논문 링크 : https://arxiv.org/abs/2002.08909
❖ 논문 선정 이유
- 내가 이 논문을 선택한 이유는, 지원을 고려 중인 대학원 대부분이 LLM을 기반으로 하고 있으며 RAG를 그 핵심 배경으로 두고 있기 때문임
- 따라서 관련 연구를 이해하기 위해서는 LLM과 RAG의 근본 원리를 먼저 익히는 것이 중요하다고 판단했음
- 그중 RAG의 기초가 되는 REALM 논문을 통해 이 분야의 근간을 확실히 다지고자 했음
❖ 0. Abstract
◆ 문제점
- 기존 언어모델은 많은 지식을 담고 있지만 지식이 전부 파라미터에 암묵적으로 저장되어 있음 → 모델이 커져야만 더 많은 지식을 커버 가능했음
◆ 해결 아이디어
-
언어모델에 latent knowledge retriever 추가함
-
Wikipedia 같은 대규모 문서를 검색·참조 가능해짐
-
Pre-training, Fine-tuning, Inference 모든 단계에서 retrieval 사용함
◆ 학습 방법
-
최초로 retriever를 unsupervised하게 학습시킴
-
Masked Language Modeling(MLM) 신호 활용함
-
수백만 개 문서를 대상으로 backpropagation 진행함
❖ 1. Introduction
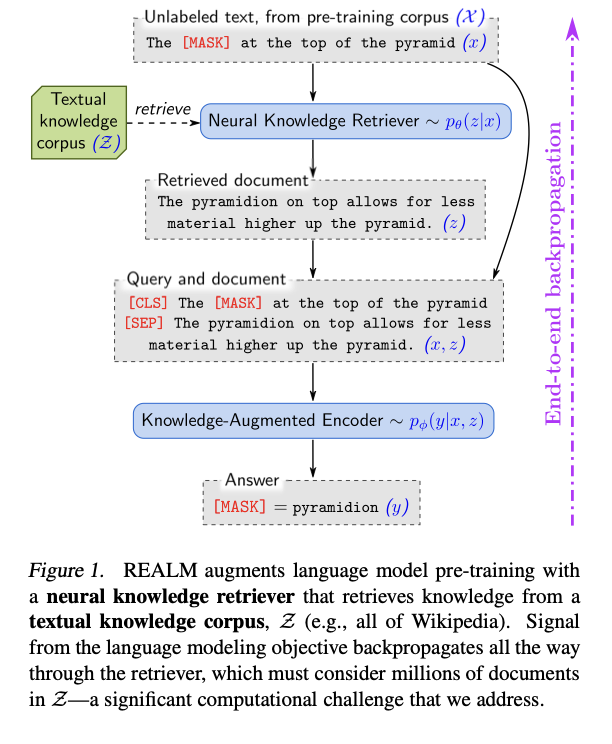 이 그림은 REALM의 전체 작동 흐름을 보여줌
이 그림은 REALM의 전체 작동 흐름을 보여줌
-
먼저 모델은 [MASK] 토큰이 포함된 문장(x) 을 입력으로 받고, Neural Knowledge Retriever가 대규모 지식 말뭉치(Z) (예: Wikipedia)에서 관련 문서(z)를 검색함
-
검색된 문서와 원문을 결합해 Knowledge-Augmented Encoder에 함께 입력하면, 모델은 문맥과 외부 지식을 활용해 [MASK]의 정답(y) 을 예측함
-
이 과정 전체는 end-to-end 학습으로 이루어지며, 예측 결과의 손실이 retriever까지 역전파(backpropagation) 되어 함께 학습된다는 점이 핵심임
◆ 배경
-
2020년도 당시 LM(BERT, RoBERTa, T5 등)은 대규모 텍스트에서 학습해 놀라운 수준의 세계 지식을 담고 있었음
- 예: BERT는 “The ___ is the currency of the United Kingdom”에서 “pound” 맞춤
-
하지만 이 지식은 모델 파라미터 속에 암묵적으로 저장되며 어디에 어떤 지식이 있는지 알기 어려움 (비해석성)
-
지식을 더 담으려면 모델 크기를 키워야 함 (비효율, 고비용)
◆ 제안 (REALM)
-
