논문 리뷰 : BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer
논문 리뷰
논문 링크 : BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer
❖ 논문 선정 이유
저번 프로젝트 리뷰에서 진행한 LLM을 활용한 일본여행 추천챗봇에서 사용자의 영화 추천 단계를 맡은 모델인 BERT4Rec을 제대로 이해하기 위하여 논문 리뷰를 진행함
❖ 0. Abstract
기존 추천 시스템 연구
- 왼쪽에서 오른쪽으로만 읽는 순차 신경망(unidirectional) 을 활용하여 사용자의 과거 상호작용을 은닉 표현(hidden representation)으로 인코딩해 추천을 수행
기존 접근의 두 가지 한계와 해결방안
- 단방향 구조는 시퀀스 내 표현력을 제한함
- 실제 데이터는 엄격한 순서를 따르지 않는데, 기존 모델은 이를 가정함
- 이를 해결하기 위해 BERT4Rec 모델을 제안함
- 이 모델은 양방향 self-attention 을 활용하여 사용자 행동 시퀀스를 표현하며, 정보 누수를 방지하고 효율적인 학습을 위해 Cloze objective(마스킹 예측) 을 도입함
❖ 1. Introduction
문제 배경
- 추천 시스템에서 핵심은 사용자의 동적이고 변화하는 관심사를 잘 포착하는 것임
- 실제로 사용자의 관심사는 과거 행동에 의해 영향을 받고, 시퀀스적 패턴을 가짐
- 예: 닌텐도 스위치를 구매한 후 곧바로 조이콘 같은 액세서리를 사는 경우
기존 접근
- 기존 시퀀스 추천(sequential recommendation) 모델들은 주로 왼쪽→오른쪽(unidirectional) 방식으로 사용자의 과거 아이템을 인코딩하고 이를 기반으로 다음 아이템을 예측함
- RNN, GRU 같은 순환 신경망이 대표적임
한계
- 단방향 모델은 이전 아이템 정보만 사용하기 때문에 표현력이 제한됨
- 기존 모델은 텍스트·시계열처럼 엄격한 순서를 가정하는데 실제 사용자 행동은 외부 요인으로 인해 반드시 순차적이지 않음
제안 아이디어
- 이를 해결하기 위해, BERT의 성공에서 영감을 받아 양방향 self-attention 기반 모델(BERT4Rec) 을 도입함
- 각 아이템이 좌·우 문맥을 모두 활용하여 표현을 학습
- 하지만 단순히 양방향으로 학습하면 정보 누수 문제가 생김 → 목표 아이템을 미리 보는 효과 발생
해결 방법: Cloze objective
- 입력 시퀀스의 일부 아이템을 무작위로 [mask] 처리하고 마스크된 아이템을 주변 좌·우 문맥으로 예측하게 학습함
- 이를 통해 양방향 맥락을 활용하면서도 정보 누수를 막고 학습 시 더 많은 샘플을 생성해 강력한 모델을 만들 수 있음
- 단, 학습 목표(Cloze)와 실제 추천(next-item prediction) 간에 약간의 불일치 존재 → 테스트 시에는 시퀀스 끝에 [mask]를 추가해 다음 아이템을 예측하도록 함
❖ 2. Related Work
◆ 2.1 General Recommendation
초기 추천 시스템
-
초기에는 전통적으로는 협업 필터링(Collaborative Filtering, CF) 이 주로 사용되었는데 그중에서도 행렬 분해(Matrix Factorization, MF) 가 가장 널리 쓰였음
-
사용자와 아이템을 같은 잠재 벡터 공간에 투영하고 두 벡터의 내적으로 선호도를 추정함
-
또 다른 접근으로는 item-based neighborhood methods 가 있으며 이는 아이템-아이템 유사도 행렬을 미리 계산하고 사용자가 과거에 소비한 아이템과의 유사도를 기반으로 새로운 아이템의 선호도를 예측함
딥러닝의 도입
-
넷플릭스 프라이즈(Netflix Prize)에서 Restricted Boltzmann Machine(RBM) 기반 협업 필터링이 등장하면서 주목받음
-
이후 딥러닝 기반 방법은 크게 두 가지로 발전:
- 보조 정보 활용: 텍스트, 이미지, 음성 등의 특성을 학습해 아이템 임베딩을 만들고 이를 CF 모델과 결합해 성능을 개선함
- 기존 MF 대체:
Neural Collaborative Filtering (NCF) → 내적 대신 MLP를 사용하여 사용자-아이템 상호작용을 모델링
AutoRec, CDAE → 오토인코더 구조를 이용해 사용자 평점을 직접 예측함
◆ 2.2 Sequential Recommendation
한계
- 기존 CF 기반 모델들은 순서를 무시하기 때문에 시퀀스 추천(sequential recommendation)에 적합하지 않음
초기 접근: 마코프 체인(MC)
- 사용자 행동의 순차적 패턴을 마코프 체인으로 모델링
- Shani et al.: 추천을 순차 최적화 문제로 정의, MDP 활용
- Rendle et al.: FPMC (Factorizing Personalized Markov Chains) → MC + MF 결합해 순차 행동 + 일반적 선호를 함께 모델링
딥러닝 기반 접근: RNN 계열
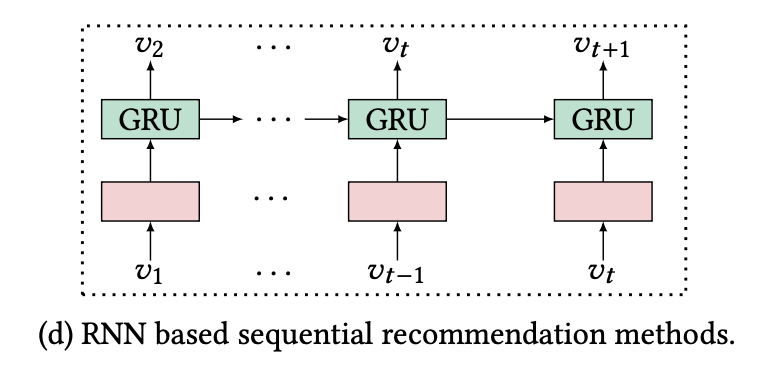
- 최근에는 RNN, GRU, LSTM이 널리 사용되었음
- 아이디어: 과거 상호작용 시퀀스를 벡터로 인코딩해 다음 행동을 예측
- 주요 모델:
- GRU4Rec: 세션 기반 GRU + ranking loss
- DREAM: Dynamic Recurrent Basket Model
- User-based GRU: 사용자 레벨 모델링
- NARM: Attention 기반 GRU
- Improved GRU4Rec: 새로운 loss (BPR-max, TOP1-max) + 개선된 샘플링 전략
- 주요 모델:
◆ 2.3 Attention Mechanism
Attention의 등장
- 원래는 기계 번역, 텍스트 분류 등 시퀀스 데이터 모델링에서 큰 성과를 보였는데 추천 시스템에서도 성능 향상 + 해석 가능성을 위해 attention이 도입됨
- 예: Li et al. → GRU에 attention을 결합해 세션 기반 추천에서 사용자의 순차적 행동 + 주요 목적을 함께 반영함
Transformer / BERT의 차별점
- 기존 연구는 attention을 단순히 보조 모듈로 활용했지만 Transformer와 BERT는 multi-head self-attention만으로 구성된 순수 attention 모델임
- 이 구조는 텍스트 시퀀스 모델링에서 SOTA 성능을 달성했고 효율성·효과성 모두 뛰어남
순차 추천 적용
-
Kang & McAuley (SASRec): 2-layer Transformer decoder 기반 모델 → 사용자 행동 시퀀스를 모델링, 공개 데이터셋에서 SOTA 기록함
- 단점: SASRec은 단방향(causal mask) 만 사용 → 과거 정보만 반영
-
BERT4Rec: 양방향 self-attention + Cloze task 를 활용해 시퀀스를 인코딩, 보다 풍부한 표현을 학습.
