도서 데이터 찾기
문제에 맞는 데이터가 없는 상황은 종종 발생한다. 이때 딱 맞는 데이터는 아니더라도 어느 정도 비슷한 데이터를 찾을 수 없는지 생각해보자. 공개 데이터 세트를 찾아보거나 데이터 과학과 관련된 온라인 포험에 질문을 올려서 도움 요청할 수 있다.
코랩에서 데이터 확인하기
앞으로 엑셀 파일(.xlsx) 대신에 실습에 적합한 CSV 파일을 사용한다. CSV(comma-separated values) 파일은 콤마(,)로 구분된 텍스트 파일이다. 한 줄이 하나의 레코드(record)이며 레코드는 콤마로 구분된 여러 필드(field)로 구성된다. 데이터는 엑셀처럼 표 형태여야 하기 때문에 레코드에 있는 필드 개수는 모두 동일하다.
엑셀에서 보았떤 행(row)은 CSV 파일에서 한 줄로 표현된다. 열(column)은 콤마로 구분된다. 엑셀은 행과 열이 셀로 구분되어 있어 보기 편하지만, 콤마로 구분된 CSV 파일은 보기에 불편하다. 하지만 텍스트를 단순하게 낭려한 구조라서 파이썬 같은 프로그래밍 언어에서는 오히려 사용하기 편하다.
코랩에 데이터 다운로드하기 :gdown 패키지
- 코랩에 접속한 후 [파일] - [새 노트] 메뉴를 선택해서 빈 코랩 노트북을 만든다.
- 빈 코드 셀에서 다음과 같이 gdown 패키지를 임포트하는 코드를 작성하고 [셀 실행] 아이콘 또는 Ctrl + Enter 키를 눌러 코드를 실행합니다. 구글 드라이브에 있는 CSV 파일이 다운로드 됩니다.
import gdown
gdown.download('https://bit.ly/3eecMKZ', '남산도서관 장서 대출목록 (2021년 04월).csv', quiet=False)_+ gdown 패키지는 구글 드라이브를 포함하여 웹에서 대용량 파일을 다운로드할 수 있는 패키지.코랩에 이미 설치되어 있기 때문에 편리하게 사용 가능!
- 이 코드를 실행한 결과는 다음 화면과 같다. 이 방식 사용하면 다운로드 코드가 노트북에 저장되기 때문에 노트북 다시 열 때 이 코드 셀만 실행해주면 CSV 파일이 자동으로 준비된다.

내 컴퓨터 파일을 업로드하기
- 코랩에 파일을 업로드하려면 목차 창의 왼쪽에 위치한 [파일] 아이콘을 클릭하여 파일 창을 연다. 그 다음 내 컴퓨터에 있는 CSV 파일을 마우스로 드래그하여 파일 창 안에 놓는다.
- 코랩에 파일을 업로드할 때는 '이 런타임이 재활용되면 업로드된 파일은 삭제됩니다'와 같은 경고 메시지가 나타난다. 코랩은 구글에서 무료로 제공하는 자원이기 때문에 일정 시간(약 90분) 도안 사용하지 않으면 자동으로 런타임과 연결이 끊어진다. 이떄 업로드한 파일도 함께 삭제된다. 따라서 나중에 코랩에서 이 파일을 사용하려면 다시 업로드해야한다.
파이썬으로 CSV 파일 출력하기
CSV 파일은 텍스트 파일이므로 파이썬의 open() 함수로 읽을 수 있다. with 문으로 파일을 연 다음 readline() 메서드로 파일에서 한 줄을 읽어서 줄력해 보자
open() 함수에는 gdown 패키지로 다우로드한 파일과 같은 이름을 적어 준다. 파일 이름을 다르게 씀녀 파일을 찾을 수 없다는 FileNotFoundError 오류가 발생하니 주의!
