
논문 원본 : https://arxiv.org/abs/2005.14165
❖ 논문 선정 이유
- 지난 리뷰에서 Attention Is All You Need 논문을 통해 Transformer 구조를 살펴봤고 이 모델이 이후 BERT와 GPT 계열 모델에 큰 영향을 주었다는 점을 확인했으며 BERT는 Transformer Encoder 기반, GPT는 Decoder 기반으로 발전해왔는데 이번에는 그 연장선에서 GPT 계열 모델 중 중요한 전환점이 된 GPT-3 논문을 선택함
- 특히 GPT-3는 기존처럼 task별 fine-tuning을 수행하는 방식이 아니라 프롬프트만으로 다양한 작업을 수행할 수 있다는 흐름을 만든 pivot 모델이라는 점에서 흥미가 생겨 리뷰하게 됨
❖ GPT-2 vs BERT
◆ Transformer
-
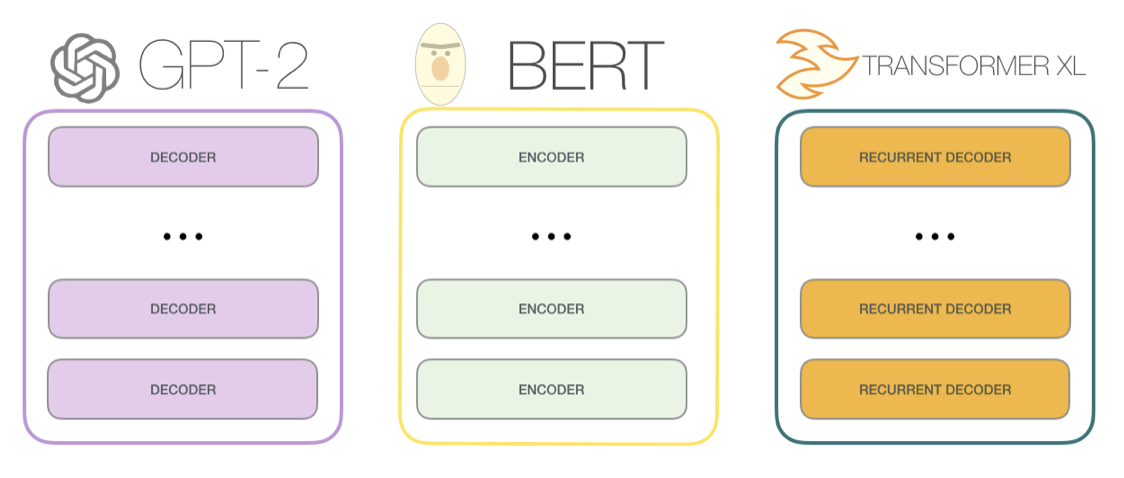
최초의 transformer 모델은 encoder와 decoder로 구성되어 있음
-
각각은 우리가 transformer 블록이라고 부르는 것들을 쌓아놓은 것이며 아키텍처는 원래 기계 번역 용도로 적합했으며 encoder-decoder 아키텍처가 과거에는 성공적이었음
-
GPT-2는 transformer의 decoder 블럭으로 구성되었고 반대로 BERT는 transformer의 encoder 블럭을 사용함
◆ BERT
-
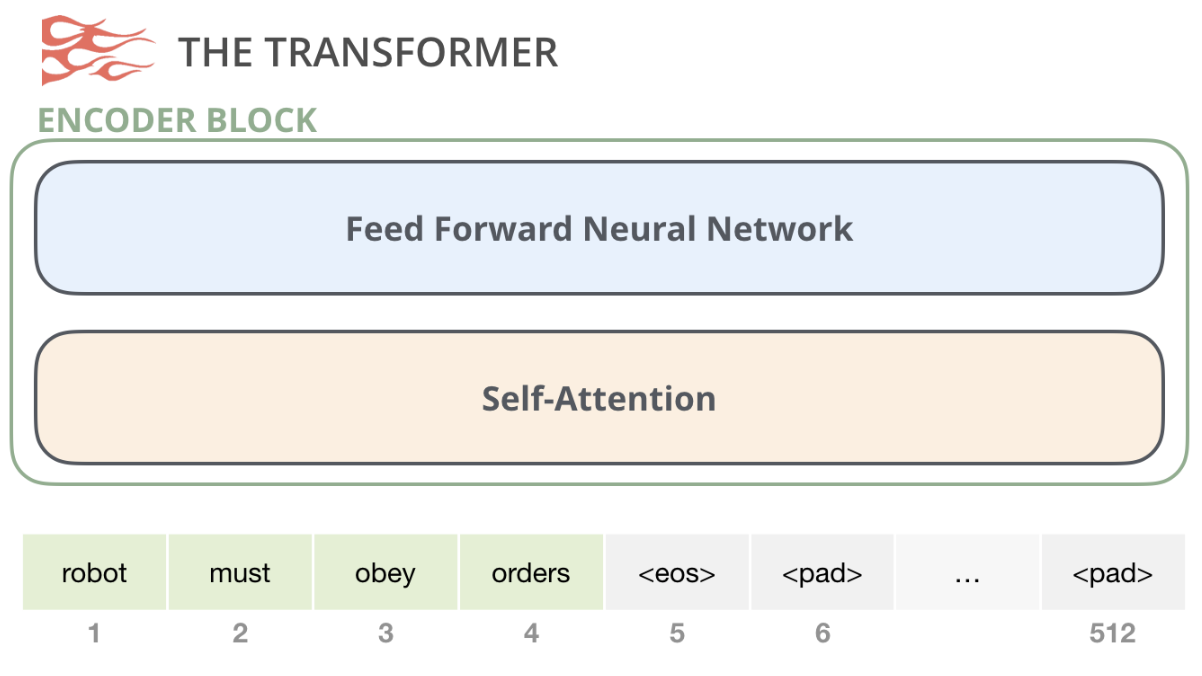
BERT는 Transformer의 Encoder 구조를 기반으로 만든 언어 모델로, 가장 큰 특징은 문장을 양방향으로 동시에 이해한다는 점임
-
기존의 GPT나 Word2Vec처럼 단방향 문맥만 보는 모델과 달리 BERT는 단어 앞뒤 문맥을 모두 활용해 더 정확한 의미 표현을 학습함
-
BERT는 두 가지 self-supervised task를 사용해 학습됨 :
-
Masked Language Modeling (MLM)
문장에서 일부 단어를 [MASK]로 가리고
→ 모델이 해당 단어를 맞히는 방식 -
Next Sentence Prediction (NSP)
두 문장이 실제 연속된 문장인지, 아니면 랜덤으로 이어 붙인 문장인지 예측
→ 문장 간 관계 학습
-
BERT는 Transformer Encoder 기반의 양방향 언어 모델로 문맥 이해 능력을 극대화해 NLP 성능의 기준을 크게 끌어올린 모델
