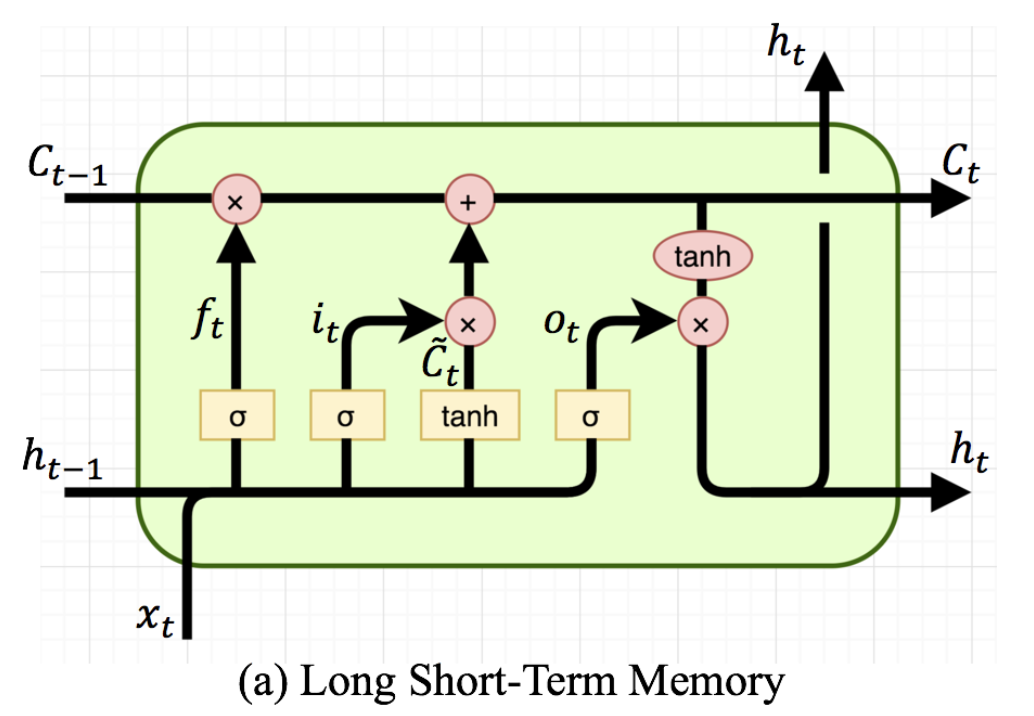
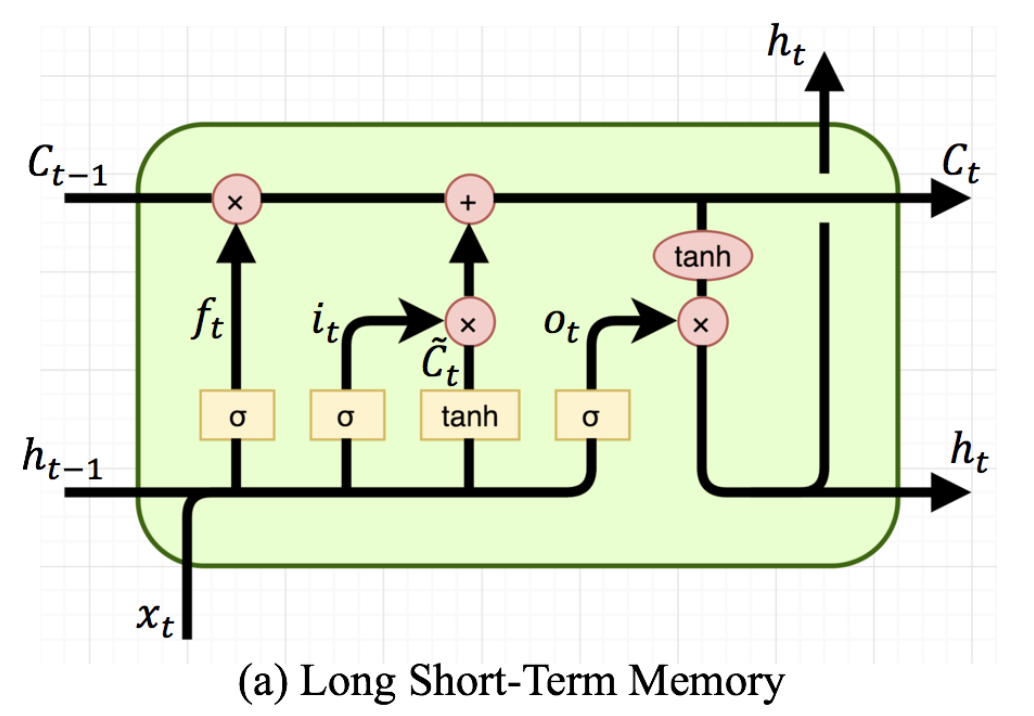

위와 같이 LSTM의 기본적인 식이 나와 있습니다.