with open('남산도서관 장서 대출목록 (2021년 04월).csv') as f:
print(f.readline())
>>> UnicodeDecodeError Traceback (most recent call last)
<ipython-input-2-11f2049e611f> in <cell line: 1>()
1 with open('남산도서관 장서 대출목록 (2021년 04월).csv') as f:
----> 2 print(f.readline())
/usr/lib/python3.10/codecs.py in decode(self, input, final)
320 # decode input (taking the buffer into account)
321 data = self.buffer + input
--> 322 (result, consumed) = self._buffer_decode(data, self.errors, final)
323 # keep undecoded input until the next call
324 self.buffer = data[consumed:]
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb9 in position 0: invalid start byteUnicodeDecodeError 오류에서 오류 메시지의 마지막 줄을 자세히 보니 utf-8 코덱이 어떤 바이트를 읽을 수 없다는 오류다!
파이썬의 open() 함수는 기본적으로 텍스트 파일이 UTF-8 형식으로 저장되어 있다고 가정한다. 하지만 한글 텍스트는 여전히 완성형 인코딩인 EUC-KR을 사용하는 일이 잦다.
파일 인코딩 형식 확인하기 : chardet.detect() 함수
파이썬에서 chardet 패키지의 chardet.detect() 함수를 사용하면 문자 인코딩 방식을 알아낼 수 있다. 이 패키지도 코랩에 이미 설치 되어 있음!
코드를 작성하면 open() 함수로 텍스트 파일을 열 때 mode 매개변수를 바이너리(binary) 일기 모드인 'rb'로 저장한다. 바이너리 모드로 지정하면 문자 인코딩 형식에 상관없이 파일을 열 수 있으므로 오류가 발생하지 않는다.
import chardet
with open('남산도서관 장서 대출목록 (2021년 04월).csv', mode='rb') as f:
d = f.readline()
print(chardet.detect(d))
>>> {'encoding': 'EUC-KR', 'confidence': 0.99, 'language': 'Korean'}예상대로 EUC-KR이 맞다! 이 CSV 파일은 UTF-8이 아니라 EUC-KR로 인코딩되어 있어 open() 함수에서 오류가 발생한 것!
인코딩 형식 지정하기
open() 함수로 파일을 읽을 때 encoding 매개변수로 인코딩 형식을 'EUC-KR'로 지정하면 된다!
with open('남산도서관 장서 대출목록 (2021년 04월).csv', encoding='euc-kr') as f:
print(f.readline())
print(f.readline())
>>> 번호,도서명,저자,출판사,발행년도,ISBN,세트 ISBN,부가기호,권,주제분류번호,도서권수,대출건수,등록일자,
"1","인공지능과 흙","김동훈 지음","민음사","2021","9788937444319","","","","","1","0","2021-03-19",성공!! 마지막 콤마(,)에 대한 이야기는 뒤에서 설명!
CSV 파일은 판다스 같은 도구로 읽는 것이 조금 더 편리하다. 그러나 아주 큰 파일을 열 때는 오랜 시간이 걸리거나 아예 열 수 없을 때도 있다. 그럴 때는 파이썬의 open() 함수와 readline() 메서드로 처음 몇 줄을 출력해 보는 것이 빠르게 파일의 내용을 확인할 수 있는 좋은 방법이다.
하지만 CSV 파일은 한 줄씩 읽어서 데이터 분석하기 어렵기 때문에 CSV 파일을 앍고 처리하는데 용이한 함수를 많이 제공하는 판다스 패키지를 사용해보자!
데이터프레임 다루기: 판다스
판다스는 CSV 파일을 읽어 데이터프레임(Dataframe) 이라는 표 형식 데이터(tabular data)로 저장한다.
표 형식 데이터는 행과 열로 구성된 데이터 구조를 말한다. CSV, 엑셀, 판다스 데이터프레임도 여기에 속한다. 아래 그림을 보면 쉽게 이해할 수 있다. 엑실 시트와 매우 비슷!!
