1절에서는 사과, 파인애플, 바나나에 있는 각 픽셀의 평균값 구해서 가장 가까운 사진 골랐음. 이 경우에는 사과, 파인애플, 바나나 사진임을 미리 알고 있었기 때문에 각 과일의 평균 구할 수 있었지만, 진짜 비지도 학습에서는 사진에 어떤 과일이 들어 있는지 알지 못함.
이런 경우 k-평균(k_mean) 군집 알고리즘이 평균값을 자동으로 찾아줌. 이 평균값이 클러스터의 중심에 위치하기 때문에 클러스터 중심(cluster center) 또는 센트로이드(centroid)라고 부른다.
k-평균 알고리즘 소개
k-평균 알고리즘의 작동 방식은 다음과 같다.
① 무작위로 k개의 클러스터 중심을 정한다.
② 각 샘플에서 가장 가까운 클러스터 중심을 찾아 해당 클러스트의 샘플로 지정함.
③ 클러스터에 속한 샘플의 평균값으로 클러스터 중심을 변경함.
④ 클러스터 중심에 변화가 없을 때까지 2번으로 돌아가 반복.
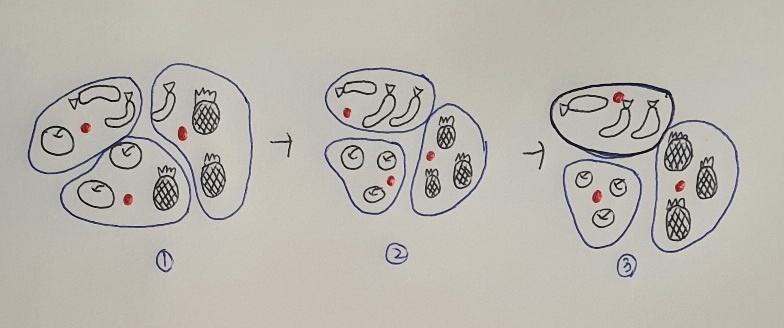
먼저 3개의 클러스터 중심(빨간 점)을 랜덤하게 지정(①). 그리고 클러스터 중심에서 가장 가까운 샘플을 하나의 클러스터로 묶는다. 왼쪽 위부터 시계 방향으로 바나나 2개와 사과 1개 클러스터, 바나나 1개와 파인애플 2개 클러스터, 사과 2개와 파인애플 1개 클러스터가 만들어짐. 클러스터에는 순서나 번호는 의미 X.
그 다음 클러스터의 중심을 다시 계싼하여 이동시킴. 맨 아래 클러스터는 사과 쪽으로 중심이 조금 더 이동하고 왼쪽 위의 클러스터는 바나나 쪽으로 중심이 더 이동하는 식.
클러스터 중심을 다시 계산한 다음 가장 가까운 샘플을 다시 클러스터로 묶기(②). 이제 3개의 클러스터에는 바나나와 파인애플, 사과가 3개씩 올바르게 묶여 있음. 다시 한 번 클러스터 중심을 계산. 그다음 빨간 점을 클러스터의 가운데 부분으로 이동시킴.
이동된 클러스터 중심에서 다시 한 번 가장 가까운 샘플을 클러스터로 묶기(③). 중심에서 가장 가까운 샘플은 이전 클러스터(②)와 동일. 따라서 만들어진 클러스터에 변동이 없으므로 k-평균 알고리즘을 종료함.
k-평균 알고리즘은 처음에는 랜덤하게 클러스터 중심을 선택하고 점차 가장 가까운 샘프의 중심으로 이동하는 비교적 간단한 알고리즘.
kMeans 클래스
# 1절에서 사용한 데이터셋 불러오기.
!wget https://bit.ly/fruits_300_data -O fruits_300.npy
# 넘파이 np.load() 함수 사용해 npy 파일을 읽어 넘파이 배열을 준비함. k-평균 모델을 훈련하기 위해 (샘플 개수, 너비, 높이) 크기의 3차원 배열을 (샘플 개수, 너비x높이) 크기를 가진 2차원 배열로 변경함.
import numpy as np
fruits = np.load('fruits_300.npy')
fruits_2d = fruits.reshape(-1, 100*100)사이킷런의 k-평균 알고리즘은 sklearn.cluster 모듈 아래 KMeans 클래스에 구현되어 있음. 이 클래스에서 설정할 매개변수는 클러스터 개수를 지정하는 n_clusters. 여기서는 클러스터 개수를 3으로 지정.