이 때, data를 하나라고 가정하고, data의 sequence는 100차원이라 가정합시다.
그러면, 위의 값들은 결국 모두 vector가 되며, 가중치 에 해당하는 term만 matrix가 됩니다.
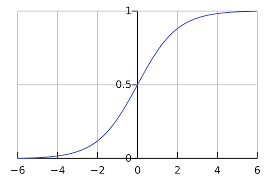
이 때, 는 sigmoid함수로, 입니다.
LSTM에서는 hidden 이 short-term memory로 여겨집니다. 즉, 은 과거의 hidden state이고, 는 현재의 input입니다.
- : input gate 에서는, 와 이 연산된 후, 를 통과해 사이의 값 vector를 반환합니다.
- 이 때, 의 크기는 , sequence 의 크기는 이라 가정할 수 있습니다. 도 마찬가지로 의 size를 가져 최종적인 결과 또한 의 size를 갖습니다.
- , : 각각 forget gate, output gate로, input gate와 유사한 연산을 거칩니다.
- : 위의 그림에서는 에 해당하는 term으로, 과거의 cell state 과 대비되는, 현재의 임시 cell state라고 볼 수 있습니다. 역시 현재의 hidden state에 해당하는 와 과거의 hidden state인 과의 연산을 한 후, 를 거쳐 사이의 값을 반환합니다.
그 후,
- : 과거의 cell state 을 forget gate 를 통해 일정 비율만 받아들이고, 현재의 임시 cell state ()를 input gate 를 통해 일정 비율만 받아들여, 최종적인 현재의 cell state 를 반환합니다.
최종적으로,
- : 현재의 cell state 에 nonlinear 를 적용시켜준 뒤, output gate 를 통해 현재의 hidden state 를 결정해줍니다.
일반적으로 딥러닝 내 연산은 아래와 같습니다.
이 때, 를 먼저 쓰는 이유는 batch 때문입니다.
예를 들어, 데이터가 1만개 있다고 가정해봅시다(각 데이터는 100 dim sequence).
그러면, 전체 데이터 셋 는 입니다.
이 때, batch size를 10이라 가정하면, mini-batch 내의 학습데이터 은 입니다.
그러면, 매트릭스 연산에서는 실제로 미니배치 이 한 번에 들어와,
일 때,
으로 연산이 됩니다. 즉, 위의 숫자 은 굉장히 가변적이기 때문에, 가 먼저 와야 연산할 수 있습니다.
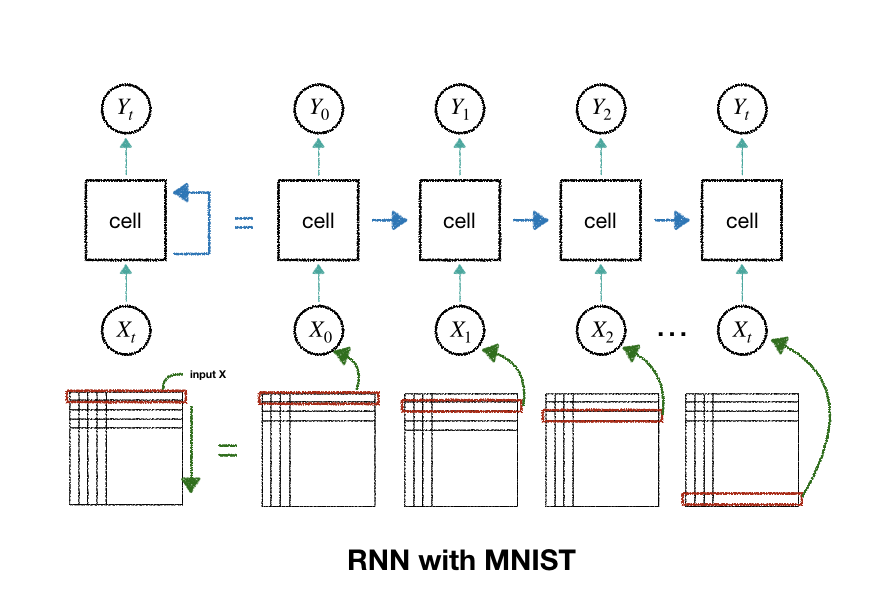
LSTM for mnist
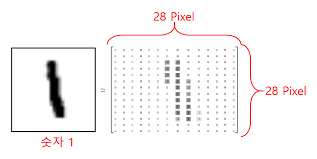
Mnist는 아래와 같이 의 image로 되어 있습니다.