❖ 3. BERT4REC
◆ 3.1 Problem Statement
목표
- 사용자의 과거 상요작용 시퀀스 를 기반으로 다음 시점에 어떤 아이템을 선택할지 예측
정의
- 사용자 집합 :
- 아이템 집합 :
- 사용자 의 상호작용 시퀀스 :
- 여기서 는 사용자가 시점 에 선택한 아이템
- 문제 공식화:
- 주어진 시퀀스 를 바탕으로 다음 아이템
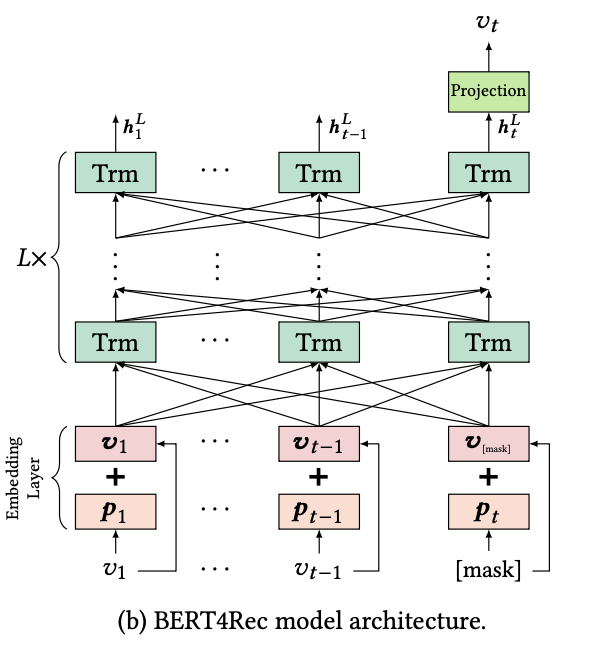
◆ 3.2 Model Architecture
모델 개요
- BERT4Rec은 Bidirectional Transformer Encoder 구조를 기반으로 시퀀스 추천을 수행함
핵심은 self-attention layer(Transformer layer)를 쌓아 올린 구조임
작동 방식
- 각 층에서 시퀀스 내 모든 위치가 서로 정보를 교환하여 표현을 갱신함
- RNN처럼 순차적으로 정보를 전달하는 대신 병렬적 처리가 가능함
Self-attention 장점
- 장거리 의존성 직접 캡처 가능 → 전역적 receptive field
- CNN 기반의 제한된 receptive field 문제 극복 병렬화 용이 → 학습 효율성 증가
비교
- RNN/SASRec → 모두 단방향(left-to-right) 구조
- BERT4Rec → 양방향 self-attention 사용더 강력한 사용자 시퀀스 표현 학습
- 결과적으로 더 정확한 추천 성능 달성 가능
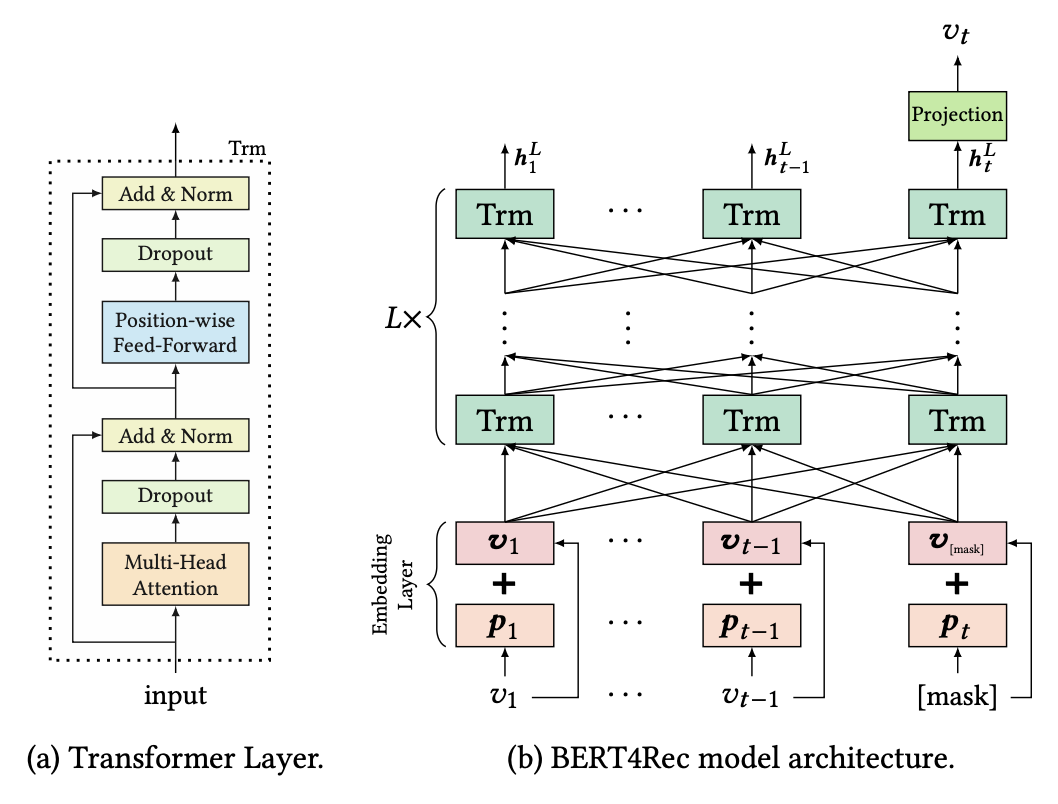
◆ 3.3 Transformer Layer
Transformer Layer 구조
- 입력 시퀀스 길이 에 대해 각 위치의 hidden representation을 동시에 계산함
- Transformer Layer
- Multi-Head Self-Attention(MHSA)
- Position-wise Feed-Forward Network(FFN)
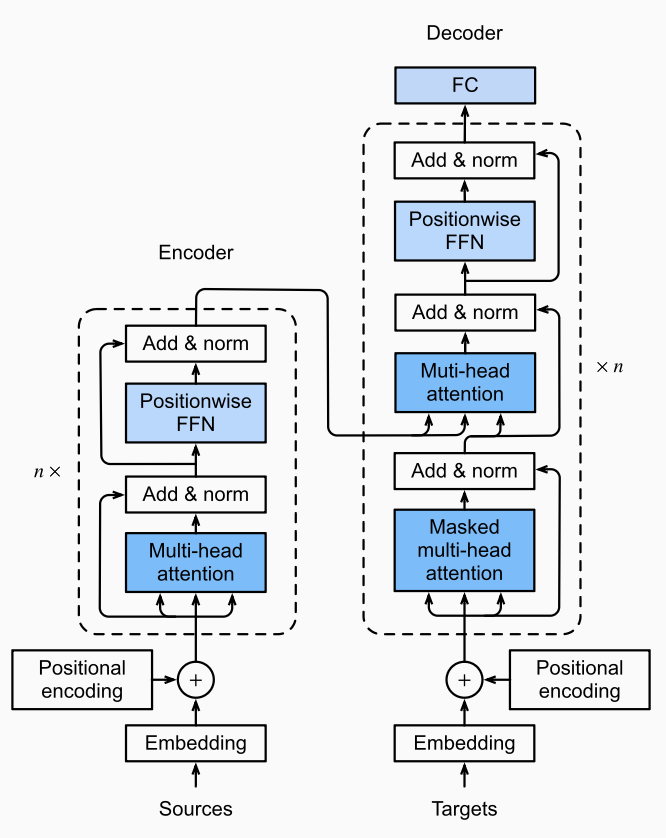
Multi-head Self Attention
- 시퀀스 내 모든 위치 간 의존성을 거리와 상관없이 학습 가능함
- 하나의 attention이 아니라 여러개의 head를 병렬로 적용하여 다양한 representation subspace를 학습함
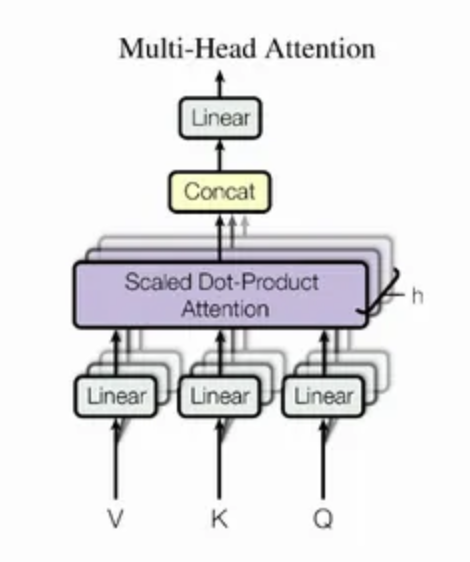
계산과정
- 입력 을 로 각각 선형 변환:
- 여러 head를 concat 후 최종 선형 변환:
- Attention 함수는 Scaled Dot-Product Attention:
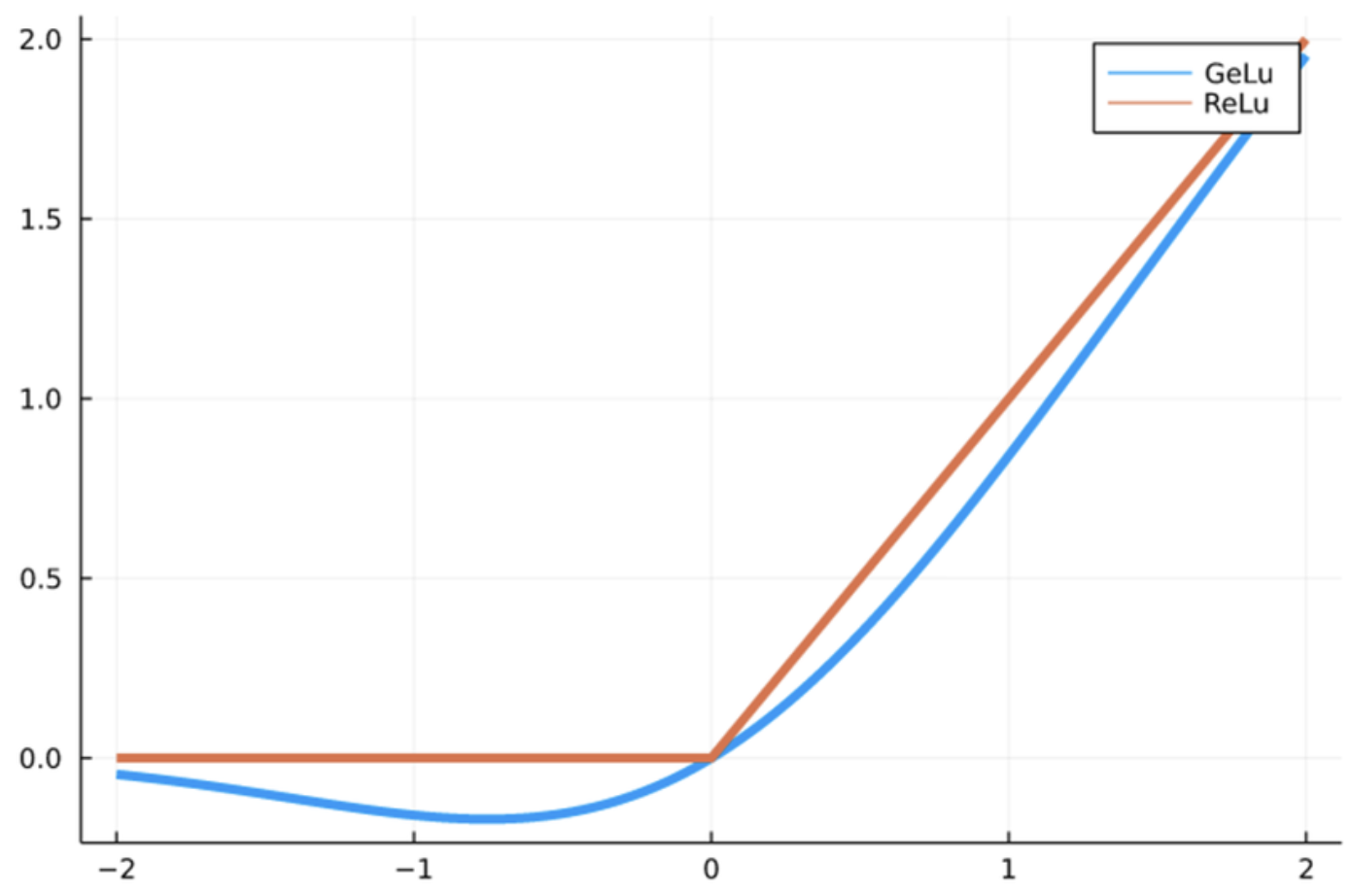
Position-wise Feed-Forward Network(FFN)
- 각 position마다 동일하게 적용되는 두개의 fully connected layer
- 비선형성을 주기 위해 GELU 활성화 함수 사용 (ReLU 보다 부드러움)
Stacking Transformer Layers
