패션 MNIST
텐서플로(TensorFlow) 사용해 패션 MNIST 불러오자. 코랩에서 텐서플로의 케라스(Keras) 패키지 임포트하면 다운로드 할 수 있다.
from tensorflow import keras
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
>>> Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz
29515/29515 [==============================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz
26421880/26421880 [==============================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz
5148/5148 [==============================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz
4422102/4422102 [==============================] - 0s 0us/stepkeras.datasets.fashion_mnist 모듈 아래 load_data() 함수는 친절하게 훈련 데이터와 테스트 데이터 나누어 반환한다. 이 데이터는 각각 입력과 타깃의 쌍으로 구성되어 있다.
# 전달 받은 데이터의 크기 확인
print(train_input.shape, train_target.shape)
>>> (60000, 28, 28) (60000,)
# 테스트 세트의 크기 확인
print(test_input.shape, test_target.shape)
>>> (10000, 28, 28) (10000,)# 몇 개의 샘플 그림으로 출력.
import matplotlib.pyplot as plt
fig, axs = plt.subplots(1, 10, figsize=(10,10))
for i in range(10):
axs[i].imshow(train_input[i], cmap='gray_r')
axs[i].axis('off')
plt.show()
크기 28x28이다 보니 꽤 작고 흐릿함. 6장에서 다루던 것처럼 반전된 흑백 이미지.
# 처음 10개 샘플의 타깃값 리스트로 만든 후 출력.
print([train_target[i] for i in range(10)])
>>> [9, 0, 0, 3, 0, 2, 7, 2, 5, 5]패션 MNIST의 타깃은 0-9까지의 숫자 레이블로 구성되어 있음. 각 숫자의 의미는 모르지만 마지막 2개의 샘플이 같은 레이블(숫자 5)를 가지고 있다. 이 2개의 샘플은 같은 종류의 신발 같음. 10개의 레이블은 다음과 같다.
0 : 티셔츠 / 1 : 바지 / 2 : 스웨터 / 3 : 드레스 / 4 : 코트 / 5 : 샌들 / 6 : 셔츠 / 7 : 스니커즈 / 8 : 가방 / 9 : 앵클 부츠
# 넘파이 unique() 함수로 레이블 당 샘플 개수 확인
import numpy as np
print(np.unique(train_target, return_counts=True))
>>> (array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8), array([6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000]))0-9까지 레이블마다 정확히 6,000개의 샘플 있다.
로지스틱 회귀로 패션 아이템 분류하기
훈련 샘플이 60,000개나 되기 때문에 전체 데이터를 한꺼번에 사용하여 모델 훈련하는 것보다 샘플 하나씩 꺼내서 모델 훈련하는 방법이 더 효율적. 이런 상황에 잘 맞는 방법이 확률적 경사 하강법.
4장 내용 다시 짚어보자! 4장에서 SGDClassifier를 사용할 때 표준화 전처리된 데이터를 사용. 그 이유로 확률적 경사 하강법은 여러 특성 중 기울기가 가장 가파른 방향을 따라 이동. 만약 트성마다 값의 범위가 많이 다르면 올바르게 손실 함수의 경사를 내려올 수 없다. 패션 MNIST 경우 각 픽셀은 0-255 사이의 정숫값을 가진다. 이런 이미지의 경우 보통 255로 나누어 0-1 사이의 값으로 정규화한다. 이건 표준화는 아니지만 양수 값으로 이루어진 이미지를 전처리할 때 많이 사용하는 방법!
# reshape() 메서드 사용해 2차원 배열인 각 샘플을 1차원 배열로 펼치기.
# SGDClassifier는 2차원 입력 다루지 못하기 때문에 각 샘플을 1차원 배열로 만들어야함.
train_scaled = train_input / 255.0
train_scaled = train_scaled.reshape(-1, 28*28)
# reshape() 메서드의 두 번째 매개변수를 28x28 크기에 맞게 지정하면 첫 번째 차원(샘플 개수)은 변하지 않고 원본 데이터의 두 번째, 세 번째 차원이 1차원으로 합쳐짐.
# 변환된 train_scaled의 크기 확인
print(train_scaled.shape)
>>> (60000, 784)# 4장처럼 SGDClassifier 클래스와 cross_validate 함수 사용해 데이터에서 교차 검증으로 성능 확인
from sklearn.model_selection import cross_validate
from sklearn.linear_model import SGDClassifier
sc = SGDClassifier(loss='log_loss', max_iter=5, random_state=42)
scores = cross_validate(sc, train_scaled, train_target, n_jobs=-1)
print(np.mean(scores['test_score']))