◆ GPT-2
-
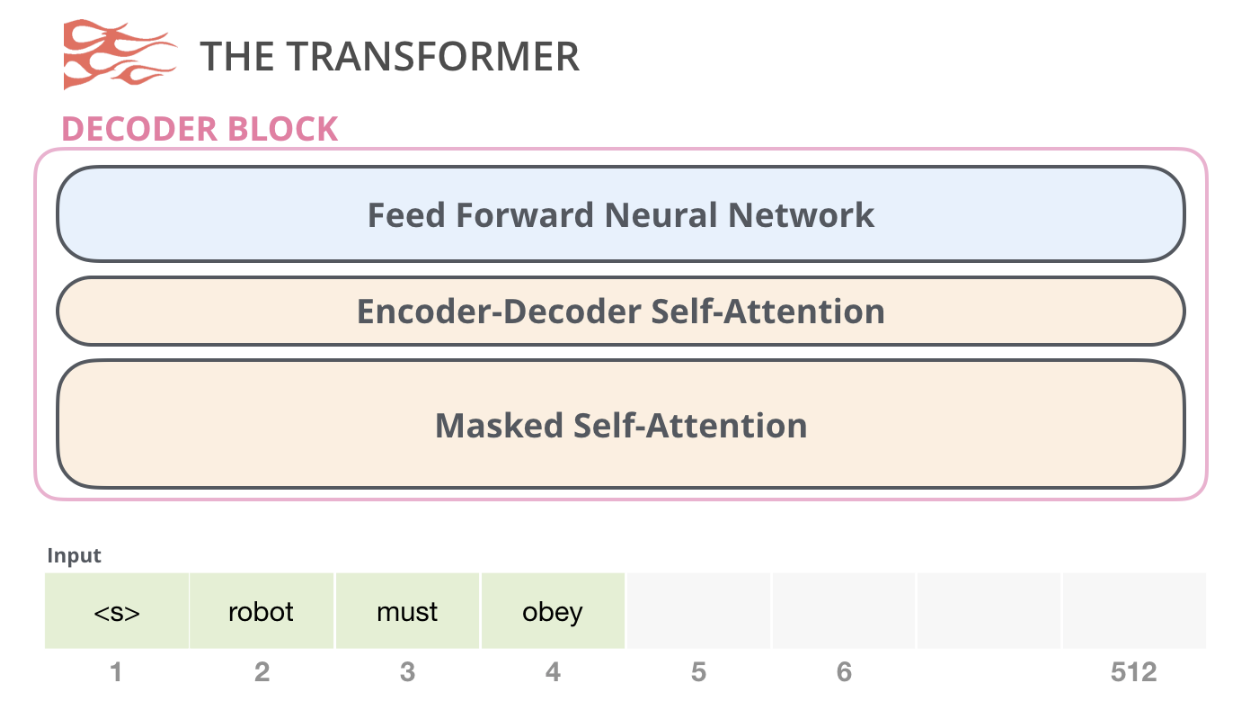
GPT-2는 Transformer Decoder 구조 기반의 autoregressive 언어 모델로, 텍스트를 왼쪽 → 오른쪽 방향으로 생성하는 특징을 가짐
-
이 모델은 문장을 이해하는 것보다 문장을 자연스럽게 이어 쓰는 것에 강점이 있음
-
GPT-2는 단 하나의 task로 학습됨:
- Next Token Prediction (언어 모델링)
→ 주어진 문맥을 기반으로 다음 단어를 예측
- Next Token Prediction (언어 모델링)
GPT-2는 Transformer Decoder 기반 언어 생성 모델로 자연스러운 문장 생성 능력을 통해 LLM 시대의 가능성을 보여준 모델
정리
- Transformer는 설계 구조
- BERT는 이해에 최적화된 Encoder 기반 모델
- GPT는 생성에 최적화된 Decoder 기반 모델
❖ GPT-2 구조
-
GPT-2는 Transformer Decoder 구조를 기반으로 한 언어 생성 모델이며 입력된 토큰 시퀀스를 바탕으로 다음에 올 단어의 확률을 예측하는 방식으로 학습됨
-
이 과정이 그림에 표현된 구조 안에서 단계적으로 이루어짐
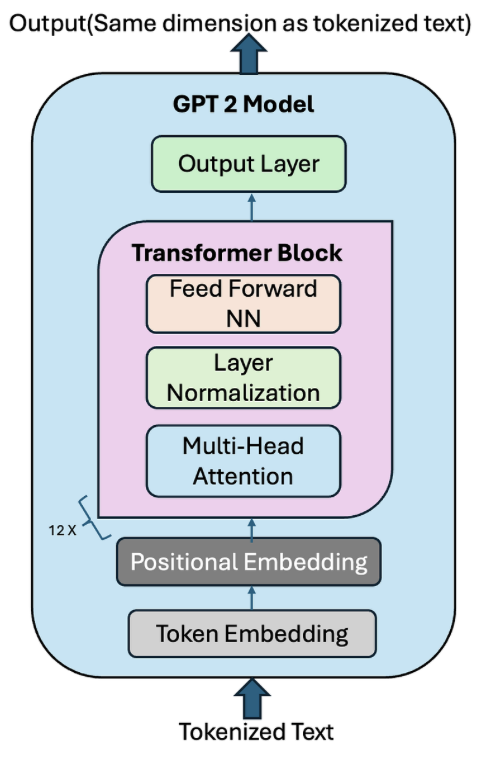
1. Token Embedding
-
처음 입력되는 데이터는 자연어 문장이 아니라 토큰화된 숫자 시퀀스임
-
GPT-2는 BPE(Byte Pair Encoding) 기반 토크나이저를 사용하여 약 50k vocabulary를 가지고 각 토큰은 고정된 차원의 벡터로 변환되며 이 벡터가 모델의 최초 입력 표현이 됨
-
텍스트 → 숫자 ID → 벡터 순으로 의미 정보가 치환됨
2. Positional Embedding
-
Transformer는 순서를 이해하지 못하기 때문에 모델이 단어의 순서를 학습할 수 있도록 위치 정보를 더해줬었는데 GPT-2는 학습 가능한 학습형 positional embedding(learnable)을 사용함
-
h0=TokenEmbedding+PositionalEmbedding 과 같은 방식으로 초기 표현을 만듦
3. Transformer Block (× 12)
-
(1) Multi-Head Masked Self-Attention
-