이는, 28차원의 dimension(세로)을 갖는 28차원의 sequence(가로)로 해석할 수 있습니다.
즉, 이미지를 Time Sequence로 바라보고 LSTM을 적용하겠습니다
이 때, 위의 time step 별 output 는 각 time step에서 반환하기로 한 에 해당합니다.
디바이스, 하이퍼파라미터 설정
이에 대해 아래와 같이 디바이스와 하이퍼파라미터를 설정할 수 있습니다.
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
device = torch.device('cuda' if torch.cuda.is_available else 'cpu')
print('device : ', device)
# 하이퍼 파라미터
sequence_length = 28
input_size = 28
hidden_size = 128
num_layers = 2
num_classes = 10
batch_size = 100
num_epochs = 2
learning_rate = 0.01데이터셋 불러오기
# MNIST dataset
train_dataset = torchvision.datasets.MNIST(root = '../../data',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = torchvision.datasets.MNIST(root = '../../data',
train=False,
transform=transforms.ToTensor())
# 데이터 로더
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size = batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset,
batch_size = batch_size,
shuffle=False)
torchvision이 제공하는 dataset은 torch.utils.data.Dataset을 상속하기 때문에 torch.utils.data.DataLoader로 전달될 수 있습니다.
RNN 클래스 정의(특히 LSTM)
이 때, RNN은 굉장히 넓은 개념이기 때문에 클래스 이름은 RNN으로 정했습니다. RNN 내부의 (hidden)cell이 바닐라 LSTM인지, LSTM인지, GRU인지에 따라 구체적인 기능이 달라집니다.
또한, 최종적으로 MNIST의 10개의 class를 예측해야 하기 때문에 Fully Connected Layer를 마지막에 달아주어야 합니다.
forward에서는,
보통 딥러닝에서는 BATCH 단위로 학습을 진행하기 때문에, INPUT DATA의 첫번째 차원을 BATCH SIZE로 맞춰주기 위해 LSTM layer에서 batch_first=True 속성을 적용해줍니다.
위의 정의대로 하면 28 time step을 갖기 때문에, 최종적인 output에서도 마지막 time step의 output만 가져오면 됩니다(out[:, -1, :])
최종적인 output도
코드는 아래와 같습니다.
# RNN class 정의 (many-to-one)
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, num_classes):
super(RNN, self).__init__() # 상속한 nn.Module에서 RNN에 해당하는 init 실행
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x):
# input x : (BATCH, LENGTH, INPUT_SIZE) 입니다 (다양한 length를 다룰 수 있습니다.).
# 최초의 hidden state와 cell state를 초기화시켜주어야 합니다.
# 배치 사이즈는 가변적이므로 클래스 내에선 표현하지 않습니다.
# 만약 Bi-directional LSTM이라면 아래의 hidden and cell states의 첫번째 차원은 2*self.num_layers 입니다.
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device) # (BATCH SIZE, SEQ_LENGTH, HIDDEN_SIZE)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device) # hidden state와 동일
# LSTM 순전파
out, _ = self.lstm(x, (h0, c0)) # output : (BATCH_SIZE, SEQ_LENGTH, HIDDEN_SIZE) tensors. (hn, cn)은 필요 없으므로 받지 않고 _로 처리합니다.