>>> 0.8196000000000001
# SGDClassifier의 반복 횟수(max_iter)를 5번으로 지정.
# max_iter = 9 일 때는 0.8303833333333334
# max_iter = 20일 때는 0.84369999999999994장에서 배웠던 로지스틱 회귀 공식 떠올려 보자!
z = a x (Weight) + b x (Length) + c x (Diagonal) + d x (Height) + e x (Width) + f
이 식을 패션 MNIST 데이터에 맞게 변형하면
z_티셔츠 = w1 x (픽셀1) + w2 x (픽셀2) + ... + w784 x (픽셀 784) + b
총 784개의 픽셀, 즉 특성이 있으므로 아주 긴 식이 만들어진다. 가중치 개수도 많아지기 때문에 a, b, c 대신 w1, w2, w3과 같은 식으로 바꾸었다. 마지막에 절편 b를 더한다.
두 번째 레이블인 바지에 대한 방정식은 어떻게 쓸까?
z바지 = w1' x (픽셀1) + w2' x (픽셀2) + ... + w784' x (픽셀784) + b'
이 식은 티셔츠에 대한 선형 방정식과 매우 비슷. 동일하게 784개의 픽셀값 그대로 사용. 다만 바지에 대한 출력을 계산하기 위해 가중치와 절편은 다른 값을 사용. 티셔츠와 같은 가중치를 사용한다면 바지와 티셔츠 구분 못 함!
이런 식으로 나머지 클래스에 대한 선형 방정식 모두 생각해 볼 수 있음. SGDClassifier 모델은 패션 MNIST 데이터의 클래스를 가능한 잘 구분할 수 있도록 10개의 방정식에 대한 모델 파라미터(가중치와 절편)을 찾는다.
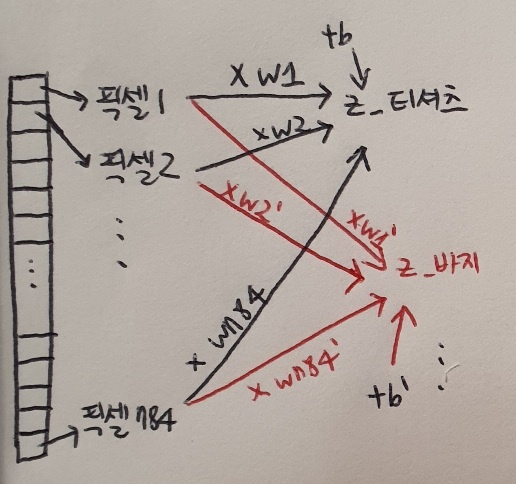
첫 번째 픽셀1이 w1과 곱해져서 z티셔츠에 더해진다. 두 번째 픽셀2도 w2와 곱해져서 z티셔츠에 더해진다. 마지막 픽셀784도 w784와 곱해져 z티셔츠에 더하고 절편 b를 더한다. z바지에 대해서도 동일한 계산 과정이 수행된다.
여기에서 중요한 점은 앞에서도 언급했듯이 티셔츠를 계산하기 위해 픽셀 784개와 곱하는 가중치 784개(w1-w784)와 절편(b)이 바지를 계산하기 위해 픽셀 784개와 곱하는 가중치 784개(w1'-w784'), 절편(b')과 다르다는 점이다.
z티셔츠, z바지와 같이 10개의 클래스에 대한 선형 방정식을 모두 계산한 다음에는 4장에서 보았듯이 소프트맥스 함수를 통과하여 각 클래스에 대한 확률 얻을 수 있다.
인공 신경망
가장 기본적인 인공 신경망은 확률적 경사 하강법을 사용하는 로지스틱 회귀와 같다. 그럼 어떻게 인공 신경망으로 성능을 높일 수 있을까? 그 전에 패션 아이템 분류 문제를 인공 신경망으로 표현해보자!
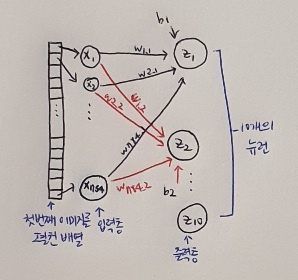
앞서 로지스틱 회귀를 표현한 그림과 매우 비슷하다. 여기에서는 z티셔츠, z바지를 z1, z2와 같이 아래 첨자를 사용하도록 바꾸었다. 클래스가 총 10개이므로 z10까지 계산. z1 - z10을 계산하고 이를 바탕으로 클래스를 예측하기 때문에 신경망의 최종 값을 만든다는 의미에서 출력증(output layer) 이라고 부른다.
인공 신경망에서는 z값을 계산하는 단위를 뉴런(neuron) 이라고 부른다. 하지만 뉴런에서 일어나는 일은 선형 계산이 전부! 뉴런보단 유닛(unit) 이라고 부르는 사람이 많아지고 있다!