단어 간 관계를 고려해 표현을 업데이트하는 연산이지만 GPT-2는 미래 단어를 미리 볼 수 없도록 Masking을 적용함
-
토큰 t는 t보다 오른쪽에 있는 토큰에 attention을 줄 수 없으며 이는 GPT-2가 Autoregressive LM이라는 성격을 그대로 반영하는 것임
-
-
(2) Layer Normalization
-
Self-Attention 연산 후 결과를 안정화하고 학습 수렴 속도를 높이기 위해 LayerNorm을 적용함
-
GPT-2는 특히 Pre-LayerNorm 구조를 사용하는데 이는 깊은 네트워크 학습 시 gradient 안정화에 기여함
-
-
(3) Feed-Forward Neural Network (FFN)
-
Self-Attention으로 얻은 표현을 비선형 변환하여 모델의 표현력을 확장하는 부분임
-
GPT-2는 GELU 활성 함수를 사용하며 이 FFN 또한 Residual connection을 가짐
-
4. Output Layer
- Transformer Blocks를 통과한 최종 hidden state는 Linear + Softmax를 통해 다음 토큰이 무엇일지에 대한 확률 분포로 변환됨
5. Autoregressive 생성 방식
- 모델 추론은 입력 시퀀스를 모델에 넣은 후 Softmax 결과에서 가장 가능성이 높은 토큰 선택하고 그 토큰을 다시 입력에 append하여 원하는 길이가 될 때까지 반복함
→ 모델이 단어를 하나씩 생성하며 문장을 이어가게됨
정리
| 구성 요소 | 역할 | GPT-2 특성 |
|---|---|---|
| Token Embedding | 텍스트 → 벡터 변환 | BPE 기반 |
| Positional Embedding | 순서 정보 학습 | Learnable |
| Multi-Head Masked Attention | 문맥 의존 표현 학습 | 미래 토큰 접근 차단 |
| FFN | 비선형 표현 확장 | GELU |
| Output Layer | 다음 토큰 확률 생성 | Autoregressive |
❖ GPT-3
GPT-3는 GPT-2 구조는 그대로 유지하되 파라미터 수와 (1.5B → 175B), 데이터 규모, 컨텍스트 길이를 증가한 스케일만 확장시킨 모델임
- 이는 새로운 구조나 알고리즘을 제안한 모델이 아니라 규모가 성능을 결정한다는 가설을 실험적으로 검증한 모델임
◆ GPT-3의 구조 개요
-
GPT-3의 아키텍처는 다음과 같다:
- Decoder-Only Transformer
- Pre-LayerNorm 구조 유지
- GELU activation 사용
- Masked Self-Attention 기반 autoregressive generation
-
기본 흐름은 GPT-2와 동일하지만 GPT-3는 모델 크기에 따라 block 수, hidden size, attention head가 크게 증가함
| 모델 이름 | 파라미터 | Layers | Hidden Dim | Heads |
|---|---|---|---|---|
| GPT-2 Large | 1.5B | 36 | 1280 | 20 |
| GPT-3 (max) | 175B | 96 | 12288 | 96 |
❖ Few-Shot Learning
GPT-3가 GPT-2와 가장 다르게 만든 부분은 학습 방식이 아니라 활용 방식임
-
GPT-2 시대까지의 흐름
- Pretraining → Fine-tuning → Task-specific 모델
-
GPT-3가 제시한 새로운 패턴
- Pretraining → Prompting → 다양한 Task 실행
-
모델을 다시 학습시키는 것이 아니라 입력 프롬프트만으로 task 수행 능력이 나타남
-
GPT-3는 아래 3가지 모드에서 실험을 진행함
◆ In-Context Learning
-
GPT-3의 가장 큰 기여는 모델이fine-tuning 없이 단지 입력 프롬프트의 맥락(context)만 보고 새로운 작업을 수행할 수 있다는 것임
-
모델의 파라미터는 업데이트되지 않지만 프롬프트 안에 포함된 예시를 보고 즉석에서 task를 학습한 것처럼 행동하는 이 방식이 바로 In-Context Learning(문맥 기반 학습)이고,
GPT-2에서 GPT-3로 넘어가며 가장 큰 패러다임 전환을 만든 요소임
Zero-Shot Learning
- Zero-shot에서는 모델에게 단지 task가 무엇인지 설명만 제공함
Translate English to French:
cheese =>-
모델은 예제를 보지 못하며 "task가 무엇이다" 라는 지시문만 기반으로 답을 생성해야 하며 모델 내부에 이미 학습된 일반화 능력을 활용함
-
GPT-3는 사전학습에서 충분히 다양한 데이터를 접했기 때문에 번역을 해야한다는 것을 인지함
One-Shot Learning
- One-shot에서는 task 설명 + 예제 하나가 함께 제공됨