지식을 파라미터 속에 묻어두지 말고, retriever를 붙여 외부 지식(예: Wikipedia)에서 검색 → LM이 이를 참조하도록 설계함
-
모델은 “어떤 지식을 검색해야 할지” 스스로 결정함
- 학습 방식: retrieval이 LM perplexity(언어모델 성능)에 도움 되면 보상, 아니면 패널티를 주고 이는 즉, retrieval 품질을 성능 기반으로 학습하는 것임
-
기술적 구현:
- 문서 후보 수백만 개 → MIPS(Maximum Inner Product Search)로 빠르게 선택
- 문서 embedding 계산은 캐싱해서 효율화
◆ 기존 연구와 차별점
-
과거 retrieval을 붙인 모델들(Chen 2017, Asai 2019 등)은 heuristic 기반 / non-learned retriever
Non-learned retriever: 학습으로 최적화되지 않고, TF-IDF나 BM25 같은 규칙 기반(heuristic)으로 문서를 검색하는 방식
-
kNN-LM(Khandelwal 2019)은 retrieval을 했지만 downstream fine-tuning에 한계
Downstream fine-tuning: 사전학습된 모델을 이후 특정 과제(예: QA, 감정분석 등)에 맞게 추가 학습시키는 단계
-
REALM은 retriever를 학습 가능하게 설계하고, 다양한 downstream task로 전이 가능함
◆ 검증
- Open-domain QA (지식집약적 태스크)에 적용함
- NaturalQuestions-Open, WebQuestions, CuratedTREC 벤치마크 실험
- 결과: 기존 최고 성능 대비 절대 4~16% 정확도 향상됨
- 추가 장점:
- 해석 가능성 (어떤 문서 보고 답했는지 확인 가능)
- 모듈성 (retriever DB만 바꾸면 지식 업데이트 가능)
❖ 2. Background
◆ Language Model Pre-training
-
목표: 언어 표현(representation) 을 학습하기 위해 대규모 비라벨 텍스트로 사전학습
대표 방법: Masked Language Model (MLM, BERT)
-
예: "The [MASK] is the currency [MASK] the UK"
정답: ("pound", "of")
의미: 문법적 지식(“of”) + 세계 지식(“pound”)을 모두 학습해야 좋은 모델이 됨
-
◆ Open-domain Question Answering (Open-QA)
-
정의: 질문 x에 대해, 사전에 특정 문서가 주어지지 않은 상태에서 정답 y를 출력
-
예: "What is the currency of the UK?" → "pound"
-
특징:
-
