혼자 공부하는 머신러닝 + 딥러닝
1.혼자 공부하는 머신러닝 + 딥러닝_01-1 인공지능과 머신러닝, 딥러닝

인공지능이란??: artificial intelligence. 사람처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터 시스템을 만드는 기술.머신러닝이란??: machine learning. 규칙을 일일이 프로그래밍하지 않아도 자동으로 데이터에서 규칙을 학습하는 알고리즘을
2.혼자 공부하는 머신러닝 + 딥러닝_01-2 코랩과 주피터 노트북
구글코랩: Colab. 웹 브라우저에서 무료로 파이썬 프로그램을 테스트하고 저장할 수 있는 서비스. 구글 계정만 있다면 누구나 무료로 사용할 수 있다. 구글 계정으로 로그인 하지 않아도 접속은 가능. 하지만 코드 실행은 X.노트북: Notebook. 웹 브라우저에서 텍
3.혼자 공부하는 머신러닝 + 딥러닝_01-3 마켓과 머신러닝
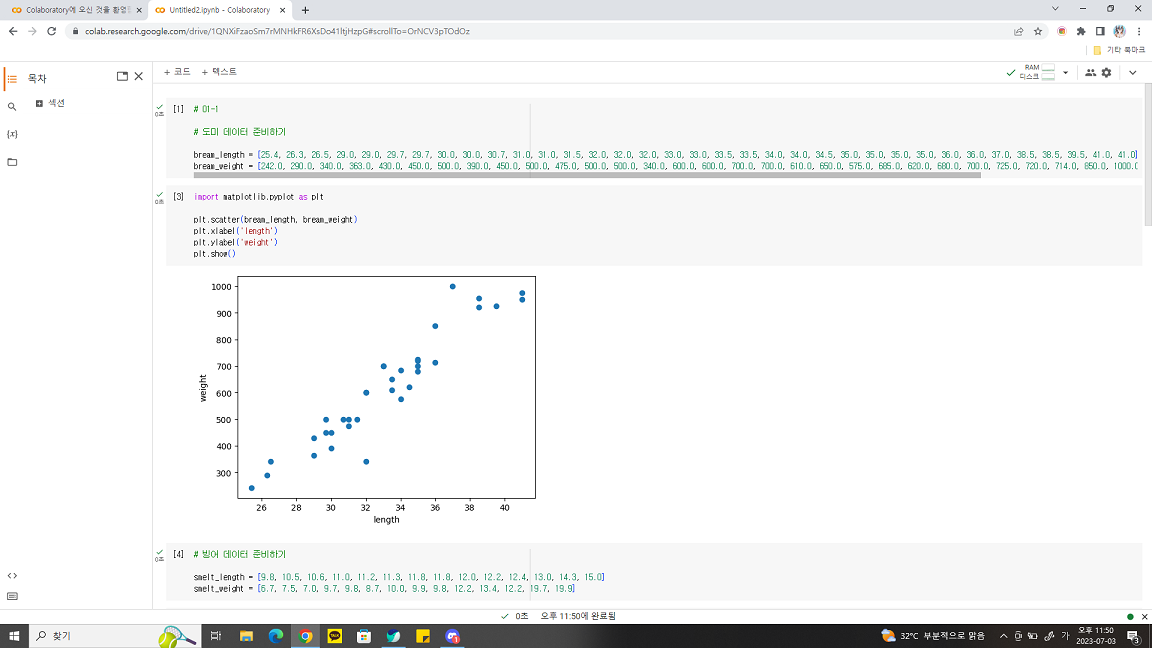
생선 분류 문제 도미 데이터 준비하기 + 이진 분류 : 머신러닝에서 여러 개의 종류(or 클래스(class)) 중 하나 구별해 내는 문제를 분류(classification)라고 하는데 2개의 클래스 중 하나 고르는 문제를 말한다. 35마리의 도미의 길이(cm)와 무게
4.혼자 공부하는 머신러닝 + 딥러닝_02-1 훈련 세트와 테스트 세트