Translate English to French:
sea otter => loutre de mer
cheese =>-
여기서 GPT-3는 첫 번째 예제를 보고 입력형식(pattern)을 추론하고 그 패턴을 따라 새로운 입력에 대해 결과를 생성함
-
예제 하나만 보고 규칙을 일반화함
Few-Shot Learning
- Few-shot에서는 task 설명 + 여러 개의 예시가 함께 주어짐
Translate English to French:
sea otter => loutre de mer
peppermint => menthe poivrée
plush giraffe => girafe peluche
cheese =>-
여러 개의 예시가 포함되면 모델은 출력 형식,문장 구조,domain-specific, 표현 방식 등을 더 잘 파악할 수 있게 되어 성과가 가장 안정적으로 향상됨
-
GPT-3 논문에서 특히 Few-shot 세팅이 기존 fine-tuned 모델을 능가하는 경우가 있었으며 이 점이 GPT-3 연구의 가장 획기적인 결과였음
❖ Experiment
-
LAMBADA를 사용하여 테스트 진행함
-
LAMBADA (LAnguage Modeling Broader Discourse Analysis) 데이터셋은
문맥 기반 언어 이해 능력을 평가하기 위해 만들어진 언어모델 벤치마크임 -
특징은 단순한 다음 단어 예측이 아니라 문장 전체를 읽어야 마지막 단어를 정확하게 예측할 수 있도록 설계된 cloze-style dataset이라는 점임
-
◆ In-Context Learning 지표화 (Table3.2)
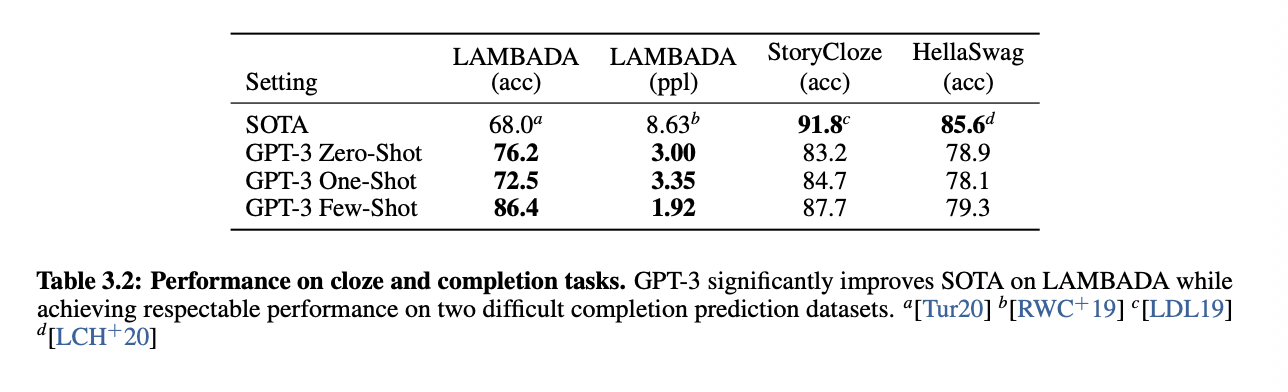
-
Table 3.2와 그래프는 GPT-3 모델이 기존 SOTA 모델을 압도하며 특히 Few-Shot 설정에서 성능이 크게 향상됨을 보여줌
-
표를 보면 GPT-3의 성능은 Few-Shot > Zero-Shot > One-Shot 순서로 나타나며 중요한 점은 GPT-3 Few-Shot(86.4%)가 기존 최고 모델보다 약 18.4% 향상되며 압도적인 성능을 보임
-
이는 기존 연구들이 fine-tuning된 task-specific 모델임에도 불구하고 GPT-3는 추가 학습 없이 단지 프롬프트만으로 더 높은 성능을 냈다는 의미임
◆ Scaling Law 시각화 (Figure 3.2)