이 클래스를 사용하는 방법도 다른 클래스들과 비슷. 다만 비지도 학습이므로 fit() 메서드에서 타깃 데이터를 사용하지 않음.
from sklearn.cluster import KMeans
km = KMeans(n_clusters=3, random_state=42)
km.fit(fruits_2d)
>>> /usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
KMeans
KMeans(n_clusters=3, random_state=42)군집된 결과는 KMeans 클래스 객체의 lagels속성에 저장됨. lagels 배열의 길이는 샘플 개수와 같음. 이 배열은 각 샘플이 어떤 레이블에 해당되는지 나타냄. nclusters=3으로 지정했기 때문에 labels 배열의 값은 0, 1, 2 중 하나.
print(km.labels_)
>>> [2 2 2 2 2 0 2 2 2 2 2 2 2 2 2 2 2 2 0 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 0 2 0 2 2 2 2 2 2 2 0 2 2 2 2 2 2 2 2 2 0 0 2 2 2 2 2 2 2 2 0 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 0 2 2 2 2 2 2 2 2 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1]레이블 값 0, 1, 2와 레이블 순서에는 어떤 의도도 없음. 실제 레이블 0, 1, 2가 어떤 과일 사진을 주로 모았는지 알아보려면 직접 이미지 출력하는 것이 최선. 그 저에 레이블 0, 1, 2로 모은 샘플의 개수를 확인.
print(np.unique(km.labels_, return_counts=True))
>>> (array([0, 1, 2], dtype=int32), array([111, 98, 91]))첫 번째 클러스터(레이블 0)가 91개의 샘플을 모았고, 두 번째 클러스터(레이블 1)가 98개의 샘플을 모았음. 세 번째 클러스터(레이블 2)는 111개의 샘플을 모음. 그럼 각 클러스터가 어떤 이미지 나타냈는지 그림으로 출력하기 위해 간단한 유틸리티 함수 draw_fruits() 만들어 보자.
import matplotlib.pyplot as plt
def draw_fruits(arr, ratio=1):
n = len(arr) # n은 샘플 개수입니다
# 한 줄에 10개씩 이미지를 그립니다. 샘플 개수를 10으로 나누어 전체 행 개수를 계산합니다.
rows = int(np.ceil(n/10))
# 행이 1개 이면 열 개수는 샘플 개수입니다. 그렇지 않으면 10개입니다.
cols = n if rows < 2 else 10
fig, axs = plt.subplots(rows, cols,
figsize=(cols*ratio, rows*ratio), squeeze=False)
for i in range(rows):
for j in range(cols):
if i*10 + j < n: # n 개까지만 그립니다.
axs[i, j].imshow(arr[i*10 + j], cmap='gray_r')
axs[i, j].axis('off')
plt.show()drawfruits() 함수는 (샘플 개수, 너비, 높이)의 3차원 배열을 입력받아 가로로 10개씩 이미지를 출력. 샘프 개수에 따라 행과 열의 개수를 계산하고 figsize를 지정. figsize는 ratio 매개변수에 비례하여 커진다. ratio 기본값은 1.
그 다음 2중 for 반복문을 사용하여 먼저 첫 번재 행을 따라 이미지를 그린다. 그리고 두 번째 행의 이미지를 그리는 식으로 계속됨.
이 함수를 사용해 레이블이 0인 과일 사진을 모두 그려보자. km.labels==0과 같이 쓰면 km.labels 배열에서 값이 0인 위치는 True, 그 외는 모두 False. 넘파이는 이런 불리언 배열 사용해 원소 선택할 수 있음. 이를 불리언 인덱싱이라고 한다.