- 여러층을 쌓으면 더 복잡한 item 간 상호작용 학습 가능함
- 문제는 깊어질수록 학습이 어려움 → 해결책
- Residual Connection
- Layer Normalization
- Dropout
- 최종적으로 한 층의 출력은
정리
BERT4Rec의 Transformer Layer는
- MHSA로 시퀀스 내 item-item 관계 학습
- FFN으로 비선형적 변환 적용
- Residual + LN + Dropout으로 안정적인 학습 보장
이 과정들을 여러층 쌓아 더 복잡한 패턴 학습함
◆ 3.4 Embedding Layer
- Transformer는 입력 순서 정보가 없기 때문에 Positional Embedding 필요함
- 입력 아이템 임베딩 와 위치 임베딩 를 더해서 초기 hidden representation 생성함
- 이때 위치 임베딩은 고정된 함수 대신, 학습 가능한 임베딩을 사용하여 성능을 향상시킴
- 최대 sequence rlfdl 제한이 있어서 이면 마지막 개 아이템만 사용함
◆ 3.5 Output Layer
-
L개의 Transformer Layer를 통과한 후 최종 hidden states H^L을 얻음
-
마스크된 아이템 를 예측하기 위해 h_t^L을 활용함
-
구조: 2-layer feed-forward network + GELU + softmax
- : 아이템 임베딩 매트릭스 (입력/출력 공유)
- : 학습 가능한 파라미터
-
입력과 출력에서 동일한 임베딩 공유하여 모델 크기를 감소시키고 과적합을 완화시킴
◆ 3.6 Model Learning
Training
기존방식
- 일반적인 순차 추천 모델은 다음 아이템 예측을 목표로 학습함
- 입력 의 타겟은 형태임
- 하지만 BERT4Rex은 양방향 모델임 → 양쪽 문맥을 모두 보기 때문에 target 정보가 포함되어 trivial 문제 발생함 (학습이 무의미해짐)
해결법
- Cloze Task(Masked Language Model) 도입
- 입력 시퀀스의 일부 아이템을 확률적으로 마스킹하고 해당 아이템을 예측하도록 학습함
- 예시 :
- Input :
- Masked :
- Label :
Loss Function
- 마스크된 위치의 hidden vector를 softmax로 분류함
- Loss = 마스크된 아이템의 negative log-likelihood
Test
- 학습 시에는 마스크된 아이템을 예측하지만, 실제 추천에서는 미래 아이템 예측이 필요함
- 이를 맞추기 위해, 테스트 시 마지막 위치를 로 대체하고 다음 아이템을 예측함
- 학습 시에도 일부 샘플은 마지막 아이템만 마스크 처리 → 실제 태스크와 일치하도록 조정함
- 결과적으로 fine-tuning 효과를 주어 추천 성능 개선함
◆ 3.7 Discussion
모델 비교
| 모델 | 학습 목표 | Attention 구조 | 입력/구조 특징 | BERT4Rec과의 관계 |
|---|---|---|---|---|
