | debconf-set-selections
# 나눔 폰트를 설치합니다.
!sudo apt-get -qq -y install fonts-nanum
import matplotlib.font_manager as fm
font_files = fm.findSystemFonts(fontpaths=['/usr/share/fonts/truetype/nanum'])
for fpath in font_files:
fm.fontManager.addfont(fpath)
>>> Selecting previously unselected package fonts-nanum.
(Reading database ... 120874 files and directories currently installed.)
Preparing to unpack .../fonts-nanum_20200506-1_all.deb ...
Unpacking fonts-nanum (20200506-1) ...
Setting up fonts-nanum (20200506-1) ...
Processing triggers for fontconfig (2.13.1-4.2ubuntu5) ...나눔 폰트 설치 후 다시 맷플롯립을 임포트하고 DPI 기본값을 변경해주자.
import matplotlib.pyplot as plt
plt.rcParams['figure.dpi'] = 100폰트 지정하기(1): font.family 속성
맷플롯립의 기본 폰트는 영문 sans-serif 폰트이다. rcParams 객체의 'font_family' 속성에 저장되어 있다.
plt.rcParams['font.family']
>>> ['sans-serif']기본 폰트를 나눔고딕 폰트를 의미하는 'NanumGothic'으로 바꾸려면 다음과 같이 작성한다.
# 나눔고딕 폰트를 사용합니다.
plt.rcParams['font.family'] = 'NanumGothic'이렇게 rcParams 객체를 사용해 맷플롯립의 기본값을 바꿀 수 있지만, 맷플롯립에서 제공하는 rc() 함수를 사용하여 설정을 바꿀 수도 있다.
폰트 지정하기(2): rc() 함수
이번에는 나눔바른고딕 폰트인 'NanumBarunGothic'으로 바꾸어 보자! rc() 함수의 첫 번째 매개변수에는 설정할 그룹을 지정한다. 'font.family'의 경우 font가 그룹이고 family는 그룹의 하위 속성이다. 따라서 rc() 함수 첫 번째 매개변수에는 그룹인 'font'를 지정하고 두 번째 매개변수에는 그룹 하위 속성을 지정한다. 이때 family는 일반 키워드 매개변수처럼 사용하면 된다.
# 위와 동일하지만 이번에는 나눔바른고딕 폰트로 설정합니다.
plt.rc('font', family='NanumBarunGothic')rc() 함수를 사용하면 한 그룹 내의 여러 설정을 동시에 지정할 수 있다. 예를 들어 폰트 패밀리와 폰트 크기를 다음처럼 동시에 설정할 수 있다.
plt.rc('font', family='NanumBarunGothic', size=11)
# 바뀐 내용은 rcParams 객체로 다시 확인 가능.
print(plt.rcParams['font.family'], plt.rcParams['font.size'])
>>> ['NanumBarunGothic'] 11.0+ 맷플롯립에서 사용할 수 있는 폰트의 전체 목록을 알려면 어떻게 해야하나요?
맷플롯립은 시스템에 설치된 폰트를 자동으로 감지하여 사용한다. 다음처럼 findSystemFonts() 함수를 사용하면 맷플롯립이 찾은 폰트 목록을 볼 수 있다.
from matplotlib.font_manager import findSystemFonts
findSystemFonts()좋다!! 한글 폰트 설정 방법 알아 보았으니 앞에서 출력해 본 간단한 그래프를 그려 그래프 제목을 한글로 출력해보자.
plt.plot([1, 4, 9, 16])
plt.title('간단한 선 그래프')
plt.show()
>>>
성공했다!!!!
출판사별 발행 도서 개수 산점도 그리기
ns_book7 데이터프레임을 사용해서 출판사별 도서가 어떤 연도에 많이 발행되었는지 산점도를 그려보자. ns_book7.csv 파일을 구글 드라이브에서 다운로드하고 판다스 데이터프레임으로 불러온다.