그 다음 픽셀1, 픽셀2를 x1, x2와 같이 바꾸었다. 역시 아래첨자 사용해 784번째 픽셀에 해당하는 x784까지 나타내고 있다. 인공 신경망은 x1 - x784까지를 입력층(input layer)이라고 부른다. 즉 입력층은 픽셀값 자체이고 특별한 계산을 수행하지 않는다. 하지만 많은 사람이 입력층이라 부르기 때문에 여기에서도 관례를 따르겠다.
z1을 만들기 위해 픽셀1인 x1에 곱해지는 가중치는 w1.1이라고 쓰고 z2를 만들기 위해 픽셀1인 x1에 곱해지는 가중치는 w1.2라고 쓴다. 절편은 뉴런마다 하나씩이므로 순서대로 b1, b2와 같이 나타냈다.
1장에서 소개했듯이 인공 신경망은 1943년 워런 매컬러(Warren McCulloch)와 월터 피츠(Walter Pitts)가 제안한 뉴런 모델로 거슬러 올라간다. 이를 매컬러-피츠 뉴런이라고 부른다. 생물학적 뉴런은 수상 돌기로부터 신호를 받아 세포체에 모은다. 신호가 어떤 임곗값에 도달하면 축삭 돌기를 통해 신호를 전달한다.
하지만 생물학적 뉴런이 가중치(w1.1, w2.1)와 입력을 곱하여 출력을 만드는 것은 아니다. 4장에서 보았던 시그모이드 함수나 소프트맥스 함수를 사용하는 것은 더욱 아님. 인공 뉴런은 생물학적 뉴런의 모양을 본뜬 수학 모델에 불과함. 생물학적 뉴런이 하는 일을 실제로 구현한 것이 아니다!
인공 신경망은 정말 우리의 뇌에 있는 뉴런과 같지 않음. 인공 신경망이란 말을 많이 사용할 수 밖에 없지만 정말 뇌 속에 있는 무언가를 만드는 일이 아니라는 것을 꼭 기억! 인공 신경망은 기존의 머신러닝 알고리즘이 잘 해결하지 못했던 문제에서 높은 성능을 발휘하는 새로운 종류의 머신러닝 알고리즘일 뿐.
+ 딥러닝은 무엇인가요?
인공 신경망과 거의 동의어로 사용되는 경우가 많음. 혹은 심층 신경망(deep neural network, DNN)을 딥러닝이라고 부른다. 심층 신경망은 다음 절에서 보겠지만 여러 개의 층을 가진 인공 신경망이다.
인공 신경망 모델 만드는 최신 라이브러리들은 SGDClassifier에는 없는 몇 가지 기능을 제공하여 더 좋은 성능을 얻을 수 있다.
텐서플로와 케라스
텐서플로는 구글이 2015년 11월 오픈 소스로 공개한 딥러닝 라이브러리. 이때를 기점으로 딥러닝에 대한 개바자의 관심이 늘어났고, 2016년 3월 알파고가 이세돌 9단을 이겨 대중에 알려지면서 폭발적으로 인기가 높아졌다.
텐서플로는 그 후 많은 발전 거듭하면서 2019년 9월 2.0 버전이 릴리스 됐음.
import tensorflow as tf텐서플로에는 저수준 API와 고수준 API가 있다. 바로 케라스(keras)가 텐서플로의 고수준 API이다. 케라스는 2015년 3월 프랑소와 숄레(Francois Chollet)가 만든 딥러닝 라이브러리.
딥러닝 라이브러리가 다른 머신러닝 라이브러리와 다른 점 중 하나는 그래픽 처리 장치인 GPU를 사용하여 인공 신경망을 훈련한다는 것. GPU는 벡터와 행렬 연산에 매우 최적화되어 있기 때문에 곱셈과 덧셈이 많이 수행되는 인공 신경망에 큰 도움이 된다.
케라스 라이브러리는 직접 GPU 연산을 수행하지 않음. 대신 GPU 연산을 수행하는 다른 라이브러리를 백엔드(backend)로 사용한다. 예를 들면 텐서플로가 케라스의 백엔드 중 하나. 이 외에도 씨아노, CNTK와 같은 여러 디러닝 라이브러리를 케라스 백엔드로 사용할 수 있다. 이런 케라스를 멀티-백엔드 케라스라고 부른다. 케라스 API만 익히면 다양한 딥러닝 라이브러리를 입맛대로 골라 쓸 수 있다. 이를 위해 케라스는 직관적이고 사용하기 편한 고수준 API를 제공한다.