| SASRec | 다음 아이템 예측 (left-to-right) | Single-head, causal mask | 단방향 구조 | BERT4Rec의 단방향 버전 |
| CBOW | 중심 단어 예측 (문맥 평균) | Uniform attention (사실상 없음) | Positional embedding 없음 | BERT4Rec 단순화 버전 (self-attention 1층, uniform attention) |
| Skip-Gram (SG) | 중심 단어로 주변 단어 예측 | - | 중앙 단어만 남기고 나머지 마스크 | BERT4Rec 변형 케이스 |
| BERT | Pre-training 후 다양한 NLP 태스크 | Multi-head, bidirectional self-attention | NSP + segment embedding 포함 | 아이디어 차용, 하지만 BERT4Rec은 end-to-end 추천에 최적화 (NSP/segment 제거) |
| BERT4Rec | 마스크된 아이템 예측 (Cloze task) | Multi-head, bidirectional self-attention | 행동 시퀀스를 하나의 문장으로 모델링 | 추천 시스템에 맞춰 BERT 구조 변형 |
❖ 4. Experiment
◆ 4.1 Datasets
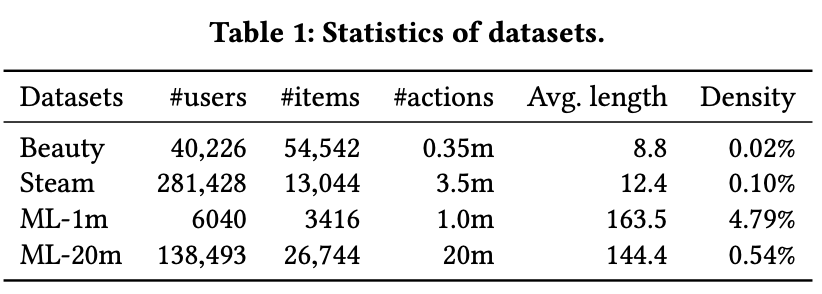
- 실험은 도메인과 희소성이 다른 4개 실제 데이터셋에서 진행됨
- Amazon Beauty: Amazon 리뷰 데이터 중 Beauty 카테고리.
- Steam: 온라인 게임 플랫폼 Steam의 구매/활동 데이터.
- MovieLens-1M (ML-1m): 약 100만 개 영화 평점 데이터.
- MovieLens-20M (ML-20m): 약 2천만 개 영화 평점 데이터.
◆ 4.2 Task Settings & Evaluation Metrics
- Task: Leave-one-out (마지막 아이템 → Test, 그 전 → Validation, 나머지 → Train)
- Negative Sampling: Test 시 ground truth 아이템 + 100개 negative 아이템 (인기도 기반 샘플링)
- Metrics:
- Hit Ratio (HR@k): 정답이 Top-k에 있으면 성공
- NDCG@k: 순위 고려한 지표
- MRR: 정답 위치의 역수 평균
◆ 4.3 Baselines & Implementation Details
Baselines
- POP: 단순 인기순 추천.
- BPR-MF: Pairwise ranking loss 기반 MF.
- NCF: MLP로 user-item 상호작용 학습.
- FPMC: MF + Markov Chain.
- GRU4Rec, GRU4Rec+: GRU 기반 sequential 추천.
- Caser: CNN 기반 sequential 추천.
- SASRec: Transformer 기반 sequential 추천 (state-of-the-art).
