EDA 과제 2 – 웹크롤링으로 주유소 세부 정보 가져와 분석하기
- 이번 과제에서 가져와야 할 세부 옵션 (충전소 여부, 경정비 여부, 편의점 여부, 24시간 운영 여부)을 한번에 클릭하고 구별 정보를 가져오려 했으나, 확인해보니 옵션을 다 선택한 채로 조회를 하면 전체 주유소 보다 적은 수 안에서만 확인할 수 있어서 하나씩 추가하는 방식으로 시작했다.
문제 1)
- 수집한 데이터들을 pandas 데이터 프레임으로 정리해주세요.
- 부가 정보 데이터는 셀프 여부와 마찬가지로 Y 또는 N 으로 저장해주세요
- 최종적으로 데이터 프레임에 들어가야할 컬럼은 총 14개로 아래와 같습니다
- 주유소명, 주소, 브랜드, 휘발유 가격, 경유 가격, 셀프 여부, 세차장 여부, 충전소 여부, 경정비 여부, 편의점 여부, 24시간 운영 여부, 구, 위도, 경도
from selenium import webdriver
from bs4 import BeautifulSoup
import numpy as np
import pandas as pd
import re
import time
import json
import requests
import folium
import matplotlib.pyplot as plt
import urllib
import platform
import seaborn as sns
from matplotlib import font_manager, rc
from urllib.request import urlopen
from tqdm import tqdm_notebook
from selenium.webdriver.common.by import By
plt.rcParams["axes.unicode_minus"] = False
rc("font", family= "Malgun Gothic")
%matplotlib inlineopinetUrl = "https://www.opinet.co.kr/searRgSelect.do"
driver = webdriver.Chrome("../driver/chromedriver.exe")
driver.get(opinetUrl)
time.sleep(1)
driver.get(opinetUrl)C:\Users\User\AppData\Local\Temp\ipykernel_14728\984525385.py:3: DeprecationWarning: executable_path has been deprecated, please pass in a Service object
driver = webdriver.Chrome("../driver/chromedriver.exe")si_do = driver.find_element(By.XPATH,'//*[@id="SIDO_NM0"]/option[2]')
si_do.click()# 서울 내 구 추출
si_gun_gu = driver.find_element(By.ID,"SIGUNGU_NM0")
gu_list =si_gun_gu.find_elements(By.TAG_NAME,"option")
gu_names = [option.get_attribute("value") for option in gu_list]
gu_names = gu_names[1:]
print(len(gu_names))
print(gu_names[:5])25
['강남구', '강동구', '강북구', '강서구', '관악구']확인해야 하는 부가옵션 (세차장, 경정비, 편의점, 24시간)을 클릭한 후 조회하면 부가옵션 선택없이 클릭한 결과보다 적은 수의 주유소가 조회되었다 .
--> 우선 전체 주유소 조회 후 각 부가 옵션을 데이터 프레임에 더하는 방식으로 진행하였다.
req = driver.page_source
soup = BeautifulSoup(req, "html.parser")oilStation = []
for gu_name in tqdm_notebook(gu_names):
time.sleep(0.5)
driver.find_element(By.ID,"SIGUNGU_NM0").send_keys(gu_name)
req = driver.page_source
soup = BeautifulSoup(req, "html.parser")
datas = soup.find(id = "body1").find_all("tr")
for item in datas :
name = item.find("a").text.strip()
brand = item.find("img")['alt']
address = item.find("a")['href'].split(",")[-11].replace("'","")
gas_cost = item.find_all("td", class_ = "price")[0].text.strip()
diesel_cost = item.find_all("td", class_ = "price")[1].text.strip()
# self 가능 주유소는 <span class="ico">셀프</span> 존재 / 셀프 불가 주유소는 정보 없음.
if item.find("span", class_= "ico") != None and item.find("span", class_= "ico").text == '셀프':
self="Y"
else : self="N"
gu = address.split(" ")[1]
data = {
"브랜드" : brand,
"주유소명" : name,
"구" : gu,
"주소" : address,
"휘발유 가격" : gas_cost,
"경유 가격" : diesel_cost,
"셀프 여부" : self
}
oilStation.append(data)
len(oilStation)444- for문을 통해 각 구의 이름을 send_keys로 보내서 주유소 이름, 브랜드, 주소 등 각 리스트에 더해주었다. Self 여부 옵션의 경우 셀프가능 주유소에만 별도의 span class~데이터가 있어서 추가 옵션을 주었다. 마지막으로 전체 주유소 개수만큼 출력되는지 확인.