Reading Comprehension(RC) (예: SQuAD)은 답변 문서가 주어짐
-
반면 Open-QA는 수백만 개 문서 중 어떤 게 관련 있는지도 알아내야 함
-
◆ 기존 접근법
Retrieval-based (검색+추출)
-
질문 x → 문서 집합 Z에서 관련 문서 z 검색 → 답 y 추출함
-
대표: Chen et al. 2017, Lee et al. 2019
Generation-based (생성)
-
질문 x → seq2seq 모델이 직접 답 y를 생성함
-
대표: Lewis et al. 2019 (BART), Raffel et al. 2019 (T5)
◆ REALM의 위치
-
REALM은 retrieval-based 접근법을 언어모델 pretraining에 통합함
-
즉, LM 학습 단계부터 retrieval을 함께 학습해 Open-QA 성능을 크게 올리는 게 목표
❖ 3. Approach
◆ 3.1 Generative Process
-
REALM은 retrieve → then predict 방식으로 작동함
-
입력 x가 들어오면 관련 문서 z를 knowledge corpus Z에서 검색
-
검색된 문서 z와 함께 정답 y를 예측
-
전체 확률은 이렇게 표현됨
-
Pretraining 단계에서는 Masked Language Modeling(MLM) 으로 학습
-
Fine-tuning 단계에서는 Open-domain QA로 학습
◆ 3.2 Model Architecture
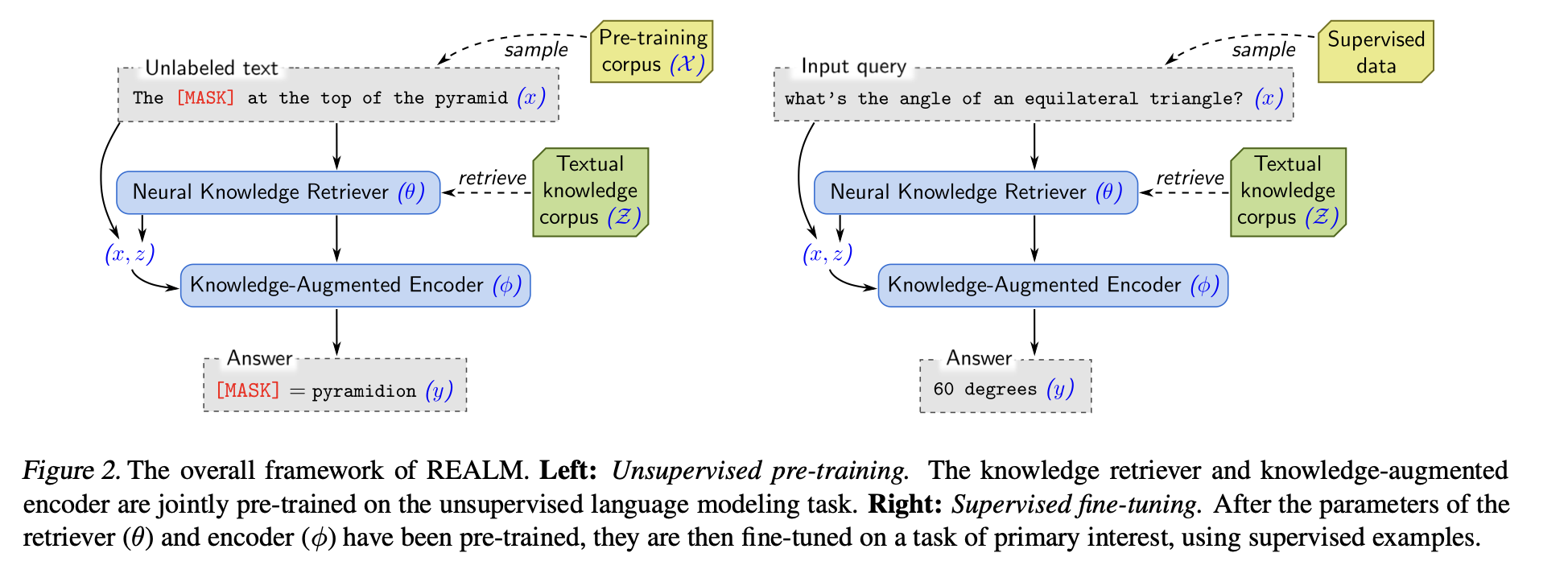
-
이 그림은 REALM의 학습 과정 전체 흐름을 보여줌
-
왼쪽은 비지도 사전학습 (Unsupervised Pre-training) 단계
-
오른쪽은 지도 미세조정 (Supervised Fine-tuning) 단계
-
왼쪽 (Pre-training)
-
모델은 [MASK] 토큰이 포함된 문장을 입력받고 Neural Knowledge Retriever 가 위키피디아 같은 지식 코퍼스 에서 관련 문서를 검색함
-
검색된 문서와 원래 문장 을 함께 Knowledge-Augmented Encoder 에 넣어 [MASK]를 채우는 단어를 예측함
오른쪽 (Fine-tuning)
-
이미 학습된 retriever와 encoder를 이용해 “정삼각형의 각도는 몇 도인가?” 같은 질문 을 입력받으면 관련 문서를 찾아보고, 그 내용을 참고해 정답 ( = 60 degrees) 를 예측함
-
즉 REALM은 retrieval(검색) 과 language modeling(생성) 을 결합 한 구조로지식이 외부 문서에 저장되어 있고, 필요한 순간에 꺼내 쓰는 형태로 동작함
(1) Neural Knowledge Retriever
