논문 원본 : https://arxiv.org/abs/2103.00020
❖ 논문 선정 이유
-
최근 GPT-3, Attention, S3-Rec, CL4SRec 등을 리뷰하면서 표현 학습과 모델 구조를 이해해왔지만 현대 연구의 흐름은 단일 모달을 넘어 멀티모달로 확장되고 있다는 것을 느꼈음
-
CLIP은 이러한 멀티모달 패러다임을 처음으로 대중적으로 열어준 핵심 논문이기 때문에
대학원을 준비하는 입장에서 반드시 짚고 넘어가야 할 연구라고 판단해 선정함
❖ 1. 연구 등장 배경
◆ 과거 모델들의 문제
-
기존 비전 모델 대부분은 ImageNet과 같은 정제된 라벨 데이터셋에 강하게 의존해왔음
-
이 방식은 잘 구축된 태스크에서는 높은 성능을 보이지만 구조적 한계가 있음
-
정확한 라벨에 대한 의존도
Supervised learning 기반 모델은 대규모의 사람이 만든 라벨이 필수적인데 이러한 라벨링 과정은 비용이 매우 크고 정의 자체가 모호하거나 전문 지식이 필요해 구축이 사실상 불가능한 경우가 많음 -
task-specific fine-tuning이라는 병목
현대의 비전 모델은 각 태스크마다 별도의 fine-tuning 단계가 필요하며 분류, 검출, OCR 등 모델 별로 이에 맞는 데이터로 따로 학습해야 하며 이로 인해 범용적 시각 표현을 학습하기 어렵고 새로운 태스크로 확장할 때마다 학습 비용이 반복적으로 발생하는 문제가 있음 -
현실 환경에서의 성능 저하 (Domain shift problem)
supervised vision 모델이 데이터 분포 변화에 매우 취약함
-
◆ 논문 핵심
-
인터넷에는 이미지 + 텍스트 설명이 ‘자연적으로 결합된 형태’로 무한히 존재함
-
예를 들어 SNS의 사진 + 캡션, 전자상거래 이미지 + 상품 설명, 뉴스 이미지 + 기사문, 등 이러한 데이터는 누가 라벨링한 것도 아니지만 이미지와 텍스트 사이에 의미 있는 연결(semantic alignment)이 존재하는 것을 알 수 있음
사람이 라벨을 붙이지 않아도, 인터넷에 존재하는 이미지–텍스트 쌍을 활용해 범용적인 시각 표현을 학습할 수 있게 만든 모델이 CLIP(OpenAI, 2021)
❖ 2. 핵심 아이디어
CLIP이 제안한 핵심 아이디어는
이미지와 텍스트를 같은 의미 공간(semantic space)에서 정렬(alignment)시키는 것
- 기존 시각 모델은 이미지 내부의 패턴을 라벨과 매핑하는 방식으로 학습되었지만, CLIP은 이미지와 이를 설명하는 자연언어 문장을 쌍(pair)으로 보며, 두 modality가 공유하는 추상적 의미(semantic concept)를 학습의 중심에 둔다.
