선 그래프(line graph)는 데이터 포인트 사이를 선으로 이은 그래프이고, 막대 그래프(bar graph)는 데이터 포인트의 크기를 막대 높이로 나타내는 그래프이다. 이 두 그래프는 전체 데이터의 형태를 가늠할 수 있는 산점도와 조금 다르다.
연도별 발행 도서 개수 구하기
# 데이터 다운로드
import gdown
gdown.download('https://bit.ly/3pK7iuu', 'ns_book7.csv', quiet=False)
# 데이터프레임으로 불러오기
import pandas as pd
ns_book7 = pd.read_csv('ns_book7.csv', low_memory=False)
ns_book7.head()
>>> 번호 도서명 저자 출판사 발행년도 ISBN 세트 ISBN 부가기호 권 주제분류번호 도서권수 대출건수 등록일자
0 1 인공지능과 흙 김동훈 지음 민음사 2021 9788937444319 NaN NaN NaN NaN 1 0 2021-03-19
1 2 가짜 행복 권하는 사회 김태형 지음 갈매나무 2021 9791190123969 NaN NaN NaN NaN 1 0 2021-03-19
2 3 나도 한 문장 잘 쓰면 바랄 게 없겠네 김선영 지음 블랙피쉬 2021 9788968332982 NaN NaN NaN NaN 1 0 2021-03-19
3 4 예루살렘 해변 이도 게펜 지음, 임재희 옮김 문학세계사 2021 9788970759906 NaN NaN NaN NaN 1 0 2021-03-19
4 5 김성곤의 중국한시기행 : 장강·황하 편 김성곤 지음 김영사 2021 9788934990833 NaN NaN NaN NaN 1 0 2021-03-19연도별 도서 개수는 value_counts() 메서드로 구할 수 있다. 데이터프레임의 한 열에서 이 메서드를 호출하면 고유한 값의 등장 횟수를 계산한다.
count_by_year = ns_book7['발행년도'].value_counts()
# 'value_counts()' : 고유한 값의 등장 횟수를 계산한다.
count_by_year
>>>
인덱스 값
2012 18601 ↓ 내림차순
2014 17797
2009 17611
2011 17523
2010 17503
...
2650 1
2108 1
2104 1
2560 1
1947 1
Name: 발행년도, Length: 87, dtype: int64반환된 count_by_year는 판다스의 시리즈 객체이다. 첫 번째 열이 인덱스이고 두 번째 열이 값에 해당한다. 결과에 보이듯이 value_counts() 메서드는 기본적으로 값을 기준으로 내림차순으로 정렬하므로 가장 많은 도서가 발행된 2012년이 맨 처음 등장한다.
하지만 선 그래프의 x축에 지정할 연도는 시간 순으로 배치되는 것이 합리적이다. count_by_year를 인덱스 기준으로 오름차순 정렬을 하려고 하면 시리즈 객체의 sort_index() 메서드를 사용하면 인덱스 순서대로 데이터를 정렬할 수 있다.
count_by_year = count_by_year.sort_index()
# 'sort_index()' : 인덱스순으로 정렬한다.
count_by_year
>>>
1947 1
1948 1
1949 1
1952 11
1954 1
..
2551 1
2552 2
2559 1
2560 1
2650 1
Name: 발행년도, Length: 87, dtype: int64하지만 상식적으로 미래에 발행될 도서가 대출 데이터에 들어 있을 순 없다! 연도가 잘못된 데이터가 들어 있는 것이다. 따라서 여기에서는 count_by_year 객체에서 index 속성이 2030년보다 작거나 같은 데이터만 뽑아 보자.
count_by_year = count_by_year[count_by_year.index <= 2030]
count_by_year
>>>
1947 1
1948 1
1949 1
1952 11
1954 1
...
2020 11834
2021 1255
2025 1
2028 1
2030 1
Name: 발행년도, Length: 68, dtype: int64부등호 기호 사용해 원하는 데이터만 뽑아 추출했다. 3장에서 부등호 기호를 사용해 데이터프레임에서 원하는 행 추출했던 것처럼 시리즈 객체에서도 이런 방법을 사용할 수 있다! 또한 값 뿐만 아니라 인덱스에도 사용 가능하다.
