혼자 공부하는 데이터 분석 with 파이썬
1.혼자 공부하는 데이터 분석 with 파이썬 01-1 데이터 분석이란
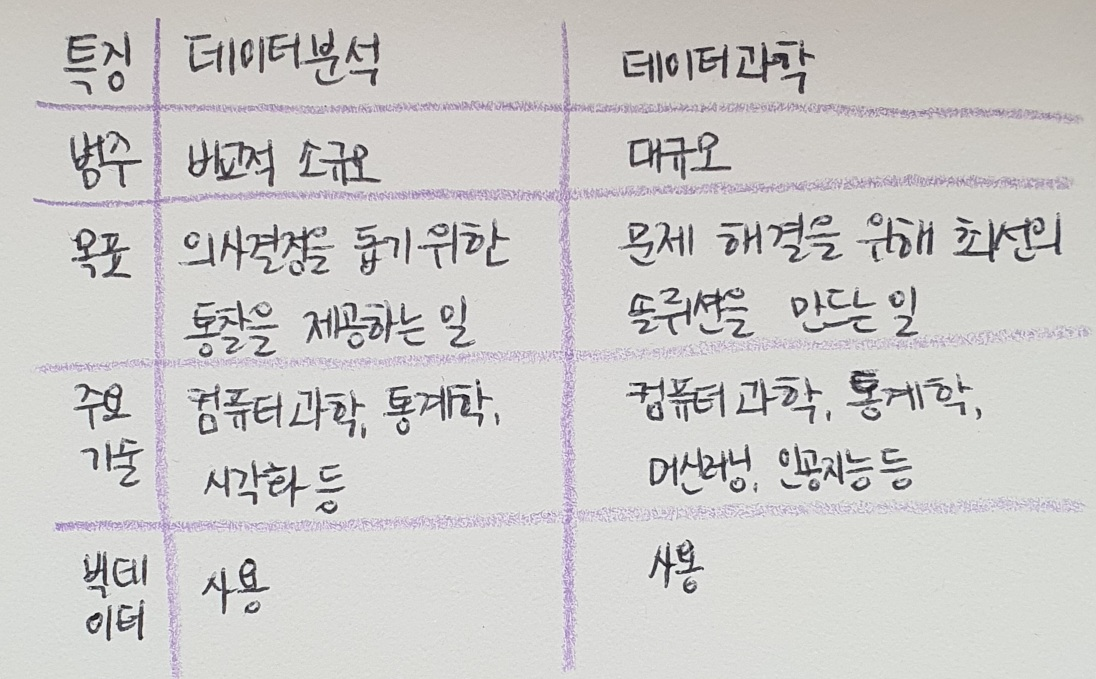
데이터 분석과 데이터 과학 데이터 분석 위키피디아에서는 '유용한 정보를 발견하고 결론을 유추하거나, 의사 결정을 돕기 위해 데이터를 조사, 정제, 변환, 모델링하는 과정'으로 정의. 데이터 분석은 다양한 접근 방법과 형태로 여러 비즈니스와 과학 분야에서 사용. 현대 사
2.혼자 공부하는 데이터 분석 with 파이썬 01-1 확인문제

① 데이터 과학② 디자인 패턴③ 통계학④ 머신러닝① 넘파이② 판다스③ 사이파이④ 플라스크넓은 의미의 데이터 분석· \_\_· \_\_· \_\_· \_\_· \_\_ 좁은 의미의 데이터 분석 · 기술통계 · 탐색적 데이터 분석 · 가설검정<풀이>3
3.혼자 공부하는 데이터 분석 with 파이썬 01-2 구글 코랩과 주피터 노트북

구글 코랩을 사용하여 실습을 진행한다. 코랩은 구글이 대화식 프로그래밍 환경인 주피터 노트북을 커스터마이징한 것으로 웹 브라우저에서 파이썬 코드를 작성하고 실행할 수 있다. 따라서 컴퓨터에 파이썬 배포판을 설치하고 환경을 구축하는 데 시간을 쏟지 않고 바로 실습 진행
4.혼자 공부하는 데이터 분석 with 파이선 01-2 확인문제

① 주피터 노트북② 코랩③ 크롬④ 아나콘다① 내 컴퓨터② 구글 드라이브③ 구글 클라우드④ 아마존 웹 서비스<풀이>3\. ①-4 / ②-1 / ③-2/ ④-3
5.혼자 공부하는 데이터 분석 with 파이썬 01-3 이 도서가 얼마나 인기가 좋을까요?
