실습 준비하기
실습 환경 설정하기!
# 한글 폰트 설치
# 노트북이 코랩에서 실행 중인지 체크합니다.
import sys
if 'google.colab' in sys.modules:
!echo 'debconf debconf/frontend select Noninteractive' | debconf-set-selections
# 나눔 폰트를 설치합니다.
!sudo apt-get -qq -y install fonts-nanum
import matplotlib.font_manager as fm
font_files = fm.findSystemFonts(fontpaths=['/usr/share/fonts/truetype/nanum'])
for fpath in font_files:
fm.fontManager.addfont(fpath)
# 폰트 기본값을 'NanumBarunGothic'으로 설정 후 그래프 잘 보이도록 해상도 기본값 100으로 높여준다.
import matplotlib.pyplot as plt
# 나눔바른고딕 폰트로 설정합니다.
plt.rc('font', family='NanumBarunGothic')
# 그래프 DPI 기본값을 변경합니다.
plt.rcParams['figure.dpi'] = 100
# 데이터 다운로드하고 판다스 데이터프레임으로 불러온다.
import gdown
gdown.download('https://bit.ly/3pK7iuu', 'ns_book7.csv', quiet=False)
import pandas as pd
ns_book7 = pd.read_csv('ns_book7.csv', low_memory=False)
ns_book7.head()
>>> 번호 도서명 저자 출판사 발행년도 ISBN 세트 ISBN 부가기호 권 주제분류번호 도서권수 대출건수 등록일자
0 1 인공지능과 흙 김동훈 지음 민음사 2021 9788937444319 NaN NaN NaN NaN 1 0 2021-03-19
1 2 가짜 행복 권하는 사회 김태형 지음 갈매나무 2021 9791190123969 NaN NaN NaN NaN 1 0 2021-03-19
2 3 나도 한 문장 잘 쓰면 바랄 게 없겠네 김선영 지음 블랙피쉬 2021 9788968332982 NaN NaN NaN NaN 1 0 2021-03-19
3 4 예루살렘 해변 이도 게펜 지음, 임재희 옮김 문학세계사 2021 9788970759906 NaN NaN NaN NaN 1 0 2021-03-19
4 5 김성곤의 중국한시기행 : 장강·황하 편 김성곤 지음 김영사 2021 9788934990833 NaN NaN NaN NaN 1 0 2021-03-19하나의 피겨에 여러 개의 선 그래프 그리기
한 피겨에 여러 개의 선 그래프를 그려야 할 때가 있다. 예를 들면 회사의 제품별 매출 현황을 비교하고 싶다면 x축을 연/월로 하고 y축을 매출로 한다. 그리고 각 제품의 매출 데이터를 선 그래프로 표시한다.
맷플롯립에서 여러 개의 선 그래프를 그리는 방법은 의외로 간단하다! 선 그래프를 그리는 plot() 함수를 여러 번 호출하는 것이 전부!
# 전체 출판사 모두 그리기 어렵기에 상위 30위 정도의 고유한 출판사 목록 고르기
top30_pubs = ns_book7['출판사'].value_counts()[:30]
top30_pubs_idx = ns_book7['출판사'].isin(top30_pubs.index)
# 상위 30위에 해당하는 출판사는 True로 표시하여 불리언 배열로 반환.
# ns_book7 데이터프레임에서 상위 30위에 해당하는 '출판사', '발행년도', '대출건수' 열만 추출
ns_book9 = ns_book7[top30_pubs_idx][['출판사', '발행년도', '대출건수']]
# groupby() 메서드 사용해 '출판사'와 '발행년도' 열 기준으로 행 모은 후 sum() 메서드로 '대출건수' 열의 합 구해준다.
ns_book9 = ns_book9.groupby(by=['출판사', '발행년도']).sum()
# 인덱스 초기화 위해 rest_index() 메서드 호출
ns_book9 = ns_book9.reset_index()
ns_book9[ns_book9['출판사'] == '황금가지'].head()
>>> 출판사 발행년도 대출건수
858 황금가지 1995 0
859 황금가지 1996 67
860 황금가지 1997 116
861 황금가지 1998 526
862 황금가지 1999 505선 그래프 2개 그리기
# 출판사 별로 각각 데이터프레임 만듦
line1 = ns_book9[ns_book9['출판사'] == '황금가지']
line2 = ns_book9[ns_book9['출판사'] == '비룡소']
# 그 다음 line1과 line2 데이터프레임의 '발행년도' 열과 '대출건수' 열로 plot() 함수를 두 번 호출한다
fig, ax = plt.subplots(figsize=(8, 6))
ax.plot(line1['발행년도'], line1['대출건수'])
ax.plot(line2['발행년도'], line2['대출건수'])
ax.set_title('년도별 대출건수')
fig.show()
>>>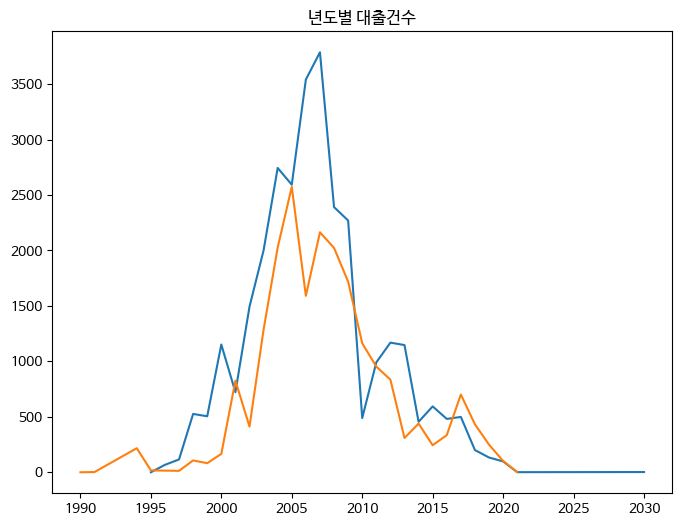
파란색이 '황금가지' 출판사 그래프, 붉은색이 '비룡소' 출판사 그래프.
맷플롯립은 똑똑하게 plot() 함수를 호출할 때 별도로 색 지정하지 않아도 자동으로 선 그래프마다 다른 색으로 그린다.
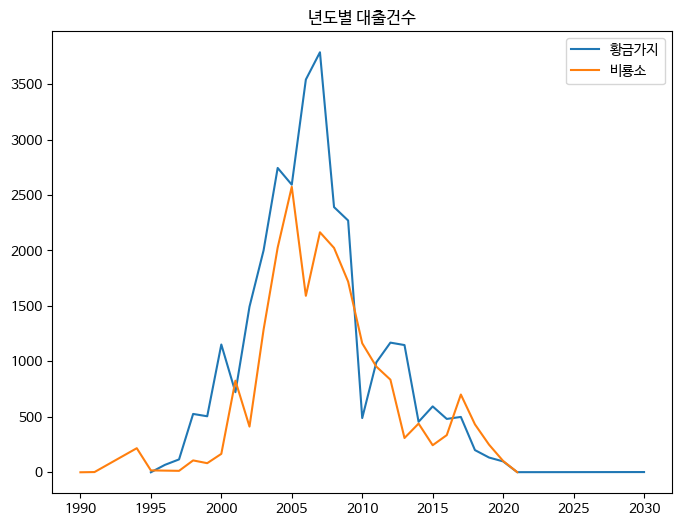
많은 선 그래프를 그린다면 구분하기 쉽지 않은데, 이를 위해 그래프에 범례(legend)를 추가하면 그래프 이해하는 데 아주 도움이 된다. plot() 함수를 호출할 때 각 선 그래프에 레이블(lable)을 추가하고, 마지막에 legend() 메서드를 호출하면 범례가 추가된다.