import gdown
gdown.download('https://bit.ly/3pK7iuu', 'ns_book7.csv', quiet=False)
import pandas as pd
ns_book7 = pd.read_csv('ns_book7.csv', low_memory=False)
ns_book7.head()
>>> 번호 도서명 저자 출판사 발행년도 ISBN 세트 ISBN 부가기호 권 주제분류번호 도서권수 대출건수 등록일자
0 1 인공지능과 흙 김동훈 지음 민음사 2021 9788937444319 NaN NaN NaN NaN 1 0 2021-03-19
1 2 가짜 행복 권하는 사회 김태형 지음 갈매나무 2021 9791190123969 NaN NaN NaN NaN 1 0 2021-03-19
2 3 나도 한 문장 잘 쓰면 바랄 게 없겠네 김선영 지음 블랙피쉬 2021 9788968332982 NaN NaN NaN NaN 1 0 2021-03-19
3 4 예루살렘 해변 이도 게펜 지음, 임재희 옮김 문학세계사 2021 9788970759906 NaN NaN NaN NaN 1 0 2021-03-19
4 5 김성곤의 중국한시기행 : 장강·황하 편 김성곤 지음 김영사 2021 9788934990833 NaN NaN NaN NaN 1 0 2021-03-19연도를 기준으로 출판사별 발행 도서 개수를 표현해야 하므로 x축에는 '발행년도', y축에는 '출판사'를 표시해야 한다. 이 데이터에 있는 전체 출판사 수는 2만 개가 넘기 때문에 그래프에 모두 표현하기는 어려우니 발행 도서가 많은 상위 30개 출판사의 데이터 중 일부를 사용하자.
고유한 출판사 목록 만들기
value_counts() 메서드를 사용해 고유한 출판사 목록을 만든다. 이 메서드는 카운트가 높은 순으로 결과를 내림차순 정렬한다! 상위 30개 출판사를 선택하려면 다음처럼 슬라이스 연산자를 사용할 수 있다.
top30_pubs = ns_book7['출판사'].value_counts()[:30] # [:30] : 마지막 인덱스는 범위에 포함하지 않으므로 가져오려는 인덱스보다 하나 더 크게 지정.
top30_pubs
>>> 문학동네 4410
민음사 3349
김영사 3246
웅진씽크빅 3227
시공사 2685
창비 2469
문학과지성사 2064
위즈덤하우스 1981
학지사 1877
한울 1553
한국학술정보 1496
열린책들 1491
살림출판사 1479
한길사 1460
博英社 1458
커뮤니케이션북스 1445
지식을만드는지식 1390
자음과모음 1364
비룡소 1331
랜덤하우스코리아 1314
넥서스 1310
황금가지 1101
길벗 1094
시그마프레스 1063
현암사 1054
다산북스 1046
집문당 1038
책세상 1037
한국문화사 1028
북이십일 21세기북스 1026
Name: 출판사, dtype: int64이제 ns_book7 데이터프레임에서 상위 30개 출판사에 해당하는 행을 표시하는 불리언 인덱스를 만들어보자. 어떤 행의 출판사가 top30_pubs 목록에 있는 출판사 중 하나에 해당하는지 검사하려면 isin() 메서드를 사용할 수 있다.
top30_pubs_idx = ns_book7['출판사'].isin(top30_pubs.index)
# 'isin(top30_pubs.index)' : 상위 30개에 해당하는 출판사는 True, 아닌 출판사는 False로 반환.
top30_pubs_idx
>>>0 True
1 False
2 False
3 False
4 True
...
376765 False
376766 False
376767 True
376768 False
376769 False
Name: 출판사, Length: 376770, dtype: bool원본 데이터프레임의 행 길이와 동일한 불리언 인덱스를 만들었다. 비교하려는 출판사 목록은 top30_pubs 객체의 인덱스에 들어 있기 때문에 isin() 메서드에 top30_pubs.index를 전달했다.
상위 30개 출판사의 발행 도서 개수가 몇 개인지 세어보자! 시리즈 객체에서 sum() 메서드를 호출하면 값을 모두 더한다. 값이 불리언일 경우 True는 1, False는 0으로 처리되므로 불리언 배열에서 True인 원소의 개수를 헤아리는데 사용할 수 있다.
top30_pubs_idx.sum()
>>> 51886상위 30개 출판사의 데이터가 5만 개가 넘는다!!
산점도로 그리기에는 여전히 많기 때문에 이 중에 1,000개만 선택해보자. 데이터프레임의 행을 무작위로 선택하려면 sample() 메서드를 사용한다.