df_oil= pd.DataFrame(oilStation)
df_oil.tail()
# 서울 지역 내 주유소 총 444개 확인| 브랜드 | 주유소명 | 구 | 주소 | 휘발유 가격 | 경유 가격 | 셀프 여부 | |
|---|---|---|---|---|---|---|---|
| 439 | S-OIL | (주)기지에너지 | 중랑구 | 서울 중랑구 용마산로 716 (신내동) | 1645 | 1845 | N |
| 440 | SK에너지 | 신내주유소 | 중랑구 | 서울 중랑구 용마산로 705 (신내동) | 1658 | 1859 | Y |
| 441 | S-OIL | 범아주유소 | 중랑구 | 서울 중랑구 동일로 881 (묵동) | 1669 | 1869 | N |
| 442 | SK에너지 | 신일셀프주유소 | 중랑구 | 서울 중랑구 상봉로 58 (망우동) | 1698 | 1899 | Y |
| 443 | SK에너지 | 용마로주유소 | 중랑구 | 서울 중랑구 용마산로 309 (면목동) | 1698 | 1858 | Y |
df_oil.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 444 entries, 0 to 443
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 브랜드 444 non-null object
1 주유소명 444 non-null object
2 구 444 non-null object
3 주소 444 non-null object
4 휘발유 가격 444 non-null object
5 경유 가격 444 non-null object
6 셀프 여부 444 non-null object
dtypes: object(7)
memory usage: 24.4+ KB- 다음 단계로 이번 과제에서 추가로 확인할 부가 옵션 정보를 더해주었다. 만들어 놓은 데이터리스트 중 주유소명 기준으로 돌리려 했는데 글자수가 길어서인지 주유소명이 전체 다 출력되지 않고 ~…형태로 나와서 for item in data: 실행 시 주소 기준으로 했더니 전체 출력이 되었다.
+해설강의를 통해 구글에서 hidden text 가져오는 법을 알게 되어 한번 이 방법으로 다시 해봐야겠다.
각 부가정보 합치기
#세차장 여부
car_wash = []
driver.find_element(By.XPATH,'//*[@id="CWSH_YN"]').click()
for gu_name in tqdm_notebook(gu_names):
time.sleep(0.5)
driver.find_element(By.ID,"SIGUNGU_NM0").send_keys(gu_name)
req = driver.page_source
soup = BeautifulSoup(req, "html.parser")
data = soup.select('#body1 > tr')
for item in data :
address = item.find("a")['href'].split(",")[-11].replace("'","")
wash = 'Y'
# 주유소 명 기준으로 다시 검색하니 주유소명이 "~..."으로 이전과 약간 다르게 조회되어 주소 기준으로 검색했다.
datas = {
"주소" : address,
"세차장 여부" : wash
}
car_wash.append(datas)
len(car_wash)C:\Users\User\AppData\Local\Temp\ipykernel_14728\654408338.py:7: TqdmDeprecationWarning: This function will be removed in tqdm==5.0.0
Please use `tqdm.notebook.tqdm` instead of `tqdm.tqdm_notebook`
for gu_name in tqdm_notebook(gu_names):
0%| | 0/25 [00:00<?, ?it/s]
338df_carwash = pd.DataFrame(car_wash)
df_carwash.tail()| 주소 | 세차장 여부 | |
|---|---|---|
| 333 | 서울 중랑구 망우로 170 (상봉동) | Y |
| 334 | 서울 중랑구 용마산로 705 (신내동) | Y |
| 335 | 서울 중랑구 동일로 881 (묵동) | Y |
| 336 | 서울 중랑구 용마산로 309 (면목동) | Y |
| 337 | 서울 중랑구 상봉로 58 (망우동) | Y |
df = pd.merge(df_oil,df_carwash, how="outer", on="주소")
df = df.fillna("N")
df| 브랜드 | 주유소명 | 구 | 주소 | 휘발유 가격 | 경유 가격 | 셀프 여부 | 세차장 여부 | |
|---|---|---|---|---|---|---|---|---|
| 0 | SK에너지 | (주)보성 세곡주... | 강남구 | 서울 강남구 헌릉로 731 (세곡동) | 1663 | 1839 | Y | Y |