지도학습 : 정답(타깃)이 있어서 알고리즘이 정답을 맞힐 수 있도록 학습하는 것. \- 훈련 데이터 : 데이터와 정답을 입력(input)과 타겟(target)이라 부르는데 이 두 가지를 합한 것.(training data)비지도학습 : 타겟 없이 입력 데이터만 사용.테
5.혼자 공부하는 머신러닝 + 딥러닝 02-1 확인 문제 풀이
① 지도학습 ② 비지도 학습 ③ 자원 축소 ④ 강화 학습① 샘플링 오류 ② 샘플링 실수 ③샘플링 편차 ④ 샘플링 편향① 행 : 특성, 열 : 샘플② 행 : 샘플, 열 : 특성③ 행 : 특성, 열 : 타깃④ 행 : 타깃, 열 : 특성<풀이>② 비지도 학습은 타깃이
6.혼자 공부하는 머신러닝 + 딥러닝 02-2 데이터 전처리
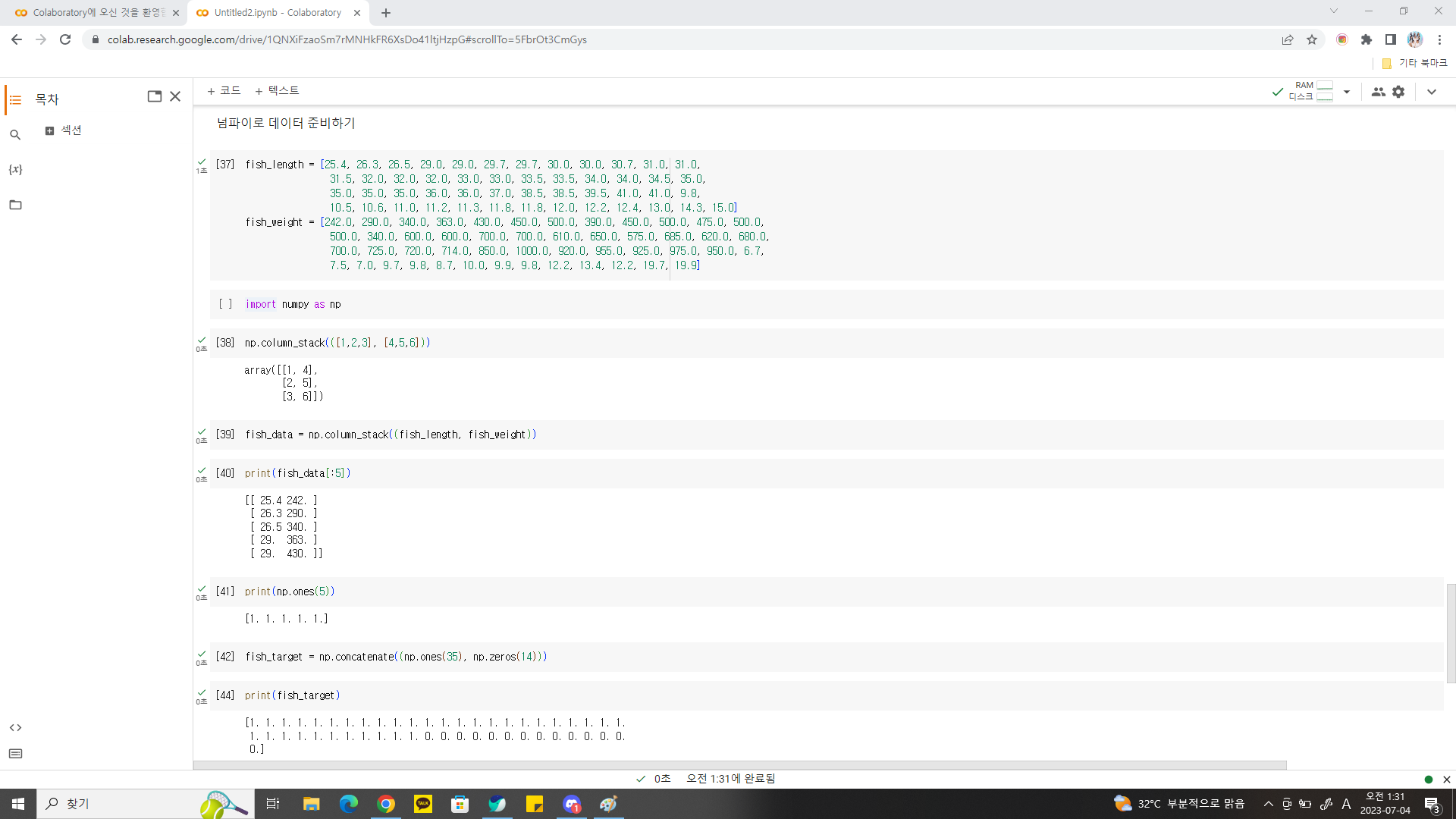
넘파이로 데이터 준비하기 넘파이의 column_stack() 함수 : 전달받은 리스트를 일렬로 세운 다음 차례대로 나란히 연결. 연결할 리스트는 튜플(tuple)로 전달. 튜플(tuple) : 리스트처럼 원소에 순서 있지만, 한 번 만들어진 튜플은 수정 불가. 이처
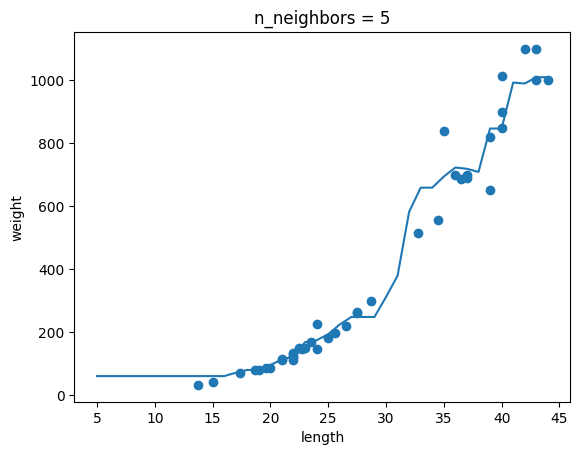
7.혼자 공부하는 머신러닝 + 딥러닝 03-1 K-최근접 이웃 회귀
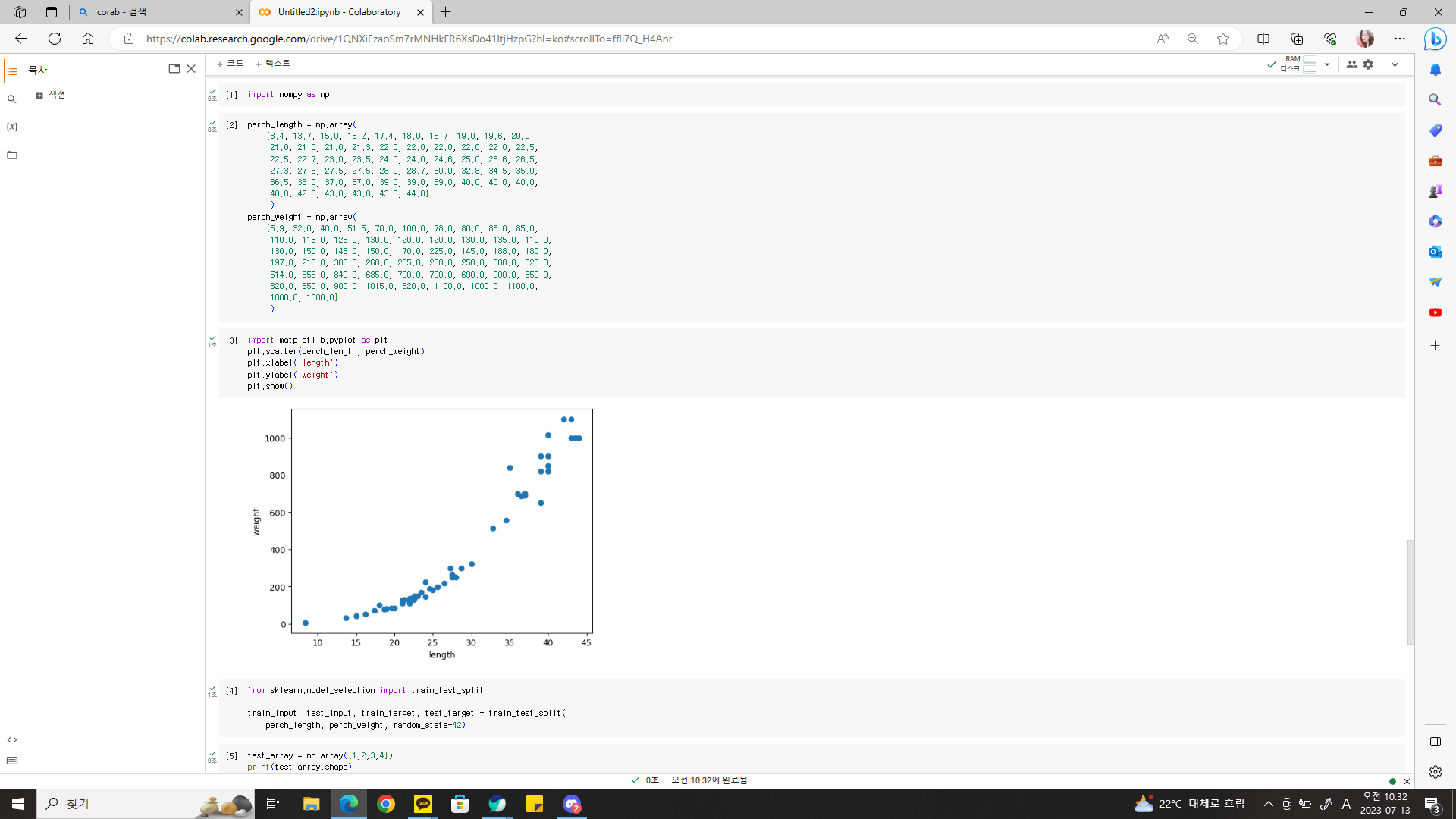
k-최근접 이웃 회귀 회귀(regression) : 클래스 중 하나로 임의의 어떤 숫자를 예측하는 문제. 예를 들면 내년도 경제 성쟝률 예측이나 배달 도착 시간 예측. 여기서는 농어의 무게 예측하는 것도 회귀에 속함! k-최근접 이웃 분류 알고리즘 예측하려는 샘플에