넘파이 배열에 불리언 인덱싱 적용하면 True인 위치의 원소만 모두 추출.
draw_fruits(fruits[km.labels_==0])
레이블 0으로 클러스터링된 91개의 이미지 모두 출력. 이 클러스터는 모두 사과가 올바르게 모임.
draw_fruits(fruits[km.labels_==1])
draw_fruits(fruits[km.labels_==2])
레이블이 1인 클러스터는 바나나로만 이루어져있음. 하지만 레이블이 2인 클러스트는 파인애플에 사과 9개와 바나나 2개가 섞여 있음. k-평균 알고리즘이 이 샘플들을 완벽하게 구별하지 못함. 하지만 훈련 데이터에 타깃 레이브을 전혀 제공하지 않았음에도 스스로 비슷한 샘플들을 아주 잘 모은 것 같음!
클러스터 중심
kMeans 클래스가 최종적으로 찾은 클러스터 중심은 clustercenters 속성에 저장되어 있음. 이 배열은 fruist_2d 샘플의 클러스터 중심이기 때문에 각 중심을 이미지로 출력하면 100 x 100 크기의 2차원 배열로 바꿔야 한다.
draw_fruits(km.cluster_centers_.reshape(-1, 100, 100), ratio=3)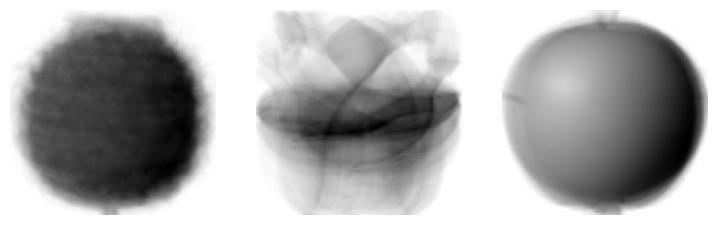
이전 절에서 사과, 바나나, 파인애플의 픽셀 평균값을 출력했던 것과 매우 비슷!!
kMeans 클래스는 훈련 데이터 샘플에서 클러스터 중심까지 거리로 변환해 주는 transform() 메서드를 가지고 있음. transform() 메서드가 있다는 것은 마치 StandardScaler 클래스처럼 특성값을 변환하는 도구로 사용할 수 있다는 의미.
인덱스가 100인 샘플에 transform() 메서드르 적용해보자! fit() 메서드와 마찬가지로 2차원 배열을 기대한다. fruits_2d[100]처럼 쓰면 (10000.) 크기의 배열이 되므로 에러가 발생한다. 슬라이싱 연산자를 사용해 (1, 10000) 크기의 배열을 전달.
print(km.transform(fruits_2d[100:101]))
>>> [[3393.8136117 8837.37750892 5267.70439881]]하나의 샘플 전달했기 땜누에 반환된 배열은 크기가 (1, 클러스터 개수)인 2차원 배열. 첫 번째 클러스터(레이블 0), 두 번째 클러스터(레이블 1)가 각각 첫 번째 원소, 두 번째 원소의 값. 세 번째 클러스터까지의 거리가 3393.8로 가장 작음! 이 샘플은 레이브 2에 속한 것 가탇. KMeans 클래스는 가장 가까운 클러스터 중심을 예측 클래스로 출력하는 predict() 메서드를 제공한다.
print(km.predict(fruits_2d[100:101]))
>>> [2]
# transform()의 결과에서 짐작할 수 있듯이 레이블 2로 예측. 클러스터 중심을 그려보았을 때 레이블 2는 파인애플이었으므로 이 샘플은 파인애플 일 듯!
draw_fruits(fruits[100:101])
k-평균 알고리즘은 앞에서 설명했듯이 반복적으로 클러스터 중심을 옮기면서 최적의 클러스터를 찾는다. 알고리즘이 반복한 횟수 KMeans 클래스의 niter 속성에 저장된다.
print(km.n_iter_)
>>> 3클러스터 중심을 특성 공학처럼 사용해 데이터셋을 저차원(이 경우에는 10,000에서 3으로 줄인다.)으로 변환할 수 있다. 또는 가장 가까운 거리에 있는 클러스터 중심을 샘플의 예측값으로 사용할 수 있다는 것을 배움!