Implementation
공통 하이퍼파라미터
- Hidden dim d ∈ {16, 32, 64, 128, 256}
- ℓ2 regularizer ∈ {1, 0.1, 0.01, 0.001, 0.0001}
- Dropout ∈ {0, 0.1, …, 0.9}
BERT4Rec 세부 설정
- Optimizer: Adam (lr=1e-4, β1=0.9, β2=0.999, weight decay=0.01)
- Layer L=2, Head h=2
- Sequence length: ML(200), Beauty/Steam(50)
- Head dim=32
- Mask 비율 ρ: Beauty=0.6, Steam=0.4, ML-1m/20m=0.2
- 학습 환경: NVIDIA GTX 1080 Ti, batch size=256
◆ 4.4 Overall Performance Comparison
성능 비교 개요
- BERT4REC이 HR, NDCG, MRR 모든 지표에서 모든 데이터셋 최상위 성능
- 평균적으로:
- HR@10 +7.24%
- NDCG@10 +11.03%
- MRR +11.46%
→ 가장 강력한 baseline 대비 뚜렷한 향상함
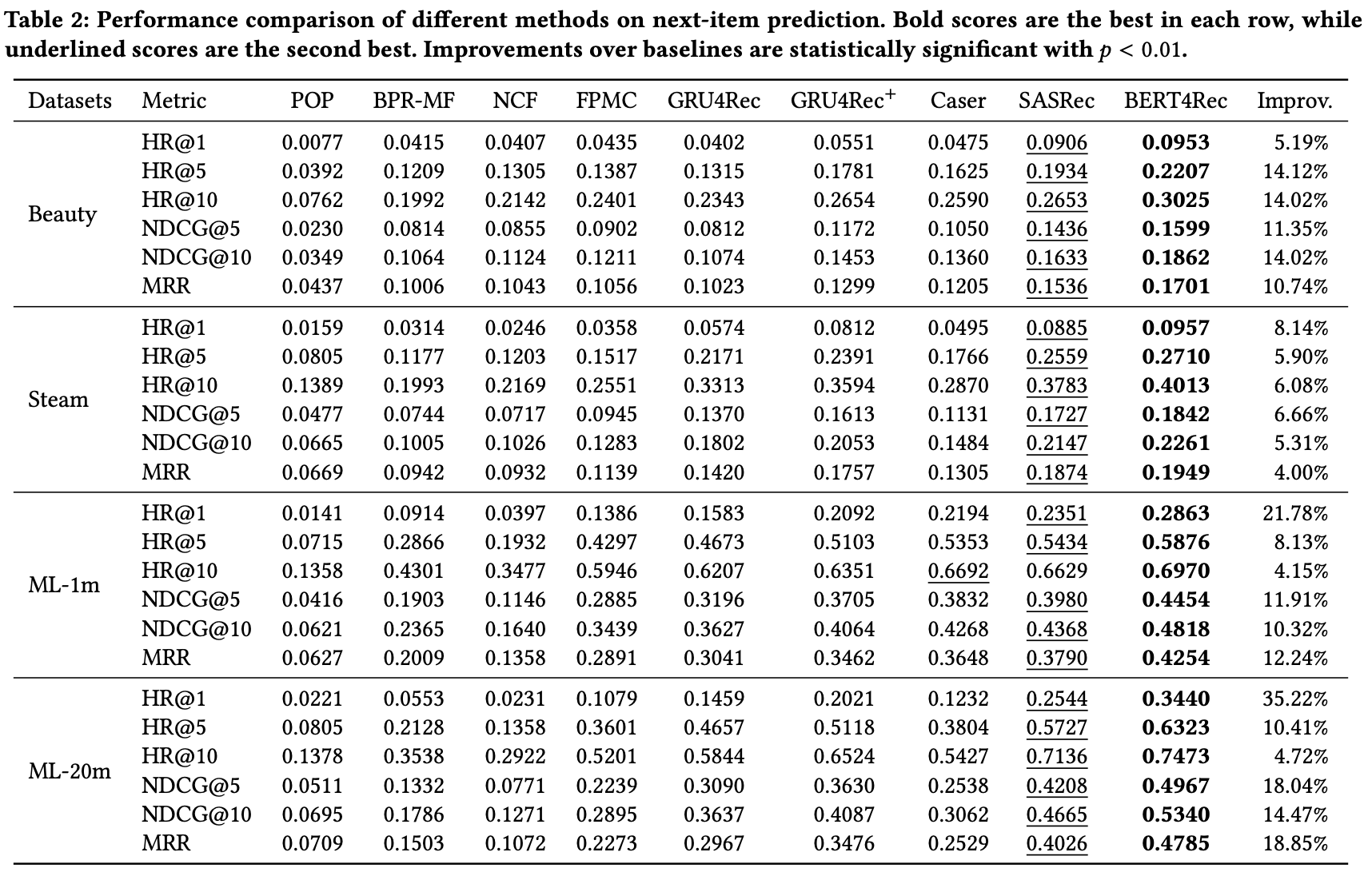
BERT4Rec 성능 향상의 원인
Question 1: Gains from Cloze Task & Bidirectionality?
-
SASRec과 비교하기 위해, BERT4Rec에서 한 번에 하나만 mask 처리
→ 차이는 양방향 문맥 사용 여부 -
결과: BERT4Rec(1 mask)이 SASRec보다 모든 지표에서 우수
→ 양방향 표현 학습의 중요성 확인 + Cloze objective 자체도 성능 향상에 기여함
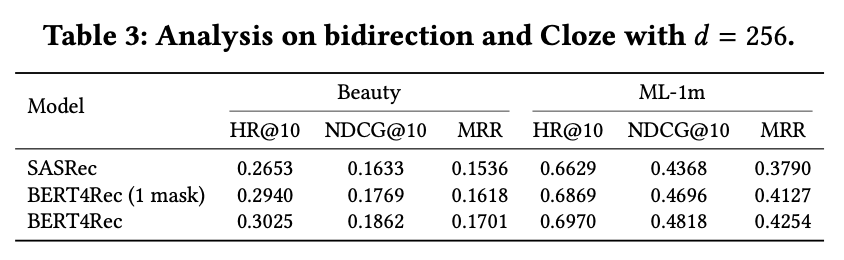
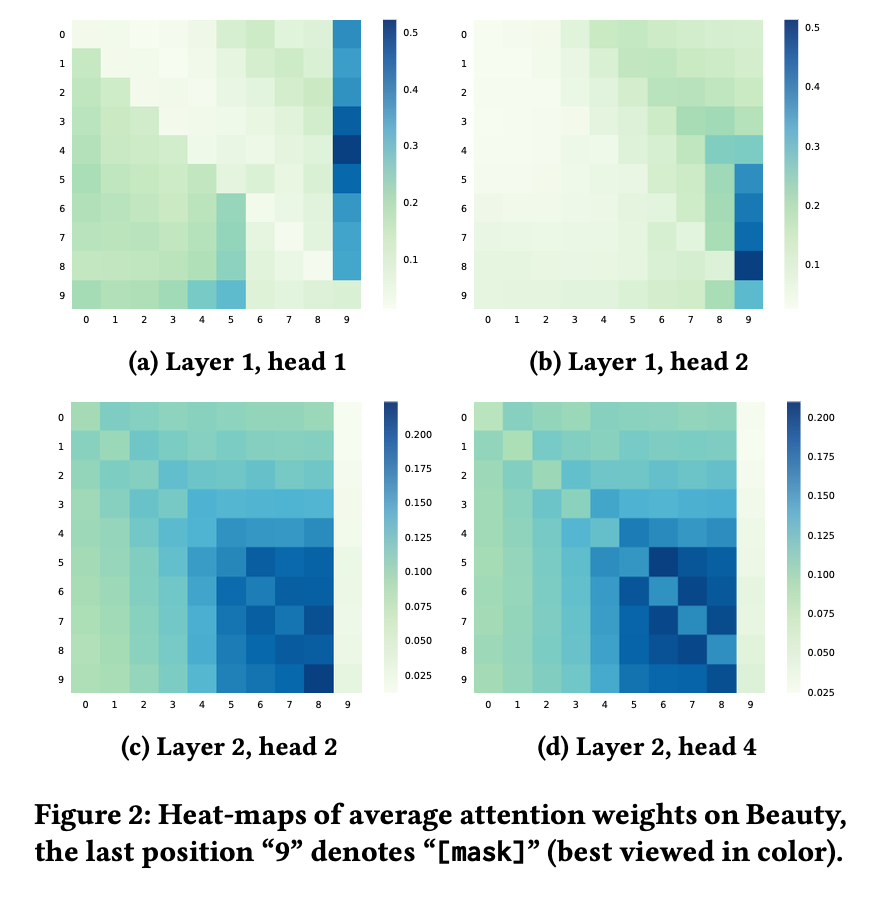
Question 2: Bidirectional 모델의 장점?