프랑소와가 구글에 합류한 뒤 텐서플로 라이브러리에 케라스 API가 내장되었다. 텐서플로 2.0부터는 케라스 API를 남기고 나머지 고수준 API를 모두 정리했고, 커라스는 텐서플로의 핵심 API가 되었다. 다양한 백엔드를 지원했던 멀티-백엔드 케라스는 2.3.1 버전 이후로 더 이상 개발되지 않는다. 케라스와 텐서플로가 거의 동의어가 된 셈!
# 텐서플로에서 케라스를 사용하려면 다음과 같이 임포트 해야함.
from tensorflow import keras
# 케라스 API를 사용해 패션 아이템을 분류하는 가장 간단한 인공 신경망 만들어 보자!인공 신경망으로 모델 만들기
앞서 로지스틱 회귀에서 만든 훈련 데이터 train_scaled와 train_target 사용. 로지스틱 회귀에서는 교차 검증 사용해 모델 평가했지만, 인공 신경망에서는 교차 검증을 잘 사용하지 않고 검증 세트를 별도로 덜어내서 사용.
이렇게 하는 이유는 ① 딥러닝 분야의 데이터셋은 충분히 크기 때문에 검증 점수가 안정적이고, ② 교차 검증을 수행하기에는 훈련 시간이 너무 오래 걸리기 때문. 어떤 딥러닝 모델은 훈련하는데 몇 시간, 심지어 며칠이 걸릴 수도 있다. 패션 MNIST 데이터셋이 그만큼 크지는 않지만, 관례 따라 검증 세트 나누어 보자. 사이킷런의 train_test_split() 함수 사용하자.
from sklearn.model_selection import train_test_split
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42)
# 사실 패션 MNIST 데이터는 이미 잘 섞인 데이터라 train_test_split() 함수 사용하지 않고 앞이나 뒤에서 10,000개 정도의 샘플 덜어서 검증 세트로 만들어도 됨!
# 훈련 세트에서 20%를 검증 세트도 덜어냄.
# 훈련 세트와 검증 세트의 크기 알아보기.
print(train_scaled.shape, train_target.shape)
>>> (48000, 784) (48000,)
print(val_scaled.shape, val_target.shape)
>>> (12000, 784) (12000,)60,000개 중에 12,000개 가 검증 세트로 분리됨. 먼저 훈련 세트(train_scaled, train_target)로 모델 만듦. 그 다음 검증 세트(val_scaled, val_target)로 훈련한 모델 평가.
먼저 인공 신경망 그림의 오른쪽에 놓인 층을 만들어 보자. 이 층은 [그림 1]처럼 10개의 패션 아이템을 분류하기 위해 10개의 뉴런으로 구성된다.
케라스의 레이어(keras.layers) 패키지 안에는 다양한 층 준비되어 있음. 가장 기본이 되는 층은 밀집층(dense layer) 이다. 왜 밀집이라 부르라면 [그림 2]에서 왼쪽에 있는 784개의 픽셀과 오른쪽에 있는 10개의 뉴런이 모두 연결된 선을 생각해보자. 그러면 784 x 10 = 7,840개의 연결된 선이 있다. 그래서 밀집층이다!
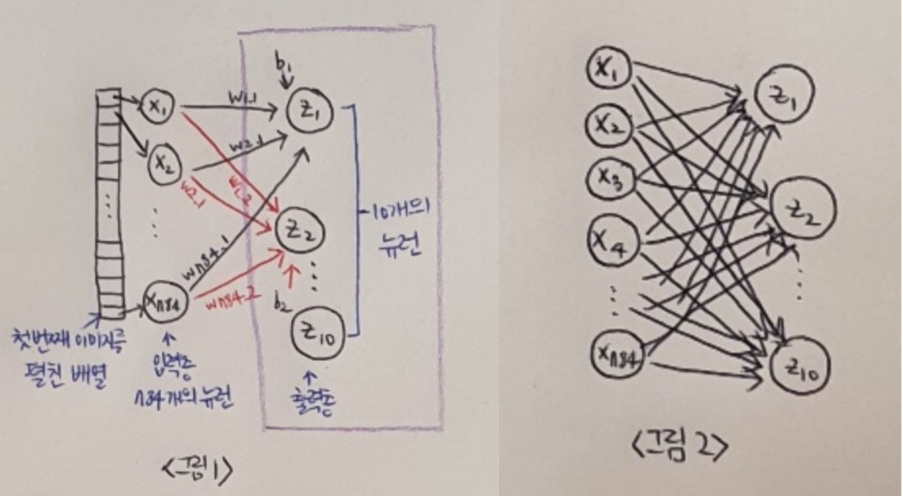
이런 층을 양쪽의 뉴런이 모두 연결하고 있기 때문에 완전 연결층(fully conneced layer) 이라고도 부른다. 그럼 케라스의 Dense 클래스를 사용해 밀집층 만들어보자.