◆ 이미지 Encoder와 텍스트 Encoder를 각각 학습하되, 두 표현이 같은 개념을 공유하도록 정렬함
-
CLIP은 두 개의 독립적인 인코더를 사용함
- Image Encoder: ResNet or Vision Transformer(ViT)
- Text Encoder: Transformer 기반 언어 인코더(GPT-like)
-
각 인코더는 임의의 공간에서 embedding을 출력하지만 같은 이미지–텍스트 쌍은 embedding space에서 가깝게 다른 쌍은 멀어지도록 학습하게됨
-
이를 통해 모델은 ‘고양이’, ‘사람’, ‘자동차’ 같은 단순 라벨이 아니라,
텍스트로 표현되는 풍부한 서술적 의미(deep semantics)를 학습하게 됨
◆ 자연언어를 라벨이 아닌 의미적 감독으로 사용
- 기존 supervised vision은 단 하나의 정답 라벨만 있었지만 CLIP에서는 한 이미지가 다양한 방식으로 설명될 수 있음
기존 supervised vision :
Image → “cat”
CLIP :
“a cute black cat sitting on a wooden floor”
“a small animal with green eyes”
“a photo of a cat indoors”
- 자유로운 자연언어 감독(signal) 을 활용함으로써 정형화된 라벨보다 훨씬 넓은 의미 공간을 학습하게 되며 자연언어 전체가 시스템의 감독 신호(supervision)가 되는 것임
◆ 대규모 웹 데이터에 기반한 대규모 contrastive learning
-
CLIP의 가장 큰 강점은 데이터 스케일임
-
약 4억 개의 (이미지, 텍스트) 쌍 noisy하지만 다양한 웹 기반 데이터이며 사전 정의된 라벨이 필요 없음
-
이 데이터는 학습 과정에서 positive / negative pair를 구성하는 데 활용되며 대규모 음수 샘플이 contrastive loss를 더욱 강력하게 만듦
◆ 최종 learned representation은 언어로 질의 가능함
- CLIP이 학습한 embedding은 단순 피처가 아니며 예를 들어 이미지에 대해:
→ “a photo of a dog”,
→ “a man riding a bike”,
→ “red sports car”-