8.혼자 공부하는 머신러닝 + 딥러닝 03-1 확인문제
① 이웃 샘플 클래스 중 다수인 클래스 ② 이웃 샘플의 타깃값의 평균③ 이웃 샘플 중 가장 높은 타깃값④ 이웃 샘플 중 가장 낮은 타깃값<풀이>
9.혼자 공부하는 머신러닝 + 딥러닝 03-2 선형회귀
여기까지는 1절 내용 그대로!길이가 50cm이고 무게가 1,033g인 농어는 세모(marker='^')로 표시, 주변 샘플은 마름모(marker='D')산점도를 보니 길이가 커질수록 노어 무게 증가하는 경향 있음. 하지만 50cm 농어에서 가장 가까운 것은 45cm 근
10.혼자 공부하는 머신러닝 + 딥러닝 03-2 확인 문제 풀이
① 회귀 파라미터② 선형 파라미터③ 학습 파라미터④ 모델 파라미터① LinearRegression② PolynomialRegression③ KNeighborsClassifier④ PolynomialClasifier<풀이>② PolynomialRegression →
11.혼자 공부하는 머신러닝 + 딥러닝 03-3 특성 공학과 규제
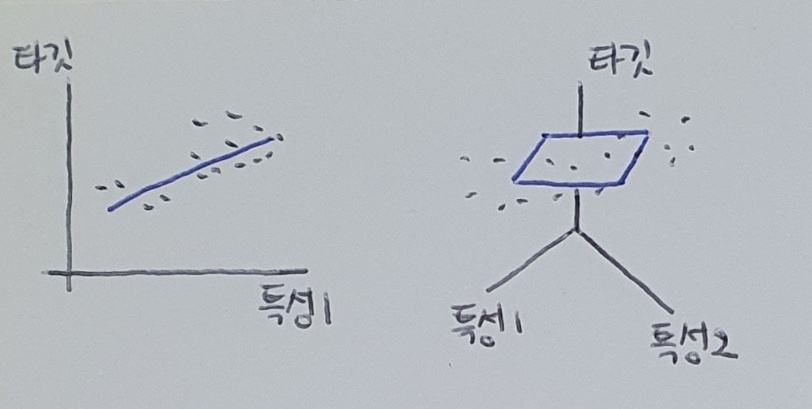
다중 회귀(multiple regression) : 여러 개의 특성을 사용한 선형 회귀하지만 우리는 3차원 공간 이상을 그리거나 상상할 수 없다. 선형 회귀를 단순한 직선이나 평면으로 생각하여 성능이 무조건 낮다고 오해해선 안된다!! 특성 많은 고차원에서는 선형 회귀가