문제에 맞는 데이터가 없는 상황은 종종 발생한다. 이때 딱 맞는 데이터는 아니더라도 어느 정도 비슷한 데이터를 찾을 수 없는지 생각해보자. 공개 데이터 세트를 찾아보거나 데이터 과학과 관련된 온라인 포험에 질문을 올려서 도움 요청할 수 있다.앞으로 엑셀 파일(.xlsx
6.혼자 공부하는 데이터 분석 with 파이썬 01-3 확인문제
① 공공데이터포털② 구글 데이터 세트 검색③ 유튜브④ 캐글① CSV 파일은 콤마로 구분된 텍스트 파일이다.② CSV 파일은 바이너리 파일이므로 텍스트 편집기로 열 수 없습니다.③ 파이썬 open() 함수로 CSV 파일을 열려면 mode 매개변수를 'rb'로 지정해야 한
7.혼자 공부하는 데이터 분석 with 파이썬 02-1 API 사용하기
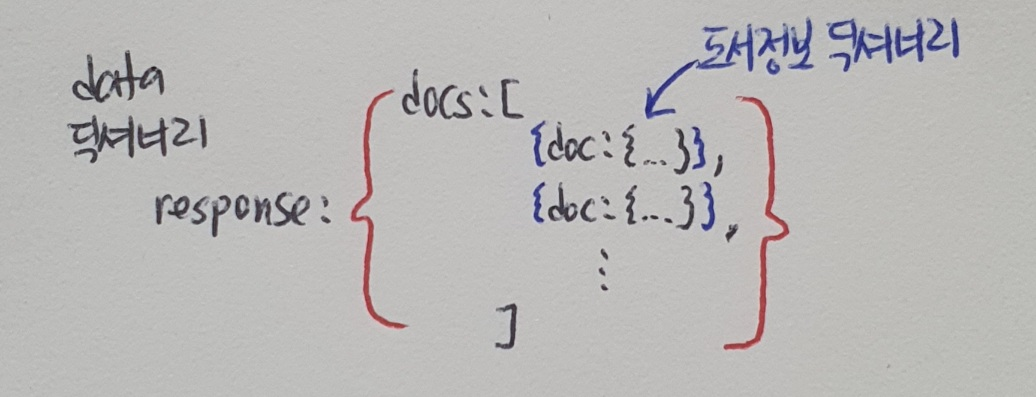
API란 데이터베이스에 민감한 개인 정보나 접근 권한이 엄격하게 관리되거나 네트워크 분리로 물리적 접근이 불가능하게 되는 경우가 있다. 이때 인증된 URL만 있다면 언제든지 필요한 데이터에 편리하게 접근할 수 있다. 이를 'API'라 부른다. API : Applicat
8.혼자 공부하는 데이터 분석 with 파이썬 02-1 확인 문제
① API는 프로그램 간의 통신을 위한 규칙을 정의한 것이다.② API는 운영체제만이 제공할 수 있다.③ API마다 별도의 라이브러리가 꼭 필요하다.④ 공개 API는 대부분 C 나 C++ 같은 저수준 언어만 사용해야 한다.① CSV② JSON③ XML④ HTML① pa
9.혼자 공부하는 데이터 분석 with 파이썬 02-2 웹 스크래핑 사용하기
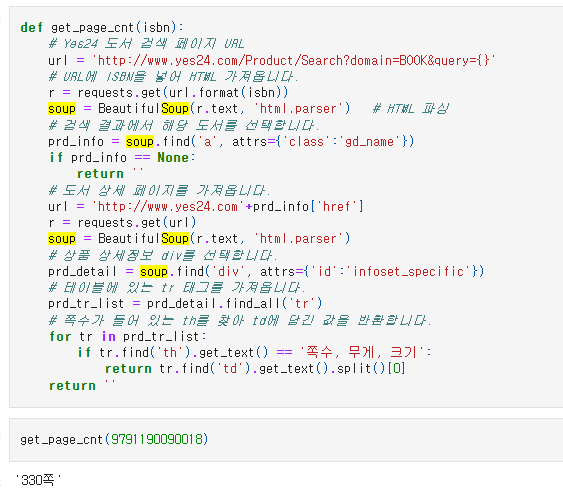
도서 쪽수를 찾아서 웹 브라우저는 온라인 서점에 있는 도서 상세 페이지의 HTML을 가져와 보여준다. 도서의 쪽수를 알고 싶다면 requests 패키지를 사용하면 가능할 것 같다. Yes24 사이트의 URL(http://www.yes24/com/Product/Good
10.혼자 공부하는 데이터 분석 with 파이썬 02-2 확인문제
col1col20 a 11 b 22 c 3① df.loc\[0,1,2,'col1', 'col2']② df.loc0:2,'col1', 'col2'③ df.loc\[:2,True, True]④ df.loc::2,'col1':'col2'① tag.find_all
11.혼자 공부하는 데이터 분석 with 파이썬 03-1 불필요한 데이터 삭제하기
데이터 정제(data cleaning) : 데이터에서 손상되거나 부정확한 부분 수정, 불필요한 데이터 삭제하거나 불완전한 값을 교체하는 등의 작업 열 삭제하기 gdown 패키지 사용해 남산도서관 데이터 다운로드. 여기서 마지막 'Unnamed: 13'열은 CSV 파
12.혼자 공부하는 데이터 분석 with 파이썬 03-1 확인 문제