이런 텍스트 후보들을 비교하기만 해도 자연스럽게 분류, 검색, 매칭 등의 작업이 가능함
-
이는 이미지와 텍스트를 동일한 좌표계로 끌어온 것이며 Vision과 Language의 경계를 완전히 허문 구조임
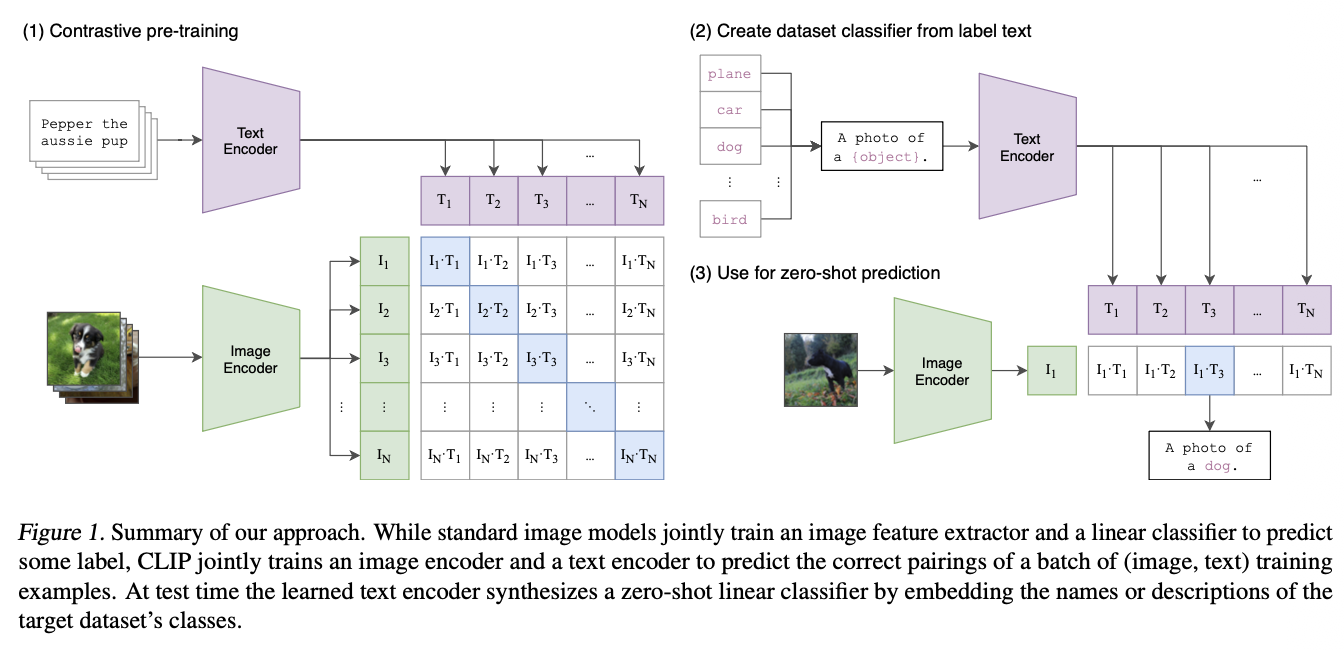
❖ 3. 모델 구조
CLIP의 전체 구조는 멀티모달 표현 학습(multimodal representation learning) 을 가능하게 하는 핵심 설계가 담겨 있음
-
모델은 크게 두 부분으로 구성됨:
- Image Encoder
- Text Encoder
-
이 두 인코더는 서로 다른 modality를 처리하지만 최종적으로 동일한 latent space로 매핑되도록 학습됨
◆ 3.1 Image Encoder
- CLIP은 이미지 인코더로 두 가지 아키텍처 선택지를 사용했음:
(1) ResNet 계열
- 기존 CNN 기반의 deep residual network이며 spatial inductive bias가 내장되어 있어 훈련 안정성 높음
- CLIP에서는 기존 ResNet 구조를 약간 수정하여 사용하였고 attention pooling 추가하여 feature aggregation 개선함
(2) Vision Transformer (ViT)
- 이미지를 patch 단위로 분해하여 Transformer로 처리하였으며 global receptive field를 갖기 때문에 다양한 구조적 패턴을 학습하기 유리함
- CLIP에서는 ViT-B/32, ViT-L/14 등 다양한 크기 실험을 하였고 결과적으로 ViT가 더 강력한 zero-shot 성능을 보여줌
◆ 3.2 Text Encoder
-
텍스트 인코더는 Transformer 기반 언어 모델이며 CLIP에서 사용한 것은 GPT 계열과 유사한 구조인
- 12-layer Transformer
- causal self-attention
- byte-pair encoding(BPE) tokenization
- 문장을 입력하면 문맥적 의미 표현을 생성
-
텍스트 T 에 대해:
-
문장의 마지막 토큰을 임베딩으로 사용하고 마찬가지로 L2정규화를 적용함
◆ 3.3 Shared Latent Space
-
CLIP의 핵심 설계 포인트는 이미지 임베딩과 텍스트 임베딩이 동일한 공간에서 비교 가능한 점임
-