fig, ax = plt.subplots(figsize=(8, 6))
ax.plot(line1['발행년도'], line1['대출건수'], label='황금가지') # 레이블 추가
ax.plot(line2['발행년도'], line2['대출건수'], label='비룡소') # 레이블 추가
ax.set_title('년도별 대출건수')
ax.legend() # 범례 추가
fig.show()
>>>
선 그래프 5개 그리기
상위 5개 출판사의 '발행년도'에 대한 '대출건수' 그래프를 그려보자. 아래 코드는 앞에서 했던 것과 동일하지만, 5개 출판사에 대한 데이터프레임을 각각 만들지 않고 대신 for 문과 슬라이스 연산자를 사용해 선 그래프를 그린다.
fig, ax = plt.subplots(figsize=(8, 6))
for pub in top30_pubs.index[:5]:
line = ns_book9[ns_book9['출판사'] == pub]
ax.plot(line['발행년도'], line['대출건수'], label=pub)
ax.set_title('년도별 대출건수')
ax.legend()
ax.set_xlim(1985, 2025)
fig.show()
>>>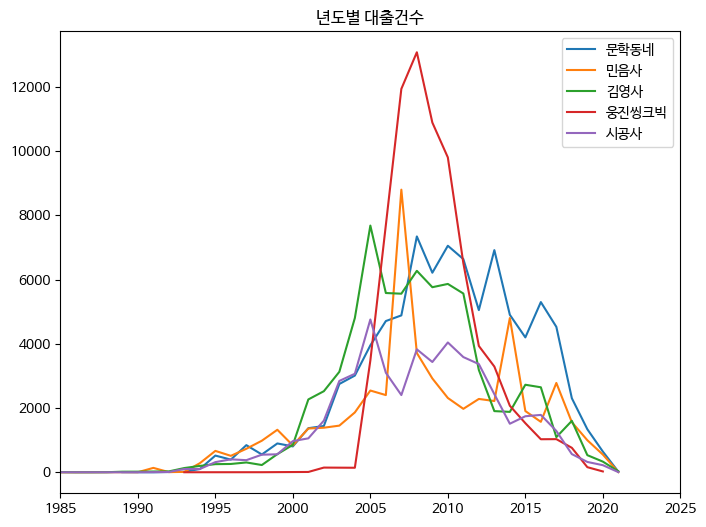
원래 이 그래프는 1970년대부터 시작하기에 연도 범위를 지정하지 않으면 오른쪽으로 많이 치우쳐 있다. 이를 피하기위해 대부분의 대출건수가 발생한 1990년대 이후 데이터가 중점적으로 보이도록 set_xlim() 메서드를 사용했다. 이 메서드에는 그래프로 출력할 x축의 좌표 범위를 지정한다. 첫 번째 매개변수는 x축의 최솟값이고 두 번째 매개변서는 x축의 최댓값이다. 비슷하게 y축의 좌표를 지정하려면 set_ylim() 메서드를 사용한다.
+ matplotlib.pyplot을 사용할 때는 xlim(), ylim() 함수를 사용하면 되나요?
맞다! plt.xlim(), plt.ylim()처럼 사용하면 된다! 이외에도 axis() 함수에는 x축의 범위와 y축의 범위를 리스트로 묶어 전달해야 한다.
plt.axis([1985, 2025, 0, 13000]) # 앞 두 개 x축, 뒤 두 개 y축이 리스트 값은 순서대로 x축의 최솟값, x축의 최댓값, y축의 최솟값, y축의 최댓값이다. 또한 이 함수는 객체지향 API에서도 동일한 이름을 사용한다. 즉 ax.set_axis([1985, 2025, 0, 130000])가 아니라 ax.axis([1985, 2025, 0, 13000])처럼 써야 한다.
범례 추가했지만, 그래프에서 5개의 출판사를 구분하기 쉽지 않다. 각 선 그래프가 서로 많이 교차하기 때문이다. 이런 경우에는 선 그래프보다 스택 영역 그래프를 그리는 것이 좋다!
스택 영역 그래프
스택 영역 그래프(stacked area graph)는 말 그대로 하나의 선 그래프 위에 다른 선 그래프를 차례때로 쌓는 것이다. 그래프 사이의 간격이 y축의 값이 된다. 이해를 도울 수 있도록 그림으로 표현하면 다음과 같다.
[356 상단 그림 삽입]
이러한 스택 영역 그래프는 맷플롯립의 stackplot() 메서드로 그릴 수 있다. 이 메서드는 첫 번째 매개변수에 x축의 값인 '발행년도'를 전달하고, 두 번째 매개변수에는 y축 값을 2차원 배열로 전달해야 한다.
예를 들어 각 출판사의 연도별 대출건수를 그리려면 y축에 해당하는 2차원 배열은 행이 각 '출판사'에 해당하고 열은 '발행년도'로 구성한다.
[356 하단 그림삽입]
따라서 앞서 만든 ns_book9 데이터프레임에서 '발행년도' 열의 개별 값을 하나의 열로 구성한 후 상위 10개 출판사의 연도별 대출건수를 스택 영역 그래프로 그려보자. 단계별로 정리하면 다음과 같다.
① pivot_table() 메서드로 각 '발행년도'열의 값을 열로 바꾸기 → y축에 넣을 2차원 배열을 만든다.
② '발행년도' 열을 리스트 형태로 바꾸기 → x축에 넣을 리스트를 만듦.
③ stackplot() 메서드로 스택 영역 그래프 그리기
① pivot_table() 메서드로 각 '발행년도'열의 값을 열로 바꾸기
하나의 열을 2차원 배열로 바꾸는 것처럼 데이터 구조를 바꾸는 방법은 판다스의 pibot_table() 메서드로 처리할 수 있다. 이 함수는 엑셀의 피벗 테이블(pivot table)과 유사한 기능을 수행한다.
[357 그림 삽입]
pivot_table() 메서드를 사용하는 방법은 간단하다! index 매개변수와 columns 매개변수에 원본 데이터프레임의 열을 지정하면 각 열의 고유한 값이 피벗 테이블로 변환된 데이터프레임의 인덱스와 열이 된다.
# 여기서는 index 매개변수에 '출판사' 열, columns 매개변수에 '발행년도' 열을 지정해보자.
ns_book10 = ns_book9.pivot_table(index='출판사', columns='발행년도')
ns_book10.head()
>>> 대출건수
발행년도 1947 1974 1975 1976 1977 1978 1979 1980 1981 1982 ... 2013 2014 2015 2016 2017 2018 2019 2020 2021 2030
출판사
博英社 0.0 NaN 0.0 NaN 0.0 NaN NaN NaN NaN NaN ... NaN 118.0 57.0 47.0 2.0 8.0 NaN 1.0 NaN NaN
길벗 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN ... 1162.0 1619.0 1410.0 1597.0 1626.0 1004.0 773.0 292.0 12.0 NaN
김영사 NaN NaN NaN NaN NaN NaN NaN 0.0 0.0 0.0 ... 1905.0 1881.0 2726.0 2647.0 1094.0 1602.0 533.0 332.0 30.0 NaN
넥서스 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN ... 1828.0 1429.0 765.0 1146.0 932.0 565.0 90.0 15.0 0.0 NaN
다산북스 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN ... 1100.0 1361.0 1321.0 1137.0 1249.0 773.0 530.0 127.0 13.0 NaN
5 rows × 50 columns기대한 대로 '발행년도' 열의 값이 하나의 열이 되었다! 한 가지 눈 여겨 보아야 할 것은 열이 다단으로 구성되어 있다는 점이다.