-
Attention 시각화 결과:
- Head별 차이: 어떤 head는 왼쪽 문맥, 다른 head는 오른쪽 문맥 집중함
- Layer별 차이: 2층은 최근 아이템에 집중 (출력층과 가까워서 미래 예측에 중요)
-
일부 head는 [mask] 토큰에도 집중 → 시퀀스 전체 정보를 아이템 수준으로 전달하는 역할
-
가장 중요한 점: SASRec(단방향)은 왼쪽만 보지만, BERT4Rec은 양쪽을 모두 봄
-
결론: 양방향 self-attention이 사용자 행동 시퀀스 모델링에 필수적임
◆ 4.5 Impact of Hidden Dimensionality
실험 개요
- Hidden dimension 값을 16 → 256까지 변화시키며 성능(NDCG@10, HR@10)을 비교해봄
- 다른 하이퍼파라미터는 최적값으로 고정함
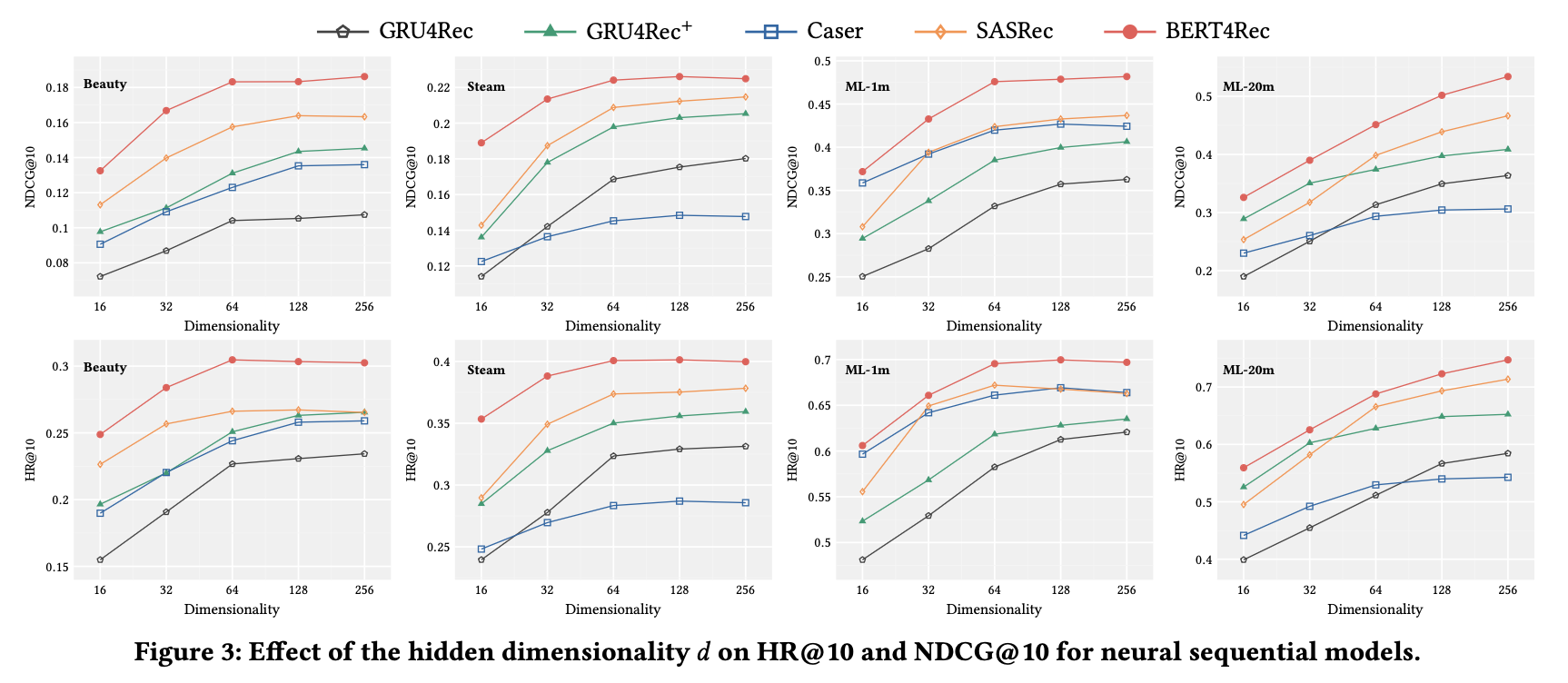
주요 관찰
- 성능 수렴 현상
- 차원이 커질수록 성능이 무조건 좋아지지 않음
- 일정 수준 이후(예: sparse dataset) → 오히려 성능 정체 또는 overfitting 발생함
- Sparse 데이터셋 영향
- Beauty, Steam 같이 희소한 데이터에서는 큰 차원이 오히려 불리함
- 모델별 차이
- Caser: 데이터셋에 따라 성능 변동이 크고 불안정함
- SASRec, BERT4Rec: 모든 데이터셋에서 안정적이며 consistently 높은 성능을 보임
- BERT4Rec의 특징
- 작은 차원(예: d=64)에서도 다른 baseline보다 좋은 성능 유지하며 효율성과 성능을 동시에 확보함
◆ 4.6 Impact of Mask Proportion
- ρ가 너무 작으면 학습 신호 부족, 너무 크면 문맥 부족으로 학습 어려움
- 결과 패턴: ρ > 0.6에서 성능 하락, 0.2는 0.1보다 항상 우수함
- 최적 ρ:
- 짧은 시퀀스 (Beauty, Steam) → 높게 설정 (0.6, 0.4)
- 긴 시퀀스 (ML-1m, ML-20m) → 낮게 설정 (0.2)
- 이유: 긴 시퀀스에서 높은 ρ는 예측해야 할 아이템이 너무 많아져 학습 난이도 ↑
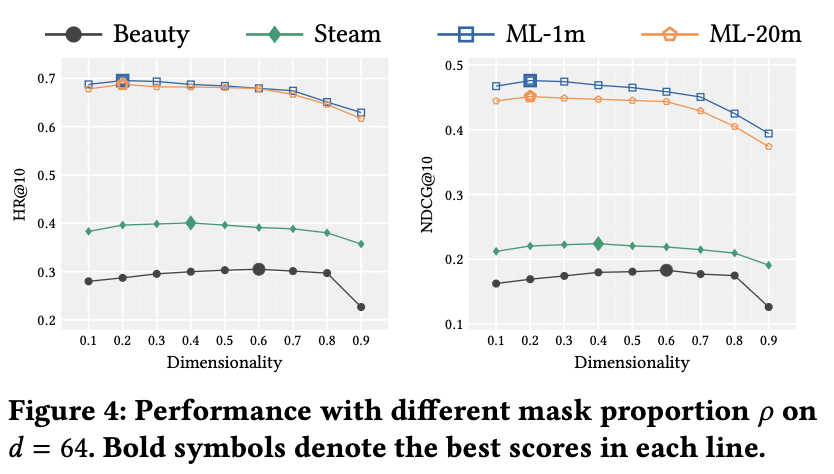
◆ 4.7 Impact of Maximum Sequence Length
-
N = 모델이 고려하는 최대 시퀀스 길이
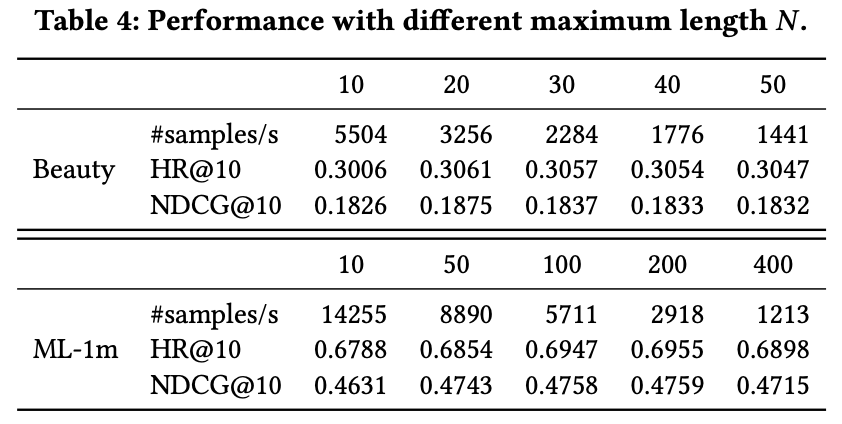
-
결과:
- Beauty (평균 8.8) → 최적 N = 20 (짧은 기록일수록 최근 아이템 영향 ↑)
- ML-1m (평균 163.5) → 최적 N = 200 (긴 기록에서 과거 아이템도 중요)
-
패턴:
- 큰 N이 항상 좋은 것은 아님 → 불필요한 정보·노이즈 증가 가능