# 필요한 매개변수는 뉴런 개수, 뉴런의 출력에 적용할 함수, 입력의 크기
dense = keras.layers.Dense(10, activation='softmax', input_shape=(784,))첫 번째 매개변수로 뉴런 개수를 10개로 지정한다. 10개의 패션 아이템을 분류하기 때문! 10개의 뉴런에서 출력되는 값을 확률로 바꾸기 위해서 소프트맥스 함수 사용한다. 케라스 층에서는 activation 매개변수에 이 함수를 지정한다. 만약 2개의 클래스를 분류하는 이진 분류라면 시그모이드 ㅏㅁ수를 사용하기 위해 activation='sigmoid'와 같이 설정한다. 마지막으로 세 번째 매개변수는 입력값의 크기이다. 10개의 뉴런이 각각 몇 깨의 입력을 받는지 튜플로 지정한다. 여기에서는 784개의 픽셀 값을 받는다.
# 밀집층 가진 신경망 모델 만들어야한다.
# 케라스의 Sequential 클래스 사용
model = keras.Sequential(dense)Sequential 클래스의 객체 만들 때 앞에서 만든 밀집층의 객체 dense 전달함. 여기서 만든 model 객체가 바로 신경망 모델이다. 다음 그림에 지금까지 만든 신경망을 나타냈다. 마지막에 소프트맥스 함수도 적용함!
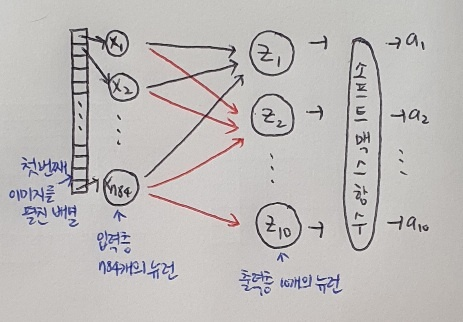
이 그림에서 복잡하지 않도록 입력층과 출력층 사이에 연결선만 나타내고 가중치는 표시 X. 절편의 경우는 아예 선도 그리지 않는 경우가 많다! 하지만 절편이 뉴런마다 더해진다는 것을 꼭 기억하자. 소프트맥스와 같이 뉴런의 선행 방정식 계산 결과에 적용되는 함수를 활성화 함수(activation function) 라고 부른다. 이 책에서는 이 값을 a로 표시하겠다!
+ 소프트맥스 함수는 별도의 층인가요?
시그모이드 함수나 소프트맥스와 같은 활성화 함수는 뉴런의 출력에 바로 적용되기 때문에 보통 층의 일부로 나타낸다. 하지만 종종 "소프트맥스 층을 적용했어"와 같이 따로 부르는 경우도 있다. 가중치와 절편으로 선형 계산을 수행하는 층을 좁은 개념의 신경망 층으로 생각한다면 소프트맥스 층은 넓은 의미의 층이라 볼 수 있다. 케라스 API에서도 층의 개념을 폭넓게 적용하고 있다.
인공 신경망으로 패션 아이템 분류하기
케라스 모델은 훈련하기 전에 설정 단계가 있다. 이런 설정을 model 객체의 complite() 메서드에서 수행한다. 꼭 지정해야 할 것은 손실 함수의 종류이다. 그 다음 훈련 과정에서 계산하고 싶은 측정값을 지정한다.
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')- 이진 분류 : loss='binary_crossentropy'
- 다중 분류 : loss='categorical_crossentropy'
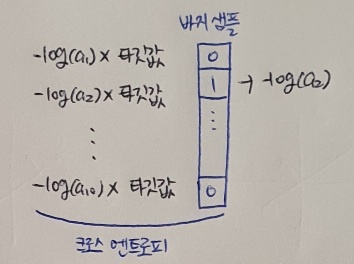
이름으로 이진 분류와 다중 분류의 손실 함수가 명확히 구분된다. 그런데 sparse란 단어는 왜 앞에 붙였을까? 이를 설명하기 위해 다시 4장의 내용 기억해보자! 이진 크로스 엔트로피 손실을 위해 -log(예측 확률)에 타깃값(정답)을 곱했다. 이를 그려보면 다음과 같다.
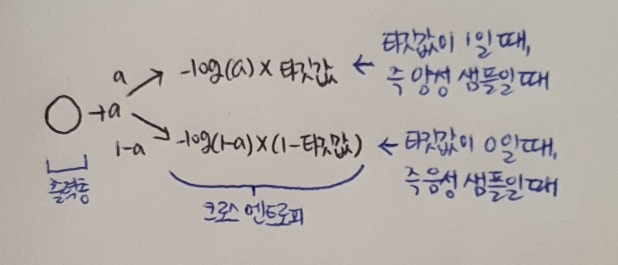
이진 분류에서는 출력층의 뉴런이 하나. 이 뉴런이 출력하는 확률값 a(시그모이드 함수의 출력값)를 사용해 양성 클래스와 음성 클래스에 대한 크로스 엔트로피를 계산한다. 이 계산은 4장의 로지스틱 손실 함수와 동일.