# 첫 번째 뎔을 보면 1947이 아니라 ('대출건수', 1947)이다
ns_book10.columns[:10]
>>> MultiIndex([('대출건수', 1947),
('대출건수', 1974),
('대출건수', 1975),
('대출건수', 1976),
('대출건수', 1977),
('대출건수', 1978),
('대출건수', 1979),
('대출건수', 1980),
('대출건수', 1981),
('대출건수', 1982)],
names=[None, '발행년도'])② '발행년도' 열을 리스트 형태로 바꾸기
이번에는 상위 10개의 출판사 이름과 x축에 놓을 '발행년도' 리스트를 준비해보자! 판다스 인덱스 객체에서 호출할 수 있는 get_level_values() 메서드는 다단으로 구성된 열 이름에서 선택한 항목만 가져올 수 있다. 따라서 ('대출건수', 1947)로 되어있는 열 이름 중 연도로 구성된 두 번째 항목만 가져올 수 있다.
top10_pubs = top30_pubs.index[:10]
year_cols = ns_book10.columns.get_level_values(1)③ stackplot() 메서드로 스택 영역 그래프 그리기
x축과 y축에 전달할 값이 준비되었다. 이제 stackplot() 메서드에 x축 값에는 year_cols를, y축에는 ns_book10에서 상위 10개 출판사에 해당하는 행을 골라 전달한다. 범례는 이전과 동일하게 출판사 이름으로 지정한다. legend() 메서드는 loc 매개변수로 범례의 위치를 지정할 수 있다.
여기서는 'upper left'로 지정하여 출력해보자.
fig, ax = plt.subplots(figsize=(8, 6))
ax.stackplot(year_cols, ns_book10.loc[top10_pubs].fillna(0), labels=top10_pubs)
ax.set_title('년도별 대출건수')
ax.legend(loc='upper left')
ax.set_xlim(1985, 2025)
fig.show()
>>>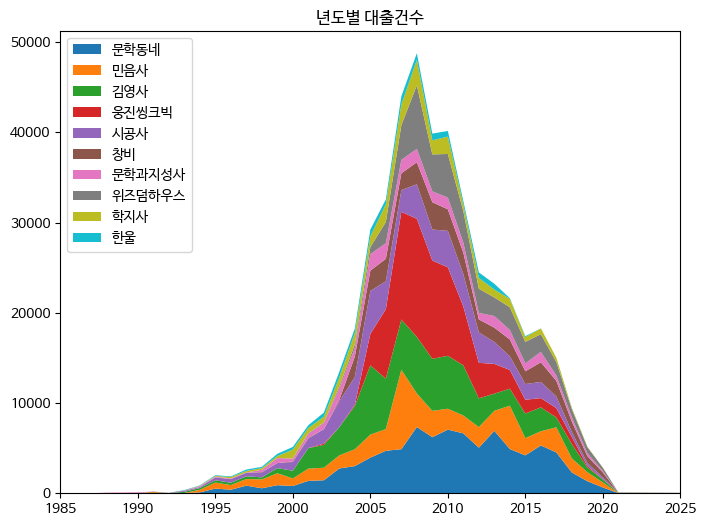
스택 영역 그래프가 성공적으로 출력되었다! 2010년 경의 그래프 면적을 보면 '문학동네'와 '웅진씽크빅'의 대출건수가 높다는 것을 쉽게 알 수 있다. 그래프 사이의 영역은 자동으로 색칠된다. 이 색은 앞서 여러 개의 선 그래프를 그렸을 떄와 마찬가지로 10개의 색이 반복된다.
+ 데이터프레임을 가져올 때 왜 fillna() 메서드를 사용하나요?
맷플롯립은 판다스 데이터프레임의 누락된 값을 제대로 처리하지 못해 그래프가 이상하게 그려지는 경우가 있다. 이런 현상을 막기 위해 그래프를 그리기 전에 fillna() 메서드로 누락된 값을 0으로 채웠다. 또는 pivot_table() 메서드를 호출할 때 fill_value=0으로 지정하면 피벗 테이블을 만들 떄 미리 누락된 값을 0으로 채울 수 있다.
하나의 피겨에 여러 개의 막대 그래프 그리기
막대 그래프를 여러 개 그리는 방법도 선 그래프와 비슷하게 bar() 메서드를 여러 번 호출하면 된다.
fig, ax = plt.subplots(figsize=(8, 6))
ax.bar(line1['발행년도'], line1['대출건수'], label='황금가지')
ax.bar(line2['발행년도'], line2['대출건수'], label='비룡소')
ax.set_title('년도별 대출건수')
ax.legend()
fig.show()
>>>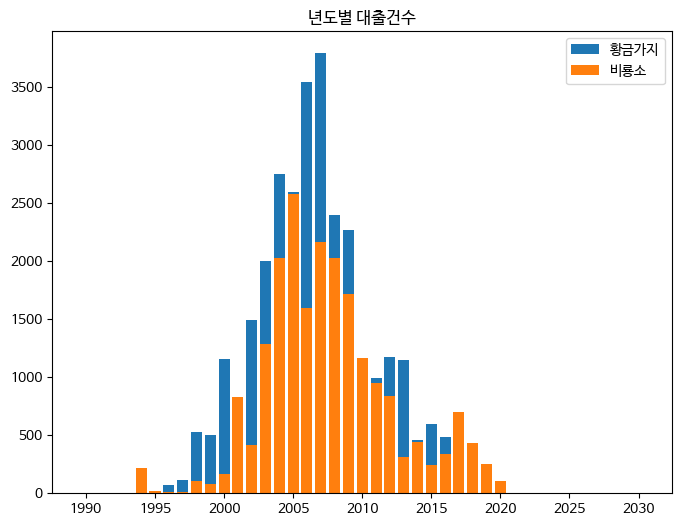
선 그래프와 달리 막대 그래프는 막대에 색이 채워진다! 그래서 그냥 bar() 메서드를 연이어 호출하면 먼저 그린 막대를 덮어쓰게 된다. 이런 방식으로는 두 출판사의 대출건수를 올바르게 나타낼 수 없다.
두 출판사의 막대를 나란히 옆으로 그리려면 어떻게 해야 할까?? 막대의 기본 너비인 0.8의 절반인 0.4 너비로 두 막대 그래프를 그린 다음, x축에서 막대 하나 너비인 0.4의 절반씩 떨어지도록 그려야 한다.