이를 위해 학습 과정 전체에서 **두 임베딩을 동일한 의미 좌표계로 정렬함
-
cosine similarity 기반으로 positive pair는 가깝게 negative pair는 멀게 학습되며 이는 contrastive learning에 의해 이루어짐
◆ 3.4 Similarity Computation
- 이미지–텍스트 similarity는 다음과 같이 계산된다:
-
dot product 기반 cosine similarity
-
τ(temperature)는 모델이 학습하는 파라미터로 similarity distribution sharpness 조절 역할
-
이 similarity가 contrastive loss 계산의 핵심 입력이 됨
❖ 4. 학습 방법
CLIP의 학습 방식은 이미지와 텍스트를 동일한 의미 공간에 정렬시키는 contrastive learning임
- 배치 내에서 올바른 이미지–텍스트 쌍은 가깝게 나머지 잘못된 조합은 멀어지도록 학습함
◆ 4.1 Positive / Negative Pair 생성
-
Positive: 같은 이미지–텍스트 쌍
-
Negative: 같은 배치 내의 다른 모든 쌍
→ 별도의 negative sampling 없이 배치 전체가 자연스럽게 negative 풀 역할을 함
◆ 4.2 임베딩 & 유사도 계산
- 이미지와 텍스트를 각각 인코더로 임베딩한 뒤 L2 정규화하고 cosine similarity를 계산함
τ: temperature (유사도 분포를 조절)
◆ 4.3 양방향 Contrastive Loss
-
CLIP은 두 방향 모두 학습함
-
Image → Text : 이미지 기준으로 올바른 텍스트를 맞추기
-
Text → Image : 텍스트 기준으로 올바른 이미지를 맞추기
-
-
두 loss를 평균내어 최종 loss로 사용함
양방향 Contrastive Loss의 핵심은 정답 쌍의 similarity를 높이고 나머지는 softmax 분모로 밀어내는 구조인 것
◆ 4.4 학습 방법의 효과
- 이 방식으로 이미지와 텍스트는 공통 의미 공간 안에서 정렬됨
결과적으로 zero-shot 분류와 텍스트 기반 이미지 검색 가능해지며 task-specific fine-tuning 없이 여러 다운스트림 태스크에 활용 가능함
❖ 5. 실험 결과
-