[그림 삽입]
판다스에는 데이터프레임 외에 시리즈(series) 라는 데이터 구조도 있다. 데이터프레임과 시리즈를 배열에 비유해서 설명해보면,
배열은 같은 종류의 데이터가 순서대로 나열된 데이터 구조를 말한다. 배열은 나열된 축이 하나인 경우 1차원 배열, 축이 2개인 경우 2차원 배열이라고 한다.
[그림삽입]
판다스 시리즈는 그림과 같은 1차원 배열과 매우 비슷하다. 이때 시리즈에 감긴 데이터는 모두 동일한 종류여야 한다. (모두 정수이거나 문자열이어야 한다.)
반면 판다스 데이터프레임은 데이터를 가로 세로로 나열한 2차원 배열과 비슷하다. 앞의 첫 번째 그림처럼 데이터프레임은 열마다 다른 데이터 타입(data type) 을 사용할 수 있다.
대신에 데이터프레임의 같은 열에 있는 데이터는 모두 같은 종류여야 한다. 즉 '저자'열에 문자열과 정수를 섞어 쓸 수 없다. 그래서 데이터프레임의 한 열을 따로 선택하면 시리즈 객체라고 할 수 있다.
CSV 파일을 데이터프레임으로 읽기 : read_csv() 함수
판다스에서 CSV 파일을 읽을 때는 read_csv() 함수를 사용한다. 앞에서 남산도서관 데이터가 EUC-KR로 저장되어 있다는 걸 알았으므로 encoding 매개변수를 'EUC-KR'로 지정하자.
read_csv() 함수를 호출하려면 판다스를 임포트 해야함. 이름은 짧게 줄여 쓰는걸 좋아하여 파이썬의 as 키워드로 임포트할 패키지 이름을 pd로 바꾼다.
import pandas as pd
df = pd.read_csv('남산도서관 장서 대출목록 (2021년 04월).csv', encoding='euc-kr')
>>> <ipython-input-4-e68e0ab15bf0>:1: DtypeWarning: Columns (5,6,9) have mixed types. Specify dtype option on import or set low_memory=False.
df = pd.read_csv('남산도서관 장서 대출목록 (2021년 04월).csv', encoding='euc-kr')코드를 실행하면 'DtypeWarning: Columns (5,6,9) have mixed types. Specify dtype option on import or set low_memory=False'라는 경고가 발생한다. 이 경고가 발생하는 이유는 조금 복잡하다.
판다스는 CSV 파일을 읽을 때 '도서명'과 '대출건수' 같은 열에 어떤 종류의 데이터가 저장되어 있는지 자동으로 파악한다. 가령 '도서명'은 문자열로 인식하고 '대출건수'는 정수로 인식하는 식. 그런데 메모리를 효율적으로 상요하기 위해 CSV 파일으 조금씩 나누어 읽는다. 이때 자동으로 파악한 데이터 타입이 달라지면 경고가 발생한다.
이 파일에서는 'ISBN', '세트 ISBN', '주제분류번호'에 해당하는 5, 6, 9 열 때무에 오류가 발생했다. 해결 방법은 low-memory 매개변수를 False로 지정하여 파일을 나누어 읽지 않고 한 번에 읽는 것이다.
df = pd.read_csv('남산도서관 장서 대출목록 (2021년 04월).csv', encoding='euc-kr',
low_memory=False)
df.head()
판다스는 데이터프레인을 표 형식으로 행과 열을 맞추어 출력한다. 코랩이나 주피터 노트북에서는 행에 교대로 배경색을 넣어 출력해 주기 때문에 더욱 알아보기 좋다.
첫 번째 열은 데이터프레임의 인덱스(index) 이다. 판다스는 행마다 0부터 시작하는 인덱스 번호를 자동으로 붙여준다. 그리고 CSV의 첫 번째 행은 열 이름으로 인식한다. 만약 첫 행에 '번호'라는 열 이름이 중복해서 등장한다면 자동으로 이름 뒤에 숫자를 붙여 고유한 이르믕로 만든다.