[361 그림 삽입]
fig, ax = plt.subplots(figsize=(8, 6))
ax.bar(line1['발행년도']-0.2, line1['대출건수'], width=0.4, label='황금가지')
ax.bar(line2['발행년도']+0.2, line2['대출건수'], width=0.4, label='비룡소')
# '+0.2#' : 막대 위치 이동
# 'width=0.4' : 막대 너비 지정
ax.set_title('년도별 대출건수')
ax.legend()
fig.show()
>>>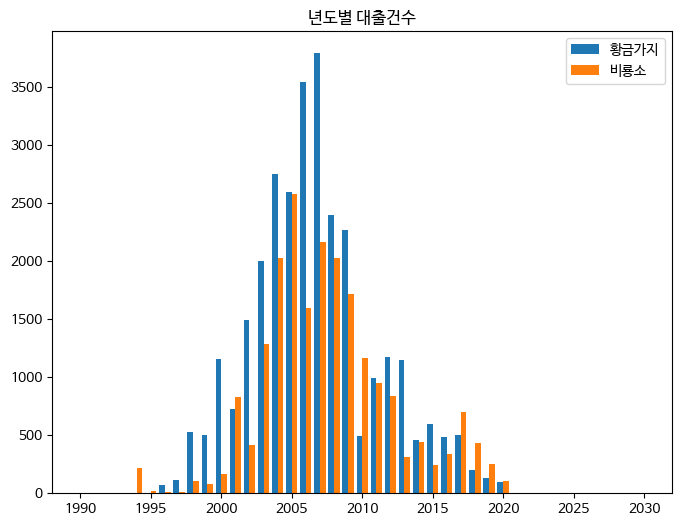
'황금가지' 출판사와 '비룡소' 출판사의 막대가 나란히 놓여 비교하기 좋다. 하지만 많은 출판사의 데이터를 그리기는 어려울 것 같다. 많은 막대르 나란히 놓으려면 막대 두께를 아주 얇게 하거나 그래프의 폭을 많이 넓혀야 하기 때문이다.
스택 막대 그래프
막대 그래프를 옆으로 나란히 놓지 않고 스택 영역 그래프처럼 위로 쌓을 수도 있다! 이런 그래프를 스택 막대 그래프(stacked bar grapth)라고 한다. 위로 쌓아 그리면 여러 개의 막대를 표현하는데 부담이 줄어든다!
[362 그림삽입]
아쉽지만 맷플롯립에는 stackplot() 메서드처럼 막대 그래프를 쌓을 수 있는 함수가 없다. 대신 bar() 매서드의 bottom 매개변수를 사용하면 수동으로 막대를 쌓을 수 있다. 이 매개변수는 막대가 시작할 y 좌표를 결정한다.
간단한 두 개의 리스트 height1, height2를 만들어 height1 막대 그래프 위에 height2를 쌓자.
height1 = [5, 4, 7, 9, 8]
height2 = [3, 2, 4, 1, 2]
plt.bar(range(5), height1, width=0.5)
plt.bar(range(5), height2, bottom=height1, width=0.5)
plt.show()
>>>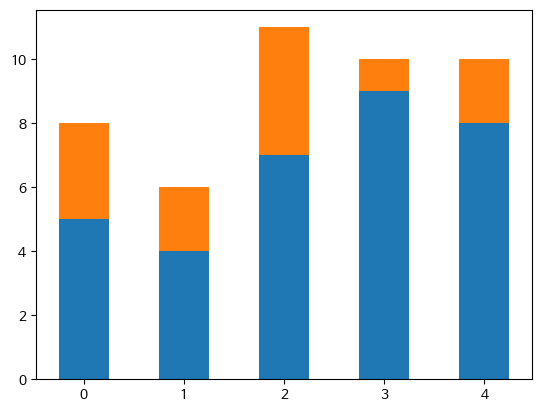
막대 그래프를 잘 쌓았지만 그래프를 그릴 때마다 막대의 시작 위치를 계속 누적하여 보관해야 하기 때문에 조금 번거롭다.
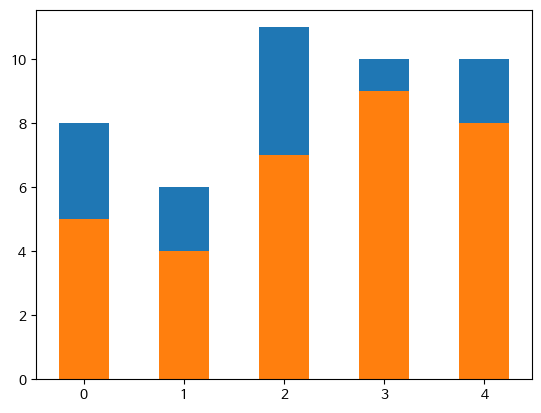
이번에는 그래프를 그리기 전에 아예 막대의 길이를 누적해 놓고 이 값으로 막대 그래프를 그리는 방법을 살펴보자. 다음처럼 height1과 height2를 더하여 height3를 만든 후, height3를 먼저 그리고 height1을 그린다.
height3 = [a + b for a, b in zip(height1, height2)]
plt.bar(range(5), height3, width=0.5)
plt.bar(range(5), height1, width=0.5)
plt.show()
>>>
데이터값 누적하여 그리기
ns_book10 데이터프레임을 스택 막대 그래프로 그려보자! 판다스 데이터프레임의 cumsum() 메서드를 사용하면 값을 누적하는 일은 아주 쉽다!
사용법 익히기 위해 먼저 ns_book10 데이터프레임에서 상위 다섯 개의 출판사의 2013-2020년 대출건수를 확인해보자.
# loc 메서드 사용
ns_book10.loc[top10_pubs[:5], ('대출건수',2013):('대출건수',2020)]
>>> 대출건수
발행년도 2013 2014 2015 2016 2017 2018 2019 2020
문학동네 6919.0 4904.0 4201.0 5301.0 4529.0 2306.0 1340.0 645.0
민음사 2219.0 4805.0 1907.0 1571.0 2782.0 1559.0 998.0 552.0
김영사 1905.0 1881.0 2726.0 2647.0 1094.0 1602.0 533.0 332.0
웅진씽크빅 3293.0 2072.0 1529.0 1029.0 1032.0 762.0 159.0 26.0
시공사 2433.0 1512.0 1745.0 1787.0 1287.0 566.0 322.0 221.0
# 동일한 데이터프레임에서 cumsum() 메서드 이어서 호출
ns_book10.loc[top10_pubs[:5], ('대출건수',2013):('대출건수',2020)].cumsum()
대출건수
발행년도 2013 2014 2015 2016 2017 2018 2019 2020
문학동네 6919.0 4904.0 4201.0 5301.0 4529.0 2306.0 1340.0 645.0
민음사 9138.0 9709.0 6108.0 6872.0 7311.0 3865.0 2338.0 1197.0
김영사 11043.0 11590.0 8834.0 9519.0 8405.0 5467.0 2871.0 1529.0
웅진씽크빅 14336.0 13662.0 10363.0 10548.0 9437.0 6229.0 3030.0 1555.0
시공사 16769.0 15174.0 12108.0 12335.0 10724.0 6795.0 3352.0 1776.0발행 연도별 대출건수가 차례대로 누적된 것을 알 수 있다. 예를 들어 원래 '민음사'의 2013년 대출건수는 2219지만, '문학동네'의 2013년 대출건수와 합쳐져서 9138이 되었다. '김영사'를 확인하며 마찬가지로 9138에 1905가 누적되어 11043인 것을 알 수 있다.
따라서 ns_book10 데이터프레임 전체에 cumsum() 메서드를 적용하려면 다음과 같이 적을 수 있다.