최적의 k 찾기
k-평균 알고리즘의 단점 중 하나는 클러스터 개수를 사전에 지정해야 한다는 점. 실전에서는 몇 개의 클러스터가 있는지 알 수 없음.
사실 군집 알고리즘에서 적절한 k 값 찾기 위한 완벽한 방법은 없음. 몇 가지 도구 있지만 저마다 장단점 있음. 여기서는 적절한 클러스터 개수를 찾기 위한 대표적인 방법인 엘보우(elbow) 방법에 대해 알아보자.
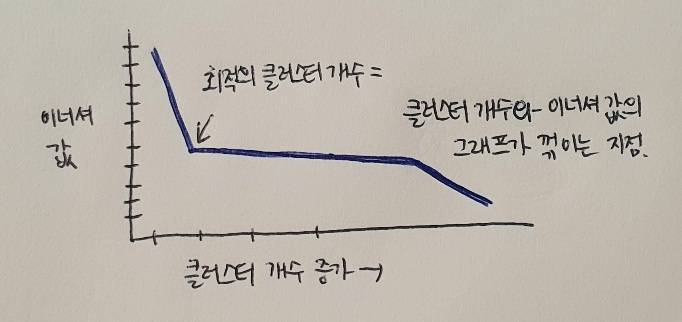
k-평균 알고리즘은 크러스터 중심과 클러스터에 속한 샘플 사이의 거리를 잴 수 있음. 이 거리의 제곱 합을 이너셔(inertia) 라고 부른다. 이너셔는 클러스터에 속한 샘플이 얼마나 가깝게 모여 있는지를 나타내는 값으로 생각할 수 있음. 일반적으로 클러스터 개수가 늘어나면 클러스터 개개의 크기는 줄어들기 때문에 이너셔도 줄어든다. 엘보우 바업은 클러스터 개수를 늘려가면서 이너셔의 변화를 관찰하여 최적의 클러스터 개수를 찾는 방법.
클러스터 개수를 증가시키면서 이너셔를 그래프로 그리면 감소하는 속도가 꺾이는 지점이 있다. 이 지점부터는 클러스터 개수를 늘려도 클러스터에 잘 밀집된 정도가 크게 개선되지 않음.
즉, 이너셔가 크게 줄어들지 않음. 이 지점이 마치 팔꿈치 모양이어서 엘보우 방법이라 부른다.
과일 데이터셋을 사용해 이너셔 계산. 친절하게도 KMeans 클래스는 자동으로 이너셔를 계산해어 inertia 속성으로 제공한다. 다음 코드에서 클러스터 개수 k를 2-6까지 바꿔가며 KMeans 클래스를 5번 훈련한다. fit() 메서드로 모델 훈련한 후 inerti 속성에 저장된 이너셔 값을 inertia 리스트에 추가함. 마지막으로 inertia 리스트에 저장된 값 그래프로 출력한다.
