도서 쪽수를 찾아서
웹 브라우저는 온라인 서점에 있는 도서 상세 페이지의 HTML을 가져와 보여준다. 도서의 쪽수를 알고 싶다면 requests 패키지를 사용하면 가능할 것 같다.
Yes24 사이트의 URL(http://www.yes24/com/Product/Goods/96024781)의 파라미터를 잠시 살펴보면 URL 뒤에 파라미터를 붙여 도서 상세 페이지를 불러오고 싶은데, 96024781란 값은 도서관 정보나루에서 얻은 데이터와 일치하는 항목이 없다. (아마도 이 값은 Yes24 사이트에서 자체적으로 관리하는 제품 번호 같다.)
이 문제는 Yes24 사이트에서 도서 제목이나 ISBN으로 검색을 해서 도서 상세 페이지로 넘어갈 수 있다. requests.get() 함수를 두 번 호출해야 하고, 검색 결과에서 도서 상세 페이지로 연결되는 URL도 차장야 하지만 아주 어렵지 않다.
[링크 URL → requests.get()으로 도서 검색 결과 가져오기 → 검색 결과에서 도서 상세 페이지로 연결되는 링크 url 추출 → 다시 requests.get()으로 도서 상세 페이지 가져오기 → 도서 상세 페이지에서 쪽수 추출]
Yes24 검색 창에 <혼자 공부하는 머신러닝+딥러닝> ISBN을 입력하여 도서를 검색했을 때 해당 검색 결과 페이지의 URL은 다음과 같다.
http://www.yes24.com/Product/Search?domain=BOOK&query=9791162243664
(여기서 '9791162243664'가 ISBN)
위 URL을 활용해서 query 파라미터에 도서관 정보나루에서 받은 ISBN을 넣으면 쉽게 원하는 도서가 들어있는 결과 페이지를 얻을 수 있다. 이 검색 결과 페이지 HTML에서 <혼자공부하는 머신러닝+딥러닝> 상세 페이지로 연결되는 링크 URL을 찾아야 한다.
requests 패키지 사용하면 검색 결과 페이지의 HTML을 비교적 쉽게 얻을 수 있을 것이다. 문제는 그 다음! 이 HTML에서 도서 상세 페이지로 넘어가는 링크 URL을 찾아야하는데 이건 쉽지 않다. 사람은 눈으로 화면을 보고 쉽게 도서 상세 페이지의 링크 URL을 찾을 수 있지만 프로그램이 보는 것은 그냥 많은 문자로 이루어진 텍스트일 뿐이다.
만약 링크 URL을 잘 찾을 수 있따면 다시 이 주소를 사용해서 도서 상세 페이지를 가져오는 것은 어렵지 않다. 그리고 도서 상세 페이지에서 최종적으로 쪽수를 추출해야 한다.
이런 식으로 프로그램으로 웹사이트의 페이지를 옮겨 가면서 데이터를 추출하는 작업을 웹 스크래핑(web scraping) 혹은 웹 크롤링(web crawling)이라고 부른다. 이전 절에서 requests 패키지로 데이터를 받는 방법을 배웠으니 이번 절에서 가져온 HTML에서 데이터를 추출 방법을 배우면 아주 간단한 웹 스크래핑 프포그램을 완성할 수 있다.
검색 결과 페이지 가져오기
# gdown 패키지 사용해 다운로드
import gdown
gdown.download('https://bit.ly/3q9SZix', '20s_best_book.json', quiet=False)
# 판다스 데이터프레임으로 불러 온 후 상위 5개 추출
import pandas as pd
books_df = pd.read_json('20s_best_book.json')
books_df.head()
>>> no ranking bookname authors publisher publication_year isbn13 addition_symbol vol class_no class_nm loan_count bookImageURL
0 1 1 우리가 빛의 속도로 갈 수 없다면 :김초엽 소설 지은이: 김초엽 허블 2019 9791190090018 03810 813.7 문학 > 한국문학 > 소설 461 https://image.aladin.co.kr/product/19359/16/co...
1 2 2 달러구트 꿈 백화점.이미예 장편소설 지은이: 이미예 팩토리나인 2020 9791165341909 03810 813.7 문학 > 한국문학 > 소설 387 https://image.aladin.co.kr/product/24512/70/co...
2 3 3 지구에서 한아뿐 :정세랑 장편소설 지은이: 정세랑 난다 2019 9791188862290 03810 813.7 문학 > 한국문학 > 소설 383 https://image.aladin.co.kr/product/19804/82/co...
3 4 4 시선으로부터, :정세랑 장편소설 지은이: 정세랑 문학동네 2020 9788954672214 03810 813.7 문학 > 한국문학 > 소설 370 https://image.aladin.co.kr/product/24131/37/co...