-
문서와 쿼리를 dense embedding으로 바꿔 relevance score 계산
-
이 score를 softmax로 변환해서 를 구함
-
탐색 과정은 MIPS (Maximum Inner Product Search) 알고리즘을 이용해 빠르게 top-k 문서를 찾음
MIPS(Maximum Inner Product Search)는 벡터 간 내적값이 최대인 항목을 빠르게 찾는 알고리즘
(2) Knowledge-Augmented Encoder
- 검색된 문서 z와 입력 x를 하나의 시퀀스로 결합
- Transformer가 두 정보를 통합해 인코딩
- MLM에서는 [MASK] 토큰 예측
- Open-QA에서는 정답의 시작·끝 위치를 예측
◆ 3.3 Training
-
Retriever와 Encoder를 end-to-end로 함께 학습함
-
하지만 p(y|x)는 수백만 개 문서를 모두 합산해야 하므로 계산량이 매우 큼
-
이를 해결하기 위해 top-k 근사를 사용함
Asynchronous MIPS Refresh
-
retriever의 embedding이 계속 바뀌면 MIPS 인덱스가 오래돼서 일관성이 깨짐
-
그래서 trainer job(학습)과 index builder job(인덱스 재구성)을 비동기적으로 병렬 실행함
- Trainer job은 모델을 학습시키는 작업
- Index builder job은 학습된 벡터들을 효율적으로 검색하기 위해 인덱스를 재구성하는 작업
- 일정 주기로 인덱스를 “refresh”해서 retriever의 최신 상태를 반영함
◆ 3.4 Injecting Inductive Biases
- REALM이 단순 MLM이 아닌 지식 학습 중심으로 발전하도록 몇 가지 전략을 추가함
Salient Span Masking
- 단어 하나가 아닌 의미 단위(예: “United Kingdom”)를 통째로 마스킹
BERT tagger(CoNLL NER)로 주요 개체 span을 골라 masking
→ 지식 예측에 초점을 맞춘 학습 가능
Null Document
- 모든 [MASK]가 외부 지식 기반 예측을 필요로 하진 않음
빈 문서(null doc)를 추가해 불필요한 retrieval을 막음
Prohibiting Trivial Retrievals
- 학습 코퍼스 X와 지식 코퍼스 Z가 같으면 retriever가 단순 문자열 매칭을 학습할 위험이 있음
- 이런 경우는 학습에서 제외
Initialization (Warm Start)
- 초기에는 embedding 품질이 낮아서 retriever가 엉뚱한 문서를 가져올 수 있음