주제별 도서 개수 구하기
이번에는 막대 그래프를 그리기 위한 주제별 도서 개수를 구해보자. 사실 '주제분류번호' 열에는 도서관에서 책을 분류하는 기준인 십진분류 코드가 기입되어 있다. 예를 들면 주제분류번호가 1로 시작하면 철학, 2로 시작하면 종교 도서이다. 또 8로 시작하면 문학 서적이다. 따라서 '주제분류번호' 열의 첫 번째 문자를 기준으로 도서를 카운트하면 주제별 도서 개수를 구할 수 있다.
+ 위키백과의 한국십진분류법 문서 : https://ko.wikipedia.org/wiki/한국십진분류법
'주제분류번호'의 첫 번째 문자만 선택할 수 있다면 value_counts() 메서드를 적용하여 쉽게 도서 개수를 취합할 수 있다. 다만 이 열에는 NaN이 포함되어 있으므로 값이 NaN이라면 -1을 반환하는 함수를 만들어 걸러내야 한다. '주제분류번호' 열의 값을 받아 첫 번째 문자를 반환하는 kdc_1st_char() 함수를 선언한 후 apply() 메서드에 넣어 데이터프레임에 반복 적용한다.
import numpy as np → np.nan 사용하기 위해 넘파이 임포트한다.
def kdc_1st_char(no): → '주제분류번호' 열의 값이 NaN인 경우 -1을 반환한다. 그렇지 않으면 첫 번째 문자를 반환한다.
if no is np.nan:
return '-1'
else:
return no[0]
count_by_subject = ns_book7['주제분류번호'].apply(kdc_1st_char).value_counts()
count_by_subject
>>>
8 108643
3 80767
5 40916
9 26375
6 25070
1 22647
-1 16978
7 15836
4 13688
2 13474
0 12376
Name: 주제분류번호, dtype: int64문학에 해당하는 8로 시작하는 도서가 가장 많은 것으로 나타난다. 여기서 인덱스는 숫자이지만 연도별 발행 도서 개수인 countby_year와는 다르게 순서에 의미가 있지 않다. 즉 철학(1) 서적이 종교(2) 서적보다 더 앞서거나 혹은 더 작은 것이 아니다. 따라서 count_by_year처럼 인덱스 순서대로 정렬할 필요는 없다.
+ 순서가 없는 데이터와 순서가 있는 데이터
순서를 매길 수 없는 데이터를 명목형 데이터(nominal data) 라고 한다. 예를 들면 성별, 국가 등. 반대로 순서가 있을 떄는 순서형 데이터(ordinal data) 라고 한다. 예를 들면 만족도, 성적 등급 등._
선 그래프 그리기
맷플롯립의 plot() 함수는 선 그래프를 그릴 수 있다. 첫 번째 매개변수에는 x축의 값, 두 번째 매개변수에는 y축에 해당하는 값을 전달한다. 일단 서브플롯을 사용하지 않고 간단하게 하나의 피겨 객체를 사용해 선 그래프를 그려보자.
먼저 그래프 해상도를 놓이기 위해 맷플롯립의 기본 DPI를 100으로 바꾼다.
import matplotlib.pyplot as plt
plt.rcParams['figure.dpi'] = 100그 다음 plot() 함수의 두 매개변수에 count_by_year의 연도(index)와 도서 개수(values)를 각각 지정하여 선 그래프를 그린다. 그래프의 의미가 더 잘 드러나도록 제목과 축 이름도 넣어주자. 서브플롯을 사용하지 않을 때는 그래프 제목은 title() 함수, x축 이름과 y축 이름은 각각 xlabel() 함수와 ylabel() 함수를 사용하여 지정한다.
plt.plot(count_by_year.index, count_by_year.values)
plt.title('Books by year')
plt.xlabel('year')
plt.ylabel('number of books')
plt.show()
>>>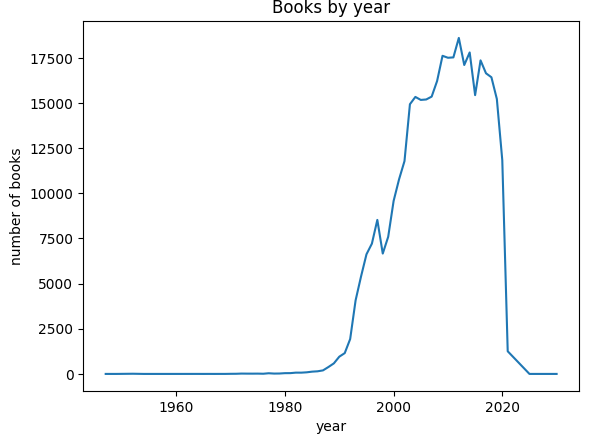
→ 연도별 발행 도서의 추세를 확인하기 위해 plot() 함수의 x축에 연도, y축에 도서 개수를 넣는다.