4 5 5 아몬드 :손원평 장편소설 지은이: 손원평 창비 2017 9788936434267 03810 813.7 문학 > 한국문학 > 소설 365 http://image.aladin.co.kr/product/16839/4/cove...books_df 데이터프레임은 열이 많아서 한 눈에 들어오지 않는다. 이 데이터프레임에서 'no' 열 부터 'isbn13' 열까지만 선택해서 새로운 데이터프레임 만들어보자. ['no', 'ranking', 'bookname']처럼 원하는 열 이름을 리스트로 만들어 데이터프레임의 인덱스처럼 사용하면 된다.
books = boos_df[['no', 'ranking', 'bookname', 'authors', 'publisher', 'publication_year', 'isbn13']]
books.head()
>>> no ranking bookname authors publisher publication_year isbn13
0 1 1 우리가 빛의 속도로 갈 수 없다면 :김초엽 소설 지은이: 김초엽 허블 2019 9791190090018
1 2 2 달러구트 꿈 백화점.이미예 장편소설 지은이: 이미예 팩토리나인 2020 9791165341909
2 3 3 지구에서 한아뿐 :정세랑 장편소설 지은이: 정세랑 난다 2019 9791188862290
3 4 4 시선으로부터, :정세랑 장편소설 지은이: 정세랑 문학동네 2020 9788954672214
4 5 5 아몬드 :손원평 장편소설 지은이: 손원평 창비 2017 9788936434267한 눈에 들어온다. 그런데 일곱 개나 되는 열 이름을 모두 쓰는 건 번거롭다. 만약 선택해야 할 열이 더 많다면 아주 귀찮은 일이다. 더우이 열 이름을 하나라도 잘못 쓰면 오류가 난다.
데이터프레임 행과 열 선택하기: loc 메서드
판다스가 제공하는 loc 메서드를 사용하면 원하는 행과 열을 조금 더 쉽게 선택할 수 있다. loc는 메서드이지만 대괄호를 사용하여 행의 목록과 열의 목록을 받는다.
loc 메서드의 첫 번째 메개변수로 행 인덱스 0과 1을 리스트로 전달하고 두 번째 매개변수로 열 이름 'bookname', 'authors'를 리스트로 전달한다. 이렇게 쓰면 첫 번째, 두 번째 행의 도서명과 저자만 추출하여 데이터프레임을 만들 수 있다.
books_df.loc[[0,1], ['bookname', 'authors']]
>>> bookname authors
0 우리가 빛의 속도로 갈 수 없다면 :김초엽 소설 지은이: 김초엽
1 달러구트 꿈 백화점.이미예 장편소설 지은이: 이미예+ iloc도 있던데 이건 무엇인가요?
ioc 메서드는 인덱스와 열 이름을 사용한다. 열 이름이 곧 인덱스이기 때문에 열 인덱스라고도 부른다.
iloc 메서드는 인덱스의 위치를 사용한다. books_df의 행 인덱스는 0부터 시작하므로 인덱스와 인덱스 위치가 같다. 열의 경우 'no'부터 위치가 0에서 시작하여 1씩 증가한다. 따라서 앞의 코드를 iloc로 다시 쓰면 books_df.iloc[[0,1]. [2,3]]과 같다.
더욱 편리한 것은 리스트 대신 슬라이스 연산자(:)를 쓸 수도 있다.
books_df.loc[0:1, 'bookname':'authors']
>>> bookname authors
0 우리가 빛의 속도로 갈 수 없다면 :김초엽 소설 지은이: 김초엽
1 달러구트 꿈 백화점.이미예 장편소설 지은이: 이미예하지만 loc 메서드의 슬라이싱은 파이썬의 슬라이싱과 다르게 마지막 항목도 포함한다. 그래서 두 개의 행과 'bookname', 'authors' 열이 모두 포함되어 있다.
시작과 끝을 지정하지 않고 슬라이스 연산자를 사용하면 전체를 의미한다. 따라서 전체 행과 'no' 열에서 'isbn13' 열까지 선택하는 코드를 다음처럼 쓸 수 있다.
books = boos_df.loc[:, 'no':'isbn13']
>>> no ranking bookname authors publisher publication_year isbn13
0 1 1 우리가 빛의 속도로 갈 수 없다면 :김초엽 소설 지은이: 김초엽 허블 2019 9791190090018
1 2 2 달러구트 꿈 백화점.이미예 장편소설 지은이: 이미예 팩토리나인 2020 9791165341909
2 3 3 지구에서 한아뿐 :정세랑 장편소설 지은이: 정세랑 난다 2019 9791188862290
3 4 4 시선으로부터, :정세랑 장편소설 지은이: 정세랑 문학동네 2020 9788954672214
4 5 5 아몬드 :손원평 장편소설 지은이: 손원평 창비 2017 9788936434267전체 열 이름 나열보다 loc 메서드와 슬라이스 연산자를 사용하니 훨씬 간단하게 원하는 데이터프레임을 만들 수 있다.
_+ 파이썬 슬라이싱처럼 스탭(step)을 지정할 수 있나요?
물론!! 다음처럼 2를 추가해주면 하나씩 건너뛰며 행을 선택한다.
books_df.loc[::2, 'no':'isbn13'].head()
>>> no ranking bookname authors publisher publication_year isbn13
0 1 1 우리가 빛의 속도로 갈 수 없다면 :김초엽 소설 지은이: 김초엽 허블 2019 9791190090018
2 3 3 지구에서 한아뿐 :정세랑 장편소설 지은이: 정세랑 난다 2019 9791188862290
4 5 5 아몬드 :손원평 장편소설 지은이: 손원평 창비 2017 9788936434267
6 7 7 목소리를 드릴게요 :정세랑 소설집 지은이: 정세랑 아작 2020 9791165300005
8 9 9 선량한 차별주의자 김지혜 지음 창비 2019 9788936477196
검색 결과 페이지 HTML 가져오기: requests.get() 함수
이제 02-1절에서 실습했던 것처럼 requests 패키지를 임포트하고 requests.get() 함수로 첫 번째 도서에 대한 검색 결과 페이지 HTML을 가져와 보자.
