API란
데이터베이스에 민감한 개인 정보나 접근 권한이 엄격하게 관리되거나 네트워크 분리로 물리적 접근이 불가능하게 되는 경우가 있다. 이때 인증된 URL만 있다면 언제든지 필요한 데이터에 편리하게 접근할 수 있다. 이를 'API'라 부른다.
API : Application Programming Interface. 두 프로그램이 서로 대화하기 위한 방법을 정의한 것. 프로그램 A와 프로그램 B가 데이터를 주고받는 규칙이 다르다면 올바르게 데이터 처리하지 못함!
웹 페이지를 전송하기 위한 통신 규약 : HTTP
웹사이트는 웹 페이지를 서비스하기 위해 웹 서버(web server) 소프트웨어를 사용한다. 대표적인 웹 서버 프로그램으로는 엔진엑스(NGINX), 아파치(Apache) 등이 있다. 이런 웹 서버 프로그램은 웹 브라우저와 통신할 때 HTTP란 프로토콜(protocol)을 사용한다.
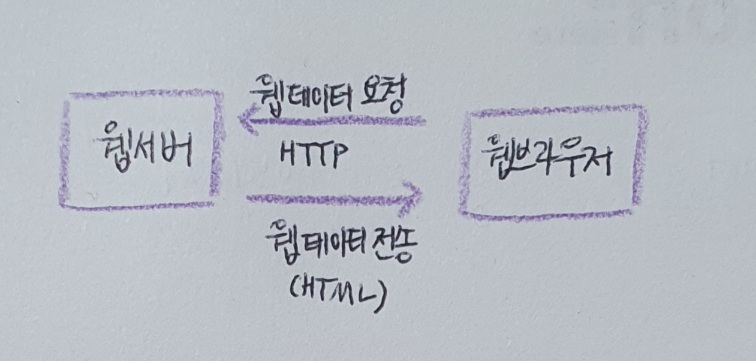
HTTP : Hyper Text Transfer Protocol. 인터넷에서 웹 페이지를 전송하는 기본 통신 방법. 그림처럼 웹 브라우저가 웹 서버에 웹 페이지를 요청하고 웹 서버는 요청에 맞는 웹 페이지를 웹 브라우저에게 전송한다. 웹 서버는 네이버 같은 웹사이트에서 운영하고, 웹 브라우저는 내 컴퓨터에 설치되어 있다.
웹 페이지 문서 : HTML
HTML : Hypertext Markup Language. 웹 브라우저가 화면에 표시할 수 있는 문서의 한 종류이자 웹 페이지를 위한 표준 언어.
HTML 같은 언어를 마크업(markup) 언어라 부르고 < div >와 같은 표시를 태그라고 부른다.
웹 기반 API는 웹 서버와 웹 브라우저가 대화하는 방식과 비슷하다. HTTP 프로토콜을 사용하지만 HTML을 주고받는 것이 아니라 일반적으로 CSV, JSON, XML 같은 파일을 사용한다.

웹 기반 API에서 HTML 대신 CSV나 JSON, XML을 선호하는 이유는 HTML 소스에서 볼 수 있듯이 구조가 비교적 복잡하기 때문이다. 주고받는 데이터가 복잡한 구조를 가지면 프로그램에 버그가 생길 가능성이 높다. 또 프로그래머가 오류를 찾기 위해 데이터를 확인할 때도 HTML은 너무 장황해 쉽게 이해하기 어렵다.
API는 프로그램 사이의 대화 방식을 결정한다. 다양한 API 중 HTTP 프로토콜을 사용한는 웹 기반 API가 널리 사용된다. 마치 웹 브라우저가 웹 서버의 웹 페이지를 요청하여 보여주는 방식과 비슷하다. HTTP나 웹 서버에 대해 자세히 알지 못해도 괜찮다.
웹 기반 API는 주로 CSV, JSON, XML 형태로 데이터를 전달한다. JSON과 XML은 CSV와 마찬가지로 텍스트 파일이다. 컴퓨터에 설치된 텍스트 편집 프로그램으로 쉽게 열어서 내용을 확인할 수 있다. 보통 웹 기반 API에는 CSV보다 JSON이나 XML을 많이 사용한다. CSV는 각 행마다 항목의 개수가 정확하게 맞지 않으면 읽을 수가 없다. 또 행과 열로만 구성되기 떄문에 복잡한 데이터 구조를 표현하기 어렵다. 이에 비해 JSON이나 XML은 다양한 구조를 생성할 수 있다.