1. 다음 df 데이터프레임에서 'col2' 열만 삭제하는 명령으로 올바른 것은 무엇인가요? --------col1-------col2-------col3 0---------1--------a----------NaN 1---------2--------NaN-------
13.혼자 공부하는 데이터 분석 with 파이썬 03-2 잘못된 데이터 수정하기
'도서명' 열은 NaN이 아닌 행 개수가 384,188개이므로 젖체 행 개수 중 누락된 값이 403개임을 알 수 있다.float64는 실수형, int64는 정수형, object는 문자열 또는 혼합형 데이터 타입.각 열의 누락된 값이 정확하게 몇 개가 있는지 확인하고,
14.혼자 공부하는 데이터 분석 with 파이썬 03-2 확인문제
① df.isna()=''② df.locdf.isna()=''③ df.fillna('')④ df.replace(NaN,'')df\-------A----B----C----D0-----NaN--2.0--NaN---01-----3.0--4.0--NaN---12-----NaN
15.혼자 공부하는 데이터 분석 with 파이썬 04-1 통계로 요약하기
기술통계(descrptive statistics) : 테크니컬(technical)한 어떤 것을 지칭하는 것이 아니라 자료의 내용을 압축하여 설명하는 방법. 다른 말로는 요약 통계(summary statistics) 라 부른다. 정량적인 수치로 전체 데이터의 특징을 요약
16.혼자 공부하는 데이터 분석 with 파이썬 04-1 확인문제
① 판다스의 describe() 메서드② 판다스의 info() 메서드③ 판다스의 mean() 메서드④ 넘파이의 mean() 메서드① 데이터를 랜덤하게 섞은 후 가운데 위차한 값을 선택한다.② 데이터 개수가 짝수 개 일 떄는 중앙값이 두 개가 된다.③ 평균과 중앙값이 같
17.혼자 공부하는 데이터 분석 with 파이썬 04-2 분포 요약하기
평균이나 중앙값은 데이터 분석을 잘 몰라도 이해하기 쉽지만, 분위수, 분산, 표준편차 등으 ㅣ통계량은 간단하게 설명하기 쉽지 않다. 게다가 통계량만 나열한 보고서라면 그 의미를 이해하기 더욱 어렵다.전체 데이터를 한눈에 파악하려면 그래프가 가장 좋은 방법이다. 이번 절
18.혼자 공부하는 데이터 분석 with 파이썬 04-2 확인문제
scatter() hist() boxplot()① 히스토그램② 상자 수염 그림③ 산점도① 이상치 파악하기 좋다.② 3개 이상의 특성을 하나의 산점도로 그리기 어렵다.③ 맷플롯립의 scatter() 함수에는 넘파이 배열만 사용할 수 있다.④ 특성이 정규분포를 따르는지
19.혼자 공부하는 데이터 분석 with 파이썬 05-1 맷플롯립 기본 요소 알아보기
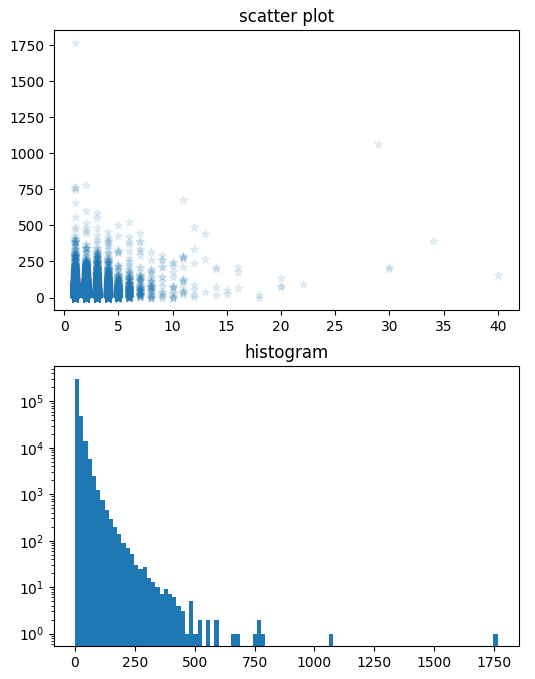
Figure 객체 Figure라는 모든 그래프 구성 요소를 담고 있는 최상위 객체가 있다. scatter() 함수로 산점도를 그릴 때 자동으로 피겨 객체가 생성된다! figuer() 함수로 명시적으로 피겨 객체를 만들어 활용하면 다양한 그래프 옵션을 조절할 수 있다.