CLIP의 실험 섹션은 단순히 정확도를 비교하는 수준이 아니라 자연어 기반 학습이 실제로 범용적이고 강력한지를 검증하는 데 초점이 맞춰져 있음
-
핵심적으로 봐야 할 결과는 다음 네 가지
◆ Zero-Shot Transfer
1) Zero-shot classification에서 기존 supervised 모델과 경쟁하는 성능
-
CLIP은 ImageNet을 포함한 다양한 데이터셋에서 fine-tuning 없이 zero-shot 방식으로 평가되었는데도 ImageNet zero-shot: 76.2% 의 성능을 보여줌
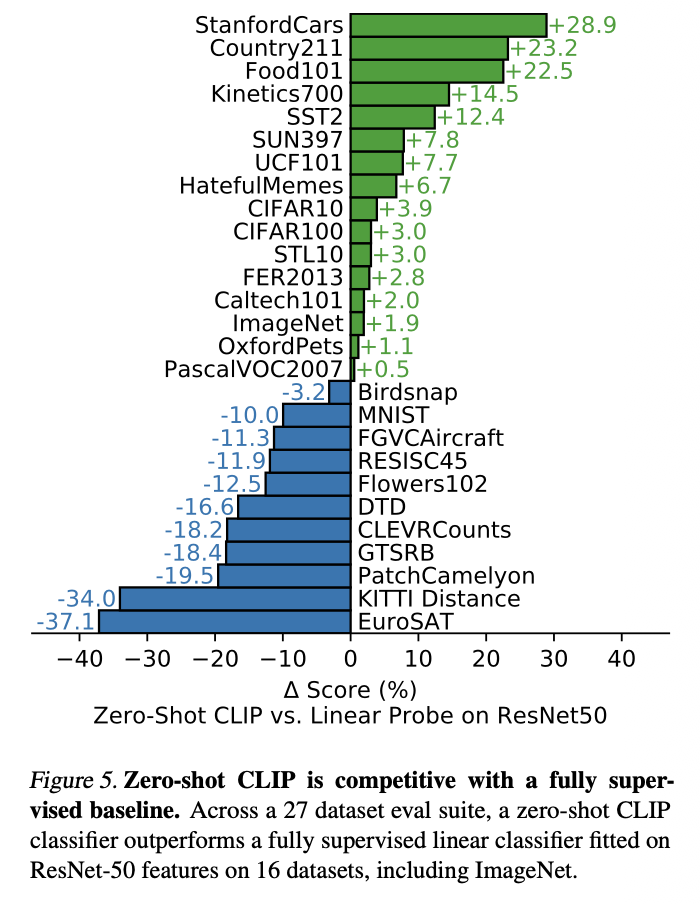
-
여러 benchmark average 성능이 기존 supervised ResNet 수준에 근접하였음
-
CLIP은 라벨 없이도 Supervised 모델과 비슷한 수준의 일반화 성능을 내었으며 이는 web-scale 자연언어 supervision의 효과를 명확히 보여줌
◆ Representation Learning
2) 27개 이상의 다양한 downstream task에서 강한 transferability
-
CLIP이 제안한 가장 중요한 기여 중 하나는 특정 task에 의존하지 않는 범용 시각 표현을
자연언어 기반 contrastive learning으로 얻을 수 있다는 점임 -
한 번 학습한 모델만으로도 이미지 분류, 세분화된 fine-grained recognition, 스타일 변환 이미지, 웹 이미지, 스케치, OCR-like 데이터 등 도메인과 분포가 크게 다른 총 27개 task에서 일관된 성능을 보임
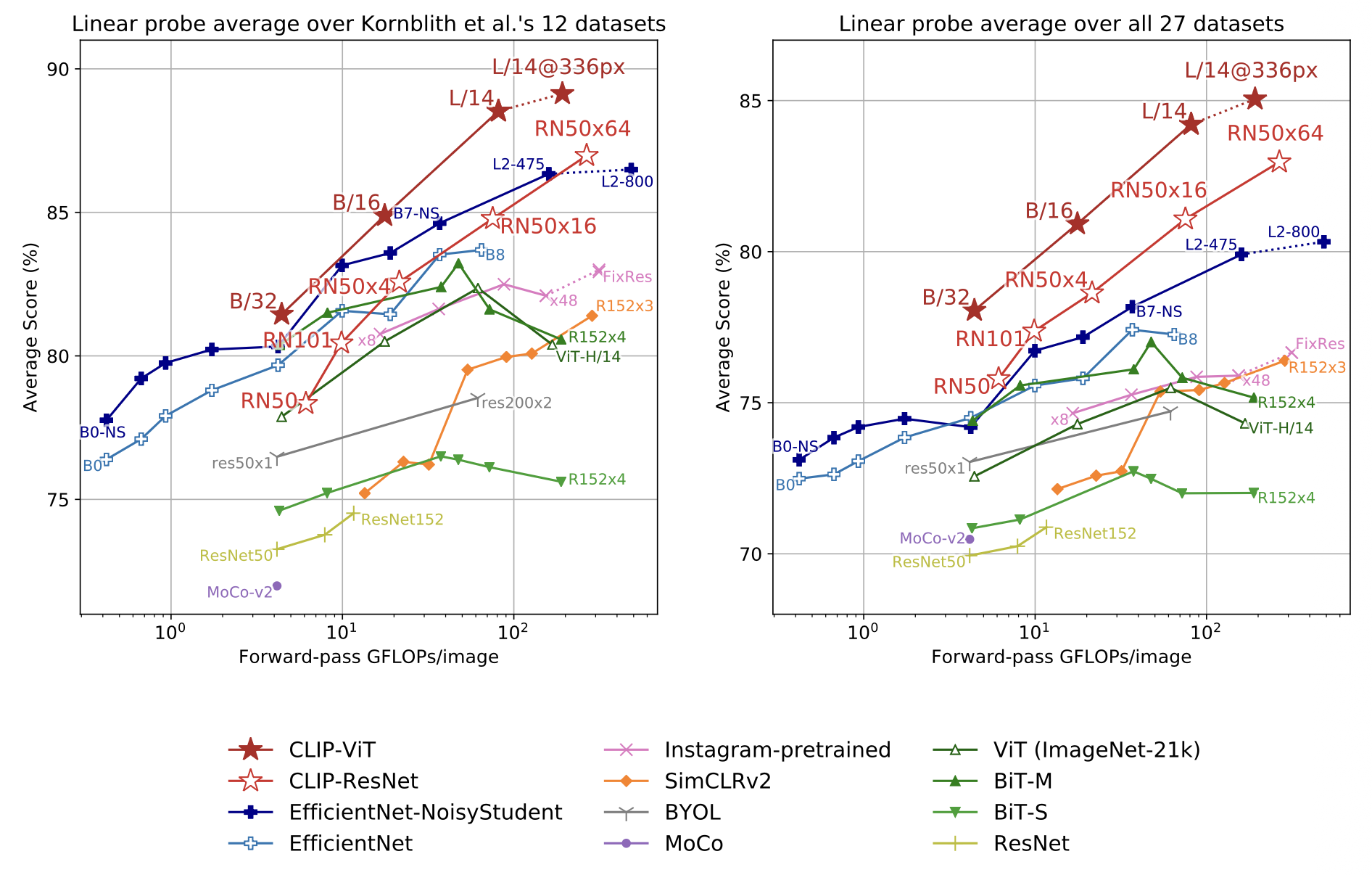
-
그래프는 CLIP을 기존 SOTA supervised 모델(EfficientNet, ResNet) 그리고 여러 self-supervised 모델(SimCLR, BYOL, MoCo)과 비교한 결과임
-
같은 연산량(GFLOPs)을 기준으로 했을 때 CLIP 계열(ViT/ResNet)은 대부분의 모델보다 consistently 더 높은 평균 성능을 기록하며 특히 CLIP-ViT/L14는 27개 task 평균 성능에서 EfficientNet-L, ResNet152x4, SimCLRv2 등 기존 강력한 모델들을 넘어섬
-