파이썬에서 JSON 데이터 다루기
JSON은 JavaScrip Object Notation의 약자이다. 원래는 자바스크립트 언어를 위해 만들어졌지만 현재는 범용적인 포맷으로 사용한다. 대부분의 프로글밍 언어는 JSON 형태의 텍스트를 읽고 쓸 수 있다.
JSON은 파이썬의 딕셔너리와 리스트를 중첩해 놓은 것과 비슷하다. 만약 <혼자 공부하는 데이터 분석>이라는 도서명을 JSON 객체로 나타낸다면 중괄호를 사용하고 파이썬의 딕셔너리와 비슷하게 키(key)와 값(value)을 콜론(:)으로 연결한다.

여기에서 도서명에 해당하는 키는 "name"으로 정했다. 키와 값에 문자열을 쓰려면 항상 큰따옴표("")로 감싸주어야 한다.
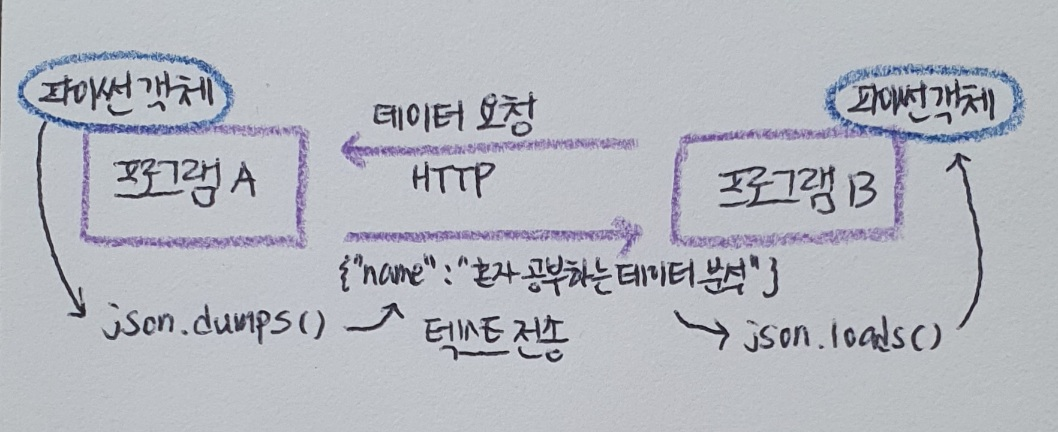
위와 같은 JSON 형식으로 파이썬 딕셔너리를 만들어 봤을 때, 잘 호환된다. 다만, 웹 기반 API로 데이터를 전달할 때는 파이썬 딕셔너리가 아니라 텍스트로 전달해야 한다.

파이썬 객체를 JSON 문자열로 변환하기 : json.dumps() 함수
파이썬의 json 패키지를 사용해 딕셔너리 d를 JSON 형식에 맞는 문자열로 바꾸어 보자.
import json # json 패키지 임포트json 패키지에서 파이썬 객체를 JSON 형식에 맞는 텍스트로 바꿀 때는 json.cumps() 함수를 사용한다.
d_str = json.dumps(ensure_ascii = False)
print(d_str)
>>> {"name": "혼자 공부하는 데이터 분석"}JSON 형식으로 변환이 잘 되었다!
json.dumps() 함수를 사용할 때 ensure_ascill 매개변수를 False로 지정한 이유는 딕셔너리 d에 한글이 포함되어 있기 때문이다. 기본적으로 json.dumps() 함수는 아스키(ASCII) 문자 외의 다른 문자를 16진수로 출력하기 때문에 한글이 제대로 보이지 않는다. 그래서 ensure_ascii 매개변수를 False로 지정하여 원래 저장된 문자를 그대로 출력하게 한다.
print(type(d_str)) # d_str이 문자열 객체인지 확인.
# type() 함수는 데이터 타입 확인할 수 있다.
>>> <class 'str'>딕셔너리가 문자열로 제대로 바뀌었다!
웹 기반 API는 전송하려는 파이썬 객체를 json.dumps() 함수를 사용하여 JSON 문자열로 변환하여 전송한다. 그런데 이런 JSON 문자열을 파이썬 프로그램에 사용하려면 다시 파이썬 딕셔너리로 바꾸어야 한다.
JSON 문자열을 파이썬 객체로 변환하기: json.loads() 함수
json.loads() 함수를 사용하면 JSON 문자열을 파이썬 객체로 변환할 수 있다.
+ 왜 바로 파이썬 객체를 전송하지 않고 문자열로 바꾸어 전송하는지???