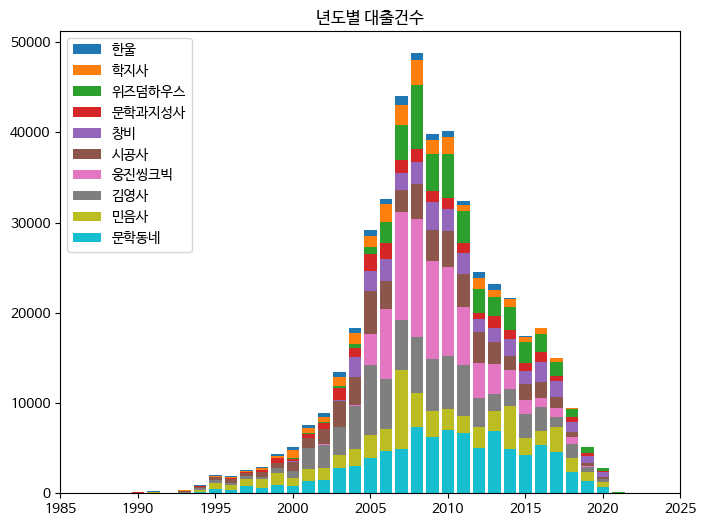
ns_book12 = ns_book10.loc[top10_pubs].cumsum()이제 누적 대출건수를 준비했으니 막대 그래프를 쌓는 작업은 간단하다! 여기서 주의할 점은 가장 큰 막대를 먼저 그려야 한다는 점이다. 그렇지 않으면 가장 큰 막대가 이전에 그린 막대를 모두 덮어쓰게 된다.
파이썬의 range() 함수로 ns_book12 데이터프레임 행 개수만큼 인덱스 번호를 만들고, for 문에 reversed() 함수를 사용해 인덱스의 역순으로 ㅂ나복하여 그리면 성공이다!
fig, ax = plt.subplots(figsize=(8, 6))
for i in reversed(range(len(ns_book12))):
bar = ns_book12.iloc[i] # 행 추출
label = ns_book12.index[i] # 출판사 이름 추출
ax.bar(year_cols, bar, label=label)
ax.set_title('년도별 대출건수')
ax.legend(loc='upper left')
ax.set_xlim(1985, 2025)
fig.show()
>>>
원 그래프 그리기
원 그래프는 전체 데이터에 대한 비율을 원의 부채꼴로 나타낸 그래프이다. 파이 차트(pie chart)라고도 부른다. value_counts() 메서드로 상위 30개 출판사의 발행 도서 개수를 구한 top30_pubs의 값과 인덱스에서 처음 10개만 선택하여 각각 data와 labels 변수에 저장한다.
data = top30_pubs[:10]
# 상위 10개 출판사의 도서 개수를 선택하여 저장한다.
labels = top30_pubs.index[:10]
# 상위 10개 출판사의 인덱스를 저장한다.원 그래프는 맷플롯립의 pie() 메서드로 그릴 수 있다. 이 메서드의 첫 번째 매개변수에 앞서 정의한 data를 전달하면 자동으로 데이터 전체에 대한 비율을 계산하여 그래프를 그린다. 부채꼴 모양 위에 표시할 출판사 이름은 labels 매개변수에 전달한다.
fig, ax = plt.subplots(figsize=(8, 6))
ax.pie(data, labels=labels)
ax.set_title('출판사 도서비율')
fig.show()
>>>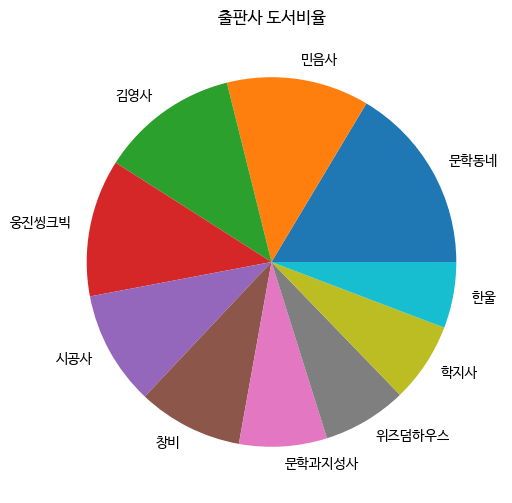
3시 방향부터 반시계 방향으로 그려진다.
각 출판사의 발행 도서 비율이 자동으로 계산되어 원 그래프가 구성되었다. 맷플롯립의 원 그래프는 기본적으로 3시 방향부터 반시계 방향으로 데이터를 그린다. data 배열에 맨 처음 '문학동네'가 나오고 그 다음 '민음사' 데이터이다.
다행히 data 배열의 값은 크기 순서대로 정렬되어 있다. '창비' 출판사가 '문학과지서사' 출판사보다 먼저 등장하는 것을 보고, '창비' 출판사의 값이 더 크다는 것을 알 수 있다. 하지만 크기 순으로 정렬되어 있지 않은 데이터를 사용했다면 '창비'와 '문학과지성사' 중 어떤 부채꼴이 더 큰지 확실히 말 할 수 있을까?!!
원 그래프의 단점
선 그래프나 막대 그래프와 달리 원 그래프는 시각적으로 어떤 데이터가 더 큰지 한눈에 구분하기 어렵다. 특히 3차원으로 그린 원 그래프는 더욱 그렇다. 이런 이유로 원 그래프를 사용할 때는 잘못된 정보를 제공하지 않도록 조심해야 한다!
다음 그래프를 살펴보자! 이 그래프는 startangle 매개변수를 90으로 지정하여 12시 방향부터 원 그래프를 그렸다. 두 개의 데이터만 있는 경우라면 원 그래프는 데이터의 차이를 명확하게 나타낼 수 있다. 하지만 이 역시 더 명확하게 데이터의 비율을 표시하는 것이 어느 쪽 데이터가 얼마나 크고 작은지 비교하기 좋다.
plt.pie([10,9], labels=['A제품', 'B제품'], startangle=90)
plt.title('제품의 매출비율')
plt.show()
>>>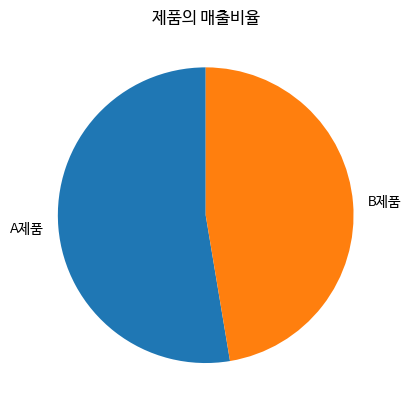
pie() 메서드의 startangle 매개변수는 원 그래프의 시작 위치를 지정할 수 있다.