기존 supervised 모델은 특정 데이터셋에서 강하지만 도메인이 바뀌면 성능이 급격히 떨어지지만 CLIP은 웹 기반 이미지–텍스트 쌍 덕분에 domain shift에 매우 강함
◆ Robustness to Natural Distribution Shift
3) Domain shift 상황에서도 매우 강한 robustness
-
기존 supervised vision 모델은 학습한 분포를 벗어나면 성능이 급격히 하락하는 domain shift 문제를 가짐
-
ImageNet에서는 높은 정확도를 유지해도 조금만 스타일이 달라지거나 다른 출처의 이미지가 주어지면 성능이 크게 무너짐
-
CLIP은 이러한 한계를 극복한 대표적인 사례이며 Figure 13은 이를 가장 명확하게 보여주는 핵심 실험임
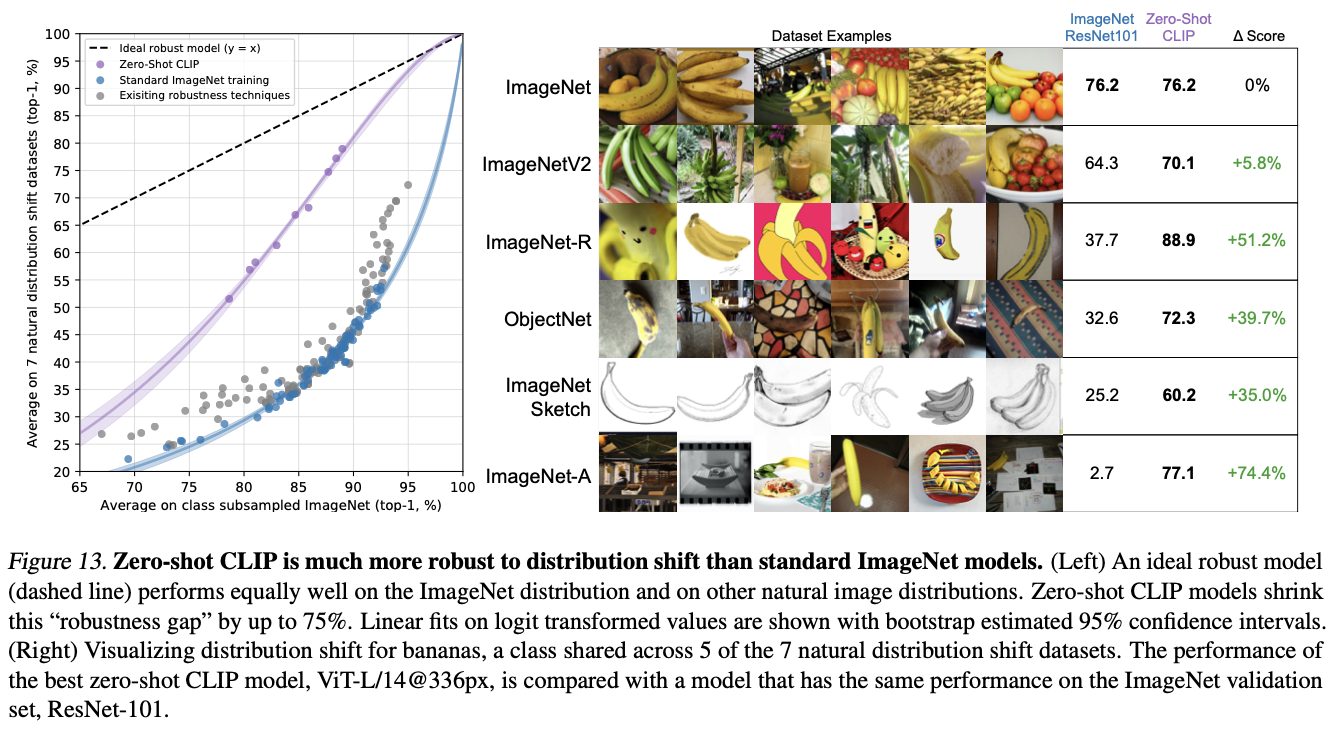
왼쪽 그래프의 해석
-
CLIP의 견고함을 수치로 증명
- x축: ImageNet에서의 정확도
- y축: ImageNet 변형·파생 데이터셋들(총 7개)에서의 평균 정확도
-
ImageNet에서 똑같은 성능이라면 실제 환경에 가까운 다른 데이터셋에서 얼마나 성능이 유지하는지를 시각적으로 비교하는 그래프임
-
ResNet101(파란색)은 ImageNet에서는 76%지만 domain shift 데이터셋에서는 35~40%대까지 급락하는 것을 볼 수 있음
-
반면 Zero-shot CLIP(보라색)은 ImageNet 성능이 동일한 수준임에도 다른 이미지 분포에서도 훨씬 높은 성능 유지함
오른쪽 테이블 해석
-
실제 데이터셋 기준으로 확인한 robustness
-
오른쪽 표는 ‘바나나’ 이미지처럼 같은 클래스지만 분포가 매우 다른 예시를 통해 robustness를 직접 비교함
-
같은 ‘바나나’ 클래스임에도, 사진 스타일이 조금만 바뀌면 ResNet은 거의 성능이 사라지지만 CLIP은 의미 단위로 이해하기 때문에 성능이 지속됨
-
이것은 CLIP이 단순 pixel-level pattern 매칭이 아니라 텍스트와 연결된 semantic representation을 학습했기 때문에 가능한 결과임
❖ 6. 마무리
-
CLIP은 이미지와 텍스트라는 두 모달리티를 대규모 웹 데이터에서 직접 학습함으로써 기존 supervised vision 모델이 가진 구조적 한계를 근본적으로 재해석한 연구임