웹 기반 API가 사용하는 HTTP 프로토콜이 텍스트 기반이기 때문이다. 웹 브라우저에서 HTML 소스를 보았을 때 텍스트로 출력되었던 것을 기억할 것이다. 그래서 HTTP 프로토콜로 데이터를 전송하려면 먼저 객체를 텍스트로 변환해야 한다. 이렇게 프로그램 상의 객체를 저장하거나 읽을 수 있는 형태로 변환하는 것을 직렬화(serialization)라고 한다. 반대로 직렬화된 정보를 다시 프로그램에서 실행 가능한 객체로 변환한느 것을 역직렬화(deserialization)라고 한다.
그럼 json.loads() 함수로 d_str 문자열을 파이썬 딕셔너리로 바꾸어 보자. 딕셔너리로 잘 변환되었는지 확인하기 위해 d2에서 'name' 항목도 출력해본다.
d2 = json.loads(d_str)
print(d2['name'])
>>> 혼자 공부하는 데이터 분석
# 타입도 확인
print(type(d2))
>>> <class 'dict'>기대했던 대로 문자열이 json.loads() 함수를 통해서 파이썬 딕셔너리로 바뀌었다. 웹 기반 API에서 전달되는 데이터가 JSON 문자열이라면 혼공분석은 json.loads() 함수를 사용해 파이썬 객체로 변환한 다음 분석 프로그램에 사용하면 된다!
지금까지는 파이썬 딕셔너리를 먼저 만들고 json.dumps() 함수로 문자열을 반환한 다음 json.loads() 함수를 사용했다. 매번 이렇게 하면 번거로우니 JSON 문자열을 json.loads() 함수에 직접 전달해보자.
값을 정수로 취급하려면 큰따옴표로 감쌀 필요가 없다!
d3 = json.loads('{"name": "혼자 공부하는 데이터 분석", "author": 박해선, "year": 2022}')
print(d3['name'])
print(d3['author'])
print(d3['year'])
>>> 혼자 공부하는 데이터 분석
박해선
2022여러 개 항목 가진 JSON 문자열을 json.loads() 함수에 전달하여 성공적으로 딕셔너리로 변경했다!!
이번에는 조금 더 복잡하게! "author" 키에 여러 항목 들어가려면 어떻게 하면 될까?? JSON은 대괄호 안에 여러 항목을 나열하여 배열을 표현할 수 있다. 파이썬의 리스트와 비슷하다!
d3 = json.loads('{"name": "혼자 공부하는 데이터 분석", "author": ["박해선", "홍길동"], "year": 2022}')
print(d3['author'][1])
>>> 홍길동파이썬 딕셔너리로 변환한 후 "author" 키의 값인 리스트에서 두 번째 항목 출력해 보았다. 예상대로 '홍길동'이 출력됨!
마지막으로 여러 개의 도서를 포함시킬 수 있는 더 복잡한 구조를 만들어보자. 앞에서 저자를 대괄호 안에 나열한 것처럼 JSON 객체를 대괄호 안에 나열하면 <혼자 공부하는 데이터 분석> 도서와 <혼자 공부하는 머신러닝+딥러닝> 도서를 하나의 JSON 배열로 나타낼 수 있다.
JSON 배열→[
JSON 객체→{
"name":"혼자 공부하는 데이터 분석",
"author": "박해선",
"year": 2022
}
,
JSON 객체→{
"name": "혼자 공부하는 머신러닝+딥러닝",
"author": "박해선",
"year": 2020
}
]
도서 두 권을 JSON 객체로 표현하고 이를 대괄호 안에 콤마(,)로 나열했다. 이 문자열을 json.loads() 함수를 사용해 파이썬 객체로 변환시켜 보자. 문자열이 길기 때문에 파이썬 세겹따옴표(""")를 사용해 여러 줄에 걸친 문자열을 만들자.
d3_str = """ → 세겹따옴표를 사용하면 긴 문자열을 줄바꿈하여 입력할 수 있다.
[
{"name": "혼자 공부하는 데이터 분석", "author": "박해선", "year": 2022},
{"name": "혼자 공부하는 머신러닝+딥러닝", "author": "박해선", "year": 2020}
]
"""
d4 = json.loads(d4_str)
print(d4[0]['name'])
>>> 혼자 공부하는 데이터 분석JSON 배열은 파이썬 리스트로 변환된다. d4[0]은 파이썬 리스트의 첫 번째 딕셔너리가 된다. 따라서 d4[0]['name']은 첫 번째 딕셔너리의 "name" 키에 해당하는 값을 잘 반환한다.