선 모양과 색상 바꾸기
plot() 함수는 선 모양을 지정할 수 있는 linestyle 매개변수를 제공한다. linestyle 매개변수 기본값은 실선을 나타내는 '-'이다. 이외에도 선 모양을 다음과 같이 지정할 수 있다.
- 실선(solid line) : '-'
- 점선(dotted line) : '.'
- 쇄선(dash dot line) : '-.'
- 파선(dashed line) : '--'
또한 color 매개변수에 색상을 지정할 수 있다. #ff0000 처럼 16진수 컬러 코드를 지정하거나 red처럼 색 이름을 지정할 수 있다. 산점도에서 사용해 보았던 marker 매개변수도 제공한다.
그럼 마커는 점으로, 선은 점선을 사용한 선 그래프를 빨간색으로 다시 그려보자. 이번에는 아의 코드와 다르게 x축의 값과 y축의 값을 각각 시리즈 객체의 index와 values로 지정하지 않고, 시리즈 객체 그대로 plot() 함수에 전달하자. 이렇게 하면 자동으로 인덱스를 x축의 좌표로 사용하여 그래프를 그린다.
plt.plot(count_by_year, marker='.', linestyle=':', color='red')
plt.title('Books by year')
plt.xlabel('year')
plt.ylabel('number of books')
plt.show()
>>>
빨간 선 그래프에 마커까지 있어 데이터 포인트가 명ㅇ확하게 표현되는 것을 알 수 있다!
plot() 함수의 매개변수에 지정한 마커, 선 모양, 색깔을 하나의 문자열로 합쳐서 선 그래프의 포맷으로 나타낼 수도 있다. 이 문자열을 plot() 함수의 x, y축 값 다음에 지정하면 된다. 예를 들어 위 코드의 marker='.', linstlye=':', color='red' 대신 다음과 같이 쓸 수 있다.
plt.plot(count_by_year, '.:r') → 마커, 선 모양, 색깔 옵션을 하나의 문자열로 지정할 수 있다.+ color 매개변수에 지정할 수 있는 색 이름은 어떤 것이 있나요?
color 매개변수에서 지원하는 색 이름 'blue', 'green', 'red', 'cyan', 'magenta', 'yellow', 'black', 'white'이다. 포맷 문자열에 쓸 때는 색 이름의 첫 글지를 사용한다.
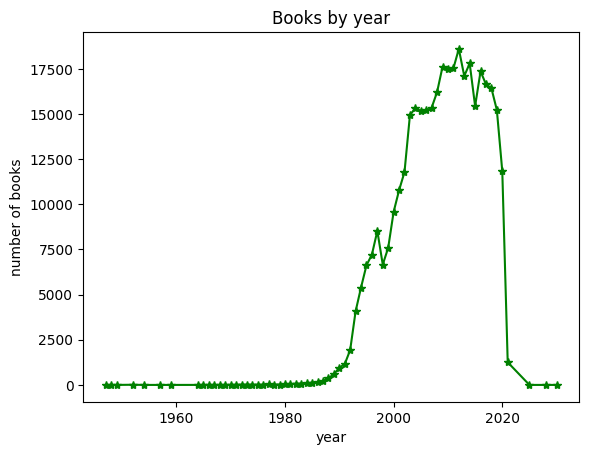
이번에는 별 모양 마커와 실선을 사용한 선 그래프를 녹색으로 그려보자.
plt.plot(count_by_year, '*-g')
plt.title('Books by year')
plt.xlabel('year')
plt.ylabel('number of books')
plt.show()
>>>
선 그래프 눈금 개수 조절 및 마커에 텍스트 표시하기
앞서 그린 선 그래프는 x축 눈금이 4개만 표시되었다. 먼저 눈금 개수를 조금 더 늘려서 그래프를 보기 편하게 만들어 보자. x축 눈금을 지정할 때는 xticks() 함수를 사용하자.