먼저 첫 번째 도서의 ISBN과 Yes24 검색 결과 페이지 URL을 위한 변수를 정의한다. 그 다음 requests.get() 함수를 호출할 때 파이썬 문자열의 format() 메서드를 사용해 isbn 변수에 저장된 값을 url 변수에 전달한다.
이렇게 하면 다음처럼 url 변수에 있는 중괄호 {} 부분이 isgn 값으로 바뀐다.
http://www.yes24.com/Product/Search?domain=BOOK&query=9791190090018
import requests
isbn = 9791190090018 # '우리가 빛의 속도로 갈 수 없다면'의 isbn
url = http://www.yes24.com/Product/Search?domain=BOOK&query={}'
r = requests.get(url.format(isbn))그 다음 requeste.get() 함수가 반환한 응답 객체를 사용해 도서 검색 결과 페이지 HTML을 출력한다.
print(r.text)
>>> (중략)
</div>
<div class="info_row info_name">
<span class="gd_res">[도서]</span>
<a class="gd_name" href="/Product/Goods/74261416" onclick="wiseLogV2('S', '101_005_003_001', ''); setGoodsClickExtraCodeHub('032', '9791190090018', '74261416', '0');">우리가 빛의 속도로 갈 수 없다면</a>
<span class="gd_feature">[ 양장 ]</span>
<a href="/Product/Goods/74261416" target="_blank" class="bgYUI ico_nWin" onclick="wiseLogV2('S', '101_005_003_001', ''); setGoodsClickExtraCodeHub('032', '9791190090018', '74261416', '0');">우리가 빛의 속도로 갈 수 없다면 새창이동</a>
</div>
<div class="info_row info_pubGrp">
<span class="authPub info_auth" onclick="wiseLogV2('S', '101_005_003_002', '');">
<a href="https://www.yes24.com/Product/Search?domain=ALL&query=김초엽&authorNo=208250&author=김초엽" target="">김초엽</a> 저
</span>
<span class="authPub info_pub" onclick="wiseLogV2('S', '101_005_003_003', '');"><a href="https://www.yes24.com/Product/Search?&domain=ALL&company=%ed%97%88%eb%b8%94&query=%ed%97%88%eb%b8%94">허블</a></span>
<span class="authPub info_date">2019년 06월</span>
</div> (이하 생략)성공!! 이전 절에서 request 패키지를 사용해 보았기 때문에 어렵지 않게 첫 번째 도서의 검색 결과 페이지 HTML을 가져올 수 있었다. 이제 이 HTML에서 도서 상세 페이지로 넘어가는 링크를 어떻게 찾을까?
HTML에서 데이터 추출하기: 뷰티플수프
웹 페이지나 웹 기반 API 호출하는데 requests 패키지를 많이 사용함. 비슷하게 HTML 안에 있는 내용 찾을 때는 뷰티플수프(beautiful Soup)가 널리 사용된다.
크롬 개발자 도구로 HTML 태그 찾기
-
Yes24 웹사이트에서 첫 번째 도서의 ISBN인 [9791190090018]을 검색한다. 검색 결과 화면이 나타나면 마우스 오른쪽 버튼을 클릭하여 팝업 메뉴를 띄우고 [검사]를 선택한다.
-
분할로 별도의 창이 열린다. 이 화면에서 현재 웹 페이지의 HTML을 볼 수 있다. 이 창을 개발자 도구라고 부른다. 간단하게 F12 키를 눌러도 열린다.
-
HTML에서 링크가 들어있는 위치를 찾아보자. Yes24 검색 결과 페이지를 스크롤하여 도서명이 화면에 보이게 한다. 그 다음 개발자 도구 창 메뉴 바에서 [Select] 아이콘을 클릭하고 이름 위에 마우스 커서 올리면 자동으로 개발자 도구에 HTML 위치가 나타난다.
from bs4 import BeautifulSoup
# 이 클래스의 객체 생성.
# 첫 번째 매개변수는 파싱(parsing)할 HTML 문서이고 두 번째는 피싱에 사용할 피서(parser)이다.
soup = BeautifulSOup(r.text, 'html.parser')+ 피싱과 파서가 뭔가요?
파서느 입력 데이터를 받아 데이터 구조를 만드는 소프트웨어 라이브러리를 의미함. 그리고 이런 과정을 피싱이리ㅏ고 부른다. 02-1에서 사용했던 json 패키지, xml 패키지가 각각 JSON과 XMl을 위한 파서라고 볼 수 있다.
html.parser는 파이썬에 게본 내장된 HTML 파서이다. 뷰티플수프는 lxml 패키지가 설치되어 있는 경우 lxml을 우선적으로 사용함. lxml 패키지는 XML과 HTML 피싱 기능을 제공하는 패키지로 html.parser보다 빠르지만, 엄격하게 HTML 표준을 검사하기 때문에 피싱에 실패하는 경우가 있다. Yes24에서 가져온 HTML이 이런 경우이다. 따라서 코랩에 설치된 lxml 패키지 대신 파이썬 내장 파서를 사용하기 위해 'html.parser'로 지정함.
개발자 도구 창에서 찾은 링크는 다음처럼 HTML의 < a >태그 안에 포함되어 있다.