inertia = []
for k in range(2, 7):
km = KMeans(n_clusters=k, n_init='auto', random_state=42)
km.fit(fruits_2d)
inertia.append(km.inertia_)
plt.plot(range(2, 7), inertia)
plt.xlabel('k')
plt.ylabel('inertia')
plt.show()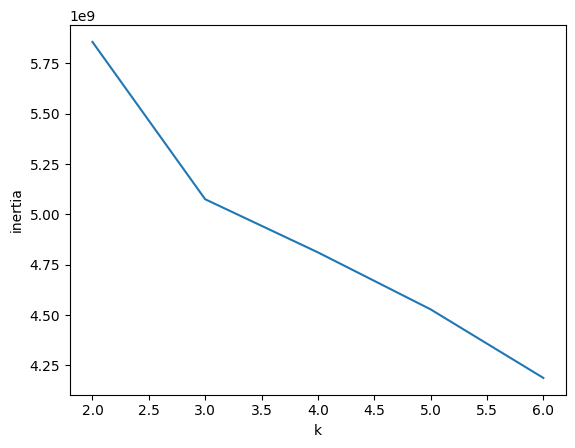
전체 코드 (출처 : https://bit.ly/hg-05-2)
!wget https://bit.ly/fruits_300_data -O fruits_300.npy
import numpy as np
fruits = np.load('fruits_300.npy')
fruits_2d = fruits.reshape(-1, 100*100)
from sklearn.cluster import KMeans
km = KMeans(n_clusters=3, random_state=42)
km.fit(fruits_2d)
print(km.labels_)
print(np.unique(km.labels_, return_counts=True))
import matplotlib.pyplot as plt
def draw_fruits(arr, ratio=1):
n = len(arr) # n은 샘플 개수입니다
# 한 줄에 10개씩 이미지를 그립니다. 샘플 개수를 10으로 나누어 전체 행 개수를 계산합니다.
rows = int(np.ceil(n/10))
# 행이 1개 이면 열 개수는 샘플 개수입니다. 그렇지 않으면 10개입니다.
cols = n if rows < 2 else 10
fig, axs = plt.subplots(rows, cols,
figsize=(cols*ratio, rows*ratio), squeeze=False)
for i in range(rows):
for j in range(cols):
if i*10 + j < n: # n 개까지만 그립니다.
axs[i, j].imshow(arr[i*10 + j], cmap='gray_r')
axs[i, j].axis('off')
plt.show()
draw_fruits(fruits[km.labels_==0])
draw_fruits(fruits[km.labels_==1])
draw_fruits(fruits[km.labels_==2])
draw_fruits(km.cluster_centers_.reshape(-1, 100, 100), ratio=3)
print(km.transform(fruits_2d[100:101]))
print(km.predict(fruits_2d[100:101]))
draw_fruits(fruits[100:101])
print(km.n_iter_)
inertia = []
for k in range(2, 7):
km = KMeans(n_clusters=k, n_init='auto', random_state=42)
km.fit(fruits_2d)
inertia.append(km.inertia_)
plt.plot(range(2, 7), inertia)
plt.xlabel('k')
plt.ylabel('inertia')
plt.show()정리
- k- 평균 알고리즘은 처음에 랜덤하게 클러스터 중심을 정하고 클러스터를 만든다. 그 다음 클러스터의 중심을 이동하고 다시 클러스터를 만드는 식으로 반복해서 최적의 클러스터를 구성하는 알고리즘.
- 클러스터 중심은 k-펑균 알고리즘이 만든 클러스터에 속한 샘플의 특성 평균값. 센트로이드(centroid)라고도 부른다. 가장 가까운 클러스터 중심을 샘플의 또 다른 특성으로 사용하거나 새로운 샘플에 대한 에측으로 활용할 수 있다.
- 엘보우 방법은 최적의 클러스터 개수를 정하는 방법 중 하나. 이너션느 클러스터 중심과 샘플 사이 거리의 제곱 합. 클러스터 개수에 따라 이너셔 감소가 꺾이는 지점이 적절한 클러스터 개수 k가 될 수 있다. 이 그래프의 모양을 따러 엘보우 방법이라 부른다.
핵심 패키지와 함수
scikit-learn
- KMeans : k-평균 알고리즘 클래스.
n_clusters에는 클러스터 개수를 지정. 기본값은 8.
처음에 랜덤하게 센트로이드를 초기화하기 때문에 여러 번 반복하여 이너셔를 기준으로 가장 좋은 결과를 선택한다. n_init는 이 반복 횟수를 지정한다. 기본값은 10.
max_iter는 k-평균 알고리즘의 한 번 실행에서 최적의 센트로이드를 찾기 위해 반복할 수 있는 최대 횟수. 기본값은 200.