이를 막기 위해 BERT-base 모델로 warm start후 학습 시작Warm start는 이전 학습 결과(가중치 등)를 초기값으로 사용해 학습을 이어가는 방식
◆ 3.5 What the Retriever Learns
- REALM의 retriever는 모델 예측 정확도를 높이는 retrieval을 선택하는 방향으로 학습됨
- retrieval이 언어모델의 perplexity를 낮추면 gradient가 f(x,z)를 높이는 방향으로 업데이트됨
- 즉, 도움이 되는 문서를 스스로 구별하고 가져오는 법을 배우는 셈
❖ 4. Experiments
- REALM은 Open-Domain Question Answering(Open-QA) 태스크에서 성능을 검증함
- 이때 모델의 핵심 목표는 외부 지식 문서(Wikipedia 등) 를 활용해 질문에 대한 정답을 예측하는 것임
◆ 4.1 Open-QA Benchmarks
- NaturalQuestions-Open (NQ): 실제 Google query 기반의 질문·답변 데이터셋
- WebQuestions (WQ): Google Suggest API에서 수집된 데이터
- CuratedTrec (CT): 실제 검색 질의 기반 QA 쿼리 세트
- REALM은 이 세 벤치마크에서 state-of-the-art 모델 대비 4~16%p 성능 향상을 달성함
◆ 4.2 비교 모델
- 비교 대상은 크게 두 가지 패러다임으로 나뉨:
- Retrieval-based 모델 — ORQA, DrQA, PathRetriever 등
- 문서를 검색해 정답을 추출
- Generation-based 모델 — T5, GPT-2 기반
- 질문을 입력받아 정답을 직접 생성
- REALM은 retrieval 기반이지만, pre-training 단계부터 retriever를 end-to-end로 학습한다는 점이 차별점임
◆ 4.3 Implementation Details
- Pre-training: 200k step, 64 TPU, batch size 512
- Fine-tuning: NQ 기준 상위 5개 retrieval 결과를 이용
- Knowledge corpus: Wikipedia (또는 CC-News)
◆ 4.4 Main Results
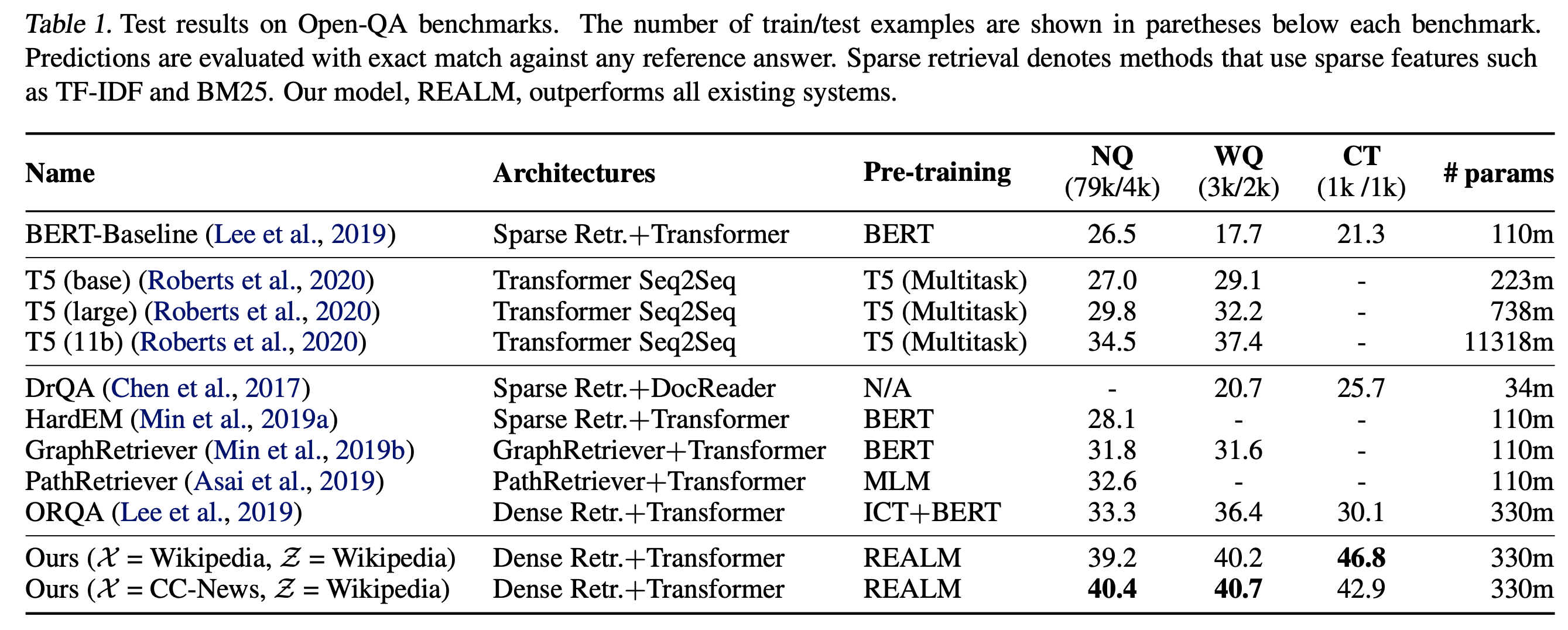
- 기존 ORQA 대비 약 +7%p 향상함
- parameter는 같지만 retriever pre-training 덕분에 효율적임
◆ 4.5 Analysis
- REALM은 모델의 구성 요소가 실제 성능에 어떤 영향을 미치는지를 Ablation Study로 검증함
Ablation Study는 모델의 구성요소나 입력을 하나씩 제거해가며 각 요소의 성능 기여도를 분석하는 실험