그리고 random_state 매개변수에 임의의 숫자를 적는다. 이 매개변수는 4장에서 본 넘파이의 seed() 함수와 비슷한 역할이다. 따라서 예시와 동일한 값을 전달하면 항상 같은 결과를 얻을 수 있다.
ns_book8 = ns_book7[top30_pubs_idx].sample(1000, random_state=42)
ns_book8.head()
>>> 번호 도서명 저자 출판사 발행년도 ISBN 세트 ISBN 부가기호 권 주제분류번호 도서권수 대출건수 등록일자
141760 155786 제갈량 문집 제갈량 지음 ;조영래 옮김 지식을만드는지식 2012 9788966805785 NaN 0 10 808 1 2 2013-04-10
249855 268595 존 레넌을 찾아서 토니 파슨스 지음;이은정 옮김 시공사 2007 9788952750419 NaN 0 NaN 843 1 18 2007-12-14
129347 142802 요리사 & 쇼핑호스트 :생활과학 계열·예체능 계열 와이즈멘토 글 ;김성희 그림 김영사 2013 9788934959854 9788934959717 7 14 321.55 1 3 2013-12-09
349194 371975 임정섭의 글쓰기 훈련소 임정섭 지음 다산북스 2017 9791130614472 NaN NaN NaN NaN 1 0 1970-01-01
46734 51748 초한지 :이문열의 史記 이야기 지은이: 이문열 민음사 2017 9788937481659 9788937481581 0 7 813.6 1 9 2018-07-02산점도 그리기
x축에는 '발행년도' 열, y축에는 '출판사' 열을 지정한다. 조금 크게 그리기 위해 subplots() 함수로 피겨의 크기를 (10, 8)로 지정한다. 이렇게 하면 자연스럽게 객체지향 API를 사용하게 된다.
fig, ax = plt.subplots(figsize=(10, 8))
ax.scatter(ns_book8['발행년도'], ns_book8['출판사'])
ax.set_title('출판사별 발행도서')
fig.show()
>>>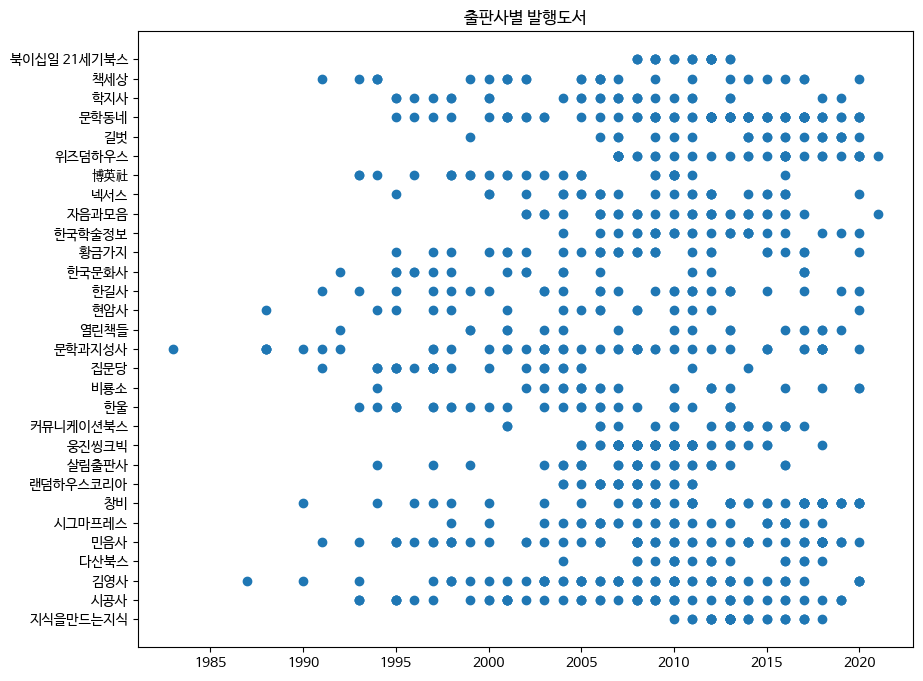
해당 연도에 어떤 출판사의 도서가 발행되었는지 알려 주는 산점도가 출력되었다! 그러나 어떤 해에 얼마나 많은 도서가 대출되었는지는 알 수 없으니 이를 개선해보자!!