JSON 문자열을 데이터프레임으로 변환하기: read_json() 함수
이번에는 JSON 문자열을 데이터프레임으로 바꿔보자. 편리하게도 판다스는 JSON 문자열을 읽어서 데이터프레임으로 변환하는 read_json() 함수를 제공한다. 앞에서 만든 d4_str 문자열을 판다스 데이터프레임으로 변환해보자.
import pandas as pd → 판다스를 임포트한다.
pd.read_json(d4_str)
>>> name author year
0 혼자 공부하는 데이터 분석 박해선 2022
1 혼자 공부하는 머신러닝+딥러닝 박해선 2020JSON 객체 두 개가 데이터프레임의 각 행에 잘 매핑(mapping) 되었다.
JSON을 데이터프레임으로 바꾸는 또 다른 방법은 JSON 문자열을 파이썬 객체로 만든 다음 DataFrame 클래스를 사용하는 것이다. 앞에서 d4_str을 파이썬 객체로 변환한 d4를 사용해 데이터프레임을 만들어보자.
pd.DataFrame(d4)
>>> name author year
0 혼자 공부하는 데이터 분석 박해선 2022
1 혼자 공부하는 머신러닝+딥러닝 박해선 2020역시 잘 만들어졌다!
지금까지 JSON 데이터를 파이썬 객체와 판다스 데이터프레임으로 변환하는 방법을 배웠다. JSON은 비교적 읽기 쉽고 간결하기 때문에 최근 웹 기반 API에서 많이 사용한다. 웹 기반 API를 사용해 데이터를 수집하는 경우 JSON을 만날 가능성이 아주 높기 때문에 이 내용을 잘 이해하는 것이 좋다.
파이썬에서 XML 데이터 다루기
XML은 eXtensible Markup Language의 약자이다. HTML은 웹 페이지를 표현하는 데는 뛰어나지만, 구조적이지 못하기 때문에 프로그램 간의 약속대로 전송하는 API에서는 적절하지 않다. 대신 XML은 컴퓨터와 사람이 모두 읽고 쓰기 편한 문서 포맷을 위해 고안되었다.

XML은 엘리먼트(element)들이 계층 구조를 이루면서 정보를 표현한다. 엘리먼트는 시작 태그와 종료 태그로 감싼다. 기호는 <기호로 시작해서 >기호로 끝나며 태그 이름은 영문자와 숫자를 사용하고, 시작 태그와 종료 태그의 이름은 같아야 한다.
예를 들면 < name>이 시작 태그이고 < /name>은 종료 태그이다. 하나의 엘리먼트는 '< name>혼자 공부하는 데이터 분석< /name>'와 같이 시작 태그와 종료 태그로 구성된다. 따라서 < book>엘리먼트가 세 개의 하위 엘리먼트를 가지고 있음을 알 수 있다. 이때 < book> 엘리먼트를 부모 엘리먼트(parent element) 혹은 부모 노드(parent node)라고 부른다. < name>, < author>, < year> 엘리먼트는 < book> 엘리먼트의 자식 엘리먼트(child element)이다.
+ < book> 엘리먼트는 맨 먼저 등장하기 때문에 루트 엘리먼트(root element)라고도 부른다.
+ 태그 이름을 정하는 규칙이 있나요?
태그 이름은 안에 담긴 정보가 잘 드러나도록 정하는 것이 좋다. 이는 마치 데이터프레임의 열 이름이나 파이썬의 변수 이름을 정하는 것과 비슷하다. 또 동일한 자식 엘리먼트를 여러 개 포함하는 부모 엘리먼트는 복수형으로 사용하는 것이 이해하기 쉽다.
XML 문자열을 파이썬 객체로 변환하기: fromstring() 함수
XML을 파이썬의 세겹따옴표로 문자열로 만든 다음, 파이썬에서 제공하는 xml 패키지를 사용해 읽어보자.
x_str = """
<book>
<name>혼자 공부하는 데이터 분석</name>
<author>박해선</author>
<year>2022</year>
</book>
"""파이썬에서 기본으로 제공되는 xml 패키지는 XML 문서를 읽고 쓸 수 있는 간편한 API를 제공한다. 여기서는 xml.etree.ElemenTree 모듈의 fromstring() 함수를 사용해 x_str 문자열을 XML로 변환해 보자.
import xml.etree.ElementTree as et
book = et.fromstring(x_str)json 패키지는 JSON 문자열을 파이썬 객체로 변환하지만, fromstring() 함수가 반환하는 객체는 단순한 파이썬 객체가 아니라 ElementTree 모듈 아래에 정의된 Element 클래스의 객체이다. type() 함수로 fromstring() 함수가 어떤 객체를 반환하는지 book 변수의 타입을 확신해 보면 다음과 같다.