12.혼자 공부하는 머신러닝 + 딥러닝 03-3 확인 문제 풀이
① 1② a③ a b④ a b^2① Ridge② Lasso③ StandardScaler④ LinearRegerssion① 과대적합인 모델은 훈련 세트의 점수가 높습니다.② 과대적합인 모델은 테스트 세트의 점수도 높습니다.③ 과소적합인 모델은 훈련 세트의 점수가 낮습
13.혼자 공부하는 머신러닝 + 딥러닝 03 선택 미션
: 그 값이 데이터들에 의해 결정되는 값. 회귀 모델 같은 경우 데이터에 따라 계수와 상수항이 결정된다.파라미터는 예측을 할 때 모델에서 필요로 한다,파라미터는 데이터로부터 추정되거나 학습된다파라미터는 직접 설정되지 않는다.파라미터는 종종 모델의 일부로 저장된다.하이퍼
14.혼자 공부하는 머신러닝 + 딥러닝 04-1 로지스틱 회귀
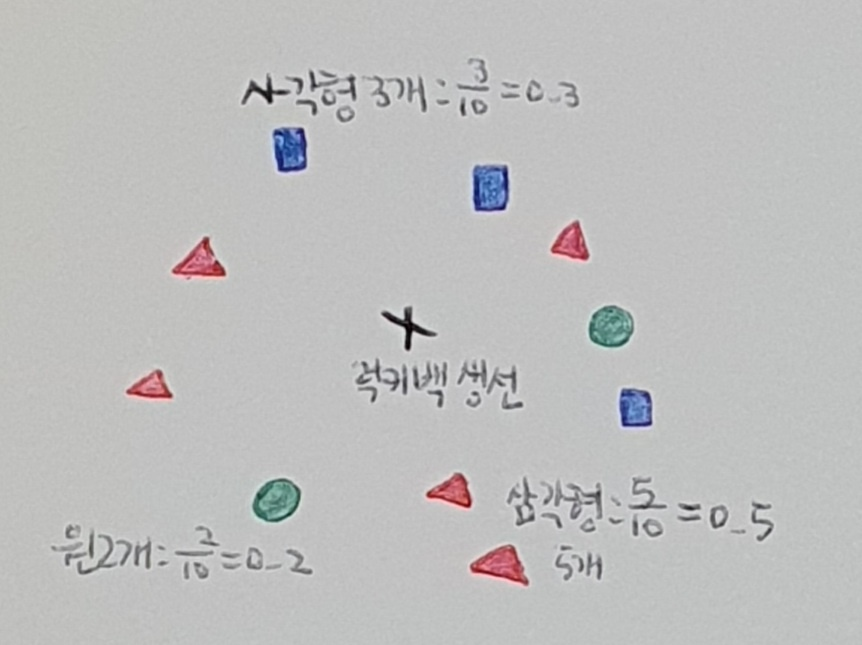
럭키백의 확률 럭키백에 들어갈 수 있는 생선은 7마리! "k-최근접 이웃은 주변 이웃을 찾아주니까 이웃의 클래스 비율을 확률이라고 출력하면 되지 않을까?" 다중 회귀(multiple regression) : 여러 개의 특성을 사용한 선형 회귀 하지만 우리는 3차원
15.혼자 공부하는 머신러닝 + 딥러닝 04-1 확인문제
① 이진 분류 ② 다중 분류③ 단변량 회귀④ 다변량 회귀① 시그모이드 함수② 소프트맥스 함수③ 로그 함수④ 지수 함수① 0 ② 0.25 ③ 0.5 ④ 1<풀이>① 이진 분류는 2개의 클래스, 즉 양성 클래스와 음성 클래스를 분류하는 문제.③ 단변량 회귀는 하