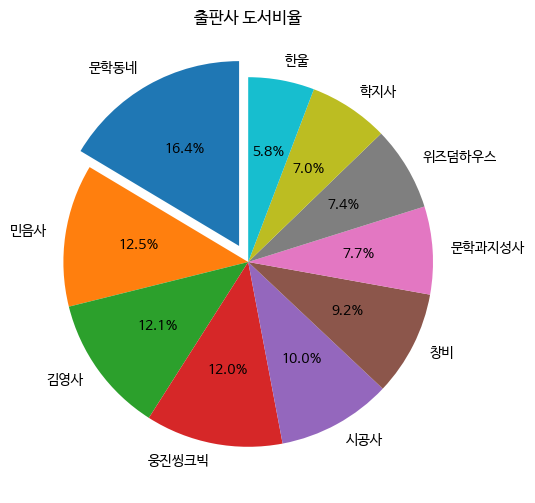
비율 표시하고 부채꼴 강조하기
pie() 메서드의 autopct 매개변수에는 파이썬의 % 연산자에 적용할 포맷팅 문자열을 전달할 수 있다. 예를 들어 %d를 전달하면 각 부채꼴의 비율이 정수로 표시된다. 여기에서는 소숫점 첫째 자리까지 포함한 실수로 표시해보자. 마지막에 퍼센트 기호를 추가하기 위해 % 기호를 한 번 더 쓰자.
중요한 항목의 경우 해당 부채꼴 조각을 원 그래프에서 조금 떨어뜨려 시각적으로 부각시킬 수 있다. 이렇게 하려면 explode 매개변수에 떨어뜨리길 원하는 조각의 간격을 반지름의 비율로 지정한다. 예를 들어 첫 번쨰 출판사인 '문학동네'만 뗴어내려면 첫 번째 항목이 0.1이고 나머지는 모두 0인 파이썬 리스트를 만들어 전달한다. explode 매개변수에 전달하는 리스트 길이는 data 배열의 길이와 같아야 한다.
fig, ax = plt.subplots(figsize=(8, 6))
ax.pie(data, labels=labels, startangle=90,
autopct='%.1f%%', explode=[0.1]+[0]*9)
ax.set_title('출판사 도서비율')
fig.show()
>>>
여러 종류의 그래프가 있는 서브플롯 그리기
마지막으로 지금까지 그려 보았던 산점도, 스택 영역 그래프, 스택 막대 그래프, 원 그래프를 하나의 피겨에 모두 그려보자.
05-1절에서 subplots() 함수로 2개의 서브플롯을 만들어 보았다. 비슷하게 4개의 서브플롯을 가로로 나란히 놓으면 화면 폭 때문에 그래프가 아주 작게 그려질 것이다. 2차원 배열 형태로 4개의 서브플롯을 그리는 것이 좋겠다.
subplots() 함수의 첫 번째 매개변수와 두 번째 매개변수에는 서브플롯의 행 개수와 열 개수를 지정할 수 있다고 했다. 예를 들어 subplots(2,2)와 같이 쓰면 행이 2개이고 열이 2개인 4개의 서브플롯이 만들어진다. subplots() 함수에서 반환 받은 Axes 객체를 사용할 때는 2차원 배열처럼 각 격자의 위치를 지정해야 한다.
[370 그림삽입]
2x2 형태의 서브플롯을 만들어 앞에서 그린 4개의 그래프를 하나씩 모두 그려보자. 추가로 서브플롯 안에 있는 산점도에 컬러 막대도 넣으려면 colorbar() 메서드의 ax 매개변수에 해당 서브플롯 객체를 지정해 주어야 한다. 그 외에는 앞에서 작성한 코드와 동일하다.
fig, axes = plt.subplots(2, 2, figsize=(20, 16))
# 산점도
ns_book8 = ns_book7[top30_pubs_idx].sample(1000, random_state=42)
sc = axes[0, 0].scatter(ns_book8['발행년도'], ns_book8['출판사'],
linewidths=0.5, edgecolors='k', alpha=0.3,
s=ns_book8['대출건수'], c=ns_book8['대출건수'], cmap='jet')
axes[0, 0].set_title('출판사별 발행도서')
fig.colorbar(sc, ax=axes[0, 0])
# 스택 선 그래프
axes[0, 1].stackplot(year_cols, ns_book10.loc[top10_pubs].fillna(0),
labels=top10_pubs)
axes[0, 1].set_title('년도별 대출건수')
axes[0, 1].legend(loc='upper left')
axes[0, 1].set_xlim(1985, 2025)
# 스택 막대 그래프
for i in reversed(range(len(ns_book12))):
bar = ns_book12.iloc[i] # 행 추출
label = ns_book12.index[i] # 출판사 이름 추출
axes[1, 0].bar(year_cols, bar, label=label)
axes[1, 0].set_title('년도별 대출건수')
axes[1, 0].legend(loc='upper left')
axes[1, 0].set_xlim(1985, 2025)
# 원 그래프
axes[1, 1].pie(data, labels=labels, startangle=90,
autopct='%.1f%%', explode=[0.1]+[0]*9)
axes[1, 1].set_title('출판사 도서비율')
fig.savefig('all_in_one.png')
fig.show()
>>>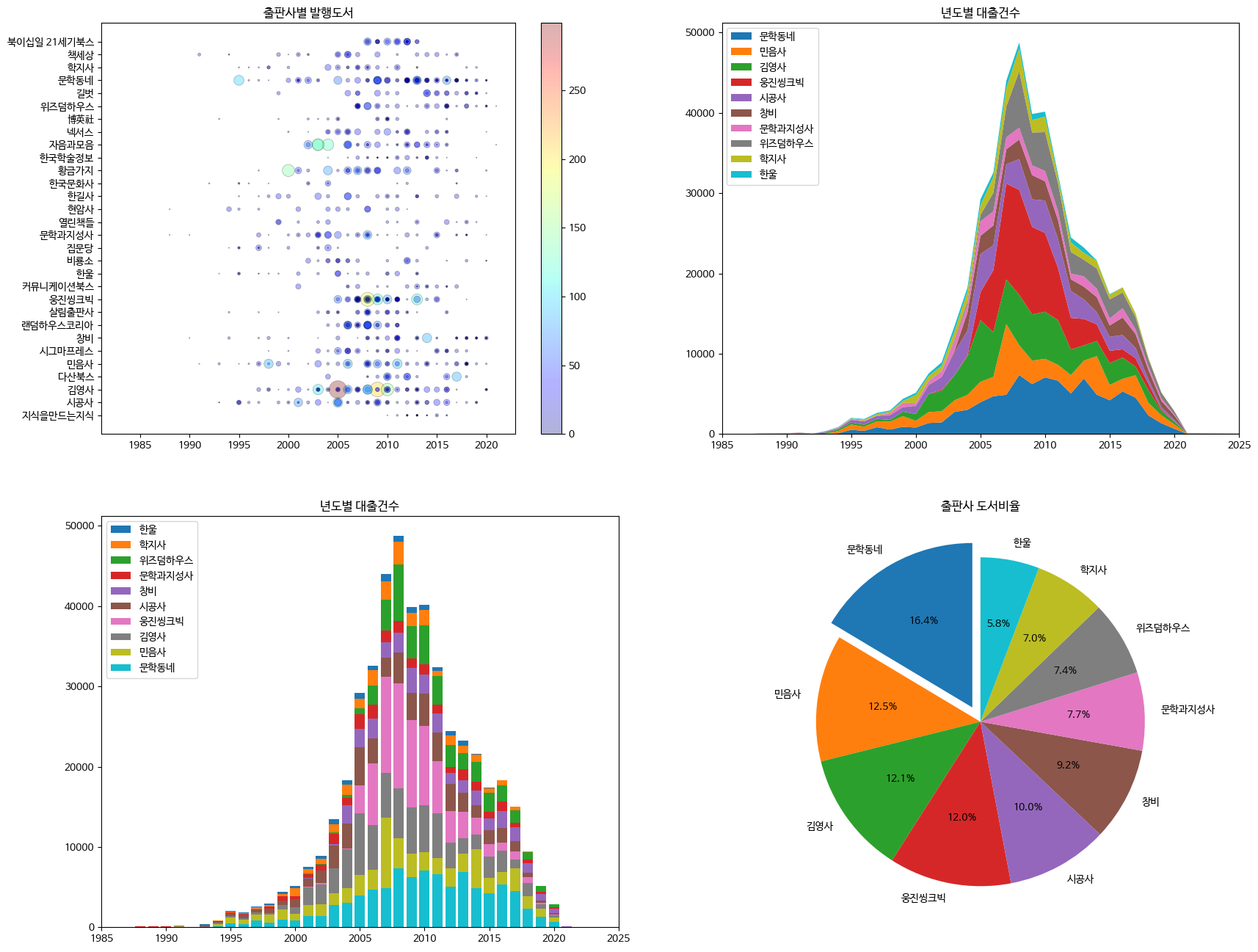
2x2 형태의 서브플롯에 산점도, 스택 영역 그래프, 스택 막대 그래프, 원 그래프가 순서대로 잘 그려졌다. 그리고 코드 마지막에 이 그래프를 all_in_one.png 이미지 파일로 저장했다.