print(type(book))
>>> <class 'xml.etree.ElementTree.Element'>또한 book 객체는 x_str에서 가장 먼저 등장하는 부모 엘리먼트인 < book>에 해당한다. book 객체의 tag 속성을 출력하면 엘리먼트 이름을 쉽게 확인할 수 있다.
print(book.tag)
>>> book자식 엘리먼트 확인하기: findtext() 메서드
XML 문서에서 추출하고 싶은 것은 도서명(name), 저자(author), 발행 연도(year)이다. 이를 위해 먼저 < book> 엘리먼트의 자식 엘리먼트를 구한 다음, 각각의 자식 엘리먼트에 담긴 텍스트를 읽을 수 있다. 먼저 book 객체를 리스트로 변환하여 자식 엘리먼트를 구해보자.
book_childs = list(book) → 리스트로 변환할 때는 list() 함수를 사용한다.
print(book_childs)
>>> [<Element 'name' at 0x7cc5eade5cb0>, <Element 'author' at 0x7cc5eade5d00>, <Element 'year' at 0x7cc5eade5d50>]실행 결과에서 볼 수 있듯이 book_dhilds에는 순서대로 도서명(name), 저자(author), 발행 연도(year) 엘리먼트가 담겨 있다.
이 book_childs 리스트 각 항목을 name, author, year 변수에 할당하고 text 속성으로 엘리먼트에 있는 텍스트를 출력한다.
name, author, year = book_childs
print(name.text)
print(author.text)
print(year.text)
>>> 혼자 공부하는 데이터 분석
박해선
2022성공적으로 XML 문서에 있는 세 가지 텍스트가 잘 출력되었다. 그러나 XML은 자식 엘리먼트 순서가 항상 일정하다는 것을 보장하지 않는다. 위처럼 book_childs에서 순서대로 자식 엘리먼트를 찾는 것은 위험하다.
book 객체의 findtext() 메서드를 사용하면 해당하는 자식 엘리먼트를 탐색하여 자동으로 텍스트 반환할 수 있다.
name = book.findtext('name')
author = book.findtext('author')
year = book.findtext('year')
print(name)
print(author)
print(year)
>>> 혼자 공부하는 데이터 분석
박해선
2022findtext() 메서드에 찾으려는 태그 이름을 넣어 주니 자동으로 해당 엘리먼트를 찾아 텍스트를 반환한다. 이런 방식은 자식 엘리먼트의 순서가 어떻게 되어 있든지 상관없기 때문에 안전하다.
x2_str = """
<books> → 부모 엘리먼트를 만든다.
<book>
<name>혼자 공부하는 데이터 분석</name>
<author>박해선</author>
<year>2022</year>
</book>
<book>
<name>혼자 공부하는 머신러닝+딥러닝</name>
<author>박해선</author>
<year>2020</year>
</book>
</books>
'''여기에서는 < books> 엘리먼트 안에 두 개의 < book> 엘리먼트를 포함시켰다. 이제 x2_str의 부모 엘리먼트는 < book>이 아니라 < books>가 된다. fromstring() 함수를 사용해 부모 엘리먼트를 확인하면 다음과 같다.
books = et.fromstring(x2_str)
print(books.tag)
>>> books여러 개의 자식 엘리먼트 확인하기: findall() 메서드와 for 문
< books> 안에 포함된 두 개의 < book> 엘리먼트를 찾아서 도서명, 저자, 발행 연도를 출력해보자.
동일한 이름을 가진 여러 개의 자식 엘리먼트를 찾을 때는 findall() 메서드와 for 문을 함께 사용하면 편리하다.
for book in books.findall('book'):
name = book.findtext('name')
author = book.findtext('author')
year = book.findtext('year')
print(name)
print(author)
print(year)
print()
>>> 혼자 공부하는 데이터 분석
박해선
2022
혼자 공부하는 머신러닝+딥러닝
박해선
2020< books>의 자식 엘리먼트를 모두 찾아 그 안에 담긴 텍스트를 잘 출력했다.
JSON의 경우 API에서 전달한 텍스트를 json.loads() 함수를 사용해 파이썬 객체로 바꾸어 내용을 추출했다면, XML은 xml.etree.ElemenTree 모듈에 있는 fromstring() 함수를 사용하여 부모(루트) 엘리먼트를 얻고, findall() 메서드로 자식 엘리먼트에 담긴 텍스트를 추출할 수 있다!
+ JSON처럼 XML를 바로 판다스로 바꾸는 방법이 있나요?