+ y축의 눈금을 설정하는 함수는 무엇인가?
yticks() 함수 사용한다. 또한 서브플롯을 그릴 떄 x축과 y축 눈금을 지정하려면 각각 set_xticks() 메서드와 set_yticks() 메서드를 사용하면 된다. 맷플롯립 함수와 서브플롯 메서드 간의 이러한 이름 규칙은 title() 함수와 set_title() 메서드에서도 쉽게 찾아볼 수 있다.
1947년부터 2030년까지 10년씩 건너뛰면서 x축의 눈금을 표시하기 위해 xticks() 함수 매개변수에 파이썬 range() 함수를 사용하자. 그 다음 연도별 발행 도서 개수를 모두 그래프에 표시하면 너무 많기 때문에 슬라이스 연산자(:)를 사용해 다섯 개씩 건너뛰면서 count_by_year의 값을 선택한다. 시리즈 객체의 items() 메서드를 사용하면 인덱스와 값을 감싼 튜플을 얻을 수 있다.
그래프에 값을 표시할 때는 annotate() 함수를 사용한다. 첫 번째 매개변수에 그래프에 나타낼 문자열을 지정하고, 두 번째 매개ㅕㄴ수에 문자열이 나타날 x, y 좌표를 튜플로 지정한다.
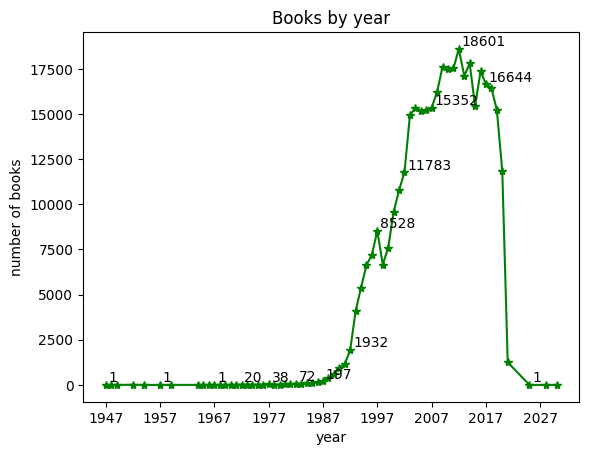
plt.plot(count_by_year, '*-g')
plt.title('Books by year')
plt.xlabel('year')
plt.ylabel('number of books')
plt.xticks(range(1947, 2030, 10))
for idx, val in count_by_year[::5].items(): # '::5' : 슬라이스 연산자의 스텝 옵션을 사용
plt.annotate(val, (idx, val)) # 'val' : 그래프에 나타낼 문자열
# 'idx, val' : 텍스트가 나타날 x, y 좌표
plt.show()
>>>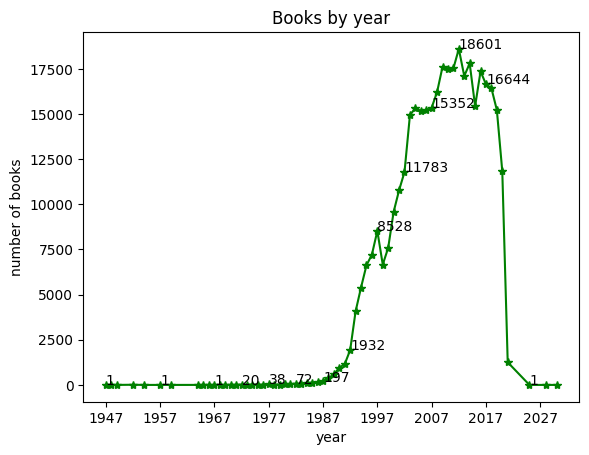
출력된 그래프를 보면 마커 옆에 바로 텍스트가 붙어 있다. 텍스트를 마커에서 조금 뗴어 놓으려면 텍스트 위치를 조절하는 xytext 매개변수를 사용할 수 있다.