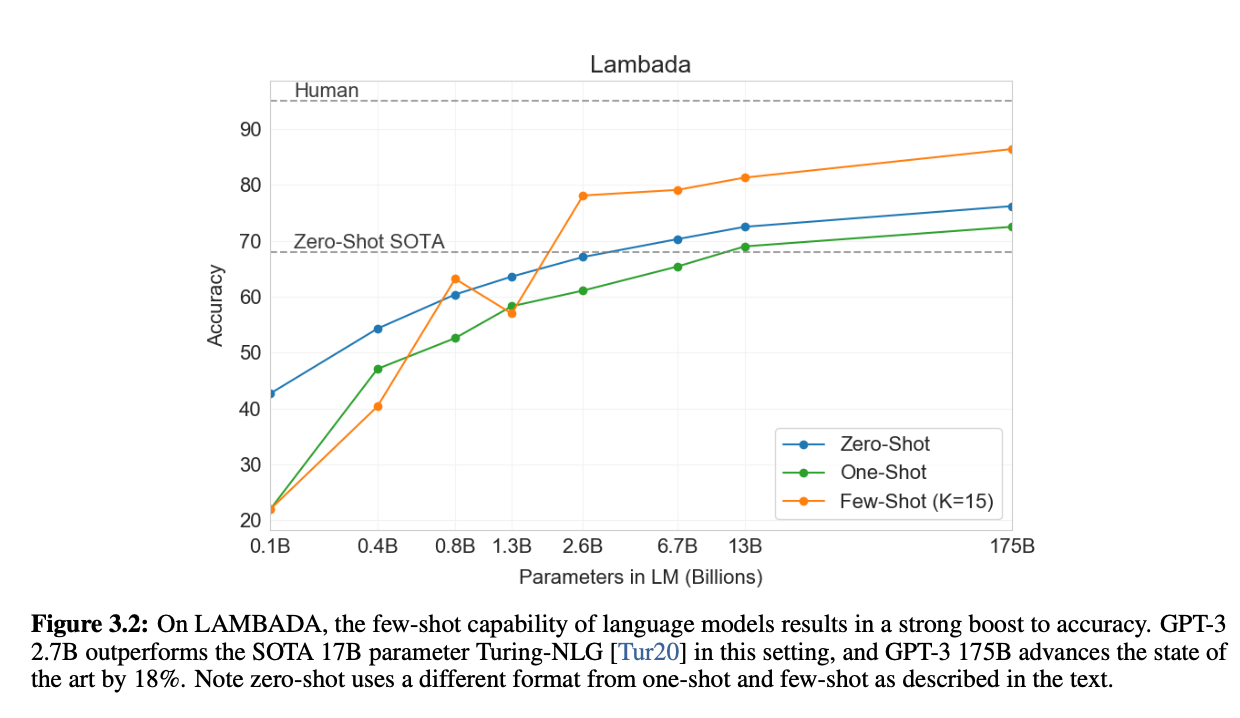
-
그래프는 모델 크기(parameter 수)가 커질수록 성능이 자연스럽게 증가하는 모습을 나타냄
-
0.1B → 175B로 커질수록 성능은 거의 단조 증가하였고 작은 모델(1.3B 이하)에서는 Zero-shot, One-shot, Few-shot 차이가 크지 않지만 13B 이상부터 Few-Shot 성능이 눈에 띄게 상승함
-
175B 모델에서 인간 수준(human baseline)에 근접하였고 이는 Few-shot 능력은 작은 모델에서는 나타나지 않고 일정 규모 이상을 넘어서면서 emergent property(창발적 특성)로 나타난다는 것을 알 수 있음
모델의 능력은 모델 구조가 아니라 규모에서 나옴을 증명함
❖ GPT-3 한계
- GPT-3는 강력한 성능을 보여주지만, 크게 6가지 한계가 존재함
1. 언어 생성 품질 문제 (Coherence & Repetition)
- 긴 문단에서는 일관성 저하, 논리 비약, 자기모순이 나타나며 의미 반복, 문맥 깨짐, 앞뒤 문장 연결 실패까지 발생함
2. 특정 추론에서 취약 — 상식·비교 추론 등
-
GPT-3는 상식 물리(Common sense physics), 의미 비교(Word-in-Context, WIC), 일부 독해(QuAC, RACE)에서 성능이 낮은 것을 보였음
-
GPT-3는 이해보다 언어 패턴 암기에 가깝기 때문
3. 구조적 제약 — Decoder-Only라 생기는 문제
-
GPT-3는 전적으로 Autoregressive LM으로 양방향 encoding이 없가 때문에
빈칸 채우기, 두 문장 비교,과거 문장을 다시 해석하며 답해야 하는 문제들에 약한 모습을 보임 -
미래 토큰을 못 보기 때문에 필요한 정보 접근이 제한되기 때문
4. LM Objectives의 근본적 한계
- GPT-3는 모든 토큰을 동일 비중으로 예측하는 self-supervised objective인데 이는 중요 정보에 대한 우선순위 없음
5. Pretraining Sample Efficiency 부족
- 인간보다 훨씬 많은 데이터를 봐야 그나마 generalization 가능하고 엄청난 양의 데이터를 학습했어도 완벽하지 않음
6. 비용, 편향, 안전성 문제
-
비용·추론 속도 너무 커서 inference가 느리고 비싸고 모델의 판단 근거가 불명확함
-