- 아래 표는 NaturalQuestions(NQ) 개발셋에서 각 실험 조건에 따른 성능을 보여줌
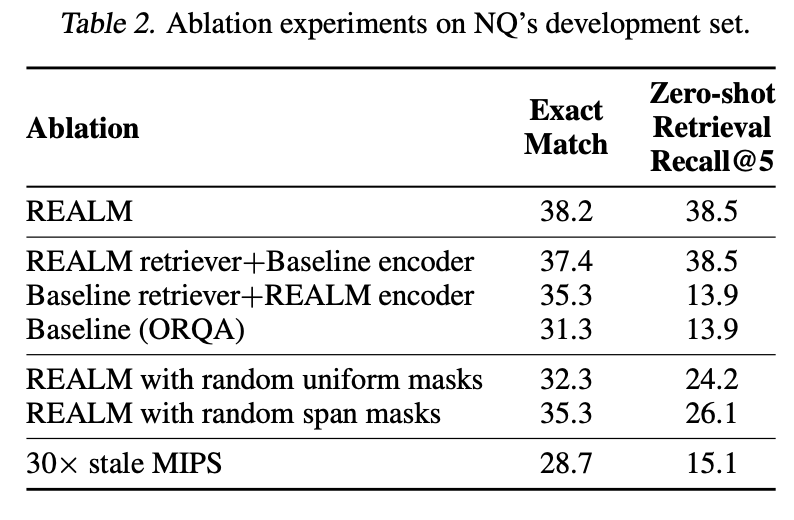
Encoder vs Retriever
- REALM은 retriever와 encoder 모두 pre-training 과정에서 성능이 향상됨을 보여줌
- retriever만 REALM으로 바꿔도 성능이 37.4로 상승
- encoder만 REALM으로 바꾸면 35.3으로 상승
→ 두 모듈이 함께 작동할 때 최고 성능(38.2)을 달성 - 즉, retrieval과 language understanding이 함께 학습될 때 시너지가 발생함을 증명함
Masking Scheme
- REALM은 기존 BERT의 random masking 대신 Salient Span Masking (핵심 명사구 마스킹) 을 사용해 성능을 개선함
- 일반 random masking: 32.3
- span masking: 35.3
→ retrieval 학습의 효율을 높이려면, 정보량이 많은 토큰을 마스킹해야 함을 보여줌
MIPS Index Refresh
- retrieval 인덱스를 주기적으로 업데이트하는 것이 매우 중요함
- 인덱스가 “stale(오래된)” 상태일 경우 성능 급감 (Exact Match 28.7)
→ retrieval-encoder 간 최신 임베딩 동기화가 모델 안정성에 핵심적
Retrieved Document Example
- BERT는 “Fermat” 단어의 예측 확률이 이지만 REALM은 관련 문서를 찾아 까지 향상시킴
- 단순히 파라미터 내부의 기억에 의존하는 대신 외부 지식 문서를 동적으로 검색해 문맥 이해를 강화함을 보여줌
❖ 5. Discussion and Related Work
◆ Language modeling with corpus as context
- 기존 BERT나 GPT는 문장 단위 혹은 문단 단위의 문맥을 활용했지만 REALM은 이를 “문서 전체 수준(corpus-level)”으로 확장시킴
→ 즉, 전체 위키피디아 같은 대규모 지식을 문맥으로 활용하는 최초의 LM 구조
◆ Retrieve-and-edit with learned retrieval
- 기존의 retrieve-then-edit 모델들은 사람이 지정한 유사 문서(lexical overlap)에 의존했지만
- REALM은 “retriever를 스스로 학습” 해서 언어모델이 필요한 정보를 직접 선택
→ 따라서 단순한 단어 유사도가 아닌 의미 기반 지식 검색이 가능
◆ Scalable grounded neural memory
- REALM의 Knowledge Index는 ‘메모리’ 처럼 작동