16.혼자 공부하는 머신러닝 + 딥러닝 04-2 확률적 경사 하강법
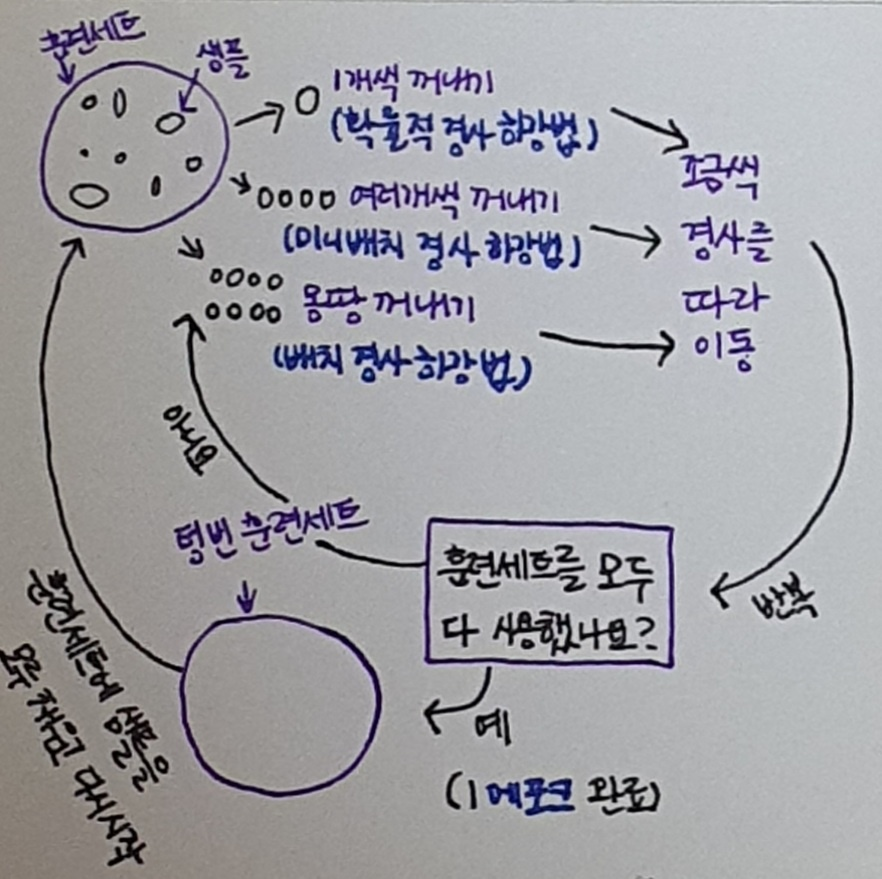
기존 훈련 데이터에 새로운 데이터를 추가하여 모델 매일매일 다시 훈련해보자! → 근데 시간이 지날수록 데이터가 늘어난다. 몇 달이 지나면 모델을 훈련하기 위해 서버를 늘려야한다. 지속 가능한 방법은 아님!또 다른 방법은 새로운 데이터 추가할 때 이전 데이터 버려서 훈련
17.혼자 공부하는 머신러닝 + 딥러닝 04-2 확인 문제
① KNeighborsClassifier② LinearRegression③ Ridge④ SGDClassifier① 확률적 경사 하강법② 배치 경사 하강법③ 미니배치 경사 하강법④ 부분배치 경사 하강법<풀이>① KNeighborsClassifier는 최근접 이웃을
18.혼자 공부하는 머신러닝 + 딥러닝 05-1 결정트리
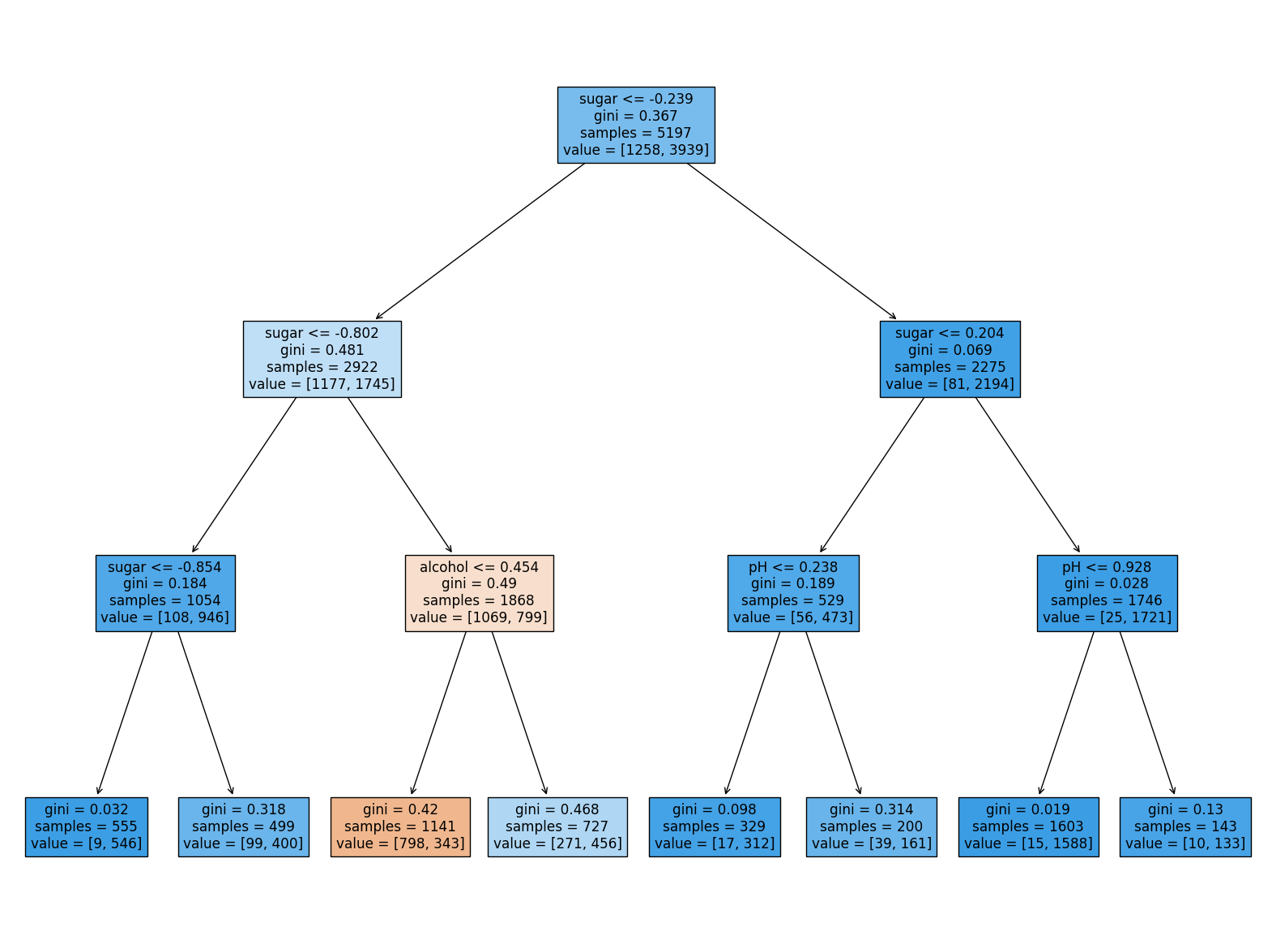
로지스틱 회귀로 와인 분류하기 → 전체 와인 데이터에서 화이트 와인 골라내는 문제. _+ 누락된 값 있으면??? 누락된 값 있다면 그 데이터를 버리거나 평균값으로 채운 후 사용 가능. 어떤 방식이 최선인지는 미리 알기 어려움. 여기서도 항상 훈련 세트의 통계 값으로
19.혼자 공부하는 머신러닝 + 딥러닝 05-1 확인문제
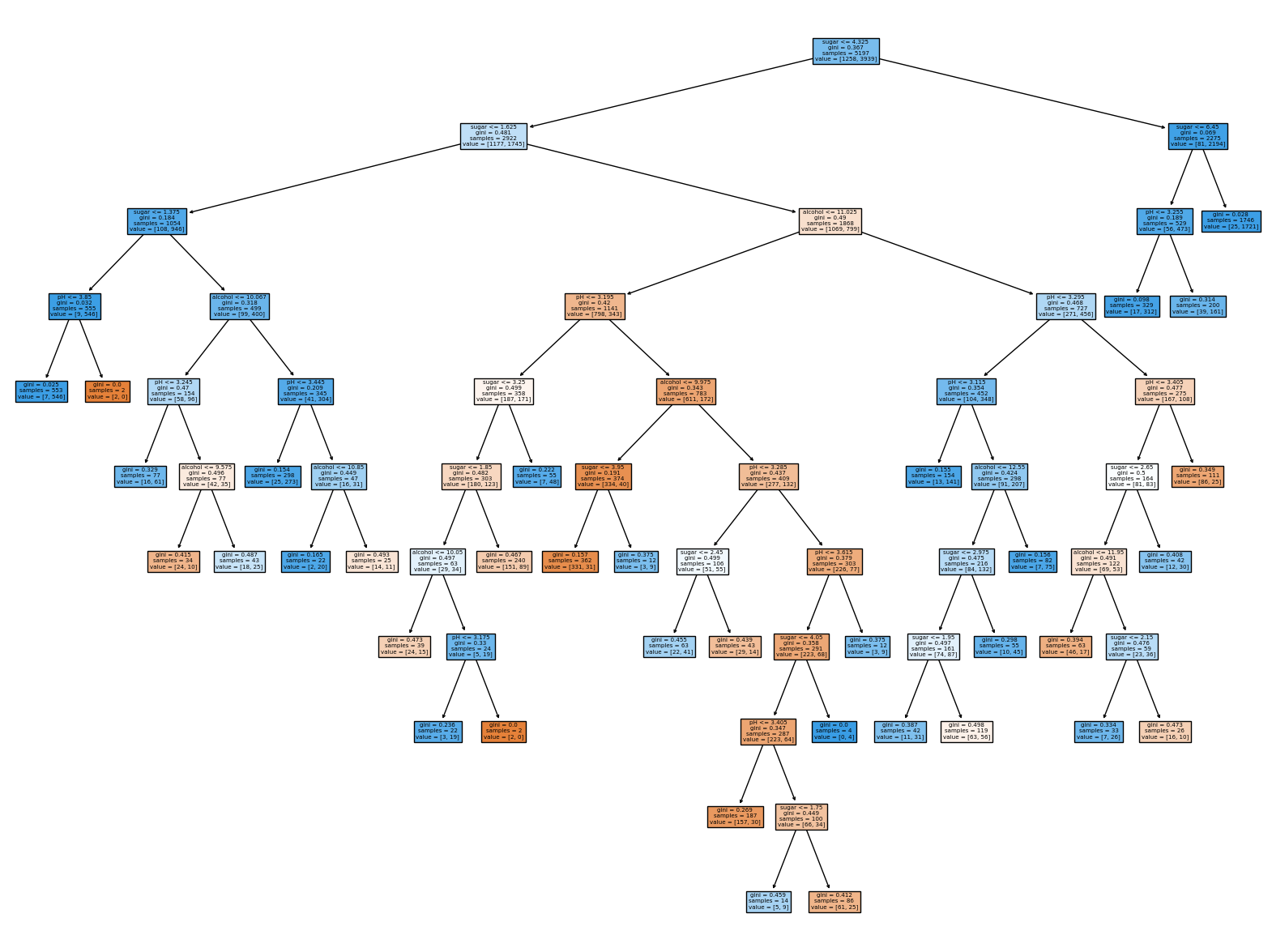