맷플롯립으로 복잡한 그래프 그리기
이번 절에서는 선 그래프를 한 피겨에 중복하여 그리는 방법을 알아보았다. 여러 출판사의 선 그래프를 보다 이해하기 쉽도록 맷플롯립의 stackplot() 메서드를 사용하여 스택 영역 그래프를 그렸다. 그래프를 순서대로 쌓기 위해 판다스 데이터프레임의 pivot_table() 메서드를 사용해 데이터를 변환하는 방법을 배웠다.
같은 데이터로 스택 막대 그래프도 그렸다. 맷플롯립으로 그릴 때는 수동으로 각 막대의 시작 위치를 지정해야 한다. 데이터프레임의 cumsum() 메서드로 막대 길이를 미리 누적해 놓으면 조금 더 쉽게 스택 막대 그래프를 그릴 수 있다.
그리고 맷플롯립의 pie() 메서드로 원 그래프를 그리는 방법을 살펴보았다. 원 그래프의 단점을 보완하기 위해 부채꼴에 비율을 표시하는 방법과 특정 조각을 뗴어내어 부각시키는 방법을 배웠다. 마지막으로 2x2 서브플롯을 만들어 4개의 그래프를 하나의 피겨에 모두 그려 보았다.
좀더 알아보기 _ 판다스로 여러 개의 그래프 그리기
스택 영역 그래프 그리기
앞서 그린 스택 영역 그래프를 판다스 데이터프레임이 제공하는 plot.area() 메서드를 사용해 다시 그려 보자.
먼저 ns_book10을 만들었던 것과 비슷하게 ns_book9를 피벗 테이블로 변환하자. 이번에는 이전과 반대로 index 매개변수에는 '발행년도' 열, columns 매개변수에는 '출판사' 열을 지정한다. 실행 결과 중에 2000년에서 2005년 사이의 데이터를 확인해보자.
ns_book11 = ns_book9.pivot_table(index='발행년도', columns='출판사', values='대출건수')
ns_book11.loc[2000:2005]
>>> 출판사 博英社 길벗 김영사 넥서스 다산북스 랜덤하우스코리아 문학과지성사 문학동네 민음사 북이십일 21세기북스 ... 창비 책세상 커뮤니케이션북스 학지사 한국문화사 한국학술정보 한길사 한울 현암사 황금가지
발행년도
2000 237.0 7.0 854.0 194.0 NaN 3.0 316.0 806.0 836.0 NaN ... 57.0 369.0 37.0 988.0 84.0 36.0 536.0 287.0 274.0 1152.0
2001 267.0 202.0 2269.0 228.0 NaN 17.0 449.0 1373.0 1363.0 NaN ... 70.0 355.0 184.0 582.0 110.0 3.0 1626.0 305.0 481.0 722.0
2002 458.0 472.0 2525.0 1154.0 NaN 20.0 686.0 1442.0 1388.0 NaN ... 0.0 794.0 80.0 625.0 134.0 47.0 777.0 450.0 398.0 1493.0
2003 444.0 795.0 3130.0 3069.0 NaN 489.0 1262.0 2750.0 1453.0 NaN ... 191.0 289.0 110.0 1006.0 215.0 95.0 1114.0 636.0 471.0 2001.0
2004 630.0 976.0 4804.0 2355.0 212.0 618.0 952.0 3012.0 1864.0 42.0 ... 2268.0 637.0 476.0 1270.0 392.0 91.0 1318.0 502.0 661.0 2744.0
2005 788.0 2162.0 7684.0 1162.0 509.0 941.0 1827.0 3952.0 2546.0 NaN ... 2256.0 1103.0 820.0 1179.0 243.0 123.0 1461.0 767.0 835.0 2593.0이전과 달리 pivottable() 메서드의 values 매개변수에 집계할 열을 지정했다. 이렇게 하면 열 이름이 다단으로 구성되지 않기 때문에 get_level_values() 메서드를 사용할 필요가 없다!!
+ pivottable() 메서드에서 values 매개변수에 지정한 열을 집계한다는 것이 어떤 뜻인가요?
pivot_table() 메서드와 groupby() 메서드는 값을 집계한다는 점에서 매우 비슷하다. 하지만 만들어진 결과가 다르다. groupby() 메서드는 집계 기준이 되는 열이 모두 행 인덱스로 바뀌지만 pivot_table() 메서드는 집계 기준이 행과 열 인덱스로 나뉜다.
ns_book9 데이터프레임은 이미 groupby() 메서드로 집계를 한 결과이다. 출판사마다 '발행년도' 열에 하나의 값만 있으므로 ns_book10을 만들 때 values 매개변수를 사용하지 않아도 괜찮았다.
CSV 파일에서 읽은 ns_book7 데이터프레임에 pivot_table() 메서드를 적용해 바로 ns_book11을 만들 수도 있다. 이런 경우 ns_book7 데이터프레임에는 '출판사'와 '발행년도' 열을 기준으로 여러 데이터가 있기 때문에 pivot_table() 메서드의 aggfunc 매개변수에 집계 방식을 지정해 주어야 한다. 기본적인 집계 방식은 평균이다. 값을 모두 더하려면 넘파이 sum() 함수를 지정하면 된다.