태그 위치 찾기: find() 메서드
태그 위치는 soup 객체의 find() 메서드를 사용하면 간편하게 찾을 수 있다. 첫 번째 매개변수에는 찾을 태그 이름을 지정하고, attrs 매개변수에는 찾으려는 태그의 속성을 딕셔너리로 지저하면 된다. 예를 들어 soup.find('div', attrs={'id':'search'})는 id 속성이 'search'인 < div >태그를 찾으라느 의미이다.
도서 상세 페이지 링크가 있는 < a > 태그를 살펴보면 class 속성이 "gd_name"으로 지정되어 있다. 따라서 다음처럼 find 메서드를 구성하면 손쉽게 < a > 태그를 추출할 수 있다.
prd_link = soup.find('a', attrs={'class':'gd_name'})링크가 포함되어 있는 prd_link는 뷰티플수프의 Tag 클래스 객체이다. 이 객체를 print() 함수로 출력하면 태그 안에 포함된 HTML을 출력한다.
print(prd_link)
>>> <a class="gd_name" href="/Product/Goods/74261416" onclick="wiseLogV2('S', '101_005_003_001', ''); setGoodsClickExtraCodeHub('032', '9791190090018', '74261416', '0');">우리가 빛의 속도로 갈 수 없다면</a>prd_link를 딕셔너리처럼 사용해 태그 안의 속성을 참조할 수 있다. 이 방법으로 링크 주소인 href 속성의 값을 얻을 수 있다.
print(prd_link['href'])
>>> /Product/Goods/74261416뷰티플수프를 사용해 Yes24의 검색 결과 페이지에서 도서의 상세 페이지로 넘어가는 링크를 찾았다!! 이 주소만 있다면 다시 requests.get() 함수를 사용해 쪽수가 담긴 상세 페이지 HTML을 가져올 수 있다!!
도서 상세 페이지 HTML 가져오기
검색 결과 페이지를 가져왔을 때처럼 상세 페이지 주소를 만들어 requests.get() 함수를 호출해보자!
# '우리가 빛의 속도로 갈 수 없다면'의 상세 페이지 가져오기
url = 'http://www.yes24.com'+prd_link['herf']
r = requests.get(url)
# 출력
print(r.text)
>>>
<!DOCTYPE html >
<html lang="ko">
<head><link rel="canonical" href="https://www.yes24.com/Product/Goods/74261416"> <link rel="alternate" media="only screen and(max-width: 640px)" href="https://m.yes24.com/Goods/Detail/74261416">
<meta http-equiv="X-UA-Compatible" content="IE=Edge" />
<meta http-equiv="Content-Type" content="text/html;charset=utf-8" />
<meta http-equiv="Accept-CH" content="dpr, width, viewport-width, rtt, downlink, ect, UA, UA-Platform, UA-Arch, UA-Model, UA-Mobile, UA-Full-Version" />
<meta http-equiv="Accept-CH-Lifetime" content="86400" />
<meta name="referrer" content="unsafe-url" />
<meta name="viewport" content="width=1170" />
<title>우리가 빛의 속도로 갈 수 없다면 - 예스24 </title>
(이하 생략)상세 페이지 잘 가져왔다! 이제 크롬 브라우저의 개발자 도구를 열어 쪽수가 담긴 HTML 위치를 찾자.
-
Yes24의 『우리가 빛의 속도로 갈 수 없다면』 도서 상세 페이지에 접속하여 마우스 오른쪽 버튼 클릭 후 팝업 메뉴 띄우고 [검사]를 선택한다.
-
개발자 도구를 열고 [Select] 아이콘을 클릭 후 도서의 품목정보 아래 있는 [쪽수]를 선택한다.
쪽수는 품목정보를 포함하고 있는 < div id="infoset_specific" classgd_infoSet infoSet_noLine" > 태그 안에 있다. 이 < div > 태그는 품목정보를 위해서만 사용되는 것 같기 때문에 다른 < div >와 혼동될 염려없이 find() 메서드로 id 속성이 "infoset_specific"인 div 태그를 찾을 수 있다.
soup = BeautifulSoup(r.text, 'html.parser')
prd_detail = soup.find('div', attrs={'id':'infoset_specific'})
print(prd_detail)
>>> <div class="gd_infoSet infoSet_noLine" id="infoset_specific">
<div class="tm_infoSet">
<h4 class="tit_txt">품목정보</h4>
</div>
<div class="infoSetCont_wrap">
<div class="yesTb">
<table class="tb_nor tb_vertical" summary="품목정보 국내도서, 외국도서 " width="100%">
<caption>품목정보</caption>
<colgroup>
<col width="170"/>
<col width="*"/>
</colgroup>
<tbody class="b_size">
<tr>
<th class="txt" scope="row">발행일</th>
<td class="txt lastCol">2019년 06월 24일</td>
</tr>
<tr>
<th class="txt" scope="row">판형</th>
<td class="txt lastCol">
양장
<a class="bgYUI ico_comm ico_help" href="javascript:void(0);" onclick="$.yesPop('dPop_binding',this,{cock:true,mask:false,pWidth:640,ajaxURL : '/Product/Goods/Popup?id=dPop_bookBindingMethodInfo'});" title="도서 제본방식 안내">도서 제본방식 안내</a>
</td>
</tr>
<tr>
<th class="txt" scope="row">쪽수, 무게, 크기</th>
<td class="txt lastCol">330쪽 | 496g | 130*198*30mm</td>
</tr>
<tr>
<th class="txt" scope="row">ISBN13</th>
<td class="txt lastCol">9791190090018</td>
</tr>
<tr>
<th class="txt" scope="row">ISBN10</th>
<td class="txt lastCol">1190090015</td>
</tr>
</tbody>
</table>
</div>
</div>
<script type="text/javascript">
if ($("#infoset_specific table tbody tr").length == 0) {
$("#infoset_specific").remove();
}
</script>
</div>_+ < div > 태그 대신 그 아래 < table > 태그 찾으면 안되나요?