판다스 read_json() 함수 사용하면 JSON 문자열을 바로 판다스 데이터프레임으로 변환할 수 있다. XML도 비슷하게 read_xml() 함수를 사용하면 XML을 데디터프레임으로 변환해준다. read_xml() 함수는 판다스 1.3.0 버전부터 지원된다.
API로 20대가 가장 좋아하는 도서 찾기
-
도서관 정보나루에 접속. 메인 페이지 [데이터 활용] 탭을 클릭한 후 메뉴 아래에 [Open API 활용방법] 탭을 클릭. 이 탭에는 정보나루 웹사이트에서 제공하는 API가 정리되어 있다.
-
인증키를 받기 전에 다시 스크롤로 화면을 올려 이용안내 항목 옆의 [API매뉴얼다운로드] 버튼을 클릭. 다운로드한 PDF에서 연령별 대출 데이터를 제공하는 API가 있는지 알아보자.
-
도서관 정보나루 API 매뉴얼 PDF의 7쪽을 살펴보면 '3. 인기대출도서 조회'에서 연령별 데이터를 제공한다고 쓰여 있다.
API를 호출하는 URL 작성하기
도서관 정보나루 공개 API를 사용하려면 호출 URL이 필요하다. [3. 인기대출도서 조회] 항목에서 호출 URL 형식 보면 http로 시작한다. HTTP 프로토콜을 사용한다는 의미. 호출 URL이 아주 길어서 혼공분석이 데이터 조회에 필요한 것을 정리했다!
- 호출 URL : http://data4library/kr/api/loanItemSrch
- 파라미터
- format : 지정하지 않으면 XML 문서로 변환됨. 여기에서는 json으로 지정하여 JSON 문서로 받는다.- startDt : 검색 시작 일자.
- endDt : 검색 종료 일자.
- age : 연령대.
- authKey : 인증키. 정보나루 사이트에서 인증키 신청하여 받아야한다.
조회할 값은 호출 URL 뒤에 파라미터를 뒤에 연결하면 된다. 파라미터와 값은 =문자로 연결하고 파라미터 사이는 &문자로 연결한다. 호출 URL과 파라미터는 ?문자로 연결한다. 이러한 방식을 HTTP GET 방식이라고 한다.
파이썬으로 API 호출하기: requests 패키지
파이썬에서 URL을 호출하여 데이터 받을 수 있는 많은 방법 중, requests 패키지를 사용하자.
import requests
# 앞에서 만든 도서관 정보나루 API 인증키를 넣은 호출 URL을 변수에 저장.
url = "http://data4library.kr/api/loanItemSrch?format=json&startDt= \
2021-04-01&endDt=2021-04-3-&age=20&authKey=c01ec5e4575f..."
# 마지막 'c01ec5e4575f...'가 발급받은 API 인증키 입력하는 부분사용법 간단!! 이 URL은 HTTP GET 방식으로 파라미터 값을 전달하기 때문에 URL을 requests.get() 함수에 전달하는 것이 전부!
r - requests.get(url)get() 함수가 반환하는 값은 API 호출의 결과를 담고 있는 requests 패키지의 Response 클래스 객체이다.
이 객체는 유용한 여러 메서드를 제공한다. 이 중 json() 메서드는 편리하게도 웹 서버로부터 받은 JSON 문자열을 파이썬 객체로 변환하여 반환한다. 이 메서드를 사용해 브라우저에서 보았던 것과 받은 데이터가 같은지 확인해보자.
data = r.json()
print(data)
>>> {'response': {'request': {'startDt': '2021-04-01', 'endDt': '2021-04-30', 'age': '20', 'pageNo': 1, 'pageSize': 200}, 'resultNum': 200, 'numFound': 5000, 'docs': [{'doc': {'no': 1, 'ranking': '1', 'bookname': '우리가 빛의 속도로 갈 수 없다면 :김초엽 소설 ', 'authors': '지은이: 김초엽', 'publisher': '허블', 'publication_year': (이하 생략)실행 결과 보면 앞서 브라우저에 URl을 직접 입력하여 보았던 내용(105쪽)과 일치한다! 성공!!
+ JSON 말고 그냥 워논 데이터 받으려면 어떻게 해야 하나요?
requests.get() 함수로 얻은 응답 객체는 유용한 여러 속성을 제공한다. r.text에는 응답으로 받은 원본 텍스트를 담고 있다. r.content도 비슷하게 응답받은 데이터를 제공하지만 파이썬 바이트 객체(bytes)로 제공된다. 이미지와 같은 바이너리 데이터를 수신할 때 유용하게 사용할 수 있다. r.status_code는 HTTP 상태 코드를 담고 있다. 404이면 파일을 찾을 수 없다는 뜻이고 200이면 정상 응답을 의미한다.