20.혼자 공부하는 데이터 분석 with 파이썬 05-1 확인문제
① plt.figure(figsize=(10,10))② plt.subplots(figsize=(10,10))③ plt.rcParams'figure.figsize' = (10,10)④ plt.figsize(10,10)① figure() 함수의 figsize 매개변수에 지
21.혼자 공부하는 데이터 분석 with 파이썬 05-2 선 그래프와 막대 그래프 그리기
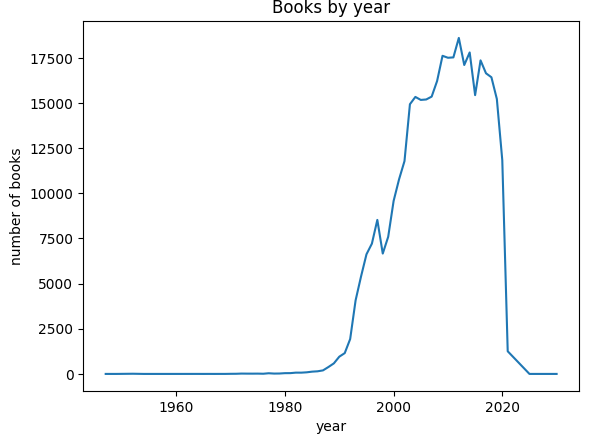
선 그래프(line graph)는 데이터 포인트 사이를 선으로 이은 그래프이고, 막대 그래프(bar graph)는 데이터 포인트의 크기를 막대 높이로 나타내는 그래프이다. 이 두 그래프는 전체 데이터의 형태를 가늠할 수 있는 산점도와 조금 다르다. 연도별 발행 도서
22.혼자 공부하는 데이터 분석 with 파이썬 05-2 확인문제
① plt.plot('a', 'b', 'c', 1, 2, 3)② plt.plot({1:'a', 2:'b', 3:'c'})③ plt.plot('a', 'b', 'c')④ plt.plot('a', 'b', 'c', range(1,4))① '-' ② '--' ③ '-.' ④
23.혼자 공부하는 데이터 분석 with 파이썬 06-1 객체지향 API로 그래프 꾸미기
그래프 그리는 방법에는 두 가지가 있는데, matplotlib.pyplot에 있는 함수를 사용하는 pyplot 방식, 명시적으로 피겨 객체와 서브플롯 객체를 만들고 이 객체의 메서드를 사용하는 객체지향 API 방식이다. matplotlib.pyplot에 있는 함수를 사
24.혼자 공부하는 데이터 분석 with 파이썬 06-1 확인문제
① resource()② rc_params()③ default()④ rc()① plt.rcParams'font.size' = 11② plt.rcParams('font'.size=11)③ plt.rc('font.size') = 11④ plt.rc('font', 11)①
25.혼자 공부하는 데이터 분석 with 파이썬 06-2 맷플롯립의 고급 기능 배우기
실습 준비하기 실습 환경 설정하기! 하나의 피겨에 여러 개의 선 그래프 그리기 한 피겨에 여러 개의 선 그래프를 그려야 할 때가 있다. 예를 들면 회사의 제품별 매출 현황을 비교하고 싶다면 x축을 연/월로 하고 y축을 매출로 한다. 그리고 각 제품의 매출 데이터를 선
26.혼자 공부하는 데이터 분석 with 파이썬 06-2 확인 문제
① df.plot.bar(stacked=True)② df.plot.bar(bottom=True)③ df.plot.stackbar()④ df.plot.barstack()① labels② explode③ startangle④ autopct① axes1.plot(...)②
27.혼공 학습단 11기 회고

드디어 혼공 학습단 11기 6주 활동이 끝이 났다!!10기에 이어 11기로 찾아왔다. 사실 지난 10기의 혼공머신 때는 회고 이벤트는 못 했는데, 이번엔 회고까지 야무지게 하는 중이다. ㅋㅋㅋㅋ매번 족장님의 애정 어린 피드백 덕분에 6주를 마칠 수 있었다. 사실 별러놓