- BERT4Rec은 N이 커져도 안정적으로 성능 유지 → 중요한 아이템만 잘 선택(attend)
-
효율성
- Self-attention의 복잡도: (길이 n에 대해 이차적)
- 하지만 GPU 병렬화 덕분에 훈련 속도는 실험에서 안정적임
4.8 Ablation Study
- BERT4Rec의 핵심 구성요소들을 제거하거나 변경하며 성능에 미치는 영향을 분석함
- (d=64, 기본 설정: L=2, h=2)
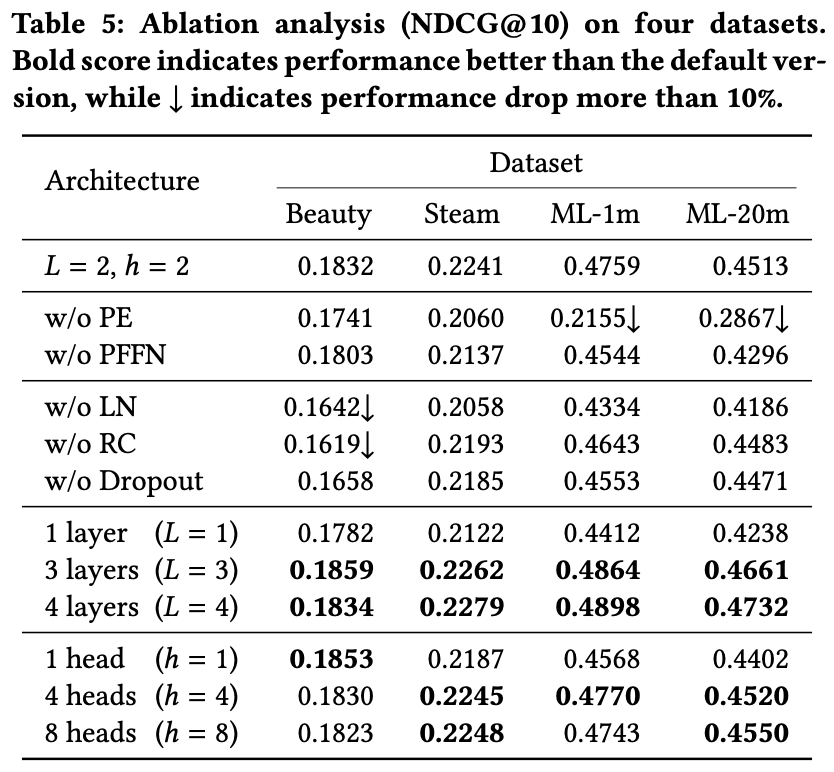
- (d=64, 기본 설정: L=2, h=2)
| 구성 요소 | 결과 & 영향 | 결론 |
|---|---|---|
| Positional Embedding (PE) | 제거 시 긴 시퀀스(ML-1m, ML-20m) 성능 급락. 위치 정보가 없으면 [mask] 토큰이 동일 표현 공유 → 예측 불안정 | 긴 시퀀스 학습에 필수 |
| Position-wise FFN (PFFN) | 긴 시퀀스에서 효과 큼. 여러 head 정보를 통합하는 역할 | long sequence에 유리 |
| LayerNorm (LN), Residual Connection (RC), Dropout | 주로 과적합 방지 목적. 작은 데이터셋(Beauty)에서 효과 뚜렷. ML-20m에서 RC 제거 → 성능 약 10%↓ | 일반화에 중요 |
| Layer 수 (L) | 층을 쌓을수록 성능 ↑ (특히 큰 데이터셋). 하지만 Beauty에서 L=4 → 과적합으로 성능↓ | 대규모 데이터셋 → 깊게, 소규모 데이터셋 → 얕게 |
| Head 수 (h) | 긴 시퀀스(ML-20m) → 큰 h가 효과적 (멀리 떨어진 의존성 학습). 짧은 시퀀스(Beauty) → 작은 h가 더 적합 | 시퀀스 길이에 따라 h 조정 필요 |
❖ 5.Conclusion & Future Work
결론
- 본 논문은 BERT4Rec, 즉 양방향 self-attention 기반 sequential recommendation 모델을 제안
- 학습 시 Cloze task를 도입하여, 아이템을 마스킹하고 양쪽 문맥을 활용해 예측함
- 4개 실제 데이터셋에서 실험한 결과, 기존 state-of-the-art 모델들을 모두 능가하는 성능을 보임
향후 연구 방향
- 풍부한 아이템 특성 반영
- 단순 item ID 대신, 제품 카테고리, 가격, 영화 출연진 등 부가 정보 활용하는 것
- 사용자 특성 모델링
- 단일 시퀀스가 아닌 여러 세션을 가진 유저를 명시적으로 모델링
- User embedding을 모델에 포함해 더욱 정교한 추천 가능성
자료 출처
https://www.analyticsvidhya.com/blog/2023/06/understanding-attention-mechanisms-using-multi-head-attention/