# 마지막 time step(sequence length)의 hidden state를 사용해 Class들의 logit을 반환합니다(hidden_size -> num_classes).
out = self.fc(out[:, -1, :])
return out
학습 & 평가
# 모델 할당 후 학습
model = RNN(input_size, hidden_size, num_layers, num_classes).to(device) #
# 손실 함수와 옵티마이저 정의
criterion = nn.CrossEntropyLoss() # 분류
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 학습
total_step = len(train_loader) # 배치 개수
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.reshape(-1, sequence_length, input_size).to(device) # (BATCH(100), 1, 28, 28) -> (BATCH(100), 28, 28)
labels = labels.to(device) # Size : (100)
# 순전파
outputs = model(images)
loss = criterion(outputs, labels)
# 역전파 & 최적화
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 100 == 0:
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(
epoch+1, num_epochs, i+1, total_step, loss.item()))
# 결과
Epoch [1/2], Step [100/600], Loss: 0.3529
Epoch [1/2], Step [200/600], Loss: 0.3285
Epoch [1/2], Step [300/600], Loss: 0.1513
Epoch [1/2], Step [400/600], Loss: 0.0811
Epoch [1/2], Step [500/600], Loss: 0.0673
Epoch [1/2], Step [600/600], Loss: 0.1529
Epoch [2/2], Step [100/600], Loss: 0.0384
Epoch [2/2], Step [200/600], Loss: 0.2253
Epoch [2/2], Step [300/600], Loss: 0.1461
Epoch [2/2], Step [400/600], Loss: 0.1451
Epoch [2/2], Step [500/600], Loss: 0.1352
Epoch [2/2], Step [600/600], Loss: 0.0478
# 모델 평가
model.eval() # Dropout, Batchnorm 등 실행 x
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.reshape(-1, sequence_length, input_size).to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs, 1) # logit(확률)이 가장 큰 class index 반환
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Test Accuracy of the model on the 10000 test images: {} %'.format(100 * correct / total))
# 모델 저장
torch.save(model.state_dict(), 'model.ckpt')
# 결과
Test Accuracy of the model on the 10000 test images: 98.08 %LSTM의 연산 Code
LSTM의 구체적인 연산 과정은 파이토치의 내장 nn.Module.lstm 내부 코드에서 볼 수 있습니다.
https://github.com/pytorch/pytorch/blob/master/benchmarks/fastrnns/custom_lstms.py
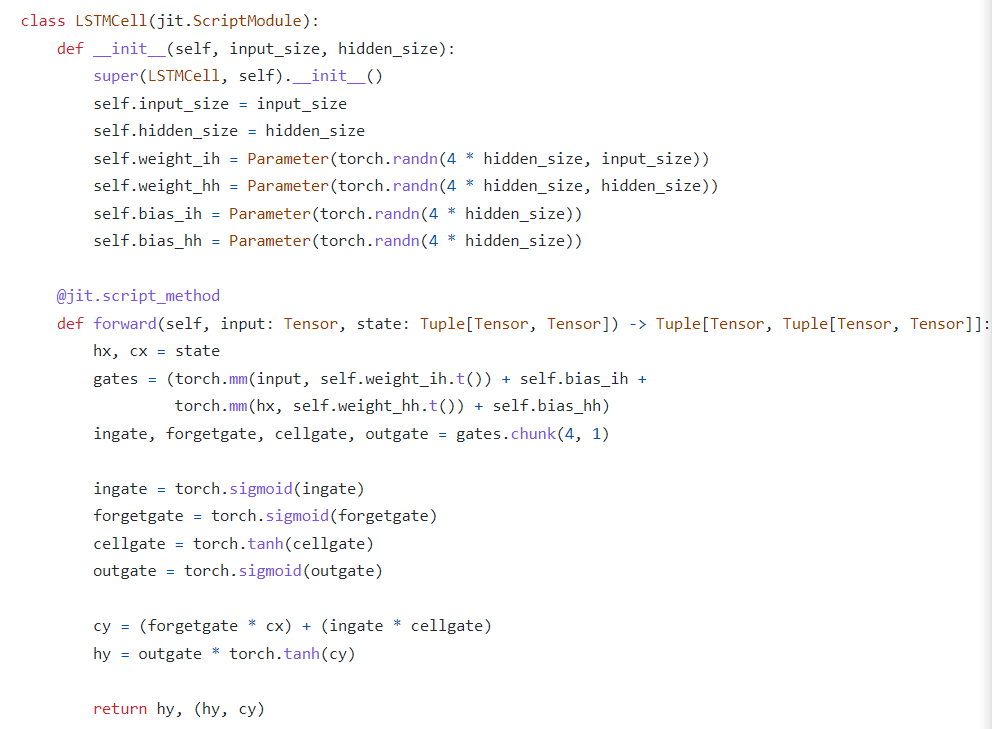
위에서 cellgate는 를 말합니다(cell state의 candidate이라 말하기도 합니다).
또한, 위 식에서
의 가중치를 각각 정의하는 게 아니라, 이 가중치들을 쌓아서 gates를 그냥 한 번에 정의한 뒤, gates.chunk를 활용해 4개로 나누는 것을 볼 수 있습니다.
즉, 위에서 를 한 번에 정의합니다.
이는 이 공통적으로 연산에 들어가기 때문에 가능합니다.