-
라벨에 의존하지 않는 자연언어 기반의 supervision은 모델이 특정 task에 종속되지 않도록 만들고 contrastive learning은 두 표현을 의미 공간에서 정렬하여 범용적인 multimodal representation을 형성함
-
실험 결과는 이러한 접근이 단순한 아이디어 수준이 아니라 실제로 zero-shot 성능, downstream transferability, domain shift robustness에서
기존 SOTA 모델들을 넘어서는 강력한 효과가 있음을 명확히 보여줌 -
특히 prompt engineering과 few-shot adaptation 실험은 CLIP이 고정된 모델이 아니라 사용자가 어떤 텍스트와 어떤 방식으로 상호작용하느냐에 따라 성능과 표현 해석이 유연하게 조정될 수 있는 모델임을 보여줌
-
CLIP은 단순한 비전 모델이 아니라 언어를 통해 시각을 이해하는 새로운 패러다임을 제시했고 이후의 LLaVA, BLIP-2, GPT-4V 등 현대 멀티모달 모델들의 토대를 제공함
❖ 7. 논문 후기
-
지금까지는 주로 추천 시스템이나 자연어 처리처럼 단일 모달 모델에 초점이 맞춰진 논문들을 리뷰해왔지만하 실제 연구실이나 최신 연구 흐름을 보면 이제는 대부분의 모델이 멀티모달 구조를 기반으로 확장되고 있고 단일 모달만 이해해서는 전체 흐름을 따라가기 어렵다는 생각이 들었음
-
CLIP은 이미지와 텍스트를 결합해 의미 공간에서 정렬시키는 방식으로 현대 멀티모달 모델의 기반을 만든 논문이라 멀티모달을 공부하는 데 있어 좋은 출발점이라고 느꼈으며 이번 논문을 시작으로 앞으로는 멀티모달 모델이 어떻게 발전해왔는지 그 흐름까지 이어서 정리해보고자 함
논문 만족도 : ⭐️⭐️⭐️ (현대 멀티모달 모델의 기반에 대하여 배울 수 있어서 좋았음)
논문 이해도 : ⭐️⭐️⭐️⭐️ (멀티모달 개념 자체가 어렵게 느껴지지는 않았으며 constrastive learning 또한 저번 CL4SRec에서 리뷰한 내용이여서 어렵게 다가오지는 않았음)
멀티모달 관심도 : ⭐️⭐️⭐️ (실제 연구실이나 최근 연구 흐름은 대부분이 멀티 모달 구조를 기기반인데 이를 이해하기 위해서는 관심을 갖기 시작하는게 좋아보임)