https://d2l.ai/chapter_attention-mechanisms-and-transformers/transformer.html
https://www.researchgate.net/figure/Comparison-of-the-ReLu-and-GeLu-activation-functions-ReLu-is-simpler-to-compute-but_fig3_370116538
❖ 실제 프로젝트 활용
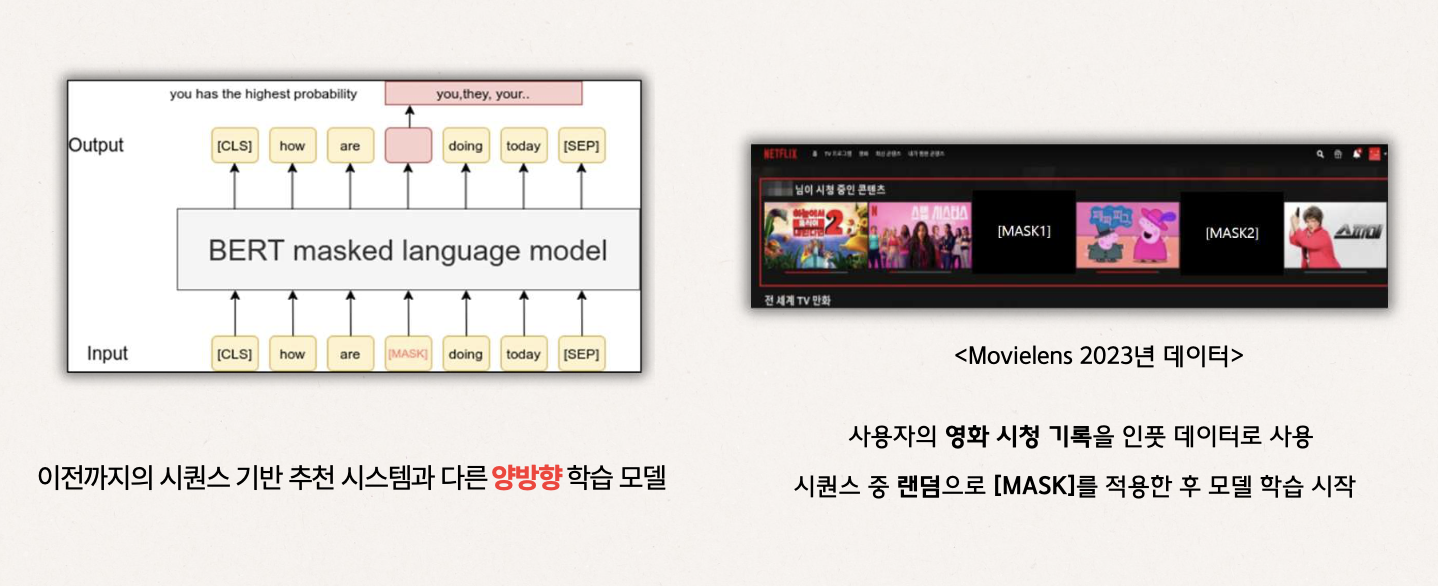
Movie Lens의 사용자가 시청한 영화 기록 데이터를 사용함
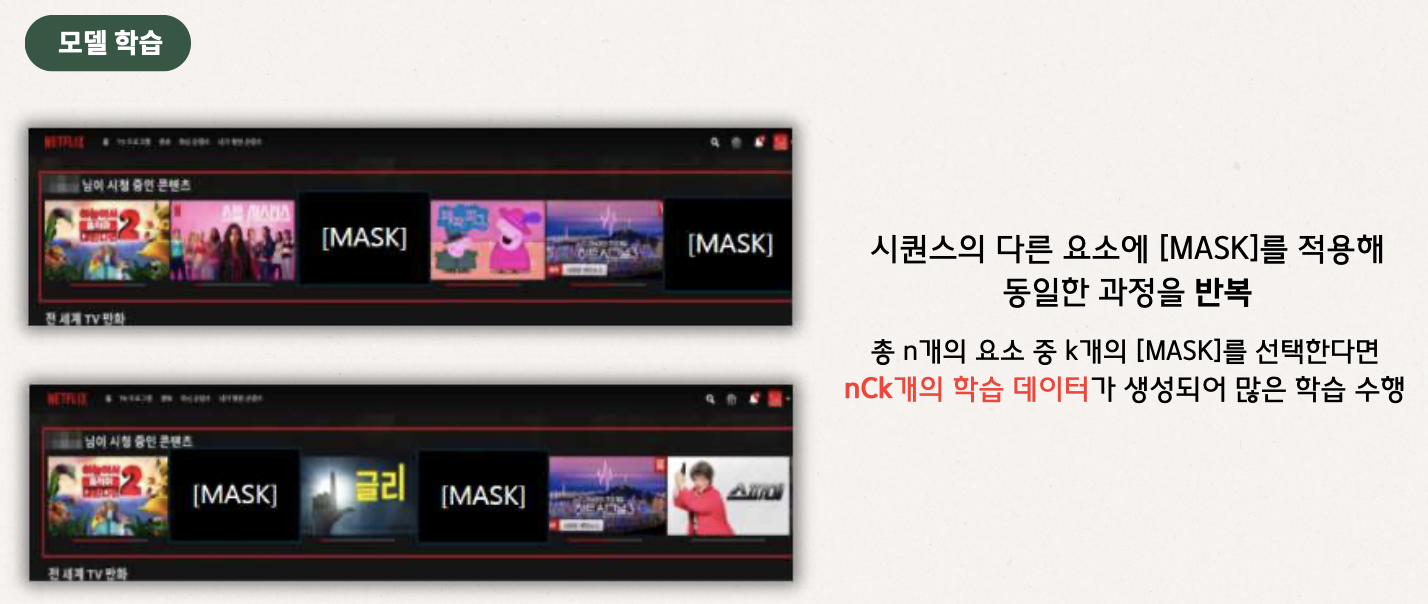
-
모델 학습 단계: 시퀀스 내 여러 아이템을 무작위로 [MASK] 처리해 Cloze 방식으로 학습을 반복

-
추천 단계: 시퀀스 마지막에 [MASK]를 추가해 사용자가 볼 다음 아이템을 예측

-
최종적으로 사용자별 1개의 영화를 추천하고, 해당 영화의 장르·분위기 정보를 활용해 여행지를 매칭힘
-
이를 통해 영화 취향을 기반으로 사용자의 내적 성향을 파악하고 맞춤형 추천에 활용
❖ 후기
- 여러 프로젝트를 진행하면서 결과 위주로만 생각하다 보니, 내가 직접 담당하지 않은 부분은 명확히 이해하지 못한 채 넘어간 경우가 있었는데 그중 하나가 바로 이 부분이었는데, 이번 기회에 논문을 직접 읽고 분석하면서 제대로 이해할 수 있었던 점이 큰 도움이 되었음
- 당시에는 “추천 시스템인데 왜 BERT 모델을 쓰는 걸까?”라는 의문이 있었는데 이번에 읽으면서 BERT의 마스킹 기법, 양방향 학습, 트랜스포머 구조를 다시 복습하며 추천 시스템에 적용했을 때 좋은 성능이 나오는 이유를 깨닫게 되었음
-
BERT가 단순히 텍스트 처리에만 쓰이는 것이 아니라 다른 도메인에도 활용될 수 있다는 점이 흥미로웠고, 이런 연관성을 떠올리니 다른 논문들에 대한 궁금증도 더 커졌음
물론 모델 내부의 모든 수식을 완벽히 이해했다고 말할 수는 없지만 전체적인 흐름과 구조는 충분히 파악할 수 있었고, 처음부터 끝까지 직접 읽어본 경험 자체가 값졌고 특히 GPT와 함께 정리하며 학습하니 훨씬 효율적이었음 -
추천 시스템이라는 분야는 생각보다 재미있고 직관적인 면이 많아 흥미가 생기게 되었음
최근 연구들이 LLM과 언어모델에 집중되는 경향이 있지만 이런 아이디어들을 추천 시스템에도 적용하는 것은 매우 의미 있는 발전이라 생각함
앞으로 기회가 된다면 다른 추천 시스템 논문들도 찾아보고 싶음
- 논문 만족도 : ⭐️⭐️⭐️
- 논문 이해도 : ⭐️⭐️⭐️
- 추천 시스템 관심도 : ⭐️⭐️⭐️⭐️
