추천(영어)
한글
- https://littlefoxdiary.tistory.com/74
- https://housekdk.gitbook.io/ml/ml/computer-vision-transformer-based/zero-shot-text-to-image-generation-dall-e
왜 자꾸 정리해놓은 글이 저장이 안 되는 걸까 ㅎㅎ..
1. Positional Embeddings은 text의 경우 1d, image의 경우 2d(row/column) embeddings을 사용.
2. Transformer decoder -> VAE decoder
해당 모델은 Transformer Decoder 뒤에 VAE의 Decoder가 붙는 구조.
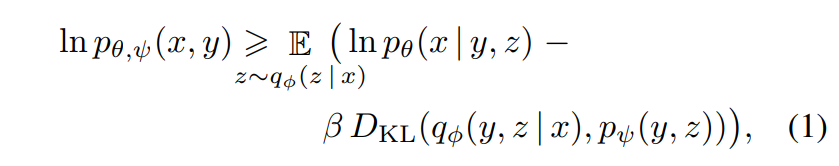
물론 Stage 2 학습에서는 tokens의 결합 사전 분포만 학습하긴 하지만(그냥 Decoder-only Transformer 학습), 엄밀히 따지면 Loss는 ELBO를 최대화하는 방향으로 학습이 진행된다고 한다.
In the second stage, we fix φ and θ, and learn the prior
distribution over the text and image tokens by maximizing
the ELB with respect to ψ. Here, pψ is represented by a
12-billion parameter sparse transformer
하지만 나는 위의 말이 이해가 가지 않는다. 일반 GPT처럼 Autoregressively하게 학습 되는 걸로 이해하고 있었는데, 갑자기 ELB를 최대화하게끔 Transformer를 학습한다니..
이미지 를 latent vector 로 압축하는 인코더나, 를 이미지로 복원하는 디코더는 학습하지 않음.
The image tokens are obtained using argmax sampling from the dVAE encoder logits
(트랜스포머 학습 당시에 필요한 image token은 dVAE로부터 얻는다.
Finally, the text and image tokens are concatenated and
modeled autoregressively as a single stream of data
(그 후 concat되어 autoregressively하게 트랜스포머로 처리된다.)
또한 text token에 대한 가중치는 1/7, image token에 대한 크로스 엔트로피 가중치는 7/8로 설정해 진행한다고 한다.
we multiply the cross-entropy loss for the text by 1/8 and the
cross-entropy loss for the image by 7/8.
여기서 말하는 크로스 엔트로피는 ELB에서의 Transformer term과 큰 상관이 없지 않나? 즉, Transformer가 내뱉는 target token의 cross entropy일 것이다.
결론적으로, ELB를 최대화하는 Transformer가 뭘까 ㅎㅎ..
아무튼,
DALL-E PYTORCH(github, not offical)
에 잘 나와있긴 하다.
기존의 생각처럼 그냥 GPT task를 수행하는 것 같은데, 그 결과가 ELB를 최대화하는 방향으로 흘러가는 것이겠거니(Token을 더 잘 뽑아내므로) 생각하고 넘어가자.
추가적으로 아래의 연구를 참고했는데, 대강 흐름 잡는 데는 도움이 되는 듯 하다.
GPT
Sparse Transformer
Transformer VAE