이진 분류의 출력 뉴런은 오직 양성 클래스에 대한 확률(a)만 출력하기 때문에 음성 클래스에 대한 확률은 간단히 1-a로 구할 수 있다. 역시 이진 분류의 타깃값은 양성 샘플일 경우에는1, 음성 샘플일 경우에는 0으로 되어 있다. 0을 곱하면 어떤 계산이든지 모두 0이 되기 때문에 특별히 음성 샘플일 경우 1로 바꾸어 (1-타깃값) 계산한다. 이렇게 하면 하나의 뉴런만으로 양성과 음성 클래스에 대한 크로스 엔트로피 손실을 모두 계산할 수 있다!
그럼 패션 MNIST 데이터셋과 같이 다중 분류일 경우는 어떻게 계산할까?? 그림으로 먼저 살펴보자.
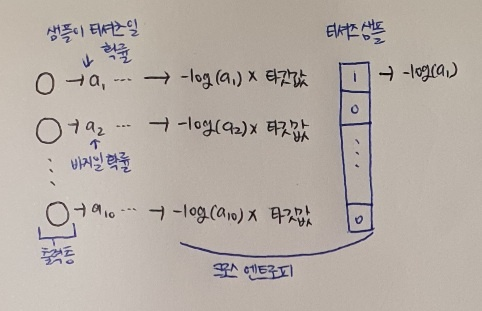
출력층은 10개의 뉴런이 있고 10개의 클래스에 대한 확률을 출력한다. 첫 번째 뉴런은 티셔츠일 확률이고 두 번째 뉴런은 바지일 확률을 출력한다. 이진 분류와 달리 각 클래스에 대한 확률이 모두 출력되기 때문에 타깃에 해당하는 확률만 남겨놓기 위해서 나머지 확률에는 모두 0을 곱한다.
예를 들어 샘플이 티셔츠일 경우 첫 번째 뉴런의 활성화 함수 출력인 a1에 크로스 엔트로피 손실 함수를 적용하고 나머지 활성화 함수 출력 a2 - a10까지는 모두 0으로 만든다. 이렇게 하기 위해 티셔츠 샘플의 타깃값은 첫 번째 원소만 1이고 나머지는 모두 0인 배열로 만들 수 있다. → [1,0,0,0,0,0,0,0,0,0] 이 배열과 출력층의 활성화 값의 배열과 곱하면 된다!
[a1,a2,a3,a4,a5,a6,a7,a8,a9,a10] x [1,0,0,0,0,0,0,0,0,0]
길이가 같은 넘파이 배열의 곱셈은 원소별 곱셉으로 수행된다. 즉, 배열에서 동일한 위치의 원소끼리 곱셈이 된다. 결국 다른 원소는 모두 0이 되고 a1만 남는다. 이 과정이 앞의 그림에 자세히 표현되어 있다
결국 신경망은 티셔츠 ㅎ샘플에서 손실을 낮추려면 첫 번째 뉴런의 활성화 출력 a1의 값을 가능한 1에 가깝게 만들어야 한다. 바로 이것이 크로스 엔트로피 손실 함수가 신경망에 원하는 바!
예를 들어 샘플이 바지일 경우 다음과 같다.
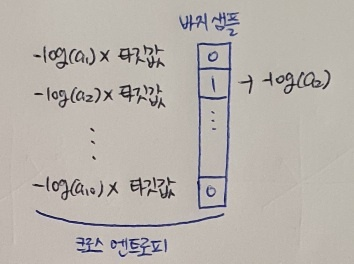
두 번째 뉴런의 활성화 출력인 a2만 남기려면 두 번째 원소만 1이고 나머지는 모두 0으로 타깃값을 준비하면 된다. 바지 샘플을 정확하게 분류하려면 신경망이 a2의 출력을 가능한 한 높여야 한다. 이와 같이 티깃값을 해당 클래스만 1이고 나머지는 모두 0인 배열로 만드는 것을 원-핫 인코딩(one-hot encoding) 이라 부른다.