값에 따라 마커 크기를 다르게 나타내기
scatter() 함수는 마커의 크기를 지정할 수 있는 s 매개변수를 제공한다. 선 그래프와 산점도의 마커 크기는 rcParams['lines.markersize']로 지정하며 기본값은 6이다. s 매개변수의 기본값을 rcParams['lines.markersize']의 제곱을 사용한다.
s 매개변수 값을 하나의 실수로 바꾸면 산점도의 모든 마커 크기가 동일하게 바뀐다. 하지만 입력 데이터와 동일한 길이의 배열을 지정하면 각 데이터마다 마커의 크기가 다른 산점도를 그릴 수 있다.
fig, ax = plt.subplots(figsize=(10, 8))
ax.scatter(ns_book8['발행년도'], ns_book8['출판사'], s=ns_book8['대출건수'])
ax.set_title('출판사별 발행도서')
fig.show()
>>>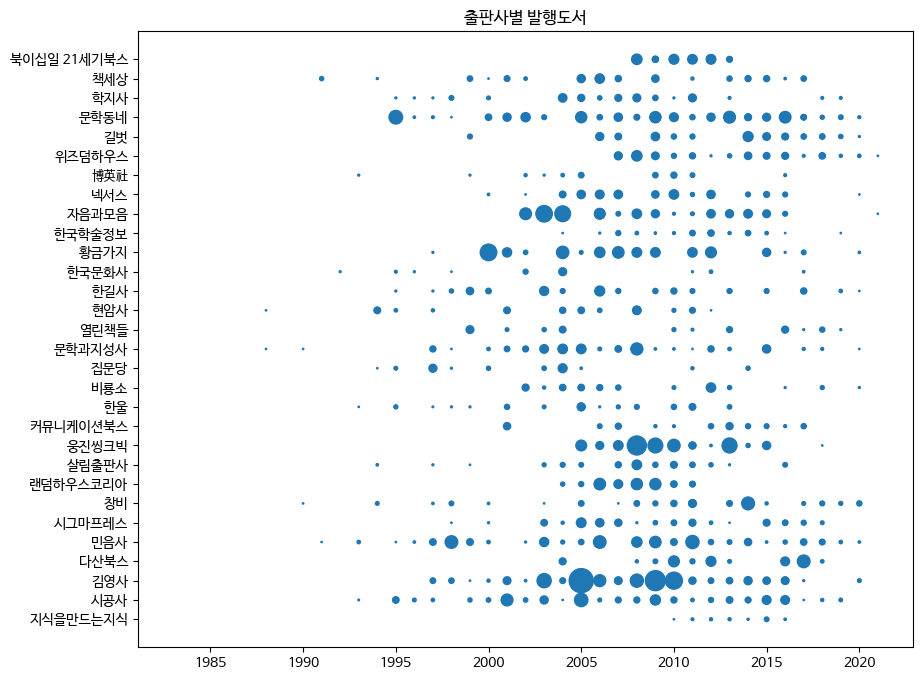
이 산점도는 각 출판사의 연도별 도서 발행 여부뿐만 아니라 얼마나 많은 대출을 기록했는지도 보여준다. '자음과모음' 출판사의 경우 2000년대 초반에 발행한 책의 대출건수가 높다. '김영사'의 경우 2005년과 2010년에 발행한 도서의 대출건수가 높다.
마커 꾸미기
① 투명도 조절하기
alpha 매개변수는 마커의 투명도를 결정한다. 마커의 진하기에 따라 해당 연도에 출간된 도서가 얼마나 많은지 대략 가늠할 수 있다. 출간 도서가 많은 경우 마커가 많이 겹치기 때문에 alpha 매개변수를 낮게 설정해도 상대적으로 진하게 나타날 것이다.
② 마커 테두리 색 바꾸기
edgecolor 매개변수는 마커 테두리의 색을 결정한다. 이 매개변수의 기본값은 마커의 색을 의미하는 'face'이다. 마커 테두리를 그리면 여러 개의 마커가 겹칠 때 경계를 구분할 수 있어 유용하다. 여기서는 검은색 의미하는 'k'로 지정.
③ 마커 테두리 선 두께 바꾸기
linewidths 매개변수는 마커 테두리 선의 두께를 결정하며 기본값은 1.5이다. 여기서는 0.5로 지정하여 조금 더 테두리를 얇게 그리자.