품목정보는 < div > 태그 아래 < table class="tb_nor_tb_vertical" summary="품목정보 국내도서, 외국도서 " width="100%" > 태그 안에 있다. 따라서 바로 이 테이블을 다음처럼 찾을 수 있다.
prd_detail = soup.find('table', attrs={'class':'tb_nor tb_vertical'})하지만 class 속성이 "tbnor tb_vertical"인 < table > 태그가 상세 페이지 안에서 항상 유일한 것인지 확신이 서지 않는다. 대신 id 속성이 "infoset_specific"인 < div > 태그는 이름으로 미루어 보아 품목정보를 나타내기 위해 사용한 것이라 짐작할 수 있다.
테이블 태그를 리스트로 가져오기: find_all() 메서드
앞서 찾은 < div > 태그 안에 다음과 같은 품목정보 테이블이 들어있다. 이 테이블에서 '쪽수, 무게, 크기'에 해당하는 행인 < tr > 태그를 찾아 < td > 태그 안에 있는 텍스트를 가져오면 된다.
[출간일 2019년 06월 24일
판형 양장 < tr > 태그
쪽수, 무게, 크기 330쪽 | 496g | 13019830mm < tr > 태그
ISBN13 9791190090018
ISBN10 1190090015]
< th> 태그 < td > 태그
품목정보 테이블의 행을 하나씩 검사해서 '쪽수, 무게, 크기'에 해당하는 < tr > 태그를 찾아야한다. 뷰티플수프의 find_all() 메서드를 사용하면 특정 HTML 태그를 모두 찾아서 리스트로 반환해 준다.
prd_tr_list = prd_detail.find_all('tr')
print(prd_tr_list)
>>> [<tr>
<th class="txt" scope="row">발행일</th>
<td class="txt lastCol">2019년 06월 24일</td>
</tr>, <tr>
<th class="txt" scope="row">판형</th>
<td class="txt lastCol">
양장
<a class="bgYUI ico_comm ico_help" href="javascript:void(0);" onclick="$.yesPop('dPop_binding',this,{cock:true,mask:false,pWidth:640,ajaxURL : '/Product/Goods/Popup?id=dPop_bookBindingMethodInfo'});" title="도서 제본방식 안내">도서 제본방식 안내</a>
</td>
</tr>, <tr>
<th class="txt" scope="row">쪽수, 무게, 크기</th>
<td class="txt lastCol">330쪽 | 496g | 130*198*30mm</td>
</tr>, <tr>
<th class="txt" scope="row">ISBN13</th>
<td class="txt lastCol">9791190090018</td>
</tr>, <tr>
<th class="txt" scope="row">ISBN10</th>
<td class="txt lastCol">1190090015</td>
</tr>]태그 안의 텍스트 가져오기: get_text() 메서드
< tr > 태그를 리스트로 추출하고 나면 다음 작업은 간단하다. for 문으로 prd_tr_list를 순화하면서 < th > 태그 안의 텍스트가 '쪽수, 무게, 크기'에 해당하는지 검사한다. 우리가 원하는 행을 찾으면 < td > 태그 안에 담긴 텍스트를 page_td 변수에 저장하면 된다.
< td > 안에 있는 텍스트를 가져오려면 Tag 객체의 get_text() 메서드를 사용한다. get_text() 메서드는 태그 안의 텍스트를 반환한다. 예를 들어 tag가 < a href='...' >클릭하세요< /a > 태그일 때 tag.get_text()는 '클릭하세요'를 반환한다.
prd_tr_list 리스트를 순화하면서 쪽수 행을 찾아 출력해보자.
for tr in prd_tr_list:
if tr.find('th').get_text() == '쪽수, 무게, 크기':
page_td = tr.find('td').get_text()
break
# page_id에 쪽수가 잘 담겼는지 확인
print(page_td)
>>> 330쪽 | 496g | 130*198*30mm성공이다!! 이후 파이썬 문자열 객체에서 split() 메서드를 호출하면 공백을 기준으로 문자열을 나누어 리스트로 반환해준다.
print(page_td.split()[0])
>>> 330쪽나머지 도서들의 쪽수도 동일한 방법으로 가져올 수 있다!
전체 도서의 쪽수 구하기
앞에서 했던 작업을 하나의 함수로 만들어보자. 순서대로 정리하면 다음과 같다.
① 온라인 서점의 검색 결과 페이지 URL을 만든다.
② requests.get() 함수로 검색 결과 페이지의 HTML을 가져온다.
③ 뷰티플수프로 HTML을 파싱한다.
④ 뷰티플수프의 find() 메서드로 < a > 태그를 찾아 상세 페이지 URL을 추출한다.