따라서 다중 분류에서 크로스 엔트로피 손실 함수를 사용하려면 0, 1, 2와 같이 정수로 된 타깃값을 원-핫 인코딩으로 변환해야한다.
print(train_target[:10])
>>> [7 3 5 8 6 9 3 3 9 9]그런데 패션 MNIST 데이터의 타깃값은 모두 정수로 되어 있다. 하지만 텐서플로에서는 정수로 된 타깃값을 원-핫 인코딩으로 바꾸지 않고 그냥 사용할 수 있다. 정수로된 타깃값을 사용해 크로스 엔트로피 손실을 계산하는 것이 바로 'sparse_categorical_crossentropy'이다. 빽빽한 배열 말고 정숫값 하나만 사용한다는 뜻에서 sparse(최소)라는 이름을 붙인 것 같다. 타깃값을 원-핫 인코딩으로 준비했다면 compile() 메서드에 손실 함수를 loss='categorical_crossentropy'로 지정한다.
이제 compile() 메서드의 두 번째 매개변수인 metrics에 대해 알아보자. 케라스는 모델이 훈련할 때 기본으로 에포크마다 손실 값을 출력해준다. 손실이 줄어드는 것을 보고 훈련이 잘 되었다는 것을 알 수 있지만 정확도를 함께 출력하면 더 좋다! 이를 위해 metrics 매개변수에 정확도 지표를 의미하는 'accuracy'를 지정한다.
훈련하는 fit() 메서드는 사이킷런과 매우 비슷하다. 처음 두 메개변수에 입력(train_scaled)과 타깃(train_target)을 지정한다. 그 다음 반복할 에포크 횟수를 epochs 매개변수로 지정한다. 사이킷런의 로지스틱 모델과 동일하게 5번 반복해보자.
model.fit(train_scaled, train_target, epochs=5)
>>> Epoch 1/5
1500/1500 [==============================] - 8s 2ms/step - loss: 0.6128 - accuracy: 0.7925
Epoch 2/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.4752 - accuracy: 0.8379
Epoch 3/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.4509 - accuracy: 0.8475
Epoch 4/5
1500/1500 [==============================] - 4s 3ms/step - loss: 0.4377 - accuracy: 0.8519
Epoch 5/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.4290 - accuracy: 0.8547
<keras.callbacks.History at 0x7d25d615bc10>케라스는 친절하게 에포크마다 걸린 시간과 손실(loss), 정확도(accuracy)를 출력해준다. 5번 반복에 정확도가 85%가 넘었다. 앞서 따로 떼어 놓은 검증 세트(val_scaled, val_target)에서 모델의 성능 확인해보자. 케라스에서 모델의 성능을 평가하는 메서드는 evaluate() 메서드이다.
model.evaluate(val_scaled, val_target)
>>> 375/375 [==============================] - 1s 2ms/step - loss: 0.4523 - accuracy: 0.8474
[0.4522610008716583, 0.8474166393280029]evaluate() 메서드로 fit() 메서드와 비슷한 출력을 보여준다. 검증 세트의 점수는 훈련 세트 점수보다 조금 낮은 것이 일반적이다. 예상대로 평가 결과는 훈련 세트의 점수보다 조금 낮은 84% 정도의 정확도를 냈다.
인공 신경망 모델로 성능 향상
이 절에서는 28 x 28 크기의 흑백 이미지로 저장된 패션 아이템 데이터셋인 패션 MNIST 데이터셋을 사용했다. 먼저 로지스틱 손실 함수를 사용한 SGDClassifier 모델을 만들어 교차 검증 점수를 확인했다.
그 다음 가장 인기 있는 딥러닝 라이브러리인 텐서플로와 케라스 API를 소개하고 케라스를 사용해 간단한 인공 신경망 모델을 만들어 패션 아이템을 분류했다. 이 간단한 인공 신경망은 사실상 앞에서 만든 경사 하강법을 사용한 로지스틱 회쉬 모델과 거의 비슷하다. 하지만 몇 가지 장점 덕분에 조금 더 높은 성능을 낸다.
인공 신경망 모델을 만들면서 이전 장에서 배웠던 로지스틱 손실 함수와 크로스 엔트로피 손실 함수를 다시 되새겨 보자. 그리고 신경망에서 이런 손실 함수를 어떻게 계산하는지 그림을 통해 배웠다. 이 과정에서 원-핫 인코딩을 배웠고 케라스 API에 대해 조금 더 자세히 알 수 있었다.
다음 그림에서 사이킷런의 SGDClassifier와 케라스의 Sequential 크래스 사용법의 차이를 정리해보자!