④ 산점도 색 바꾸기
c 매개변수는 산점도의 색을 지정한다. s 매개변수와 마찬가지로 c 매개변수에 데이터 개수와 동일한 길이의 배열을 전달하면 각 데ㅣ터를 다른 색깔로 그릴 수 있다. 예를 들어 c 매개변수에 '대출건수' 열을 전달하면 큰 값은 밝은 노랑색, 낮은 값은 진한 녹색으로 그린다.
추가로 s 매개변수는 대출건수에 2를 곱한 값으로 수정하여 마커의 크기가 눈에 더 잘 띄도록 한다.
fig, ax = plt.subplots(figsize=(10, 8))
ax.scatter(ns_book8['발행년도'], ns_book8['출판사'],
linewidths=0.5, edgecolors='k', alpha=0.3,
s=ns_book8['대출건수']*2, c=ns_book8['대출건수'])
ax.set_title('출판사별 발행도서')
fig.show()
>>>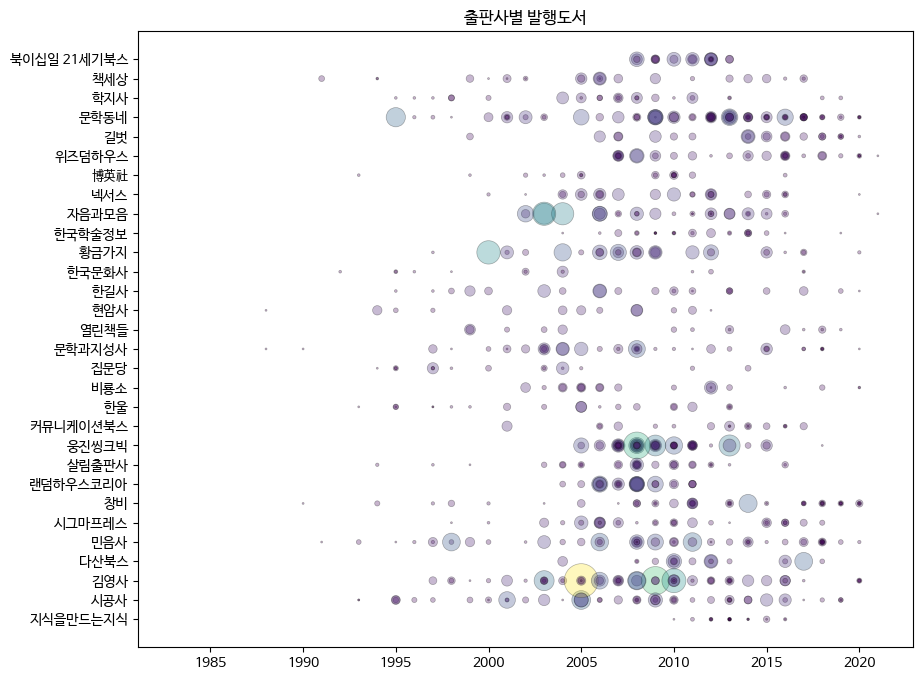
출력된 산점도 그래프는 훨씬 더 많은 정보를 보여준다. 예를 들어 '황금기지'에서 발행한 도서 중에 높은 대출건수를 기록한 것은 2000년에 발행한 도서지만, 다른 도서들은 대부분은 2005년 이후에 출간된 도서이다.
값에 따라 색상 표현하기: 컬러맵
맷플롯립은 컬러맵(color map)을 사용하여 값에 따른 색상을 다르게 표현한다. 앞서 그린 산점도는 scatter() 함수가 사용하는 기본값인 viridsis 컬러맵으로 표현되었다.
자주 사용하는 컬러맵 중 하나는 jet 컬러맵이다. jet 컬러맵은 낮은 값일수록 짙은 파란색이고, 높은 값으로 갈수록 점차 노란색으로 바뀌었다가 붉은색이 된다.