① 지니 불순도는 부모 노드의 불순도와 자식 노드의 불순도의 차이로 계산합니다.② 지니 불순도는 클래스의 비율을 제곱하여 모두 더한 다음 1에서 뺍니다.③ 엔트로피 불순도는 1에서 가장 큰 클래스 비율을 빼서 계산합니다.④ 엔트로피 불순도는 클래스 비율과 클래스 비율에
20.혼자 공부하는 머신러닝 + 딥러닝 05-2 교차 검증과 그리드 서치
검증 세트 테스트 세트 사용하지 않으면 모델이 과대적합인지 과소적합인지 판단하기 어렵다. 테스트 세트를 사용하지 않고 이를 측정하는 간단한 방법은 훈련 세트를 또 나누는 것!! 이 데이터를 검증 세트(vaildation set)라고 부른다!! 앞에서 전체 테이터 중
21.혼자 공부하는 머신러닝 + 딥러닝 05-2 확인 문제
① 교차 검증② 반복 검증③ 교차 평가④ 반복 평가① cross_validate()② GridSearchCV③ RandomizedSearchCV④ train_test_split<풀이>① cross_validate()는 주어진 모델과 훈련 세트를 사용하여 기본 5-
22.혼자 공부하는 머신러닝 + 딥러닝 05-3 트리와 앙상블
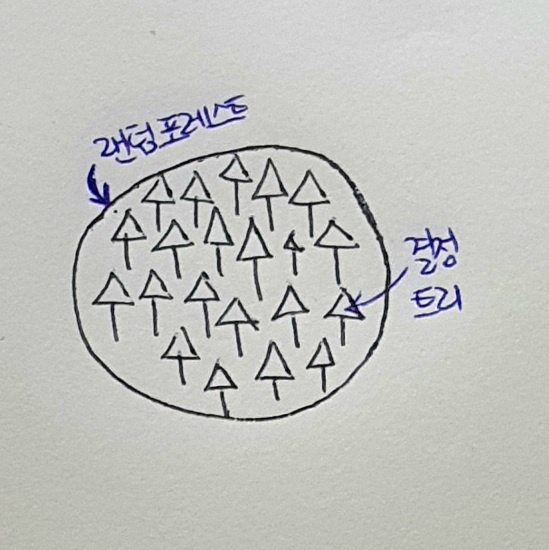
정형 데이터(structured data) : 어떤 구조로 되어 있다는 뜻. CSV나 데이터베이스 혹은 엑셀에 저장하기 쉬움.비정형 데이터(unstructured data) : 데이터베이스나 엑셀에 저장하기 어려운 것들. 텍스트 데이터, 디카로 찍은 사진, 핸드폰으로
23.혼자 공부하는 머신러닝 + 딥러닝 05-3 확인 문제