코랩이나 주피터 노트북의 편리한 기능 중 하나는 print() 함수 사용하지 않아도 코드 셀의 마지막 라인의 실행 결과를 자동으로 출력해주는 것이다.
data
>>> {'response': {'request': {'startDt': '2021-04-01',
'endDt': '2021-04-30',
'age': '20',
'pageNo': 1,
'pageSize': 200},
'resultNum': 200,정렬되면 JSON의 전체 구조를 파악하기 쉽다. 맨 처음 'response' 키가 하나의 딕셔너리를 값으로 가지고 있다. 이 딕셔너리의 'docs' 키에 해당하는 값은 리스트이다. 이 리스트는 여러 개의 딕셔너리를 가지고 있다.
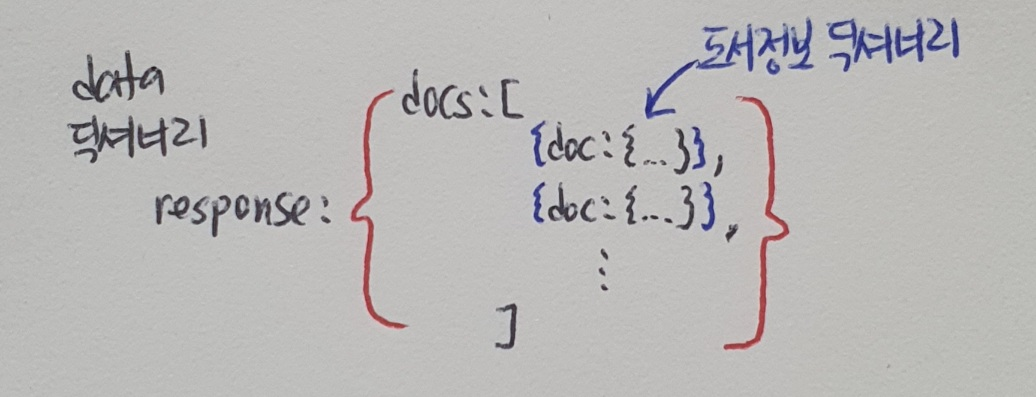
docs키와 doc 키는 각각 하나의 리스트와 하나의 딕셔너리만 가지고 있기 때문에 계층 구조를 표현하는 것 외에는 큰 역할이 없다. 실제 도서 정보는 doc 키에 매핑된 딕셔너리에 들어있다. 이 JSON 데이터를 판다스 데이터프레임으로 손쉽게 변환하기 위해 data 딕셔너리의 구조를 다음과 같이 바꾼다.
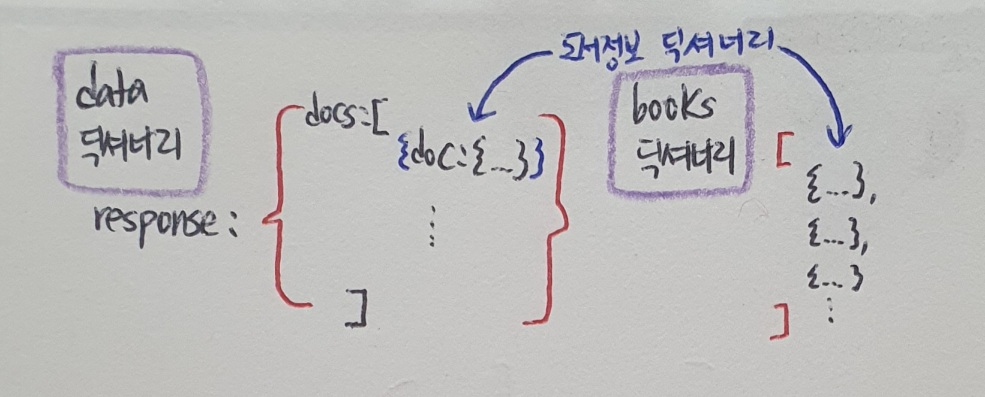
이렇게 만들기 위해 data['response']['docs']에 매핑된 리스트를 순화하면서 doc 키에 매핑된 딕셔너리를 추출한 후 빈 리스트에 추가해보자.