# 마커 위치에서 x축은 1만큼, y축으로는 10만큼 떨어지게 지정.
plt.plot(count_by_year, '*-g')
plt.title('Books by year')
plt.xlabel('year')
plt.ylabel('number of books')
plt.xticks(range(1947, 2030, 10))
for idx, val in count_by_year[::5].items():
plt.annotate(val, (idx, val), xytext=(idx+1, val+10))
plt.show()
>>>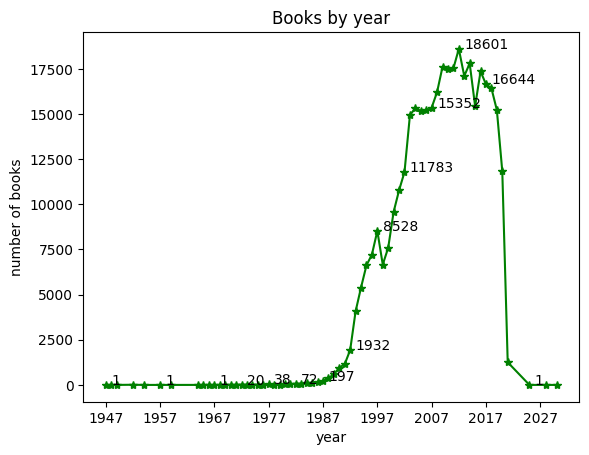
x축으로 1만큼 떨어진 것은 구분 되지만, y축은 ㄱ의 차이가 없다. y축의 스케일(0-17500)이 x축보다 훨씬 크기 때문이다.
따라서 이런 경우에는 상대적인 위치를 포인트나 픽셀 단위로 지정해야 한다. 다음처럼 xytext 매개변수와 함께 textcoords 매개변수를 사용한다.
# 여기서는 textcoords 매개변수에 포인트 단위의 상대 위치를 나타내는 'offset points'를 지정.
plt.plot(count_by_year, '*-g')
plt.title('Books by year')
plt.xlabel('year')
plt.ylabel('number of books')
plt.xticks(range(1947, 2030, 10))
for idx, val in count_by_year[::5].items():
plt.annotate(val, (idx, val), xytext=(2, 2), textcoords='offset points')
plt.show()
>>>
막대 그래프 그리기
맷플롯립에서 bar() 함수는 막대 그래프를 그린다. 앞에서 만든 주제별 도서 개수인 count_by_sybject를 사용해 막대 그래프를 그려보자.
bar() 함수는 plot() 함수와 매우 비슷하다. x축의 값과 막대 높이에 해당하는 y축의 값을 전달하면 된다. 그 외의 제목, 축 이름 등을 표시하는 방법은 동일하다. 여기서는 annotate() 함수로 y축의 값을 표시할 때 텍스트 위치를 xytext=(0, 2)로 지정한다. 막대 그래프이므로 y축 방향으로만 2포인트씩 간격을 띄워 보자.
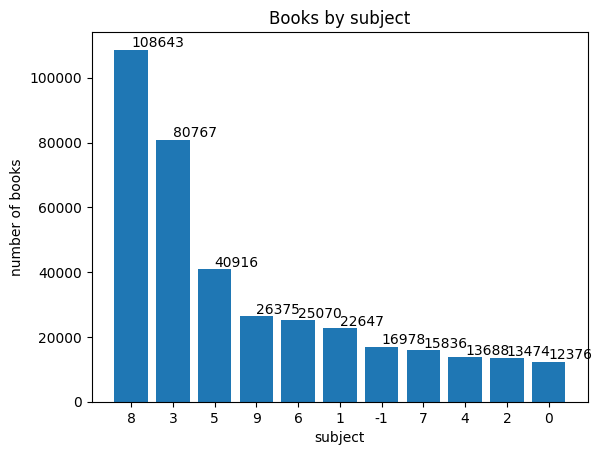
plt.bar(count_by_subject.index, count_by_subject.values)
# x축에는 인덱스인 주제분류번호, y축에는 도서 개수를 전달한다.
plt.title('Books by subject')
plt.xlabel('subject')
plt.ylabel('number of books')
for idx, val in count_by_subject.items():
plt.annotate(val, (idx, val), xytext=(0, 2), textcoords='offset points')
plt.show()
>>>
하나하나 바꿔 보자!