① 단체 학습② 오케스트라 학습③ 심포니 학습④ 앙상블 학습① 엑셀 데이너② CSV 데이터③ 데이터베이스 데이터④ 이미지 데이터① 랜덤 포레스트② 엑스트라 트리③ 그레이디언트 부스팅④ 히스토그램 기반 그레이디언트 부스팅<풀이>나머지 세 보기는 대표적인 정형 데이터
24.혼자 공부하는 머신러닝 + 딥러닝 06-1 비지도 학습
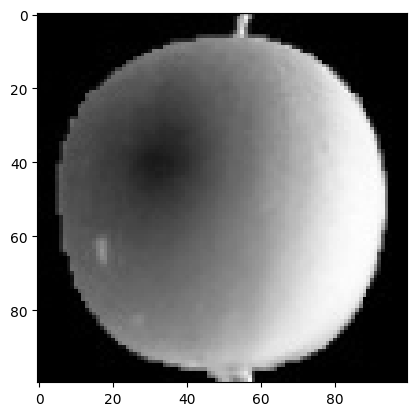
타깃을 모르는 비지도 학습 비지도 학습(unsupervised learning) : 타깃 없을 때 사용하는 머신러닝 알고리즘. 사람이 가르쳐 주지 않아도 데이터 있는 무언가를 학습하는 것. 과일 사진 데이터 준비하기 _+ !는?? '!' 문자로 시작하면 코랩은 이후
25.혼자 공부하는 머신러닝 + 딥러닝 06-1 확인 문제

① hist()② scatter()③ plot()④ bar()<풀이>② scatter()는 산점도를 그리는 함수③ plot()은 선 그래프 그리는 함수④ bat()는 막대그래프 그리는 함수
26.혼자 공부하는 머신러닝 + 딥러닝 06-2 k-평균
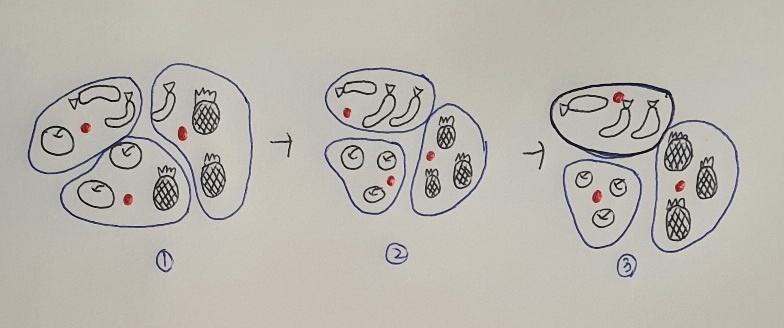
1절에서는 사과, 파인애플, 바나나에 있는 각 픽셀의 평균값 구해서 가장 가까운 사진 골랐음. 이 경우에는 사과, 파인애플, 바나나 사진임을 미리 알고 있었기 때문에 각 과일의 평균 구할 수 있었지만, 진짜 비지도 학습에서는 사진에 어떤 과일이 들어 있는지 알지 못함.