각 문서는 embedding 형태로 저장되어 있고 필요한 지식을 retrieval을 통해 “메모리에서 불러오는 구조”
→ GPT류의 암기형 모델과 달리, 설명 가능하고 해석 가능한지식 접근이 가능
◆ Unsupervised Corpus Alignment
-
REALM은 학습 중 자동으로 “문맥-문서 간 비지도 정렬(unsupervised alignment)”을 수행
→ 즉, 언어모델이 학습 도중 스스로 “어떤 문서가 어떤 문장과 관련 있는지”를 학습함 -
이를 통해 자연스럽게 텍스트와 지식 간의 연결 구조를 형성
❖ 6. Future Work
- REALM은 “지식을 실시간으로 검색하고 추론하는 언어모델” 의 최소 형태로,
향후 여러 방향으로 확장될 수 있는 기반 구조임을 제시함
◆ Structured Knowledge (구조적 지식 통합)
- 텍스트뿐 아니라, 엔티티 간 관계(graph 구조 등) 를 함께 학습하고 어떤 엔티티가 유용한지를 자동으로 판단하는 지식 선택 학습 방향으로 확장
◆ Multi-lingual (다국어 확장)
- 리소스가 적은 언어의 성능을 향상시키기 위해 고자원 언어(예: 영어)에서 검색한 지식을 저자원 언어로 전이(retrieving & transferring) 하는 방법 제안
◆ Multi-modal (멀티모달 확장)
- 텍스트로는 부족한 지식을 이미지, 비디오 등 시각 정보로 보완
- 예: “피라미드 구조”를 설명할 때 실제 이미지나 다이어그램을 retrieval 하는 식
❖ 논문 후기
-
사실 LLM은 내가 원래 깊게 관심을 두던 분야는 아니었는데 비타민에서 프로젝트를 진행하면서 LLM을 활용하긴 했지만 제대로 파고들어 공부한 건 마지막 프로젝트가 처음이었음
-
그 프로젝트에서 처음으로 RAG를 접했고 이를 이용해 프로젝트를 완성했지만 그 당시엔 단순히 “RAG를 쓰면 LLM이 더 잘 작동한다” 정도로만 이해했었음
-
최근 대학원을 알아보면서 보니 대부분의 연구실이 LLM을 기본적으로 활용하고 RAG 또한 기본 배경으로 깔고 가는 경우가 많았음 그래서 이번 기회에 RAG의 원리를 제대로 이해해보고 싶어 기초가 되는 논문을 리뷰하게 되었음
-
AI나 모델을 단순히 사용하는 것도 좋지만 원리를 알고 쓰면 훨씬 더 잘 활용할 수 있다고 생각하여서 지금처럼 시간이 있을 때 이런 기초를 다져두면 앞으로 큰 도움이 될 것 같음
-
이번에는 LLM과 RAG 관련 기본 논문을 리뷰했지만 앞으로는 추천 시스템 분야에서도 기초 논문부터 최신 연구까지 차근차근 리뷰해볼 계획임
- 논문 만족도 : ⭐️⭐️⭐️
- 논문 이해도 : ⭐️⭐️⭐️
- RAG 관심도 : ⭐️⭐️