books = []
for d in data['response']['docs']:
books.append(d['doc'])
# books 변수에 원하는 대로 저장되었는지 확인
books
>>> [{'no': 1,
'ranking': '1',
'bookname': '우리가 빛의 속도로 갈 수 없다면 :김초엽 소설 ',
'authors': '지은이: 김초엽',
'publisher': '허블',
'publication_year': '2019',
'isbn13': '9791190090018',
'addition_symbol': '03810',
'vol': '',
'class_no': '813.7',
'class_nm': '문학 > 한국문학 > 소설',
'loan_count': '487',
'bookImageURL': 'https://image.aladin.co.kr/product/19359/16/cover/s972635417_1.jpg',
'bookDtlUrl': 'https://data4library.kr/bookV?seq=5430429'},
{'no': 2,
'ranking': '2',
'bookname': '달러구트 꿈 백화점 :이미예 장편소설',
'authors': '지은이: 이미예', (이하 생략)성공! 도서 정보가 담긴 딕셔너리의 리스트 잘 만들어졌다. 이제 남은 것은 판다스 DataFrame 클래스에 이 리스트 넘기는 것 뿐!
books_df = pd.DataFrame(books)
books_df
>>> no ranking bookname authors publisher publication_year isbn13 addition_symbol vol class_no class_nm loan_count bookImageURL bookDtlUrl
0 1 1 우리가 빛의 속도로 갈 수 없다면 :김초엽 소설 지은이: 김초엽 허블 2019 9791190090018 03810 813.7 문학 > 한국문학 > 소설 487 https://image.aladin.co.kr/product/19359/16/co... https://data4library.kr/bookV?seq=5430429
1 2 2 달러구트 꿈 백화점 :이미예 장편소설 지은이: 이미예 팩토리나인 2020 9791165341909 03810 813.7 문학 > 한국문학 > 소설 407 https://image.aladin.co.kr/product/24512/70/co... https://data4library.kr/bookV?seq=5707051 (이하 생략)인기 도서 목록이 데이터프레임의 각 행에 잘 저장되었다. 친절하게도 대출을 가장 많이 한 순서대로 정렬되어 있다. 지금 만든 프로그램을 정기적으로 실행하면 보고 자료를 손쉽게 만들 수 있을 것 같다!
마지막으로 JSON 파일로 저장해주는 to_json() 메서드를 통해 20대가 좋아하는 도서 200권 목록을 JSON 파일에 저장한다.
books_df.to_json('20s_best_book.json')정리
- API는 프로그램 간 데이터를 전달하기 위해 정한 규칙. 수동으로 데이터를 받는 방법은 매주, 매일 반복되는 작업에는 적절 X. 이런 경우 공개 API가 제공되는지 살펴보자. 공개 API를 사용하면 데이터 수집 과정을 자동화할 수 있다.
- HTTP는 웹에서 데이터를 주고받기 위한 프로토콜이다. 예를 들면 웹 페이지, 이미지 등을 받아 웹 브라우저에 나타내는데 HTTP를 사용한다. 그래서 웹 브라우저로 접속하는 인터넷 URL 주소는 모두 http 혹은 보안이 강화된 https로 시작한다.
- JSON은 근래에 아주 많이 사용하는 데이터 전달 포맷이다. 자바스크립트뿐만 아니라 웹 기반 API에서도 널리 대중화되어 있다. JSON의 장점은 HTML이나 XML보다 사람이 읽기 편하고 간단하게 파이썬 객체로 변환할 수 있는 것이다.
- XML은 JSON 보다 조금 장황하지만 사람이 이해하기 쉬운 구조적인 포맷을 제공한다. 파이썬에서는 기본으로 제공되는 xml 패키지를 사용하여 XML 문서에 있는 엘리먼트를 탐색할 수 있고, 판다스의 경우 read_xml() 함수를 사용하여 데이터프레임으로 바꿀 수 있다.
핵심 함수와 메서드 정리
json.dumps() : 파이썬 객체를 JSON 문자열로 변환.
json.loads() : JSON 문자열을 파이썬 객체로 변환.
pandas.read_json() : JSON 문자열을 판다스 시리즈나 데이터프레임으로 변환.
xml.etree.ElementTree.fromstring() : XML 문자열을 분석하여 xml.etree.ElementTree.Element 클래스 객체를 반환.
xml.etree.ElementTree.Element.findtext() : 지정한 태그 이름과 맞는 첫 번째 자식 엘리머트의 텍스트를 반환.
xml.etree.ElementTree.Element.findall() : 지정한 태그 이름과 맞는 모든 자식 엘리먼트를 반환.
requests.get() : HTTP GET 방식으로 URL을 호출하고 requests.Response 객체를 반환.
requets.Response.json() : 응답받은 JSON 문자열을 파이썬 객체로 변환하여 반환.