산점도를 jet 컬러맵으로 다시 그려보자. 그리고 컬러맵의 색깔이 어떤 대출건수 값에 대응하는지 참조 정보를 제공하는 컬러 막대(color bar)를 그래프 옆에 그려주자. 컬러맵은 cmap 매개변수로 지정할 수 있고, 컬러 막대는 scatter() 함수가 반환하는 객체를 colorbar() 매서드에 전달하면 된다.
fig, ax = plt.subplots(figsize=(10, 8))
sc = ax.scatter(ns_book8['발행년도'], ns_book8['출판사'],
linewidths=0.5, edgecolors='k', alpha=0.3,
s=ns_book8['대출건수']**1.3, c=ns_book8['대출건수'], cmap='jet')
ax.set_title('출판사별 발행도서')
fig.colorbar(sc)
fig.show()
>>>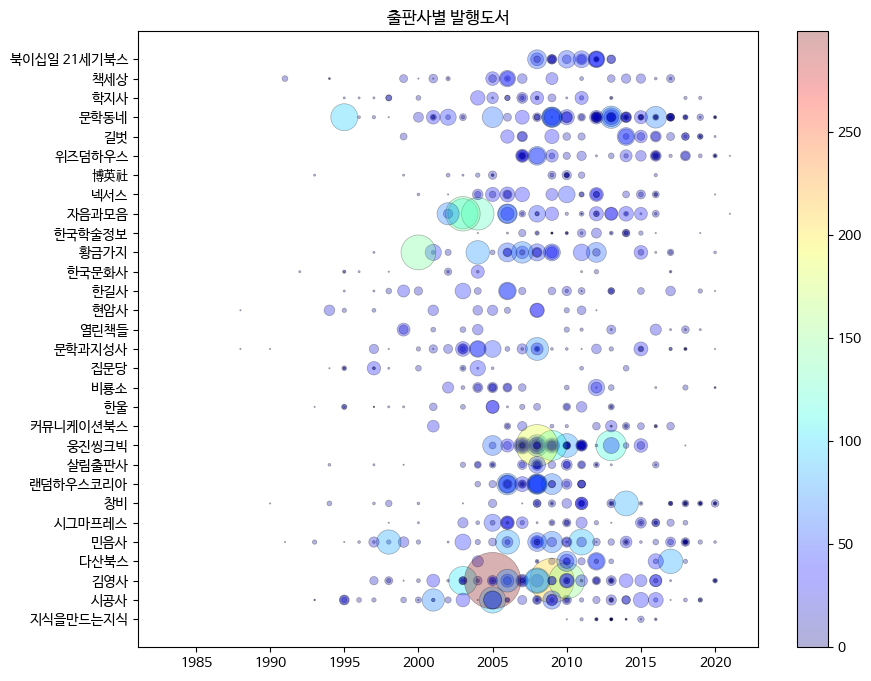
컬러 막대가 jet 컬러맵의 컬러 변화를 잘 보여준다. 가장 짙은 빨간색은 가장 큰 대출건수인 299에 맵핑되고, 가장 짙은 파란색은 가장 작은 대출건수인 0에 매핑된다. 이 컬러 막대 색깔은 아래에서부터 파란색이 점차 녹색, 노랑, 빨강으로 변한다.
이번에는 s 매개변수에 입력하는 값으로 대출건수에 1.3을 제곱했다. 대출건수가 많을수록 마커의 크기가 더욱 커진다. 앞서 그린 산점도와 비교해 보아도 마커 간의 비율 차이가 커졌다! 이렇게 마커 크기를 조절하면 산점도에 부가적인 정보를 포함시킬 수 있다. 그러나 마커 크기를 이용하여 데이터를 교묘하게 왜곡시킬 수 있다는 것을 주의해야 한다. 마커 크기를 사용해 데이터를 표현한다면 어떤 방식으로 그렸는지 정보를 제공하는 것이 좋다.
정리
- 맷플롯립의 객체지향 API는 명시적으로 피겨 객체와 서브플롯 객체를 만들고 이 객체의 매서드를 사용하여 맷플롯립 그래프를 그리는 방법이다.
- 컬러맵은 맷플롯립에서 그래프를 그리는 데 사용하기 위해 사전에 정의한 색상 리스트이다. 기본 컬러맵은 진녹색에서 노란색으로 변화하는 viridis이다. 파란색에서 노란색에서 빨간색으로 바뀌는 jet 컬러맵도 많이 사용한다.
- 컬러 막대는 데이터 포인트에 적용된 색상의 범위를 보여주는 막대이다. 보통 그래프의 오른쪽에 나란히 놓이며 색깔이 의미하는 실제 값을 참조하는데 사용된다.
핵심 함수와 메서드
- matplotlib.pyplot.rc() : rcParams 객체의 값을 설정한다.
- Figure.colorbar() : 그래프에 컬러 막대를 추가한다.