⑤ requests.get() 함수로 다시 도서 상세 페이지의 HTML을 가져온다,
⑥ 뷰티플수프로 HTML을 파싱한다.
⑦ 뷰티플수프의 find() 메서드로 '품목정보' < div > 태그를 찾는다.
⑧ 뷰티플수프의 find_all() 메서드로 '쪽수'가 들어있는 < tr > 태그를 찾는다.
⑨ 앞에서 찾은 테이블의 행에서 get_text() 메서드로 < td > 태그에 들어있는 '쪽수'를 가져온다.
이 작업을 구현한 get_page_cnt() 함수는 ISBN 정수 값을 받아 쪽수를 반환한다.
def get_page_cnt(isbn):
# Yes24 도서 검색 페이지 URL
url = 'http://www.yes24.com/Product/Search?domain=BOOK&query={}'
# URL에 ISBN을 넣어 HTML 가져옵니다.
r = requests.get(url.format(isbn))
soup = BeautifulSoup(r.text, 'html.parser') # HTML 파싱
# 검색 결과에서 해당 도서를 선택합니다.
prd_info = soup.find('a', attrs={'class':'gd_name'})
if prd_info == None:
return ''
# 도서 상세 페이지를 가져옵니다.
url = 'http://www.yes24.com'+prd_info['href']
r = requests.get(url)
soup = BeautifulSoup(r.text, 'html.parser')
# 상품 상세정보 div를 선택합니다.
prd_detail = soup.find('div', attrs={'id':'infoset_specific'})
# 테이블에 있는 tr 태그를 가져옵니다.
prd_tr_list = prd_detail.find_all('tr')
# 쪽수가 들어 있는 th를 찾아 td에 담긴 값을 반환합니다.
for tr in prd_tr_list:
if tr.find('th').get_text() == '쪽수, 무게, 크기':
return tr.find('td').get_text().split()[0]
return ''
# 첫 번째 도서의 ISBN을 넣어 함수를 테스트 해본다.
get_page_cnt(9791190090018)
>>> '330쪽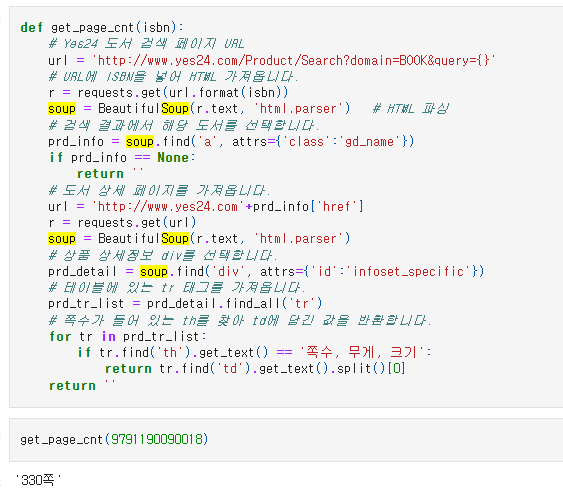
기대했던 값 그대로 나왔다!!!
데이터프레임 행 혹은 열에 함수 적용하기: apply() 메서드
books_df 데이터프레임에는 모두 200개의 도서가 들어 있다. 이 중에 가장 인기 있는 10권의 도서의 쪽수를 가져오기 위해 head() 함수로 10개 행만 가져와 데이터프레임을 만든다.
top10_books = books.head(10)이제 top_10_books의 각 행에 get_page_cnt() 함수를 적용하여 10개 도서의 쪽수를 한 번에 구하려한다. 각 행의 반복 작업을 수행하기 위해서 데이터프레임은 apply() 메서드를 제공한다.
apply() 메서드의 첫 번째 매개변수느 실행할 함수이다. 따라서 데이터프레임의 한 행을 받아 get_page_cnt() 함수를 사용해 쪽수 구하는 함수를 만들어야 한다. 이 함수는 단순히 'isbn13' 열의 값을 get_page_cnt() 함수로 전달하는 역할만 수행한다.
def get_page_cnt2(row):
isbn = row['isbn13']
return get_page_cnt(isbn)새로 만든 get_page_cnt2() 함수를 apply() 메서드에 다음과 같이 사용한다. 여기서는 각 행에 함수를 적용해야 하므로 axis 매개변수를 1로 지정한다. 기본값인 0을 지정하면 각 열에 대해 함수를 적용한다.
page_count = top10_books.apply(get_page_cnt2, axis=1)
print(page_count)
>>> 0 330쪽
1 300쪽
2 228쪽
3 340쪽
4 264쪽
5 396쪽
6 272쪽
7
8 244쪽
9 296쪽
dtype: object쪽수 잘 추출됨!!! 각 행에 적용한 get_page_cnt2() 함수의 결괏값은 page_count 변수에 판다스 시리즈 객체로 저장된다.
_+ 함수를 두 번 만들지 않고 더 간결하게 작성할 수 없을까??
람다(lambda) 함수를 사용해보면 된다. 람다 함수는 함수 이름 없이 한 줄로 쓰는 함수이다. 코드를 간결하게 작성할 수 있어 함수를 간단하고 빠르게 구현할 수 있다.