CSV 파일의 첫 행이 열 이름이 아니라면 read_csv() 함수를 호출할 때 header 매개변수를 None으로 지정해서 데이터 첫 해에 열 이름이 없다는 것을 알리고, names 매개변수에 열 이름 리스트를 따로 전달해준다. 이때 names 매개변수에 전달하는 열 이름에 중복된 이름이 있어서는 안된다.
그런데 실행 결과의 마지막 열에 원래 CSV 파일에는 없던 'Unnamed: 13' 열이 생겼다. 이 열이 왜 생겼을까?? 앞에서 CSV 파일을 열어봤을 때 각 라인의 끝에 콤마(,)가 있었다. 판다스는 이 콤마를 보고 마지막에 하나의 열이 더 있다고 판단하여 'Unnmaned: 13' 열을 표시한 것이다. CSV 파일이 올바르게 만들어지지 않은 셈이다.
+ 판다스의 read_table() 함수
CSV 파일을 읽을 때는 read_table() 함수도 사용할 수 있다. read_tabel() 함수는 read_csv() 함수와 매우 비슷한다. 콤마(,) 대신 탭(\t)으로 구분된 파일을 읽는데 사용한다. 사실 read_table() 함수는 구분자로 탭을 사용하는 read_csv(sep='\t')와 같다.
데이터프레임을 CSV 파일로 저장하기: to_csv() 메서드
판다스의 데이터프레임을 CSV로 저장할 때는 to_csv() 메서드를 사용한다. to_csv() 메서드는 기본적으로 UTF-8 형식으로 저장하기 때문에 나중에 open() 함수로 파일의 내용을 읽을 때 따로 encoding 매개변수를 사용하지 안아도 된다.
다음과 같이 to_csv() 메서드로 데이터프레임을 ns_202104.csv 파일로 저장한다. 실행 결과는 없지만, 파일 창의 디렉터리에 ns_202104.csv 파일이 생성되어 있다!
저장한 CSV 파일을 다시 open() 함수로 확인해보자. 이번에는 readline() 메서드를 세 번 적는 대신 for 문으로 세 번 반복한다.
with open('ns_202104.csv') as f:
for i in range(3):
print(f.readline(), end='')
>>> ,번호,도서명,저자,출판사,발행년도,ISBN,세트 ISBN,부가기호,권,주제분류번호,도서권수,대출건수,등록일자,Unnamed: 13
0,1,인공지능과 흙,김동훈 지음,민음사,2021,9788937444319,,,,,1,0,2021-03-19,
1,2,가짜 행복 권하는 사회,김태형 지음,갈매나무,2021,9791190123969,,,,,1,0,2021-03-19,앞서 출력했던 CSV 파일 결과와 다르게 CSV 파일 맨 왼쪽에 데이터프레임에 있떤 행 인덱스가 함께 저장되었다. 이 CSV 파일을 다시 데이터프레임으로 읽으면 어떻게 될까??
ns_df = pd.read_csv('ns_202104.csv', low_memory=False)
ns_df.head()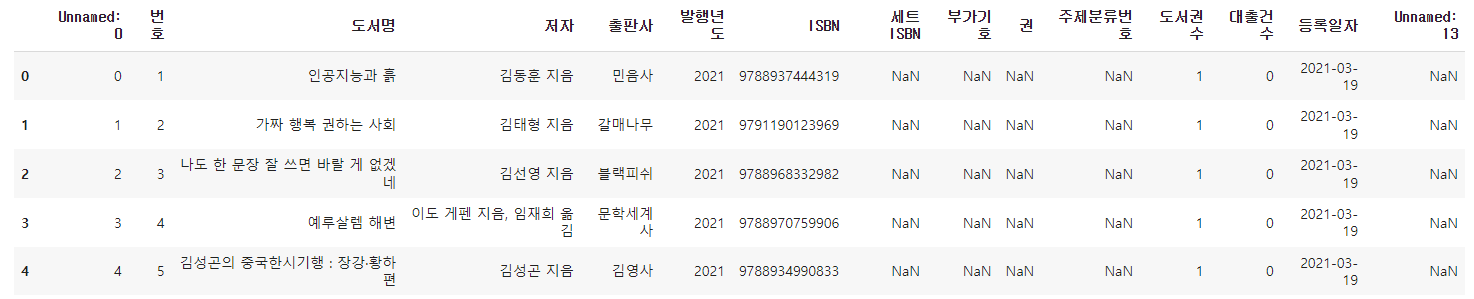
다시 'Unnamed: 0'이라는 첫 번째 열과 중복이 된다.