텍스트 정렬, 막대 조절 및 색상 바꾸기
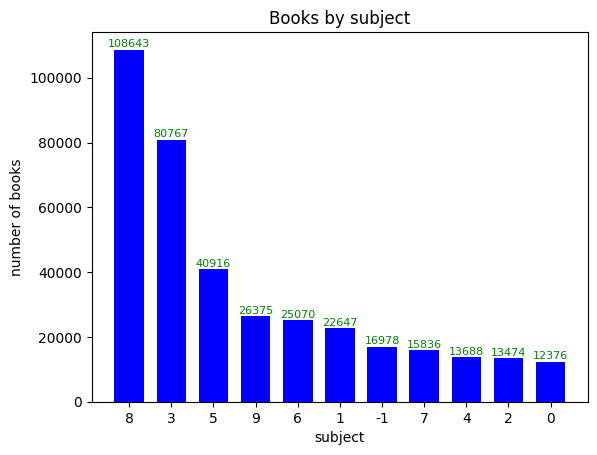
먼저 텍스트가 막대 중아에서 시작한다. 가능하면 텍스트 중앙이 막대의 중앙에 오도록 중앙 정렬하는 것이 좋다. 텍스트 위치 조절은 annotate() 함수의 ha 매개변수에 'center'를 지정하면 된다. 기본값이 'right'이기 때문에 지정하지 않으면 텍스트가 오른쪽으로 정렬되고, 'left'로 지정하면 텍스트가 왼쪽으로 정렬된다. 또한 텍스트가 서로 겹치는 경우가 있으므로 fontsize 매개변수로 텍스트 크기를 줄여 준다. 텍스트 색깔도 color 매개변수에 'green'을 지정하여 녹색으로 출력해보자.
bar() 함수는 막대의 두께를 조절하는 width 매개변수를 제공한다. 기본값은 0.8이다. 여기서는 0.7로 지정하여 막대의 두께를 조금 더 줄여보자. 그리고 color 매개변수에 'blue'를 지정하여 막대 색깔은 파랑으로 출력한다.
plt.bar(count_by_subject.index, count_by_subject.values, width=0.7, color='blue')
plt.title('Books by subject')
plt.xlabel('subject')
plt.ylabel('number of books')
for idx, val in count_by_subject.items():
plt.annotate(val, (idx, val), xytext=(0, 2), textcoords='offset points',
fontsize=8, ha='center', color='green')
plt.show()
>>>
+width 매개변수를 1로 지정하면 막대의 두께가 눈금 간격과 동일해져서 막대 사이에 간격이 사라진다.
가로 막대 그래프 그리기
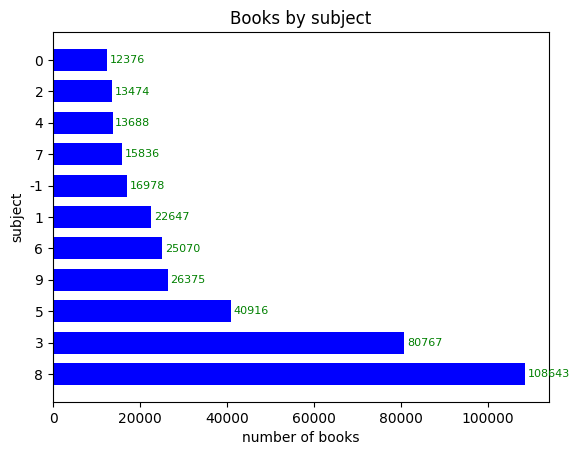
이번에는 barh() 함수를 사용해 같은 데이터를 가로 막대 그래프로 그려보자. barh() 함수에서 막대의 두께를 나타내는 매개변수는 width가 아니라 height 매개변수가 된다. 또 x축과 y축의 이름을 바꾸어 써야 한다.
annotate() 함수에 텍스트 좌표를 쓸 때도 x축과 y축 값이 바뀐다. 따라서 다음 코드처럼 (val, idx)로 써야한다.
plt.barh(count_by_subject.index, count_by_subject.values, height=0.7, color='blue')
plt.title('Books by subject')
plt.xlabel('number of books')
plt.ylabel('subject')
for idx, val in count_by_subject.items():
plt.annotate(val, (val, idx), xytext=(2, 0), textcoords='offset points',
fontsize=8, va='center', color='green')
plt.show()
>>>
막대 그래프의 텍스트를 막대 중앙에 정렬할 때 ha 매개변수를 사용했다면, 가로 막대 그래프에서는 va 매개변수를 사용한다. 기본값은 'baseline'으로 텍스트 밑면을 막대 중앙에 맞춘다. 여기서는 텍스트 중앙을 막대 중앙에 정렬하기 위해 'center'로 지정한다. 이외에도 위로 정렬하는 'top'과 아래로 정렬하는 'bottom'이 있다. 또 xytext 매개변수를 (2,0)으로 지정하여 x축 방향으로만 2포인트 간격을 두었다.