본문에서 작성한 get_page_cnt2() 함수 대신 람다 함수를 apply() 메서드에 사용한다면 다음과 같이 쓸 수 있다.
page_count = top10_books.apply(lambda row: get_page_cnt(row[;isbn13']), axis=1)람다 함수로 코드를 바꾸어 실행하면 훨씬 간단하게 작성하고도 동일한 결과를 얻을 수 있다._
데이터프레임과 시리즈 합치기: merge() 함수
잊 추출한 page_count 시리즈 객체를 top10_books 데이터프레임의 열로 합쳐 보자 이렇게 하면 도서명과 쪽수를 한 눈에 볼 수 있다.
먼저 page_count 시리즈 객체에 이름을 지정해준다. 이 이름은 top10_books 데이터프레임에 추가될 떄 열 이름으로 사용된다. 시리즈 객체의 name 속성을 사용하면 이름을 간단하게 지정할 수 있다.
page_count.name = 'page_count'
print(page_count)
>>> 0 330쪽
1 300쪽
2 228쪽
3 340쪽
4 264쪽
5 396쪽
6 272쪽
7
8 244쪽
9 296쪽
Name: page_count, dtype: objectpage_count 이름이 잘 설정되었다! 이제 top10_books 데이터프레임과 page_count 시리즈를 합친다.
판다스에서 두 데이터프레임을 합치거나 데이터프레임과 시리즈를 합칠 때 merge() 함수를 사용할 수 있다. 첫 번째와 두 번째 매개변수는 합칠 데이터프레임이나 시리즈 객체이다. 두 객체의 인덱스를 기준으로 합칠 경우 left_index와 right_index 매개변수를 True로 지정한다.
top10_with_page_count = pd.merge(top10_books, page_count, left_index = True, right_index = True)
top10_with_page_count
>>> no ranking bookname authors publisher publication_year isbn13 page_count
0 1 1 우리가 빛의 속도로 갈 수 없다면 :김초엽 소설 지은이: 김초엽 허블 2019 9791190090018 330쪽
1 2 2 달러구트 꿈 백화점.이미예 장편소설 지은이: 이미예 팩토리나인 2020 9791165341909 300쪽
2 3 3 지구에서 한아뿐 :정세랑 장편소설 지은이: 정세랑 난다 2019 9791188862290 228쪽
3 4 4 시선으로부터, :정세랑 장편소설 지은이: 정세랑 문학동네 2020 9788954672214 340쪽
4 5 5 아몬드 :손원평 장편소설 지은이: 손원평 창비 2017 9788936434267 264쪽
5 6 6 피프티 피플 :정세랑 장편소설 지은이: 정세랑 창비 2016 9788936434243 396쪽
6 7 7 목소리를 드릴게요 :정세랑 소설집 지은이: 정세랑 아작 2020 9791165300005 272쪽
7 8 8 나미야 잡화점의 기적 :히가시노 게이고 장편소설 지은이: 히가시노 게이고 ;옮긴이: 양윤옥 현대문학 2012 9788972756194
8 9 9 선량한 차별주의자 김지혜 지음 창비 2019 9788936477196 244쪽
9 10 9 쇼코의 미소 :최은영 소설 지은이: 최은영 문학동네 2016 9788954641630 296쪽top10_books 데이터프레임과 page_count 시리즈를 인덱스를 기주으로 합쳐서 top10_with_page_count 데이터프레임을 만들었다.
웹 스크래핑 할 때 주의할 점
1. 웹사이트에서 스크래핑을 허락하였는지 확인하기!
대부분의 웹사이트는 검색 엔진이나 스크래핑 프로그램이 접근해도 좋은 페이지와 그렇지 않은 페이지를 명시한 robots.txt 파일을 가지고 있다.
다행히 검색 결과 페이지인 /Product/Search와 도서 상세 페이지인 /Product/Goods는 따로 기재되어 있지 않으니 제한하지 않는다는 의미로 볼 수 있다. 대신 /member/,/Product/Goods/addModules/ 등과 같은 페이지는 웹 스크래핑 도구로 접근해서는 안된다. 이처럼 어떤 웹 페이지를 스크래핑하고 싶다면 먼저 robots.txt 파일을 확인하자!
2. HTML 태그를 특정할 수 있는지 확인하기!
태그 이름이나 속성 등 필요한 HTML 태그를 특정할 수 없다면 웹 스크래핑으로 데이터를 가져오는데 어려움이 있다. 또한 일부 웹 페이지는 웹 브라우저에 로딩된 후 HTML 대신 자바스크립트를 사용하여 웹 서버로부터 데이터를 가져와 화면을 채운다. 이런 데이터는 단순한 웹 스크래핑을 사용해서 가져오기 힘들 수 있다. 셀레니움(selenium) 같은 고급 도구를 사용해야 가능하다.