import numpy as np
ns_book11 = ns_book7[top30_pubs_idx].pivot_table(
index='발행년도', columns='출판사',
values='대출건수', aggfunc=np.sum)
ns_book11.loc[2000:2005]
>>> 출판사 博英社 길벗 김영사 넥서스 다산북스 랜덤하우스코리아 문학과지성사 문학동네 민음사 북이십일 21세기북스 ... 창비 책세상 커뮤니케이션북스 학지사 한국문화사 한국학술정보 한길사 한울 현암사 황금가지
발행년도
2000 237.0 7.0 854.0 194.0 NaN 3.0 316.0 806.0 836.0 NaN ... 57.0 369.0 37.0 988.0 84.0 36.0 536.0 287.0 274.0 1152.0
2001 267.0 202.0 2269.0 228.0 NaN 17.0 449.0 1373.0 1363.0 NaN ... 70.0 355.0 184.0 582.0 110.0 3.0 1626.0 305.0 481.0 722.0
2002 458.0 472.0 2525.0 1154.0 NaN 20.0 686.0 1442.0 1388.0 NaN ... 0.0 794.0 80.0 625.0 134.0 47.0 777.0 450.0 398.0 1493.0
2003 444.0 795.0 3130.0 3069.0 NaN 489.0 1262.0 2750.0 1453.0 NaN ... 191.0 289.0 110.0 1006.0 215.0 95.0 1114.0 636.0 471.0 2001.0
2004 630.0 976.0 4804.0 2355.0 212.0 618.0 952.0 3012.0 1864.0 42.0 ... 2268.0 637.0 476.0 1270.0 392.0 91.0 1318.0 502.0 661.0 2744.0
2005 788.0 2162.0 7684.0 1162.0 509.0 941.0 1827.0 3952.0 2546.0 NaN ... 2256.0 1103.0 820.0 1179.0 243.0 123.0 1461.0 767.0 835.0 2593.0행 인덱스가 '발행년도'이고 열 인덱스는 '출판사' 이름으로 된 데이터프레임이 만들어졌다. 이제 이 데이터프레임에서 plot.area() 메서드를 호출하여 스택 영역 그래프를 그릴 수 있다.
서브플롯을 명시적으로 만든 경우 area() 메서드의 ax 매개변수에 맷플롯립의 Axes 객체를 전달해야한다. 또 title 매개변수로 그래프 제목을 지정하고, xlim 매개변수로 x축의 범위를 설정한다.
fig, ax = plt.subplots(figsize=(8, 6))
ns_book11[top10_pubs].plot.area(ax=ax, title='년도별 대출건수',
xlim=(1985, 2025))
ax.legend(loc='upper left')
fig.show()
>>>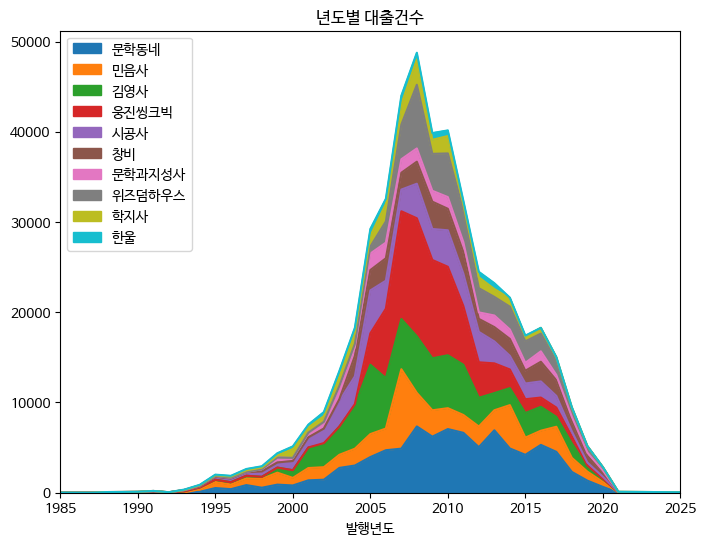
맷플롯립으로 그린 것과 동일한 그래프가 그려졌다!
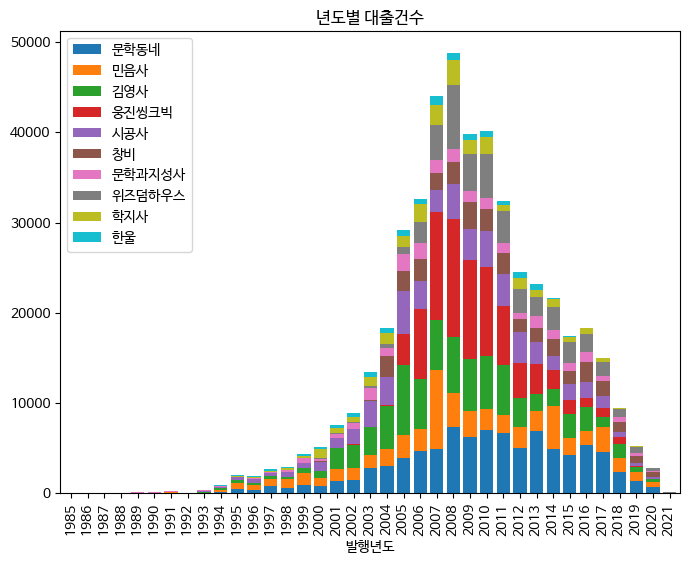
스택 막대 그래프 그리기
스택 막대 그래프는 판다스를 사용하렴 조금 더 쉽게 그릴 수 있다. 이번에는 앞서 선 그래프를 그릴 때 만들었던 nsbook11을 사용해 막대 그래프를 쌓아보자.
판다스 데이터프레임에서 제공하는 plot.bar() 메서드는 기본적으로 막대를 나란히 출력한다. 하지만 stacked 매개변수를 True로 지정하면 스택 막대 그래프를 그릴 수 있다. 게다가 맷플롯립으로 그릴 때처럼 미리 cumsum() 메서드를 호출할 필요도 없다.
판다스는 기본적으로 막대의 두께를 0.5로 설정한다. 맷플롯립과 비슷한 그래프를 그리기 위해 width를 0.8로 지정하면 다음과 같이 스택 막대 그래프가 그려진다.
+ 판다스의 막대 그래프는 이 글을 쓰는 시점에 x축 범위를 지정하는데 버그가 있어 ax.setxlim() 메서드가 작동하지 않는다. 따라서 ns_book11 데이터프레임에서 1985~2025 사이의 행만 추출하여 사용한다.
fig, ax = plt.subplots(figsize=(8, 6))
ns_book11.loc[1985:2025, top10_pubs].plot.bar(
ax=ax, title='년도별 대출건수', stacked=True, width=0.8)
ax.legend(loc='upper left')
fig.show()
>>>
정리
- 범례는 그래프에 그려진 데이터의 이름과 색상을 요약한 표이다.
- 피벗 테이블은 테이블 형태의 데이터를 평균, 합 등의 방식으로 집계하여 만든 요약표이다.
- 스택 영역 그래프는 여러 개의 선 그래프를 y축 방향으로 쌓은 그래프이다. 선 아래로 색상이 채워진 영역 형태로 표현된다. 마찬가지로 여러 개의 막대 그래프를 y축 방향으로 쌓으면 스택 막대 그래프가 된다. 막대 위에 막대가 누적되듯이 표현된다.
- 원 그래프는 데이터의 비율을 부채꼴 모양으로 나타낸 그래프이다. 다만, 그래프에 비율이 표시되어 있지 않으면 크기를 비교하기 어려우므로 autopct 매개변수를 사용하여 명확하게 비율을 표시해 주는 것이 좋다.
핵심 함수와 메서드
- Axes.legend() : 그래프에 범례를 추가한다.
- Axes.set_xlim : x축의 출력 범위를 지정한다.
- DataFrame.pivot_table() : 피벗 테이블 기능을 제공한다.
- Axes.stackplot() : 스태 영역 그래프를 그린다.
- DataFrame.plot.area() : 스택 영역 그래프를 그린다.
- DataFrame.plot.bar() : 막대 그래프를 그린다.
- DataFrame.cumsum() : 행이나 열 방향으로 누적 합을 계산한다.
- Axes.pie() : 원 그래프를 그린다.