맷플롯립으로 선 그래프와 막대 그래프 그리기
연도별 데이터로는 선 그래프를 그려 제목과 축 이름을 지정하는 방법, 선 스타일과 마커를 지정하는 방법 그래프에 텍스트를 표시하는 방법을 알아보았다.
주제별 데이터로는 막대 그래프를 그렸다. 막대 그래프를 그리는 방법으 선 그래프를 그리는 것과 매우 비슷한데 추가로 막대의 두꼐를 조정하거나 텍스트를 막대의 중앙에 정렬하는 방법을 배웠다.
마지막으로 가로 막대 그래프를 그리는 방법을 알아보았다. 가로 막대 그래프를 그릴 때는 축 이름을 바꿔 써야 하고 텍스트의 x, y좌표가 바뀌어야 한다는 것을 기억하자!
좀더 알아보기 _ 이미지 출력하고 저장하기
데이터 분석 작업을 하다 보면 이따금 이미지를 로드하여 출력해야 할 일이 생긴다. 이를 위해 맛플롯립에서 제공하는 몇 가지 함수를 사용해 이미지를 출력하고 저장하는 방법을 알아보자.
# 노트북이 코랩에서 실행 중인지 체크합니다.
import sys
if 'google.colab' in sys.modules:
# 샘플 이미지를 다운로드합니다.
!wget https://bit.ly/3wrj4xf -O jupiter.png이미지 읽기
맷플롯립에서 이미지를 읽을 때는 imread() 함수를 사용한다. 간단히 파일 이름을 전달함녀 이미지를 읽어 넘파이 배열을 반환해준다.
img = plt.imread('jupiter.png')
img.shape
>>> (1561, 1646, 3)이미지를 읽어 반환된 배열의 크기는 각각 이미지의 높이, 너비, 채널을 의미한다.
이미지 화면에 출력하기
이미지를 배열로 읽은 후 화면에 표시하려면 imshow() 함수를 사용한다.
plt.imshow(img)
plt.show()
>>>
imshow() 함수는 피겨 크기에 상관없이 기본적으로 원본 이미지의 가로세로 비율을 유지한다. 따라서 다음처럼 피겨 크기를 직사각형 크기로 설정하더라도 이미지의 가로세로 비율이 동일하다. 또한 이미지에 표시된 축과 눈금을 출력하지 않으려면 axis() 함수를 'off'로 지정하면 된다.
plt.figure(figsize=(8, 6))
plt.imshow(img)
plt.axis('off')
plt.show()
>>>
→ 이미지와 같이 표시되었던 축과 눈금이 사라짐!
+ 만약 가로세로 비율이 달라지더라도 피겨 크기에 맞추어 이미지를 출력하고 싶다면 imshow() 함수의 aspect 매개변수를 'auto'로 설정하면 된다.
+ 이미지 처리에 유용한 Pillow 패키기
사실 맷플롯립의 imread() 함수는 파이썬의 Pillow 패키지를 사용하여 이미지를 로드한다. Pillow 패키지는 이미지를 분석하거나 처리할 수 있는 유용한 기능을 제공한다. 따라서 직접 Pillow 패키지를 사용해도 앞서 imshow() 함수를 사용한 것과 동일한 결과를 얻을 수 있다. Pillow 패키지는 맷플롯립을 설치할 때 자동으로 설치되므로 따로 설치할 필요는 없다.
from PIL import Image
pil_img = Image.open('jupiter.png')
plt.figure(figsize=(8, 6))
plt.imshow(pil_img)
plt.axis('off')
plt.show()
# pil_img는 Pillow의 이미지 객체이다. 이를 넘파이 배열로 바꾸려면 간단히 넘파이 array() 함수로 전달만 하면 된다.
import numpy as np
arr_img = np.array(pil_img)
arr_img.shape
>>> (1561, 1646, 3) # imread() 함수를 사용했을 떄와 결과가 같다.이미지 저장하기
맷플롯립의 imsave() 함수를 사용하여 넘파이 배열로 ㅇ릭은 이미지를 저장할 수도 있다. 이 함수의 첫 번째 매개변수는 저장할 파일 이름이고, 두 번째 매개변수는 이미지가 저장된 넘파이 배열이다. 편리하게도 이 함수는 파일 이름의 확장자를 사용해 자동으로 이미지를 변환해 준다. 따라서 다음처럼 목성 이미지를 JPEG 포맷으로 저장할 수 있다.