이러한 이유로 웹 스크래핑은 만능 도구가 아니며 최후의 수단으로 사용하는 것이 좋다. API나 데이터베이스와 달리 웹 페이지는 언제 어떻게 바뀔지 모르기 때문에 스크래핑 프로그램이 원하는 데이터를 찾지 못하는 경우가 빈번하게 발생한다. 웹 페이지가 변경된 것을 알았더라도 HTML을 다시 분석하여 원하는 데이터를 찾는 과정을 되풀이해야 한다. 이는 스크래핑 프로그램의 유지 보수를 어렵게 만드는 이유 중 하나이다.
merge() 함수의 매개변수
140쪽에서 merge() 함수에 left_index와 right_index 매개변수를 지정하여 데이터프레임이나 시리즈 객체를 합치는 것을 배웠다. 데이터프레임이나 시리즈를 합칠 때는 매개변수에 합칠 기준을 다양하게 지정하여 데이터를 원하는 형태로 만들 수 있다.
df1 df2
col1 col2 col1 col2
0 a 1 0 a 10
1 b 2 1 b 20
2 c 3 2 d 30
on 매개변수
합칠 때 기준이 되는 열을 지정한다. 이 열은 두 데이터프레임에 모두 존재해야 한다.
col1 열의 값이 같은 행끼리 합쳐진다.
pd.merge(df1, df2, on='col1')
col1 col2 col3
0 a 1 10
1 b 2 20
how 매개변수
합쳐질 방식을 지정한다. 기본값은 inner로 how 매개변수를 생략하면 기본적으로 두 데이터프레임의 값이 같은 행만 합친다.
left일 경우 첫 번째 데이터프레임을 기준으로 두 번째 데이터프레임을 합친다. df1의 행에 df2의 행을 맞추면 다음과 같다.
pd.merge(df1, df2, how='left', on='col1')
col1 col2 col3
0 a 1 10.0
1 b 2 20.0
2 c 3 NaN → df2 데이터프레임에 없는 값은 NaN으로 표시
right로 지정하면 두 번째 데이터프레임을 기준으로 첫 번째 데이터프레임을 합친다. df2의 행에 df1의 행을 맞추면 다음과 같다.
pd.merge(df1, df2, how='right', on='col1')
col1 col2 col3
0 a 1.0 10
1 b 2.0 20
2 c NaN 30
↓ df1 데이터프레임에 없는 값은 NaN으로 표시
outer로 지정하면 두 데이터프레임의 모든 행을 유지하면서 합친다.
col1의 값이 동일한 행은 합쳐지고 그렇지 않은 행은 별개의 행으로 추가되는 것을 알 수 있다.
pd.merge(df1, df2, how='outer', on='col1')
col1 col2 col3
0 a 1.0 10.0
1 b 2.0 20.0
2 c 3.0 NaN
3 d NaN 30.0
| ↔ | → 모든 행이 합쳐지고 값이 없는 행은 NaN으로 표시
left_on과 right_on 매개변수
합칠 기준이 되는 열의 이름이 서로 다를 경우 lefton과 right_on 매개변수에 각기 지정할 수 있다. 각각의 데이터프레임의 'col1' 열을 기준으로 합치고 싶다면 pd.merge(df1, df2, on='col1')와 결과가 동일하다.
pd.merge(df1, df2, left_on='col1', right_on='col1')
left_on='col1' → df1 데이터프레임의 'col1' 열
right_on='col1' → df2 데이터프레임의 'col1' 열
col1 col2 col3
0 a 1 10
1 b 2 20
↓ 값이 같은 행만 합친다._
left_index와 right_index 매개변수
합칠 기준이 열이 아니라 인덱스일 경우 left_index 또는 right_index 로 왼쪽 또는 오른쪽 인덱스를 지정할 수 있다. df1의 'col2'열과 df2의 인덱스를 기준으로 합치면 다음과 같다.
pd.merge(df1, df2, left_on='col2', right_index=True)
left_on='col2' → df1 데이터프레임의 'col2' 열
right_index=True → df2 데이터프레임의 인덱스
col1_x col2 col1_y col3
0 a 1 b 20
1 b 2 d 30
정리
- 웹 스크래핑은 웹사이트에서 필요한 데이터를 추출하는 기술이다. HTML은 구조적이지 않기 때문에 스크래핑으로 데이터를 수집하는데 비교적 많은 노력이 필요하다. 따라서 웹 스크래핑을 사용하기 전에 먼저 공개 API를 통해 사용할 수 있는지 살펴보는 것이 좋다.
- 뷰티플수프는 HTML 문서를 파싱하는데 사용하는 대표적인 파이썬 패키지이다. 사용법이 쉽고 빠르기 때문에 파이썬 프로그래머들이 즐겨 사용한다. 뷰티플수프는 requests 패키지로 가져온 HTML에서 원하는 태그나 텍스트를 찾는 기능을 제공한다.
핵심 함수와 메서드 정리
loc : 레이블(이름) 또는 불리언 배열로 데이터프레임의 행과 열을 선택한다. 정수로 지정함녀 인덱스의 레이블로 간주한다. 불리언 배열로 지정할 경우 배열의 길이는 행 또는 열의 전체 길이와 같아야 한다.
BeautifulSOupt.find() : 현재 태그 아래의 자식 태그 중에서 지정된 이름에 맞는 첫 번째 태그를 찾는다. 찾은 태그가 없을 경우 None이 반환된다.
BeautifulSOup.find_all() : 현재 태그 아래의 자식 태그 중에서 지정된 이름에 맞는 모든 태그를 찾는다. 뷰티풀 수프 객체를 함수처럼 호출할 경우 자동으로 find_all() 메서드가 호출된다. 찾은 태그가 없을 경우 빈 리스트가 반환된다.
BeautifulSoup.get_text() : 태그 안의 텍스트를 반환한다.
DaaFrame.apply() : 데이터프레임의 행 또는 열에 지정한 함수를 적용한다.
pandas.merge() : 데이터프레임이나 시리즈 객체를 합친다.