CSV 파일에 인덱스가 이미 있다는 것을 알려 주려면 index_col 매개변수를 사용한다. ns_202104.csv 파일에는 첫 번째 열에 인덱스가 있으므로 0으로 지정한다.
ns_df = pd.read_csv('ns_202104.csv', index_col=0, low_memory=False)
ns_df.head()
ns_202104.csv 파일의 첫 번째 열이 데이터프레임의 인덱스로 지정된 것을 알 수 있다.
또 다른 방법은 애초에 데이터프레임을 CSV 파일로 저장할 때 인덱스를 뺴고 저장할 수도 있다. 이렇게 하려면 다음처럼 to_index() 메서드에 index 매개변수를 False로 지정한다.
df.to_csv('ns_202104.csv', index=False)_+ 데이터프레임을 엑셀로 저장할 수도 있나요?
가능하다! to_excel() 메서드로 데이터프레임을 엑셀로 저장할 수 있다. to_csv() 메서드와 사용법이 비슷하다.
ns_df.to_excel('ns_202104.xlsx', index=False)판다스는 엑셀 파일을 만들기 위해 기본적으로 openpyxl 패키지를 사용한다. 그런데 이 패키지로 한글 데이터를 쓰면 이따금 오류가 발생한다. 이때는 대신 xlsxwriter 패키지를 사용할 수 있다. 코랩에서 pip 명령어로 xlsxwriter 패키지를 먼저 설치한 후 to_excel() 메서드에 engine='xlsxwriter' 를 지정한다.
!pip install xlswriter
ns_df.to_excel('ns_202104.xlsx', index=False, engine='xlswriter')_
정리
- 공개 데이터 세트는 기업이나 정부 등이 무료로 공개하는 데이터 세트이다. 누구나 저작권에 상관없이 다운로드하여 데이터 분석이나 제품 개발에 활용할 수 있다.
- CSV 파일은 콤마(,)로 구분된 텍스트 파일이다. 한 줄이 한의 레코드이며, 레코드는 콤마로 구분된 여러 필드 혹은 열로 구성된다. 데이터가 엑셀처럼 표 형태ㅡㄹ 가져야 하기 때문에 레코드에 있는 필드 개수는 모두 동일해야 한다.
- 판다스는 표 형식 데이터를 위한 편리한 도구를 다양하게 제공하는 강력한 데이터 분석 패키지이다. CSV나 엑셀 파일을 읽거나 쓸 수 있으며 데이터 분석을 위한 많은 기능을 제공한다.
- 데이터프레임은 판다스읳 ㅐㄱ심 데이터 구조로 행과 열로 구성된다. CSV 파일이나 엑셀 파일로부터 데이터프레임을 만들 수 있다.
- 시리즈는 1차원 배열과 흡사한 판다스의 객체이다. 시리즈는 한 종류의 데이터만 포함할 수 있다.
핵심 함수와 메서드 정리
pandas.read_csv() CSV 파일을 읽어 데이터프레임을 만든다.
DataFrame.head() 데이터프레임에서 처음 다섯 개의 행을 반환한다.
DataFrame.to_csv() 데이터프레임을 CSV 파일로 저장한다.