데이터 편향 그대로 반영할 수 있어서 부적절한 답변 출력 위험이 있음
GPT-3는 규모 확장의 힘을 보여줬지만 이해, 추론, 현실 grounding, 안전성, 효율성 측면에서 여전히 해결해야 할 문제들이 많음
❖ Conclusion
-
GPT-3는 단순히 모델 크기를 크게 확장한 것만으로도 기존 NLP task에서 zero-shot·one-shot·few-shot 설정 모두에서 의미 있는 성능 향상을 보여주었고, 특히 few-shot 설정에서는 여러 benchmark에서 기존 SOTA를 넘어섬
-
또한 GPT-3는 fine-tuning 없이도 다양한 task를 수행하는 범용 모델 가능성을 보여줬으며 이는 기존의 task-specific 모델 학습 방식에서 벗어나 프롬프트 기반 학습 (Prompting)과 in-context learning을 NLP의 새로운 접근법으로 제시함
-
결론적으로, GPT-3는 언어 모델이 단순히 단어 예측기가 아니라 기능적 지능을 가진 foundation model로 발전할 수 있음을 실험적으로 처음 입증한 모델이라는 점에서 의의가 큼
❖ 논문후기
-
Attention Is All You Need 논문을 먼저 읽고 Transformer 구조를 이해한 뒤에 이 구조를 기반으로 발전한 BERT와 GPT 모델들을 비교해보니 흐름이 훨씬 명확하게 잡혔음
-
BERT는 Encoder만, GPT는 Decoder만 사용해 각각 다른 방향으로 발전해왔다는 점이 흥미로웠고 이후 버전들이 어떤 한계를 보완하며 진화했는지 단계적으로 살펴보니 모델 발전의 논리가 자연스럽게 이해되었음
-
현재는 GPT-5까지 등장하며 빠르게 혁신이 이어지고 있는데 이렇게 모델 계열의 역사와 설계 의도를 하나씩 따라가며 정리해보는 과정이 앞으로 LLM 관련 연구를 진행할 때 큰 기반이 될 것 같음
-
이번 리뷰 역시 읽기 → 이해하기 → 비교하기 과정의 중요성을 다시 느낀 시간이었고 앞으로도 이런 방식으로 한 단계씩 쌓아가고자 함
논문 만족도 : ⭐️⭐️⭐️ (GPT-2 -> GPT-3의 발전된 부분들을 이해하기 좋았지만 논문의 양이 너무나 길어서 전체를 읽진 못함)
논문 이해도 : ⭐️⭐️⭐️ (핵심적인 부분들은 이해하였지만 논문의 양이 너무 길어서 100% 흡수한지는 모르겠음)
LLM 관심도 : ⭐️⭐️⭐️⭐️ (추천시스템과 LLM 두개를 가장 관심있게 공부할 계획)