전체 코드 (출처 : https://bit.ly/hg-07-1)
from tensorflow import keras
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
print(train_input.shape, train_target.shape)
print(test_input.shape, test_target.shape)
import matplotlib.pyplot as plt
fig, axs = plt.subplots(1, 10, figsize=(10,10))
for i in range(10):
axs[i].imshow(train_input[i], cmap='gray_r')
axs[i].axis('off')
plt.show()
print([train_target[i] for i in range(10)])
import numpy as np
print(np.unique(train_target, return_counts=True))
train_scaled = train_input / 255.0
train_scaled = train_scaled.reshape(-1, 28*28)
print(train_scaled.shape)
from sklearn.model_selection import cross_validate
from sklearn.linear_model import SGDClassifier
sc = SGDClassifier(loss='log_loss', max_iter=5, random_state=42)
scores = cross_validate(sc, train_scaled, train_target, n_jobs=-1)
print(np.mean(scores['test_score']))
import tensorflow as tf
from tensorflow import keras
from sklearn.model_selection import train_test_split
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42)
print(train_scaled.shape, train_target.shape)
print(val_scaled.shape, val_target.shape)
dense = keras.layers.Dense(10, activation='softmax', input_shape=(784,))
model = keras.Sequential(dense)
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
print(train_target[:10])
model.fit(train_scaled, train_target, epochs=5)
model.evaluate(val_scaled, val_target)정리
- 인공 신경망은 생물학적 뉴런에서 영감을 받아 만든 머신러닝 알고리즘이다. 이름이 신경망이지만 실제 우리 뇌를 모델링한 것은 아니다. 신경만은 기존의 머신러닝 알고리즘으로 다루기 어려웠던 이미지, 음성, 텍스트 분야에서 뛰어난 성능을 발휘하면서 크게 주목받고 있다. 인공 신경망 알고리즘을 종종 딥러닝이라고도 부른다.
- 텐스플로는 구글이 만든 딥러닝 라이브러리로 매우 인기가 높다. CPU와 GPU를 사용해 인공 신경망 모델을 효율적으로 훈련하며 모델 구축과 서비스에 필요한 다양한 도구를 제공한다. 텐서플로 2.0부터는 신경망 모델을 빠르게 구성할 수 있는 케라스를 핵심 API로 채택한다. 케라스를 사용하면 간단한 모델에서 아주 복잡한 모델까지 손쉽게 만들 수 있다.
- 밀집층은 가장 간단한 인공 신경망의 층. 인공 신경망에는 여러 종류의 층이 있다. 밀집층에서는 뉴런들이 모두 연결되어 있기 때문에 완전 연결 층이라고도 부른다. 특별히 출력층에 밀집층을 사용할 때는 분류하려는 클래스와 동일한 개수의 뉴런을 사용한다.
- 원-핫 인코딩은 정슛값을 배열에서 해당 정수 위치의 원소만 1이고 나머지는 모두 0으로 변환한다. 이런 변환이 필요한 이유는 다중 분류에서 출력층에서 만든 확률과 크로스 엔트로피 손실을 계산하기 위해서이다. 텐서플로에서 'spare_categorical_emtropy' 손실을 지정하면 이런 변환을 수행할 필요 없다.
핵심 패키지와 함수
TensorFlow
- Dense : 신경망에서 가장 기본 층인 밀집층 만드는 클래스.
이 층에 첫 번째 매개변수에는 뉴런의 개수를 지정함.
activation 매개변수에는 사용할 활성화 함수를 지정. 대표적으로 'sigmoid', 'softmax' 함수가 있다. 아무것도 지정하지 않으면 활성화 함수 사용 X.
케라스의 Sequential 클래스에 맨 처음 추가되는 층에는 input_shape 매개변수로 입력의 크기 지정해야 한다. - Sequential : 케라스에서 신경망 모델을 만드는 클래스.
이 클래스의 객체를 생성할 때 신경망 모델에 추가할 층을 지정할 수 있다. 추가할 층이 1개 이상일 경우 파이썬 리스트로 전달. - compile() : 모델 객체를 만든 후 훈련하기 전에 사용할 손실 함수와 측정 지표 등을 지정하는 메서드이다.
loss 매개변수에 손실 함수를 지정. 이진 분류일 경우 'binary_crossentropy', 다중 분류일 경우 'categorical_crossentropy'를 지정한다. 클래스 레이븍ㄹ이 정수일 경우 'sparse_categorical_crossentropy'로 지정한다. 회귀 모델일 경우 'mean_square_error' 등으로 지정할 수 있다.
metrics 매개변수에 훈련 과정에서 측정하고 싶은 지표를 지정할 수 있다. 측정 지표가 1개 이상일 경우 리스트로 전달. - fit() : 모델을 훈련하는 메서드.
첫 번째와 두 번째 매개변수에 입력과 타깃 데이터를 전달한다.
epochs 매개변수에 전체 데이터에 대해 반복할 에포크 횟수를 지정한다. - evaluate() : 모델 성능을 평가하는 메서드.
첫 번째와 두 번째 매개변수에 입력과 타깃 데이터를 전달.
compile() 메서드에서 loss 매개변수에 지정한 손실 함수의 값과 metrics 매개변수에서 지정한 측정 지표를 출력함.