27.혼자 공부하는 머신러닝 + 딥러닝 06-2 확인문제
① 클러스터에 속한 샘플의 평균② 클러스터 중심③ 센트로이드④ 클러스터에 속한 샘플 개수① 엘보우 방법을 사용해 이너셔의 감소 정도가 꺾이는 클러스터 개수를 찾는다.② 랜덤하게 클러스터 개수를 정해서 k-평균 알고리즘을 훈련하고 가장 낮은 이너셔가 나오는 클러스터 개수
28.혼자 공부하는 머신러닝 + 딥러닝 06-3 주성분 분석
차원과 차원 축소 과일 사진의 경우 10,000개의 픽셀이 있어 10,000개의 특성이 있다라고 했다. 이런 특성은 차원(dimension) 이라고도 부른다. 10,000개의 특성은 결국 10,000개의 차원이라는 건데 이 차원을 줄일 수 있다면 저장 공간을 크게 절약
29.혼자 공부하는 머신러닝 + 딥러닝 06-3 확인문제
① 10개② 20개③ 50개④ 100개① (1000, 10)② (10, 1000)③ (10, 10)④ (1000, 1000)① 첫 번재 주성분② 다섯 번째 주성분③ 열 번째 주성분④ 알 수 없음<풀이>3\. 답 ① 주성분 분석은 가장 분산이 큰 방향부터 순서대로
30.혼자 공부하는 머신러닝 + 딥러닝 07-1 인공 신경망
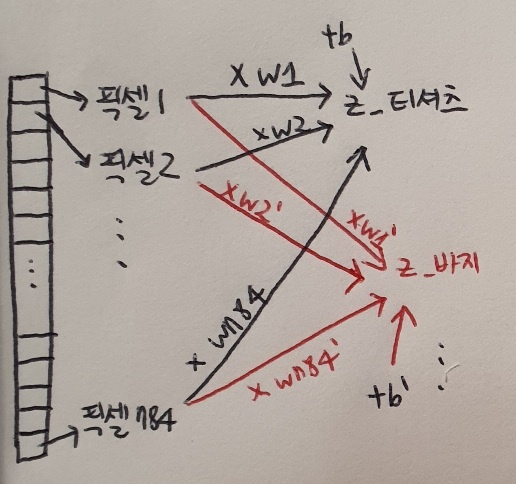
패션 MNIST 텐서플로(TensorFlow) 사용해 패션 MNIST 불러오자. 코랩에서 텐서플로의 케라스(Keras) 패키지 임포트하면 다운로드 할 수 있다. keras.datasets.fashionmnist 모듈 아래 loaddata() 함수는 친절하게 훈련 데이
31.혼자 공부하는 머신러닝 + 딥러닝 07-1 확인 문제
① 1,000개② 1,001개③ 1,010개④ 1,100개① 'binary'② 'sigmoid'③ 'softmax'④ 'relu'① configure()② fit()③ set()④ compile()① 'sparse_categorical_crossentropy'② 'ca
32.혼자 공부하는 머신러닝 + 딥러닝 07-2 심층 신경망
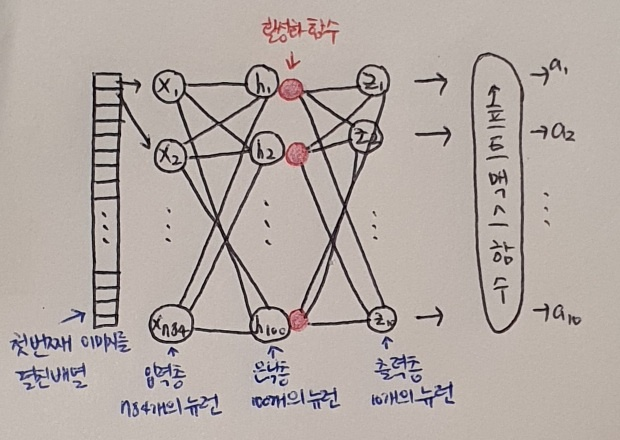
그 다음 이미지의 픽셀값을 0-255 범위에서 0-1 사이로 변환하고, 28 x 28 크기의 2차원 배열을 784 크기의 1차원 배열로 펼친다. 마지막으로 사이킷런의 train_test_split() 함수로 훈련 세트와 검증 세트로 나눈다. 여기까지는 1절에서 했던 것
33.혼자 공부하는 머신러닝 + 딥러닝 07-2 확인 문제
① model.add(keras.layers.Dense)② model.add(keras.layers.Dense(10, actibation='relu'))③ model.add(keras.layers.Dense, 10, activation='relu')④ model.add
34.혼자 공부하는 머신러닝 + 딥러닝 07-3 신경망 모델 훈련
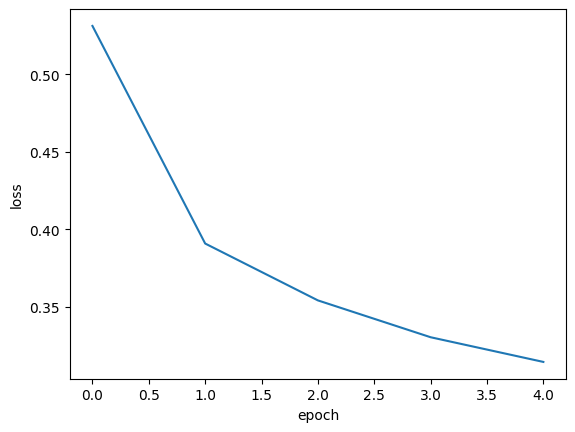
2절에서 fit() 메서드 모델을 훈련하면 훈련 과정이 상세하게 출력되어 확인할 수 있었다. 여기에는 에포크 횟수, 손실, 정확도 등이 있었다. 그런데 이 출력의 마지막에 다음과 같은 메시지를 본 적이 있을 것이다.<tensorflow.python.keras.ca
35.혼자 공부하는 머신러닝 + 딥러닝 07-3 확인 문제
① model.fit(... val_input=val_input, val_target=val_target)② model.fit(... validation_input=val_input, validation_target=val_target)③ model.fit(... va