plt.imsave('jupiter.jpg', arr_img)좀더 알아보기 _ 그래프를 이미지로 저장하기
맷플롯립의 savefig() 함수를 사용하면 그래프를 이미지로 저장할 수 있다. 이 함수의 첫 번째 매개변수는 저장할 이미지의 파일 이름이다. dpi 매개ㅕㄴ수에는 그래프를 저장할 때 사용할 DPI를 따로 지정할 수 있다. 또는 rcParams['savefig.dpi']로 DPI를 지정할 수 있다. 기본값은 'figure'로 피겨에서 설정한 DPI를 따른다.
plt.rcParams['savefig.dpi']
>>> 'figure'마짐가에 그린 가로 막대 그래프를 savefig() 함수로 저장해보자. show() 함수가 호출되면 피겨 객체가 자동으로 소멸되므로 show() 함수 이전에 savefig()를 호출해야 한다.
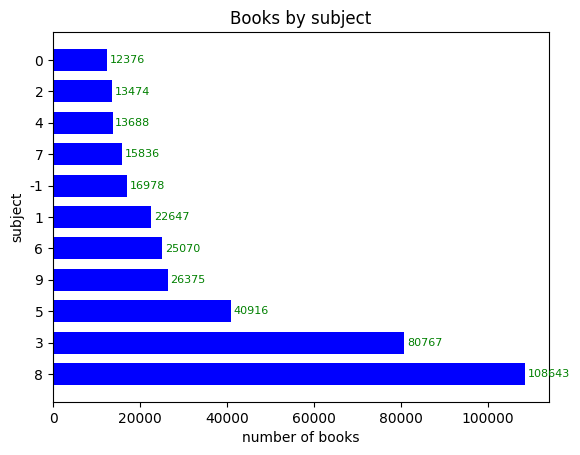
plt.barh(count_by_subject.index, count_by_subject.values, height=0.7, color='blue')
plt.title('Books by subject')
plt.xlabel('number of books')
plt.ylabel('subject')
for idx, val in count_by_subject.items():
plt.annotate(val, (val, idx), xytext=(2, 0), textcoords='offset points',
fontsize=8, va='center', color='green')
plt.savefig('books_by_subject.png')
plt.show()
>>>
저장된 파일을 불러서 다시 출력해보자.
pil_img = Image.open('books_by_subject.png')
plt.figure(figsize=(8, 6))
plt.imshow(pil_img)
plt.axis('off')
plt.show()
>>>
정리
- 선 그래프는 각 데이터 포인트를 직선으로 연결한 그래프이다. 선의 스타일이나 마커의 모양을 바꾸어 풍부하게 표현할 수 있고 데이터값을 그래프에 텍스트로 쓸 수도 있다.
- 막대 그래프는 데이터 포인트의 크기를 막대 높이로 나타낸 그래프이다. 전형적으로 x좌표는 연속적이지 않은 범주형이며 y좌표는 해당 범주의 값이다. 가로 막대 그래프는 값이 클수록 막대의 길이가 가로로 길어진다.
핵심 함수와 메서드
- matplotlib.pyplot.plot() : 선 그래프를 그린다.
- matplotlib.pyplot.title() : 그래프 제목을 설정한다.
- matplotlib.pyplot.xlabel() : x축 이름을 지정한다.
- matplotlib.pyplot.ylabel() : y축 이름을 지정한다.
- matplotlib.pyplot.xticks() : x축의 눈금 위치와 레이블을 지정한다.
- matplotlib.pyplot.annotate() : 지정한 좌표에 텍스트를 출력한다.
- matplotlib.pyplot.bar() : 세로 막대 그래프를 그린다.
- matplotlib.pyplot.barh() : 가로 막대 그래프를 그린다.
- matplotlib.pyplot.imread() : 이미지 파일을 넘파이 배열로 읽어들인다.
- matplotlib.pyplot.imshow() : 이미지를 출력한다.
- matplotlib.pyplot.imsave() : 넘파이 배열을 이미지 파일로 저장한다.
- matplotlib.pyplot.savefig() : 그래프를 이미지로 저장한다.