| 1 | 현대오일뱅크 | 현대오일뱅크(주)... | 강남구 | 서울 강남구 헌릉로 730 | 1689 | 1879 | Y | Y |
| 2 | GS칼텍스 | 방죽주유소 | 강남구 | 서울 강남구 밤고개로 215 (율현동) | 1697 | 1929 | Y | Y |
| 3 | 현대오일뱅크 | 현대오일뱅크 도곡... | 강남구 | 서울 강남구 남부순환로 2718 (도곡2동) | 1715 | 1873 | Y | Y |
| 4 | SK에너지 | 오일프러스 셀프 | 강남구 | 서울 강남구 남부순환로 2651 (도곡동) | 1716 | 1888 | Y | Y |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 439 | S-OIL | (주)기지에너지 | 중랑구 | 서울 중랑구 용마산로 716 (신내동) | 1645 | 1845 | N | N |
| 440 | SK에너지 | 신내주유소 | 중랑구 | 서울 중랑구 용마산로 705 (신내동) | 1658 | 1859 | Y | Y |
| 441 | S-OIL | 범아주유소 | 중랑구 | 서울 중랑구 동일로 881 (묵동) | 1669 | 1869 | N | Y |
| 442 | SK에너지 | 신일셀프주유소 | 중랑구 | 서울 중랑구 상봉로 58 (망우동) | 1698 | 1899 | Y | Y |
| 443 | SK에너지 | 용마로주유소 | 중랑구 | 서울 중랑구 용마산로 309 (면목동) | 1698 | 1858 | Y | Y |
444 rows × 8 columns
# 경정비 여부
fix_data = []
driver.find_element(By.XPATH,'//*[@id="CWSH_YN"]').click()
time.sleep(0.5)
driver.find_element(By.XPATH,'//*[@id="MAINT_YN"]').click()
for gu_name in tqdm_notebook(gu_names):
time.sleep(1)
driver.find_element(By.ID,"SIGUNGU_NM0").send_keys(gu_name)
req = driver.page_source
soup = BeautifulSoup(req, "html.parser")
datas = soup.select('#body1 > tr')
for item in datas :
address = item.find("a")['href'].split(",")[-11].replace("'","")
fix = 'Y'
data = {
"주소" : address,
"경정비 여부" : fix
}
fix_data.append(data)
len(fix_data)C:\Users\User\AppData\Local\Temp\ipykernel_14728\3264690695.py:9: TqdmDeprecationWarning: This function will be removed in tqdm==5.0.0
Please use `tqdm.notebook.tqdm` instead of `tqdm.tqdm_notebook`
for gu_name in tqdm_notebook(gu_names):
0%| | 0/25 [00:00<?, ?it/s]
102df_fix = pd.DataFrame(fix_data)
df = pd.merge(df,df_fix, how="outer", on="주소")
df = df.fillna("N")
df| 브랜드 | 주유소명 | 구 | 주소 | 휘발유 가격 | 경유 가격 | 셀프 여부 | 세차장 여부 | 경정비 여부 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | SK에너지 | (주)보성 세곡주... | 강남구 | 서울 강남구 헌릉로 731 (세곡동) | 1663 | 1839 | Y | Y | N |
| 1 | 현대오일뱅크 | 현대오일뱅크(주)... | 강남구 | 서울 강남구 헌릉로 730 | 1689 | 1879 | Y | Y | N |
| 2 | GS칼텍스 | 방죽주유소 | 강남구 | 서울 강남구 밤고개로 215 (율현동) | 1697 | 1929 | Y | Y | N |
| 3 | 현대오일뱅크 | 현대오일뱅크 도곡... | 강남구 | 서울 강남구 남부순환로 2718 (도곡2동) | 1715 | 1873 | Y | Y | Y |
| 4 | SK에너지 | 오일프러스 셀프 | 강남구 | 서울 강남구 남부순환로 2651 (도곡동) | 1716 | 1888 | Y | Y | Y |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 439 | S-OIL | (주)기지에너지 | 중랑구 | 서울 중랑구 용마산로 716 (신내동) | 1645 | 1845 | N | N | N |
| 440 | SK에너지 | 신내주유소 | 중랑구 | 서울 중랑구 용마산로 705 (신내동) | 1658 | 1859 | Y | Y | N |
| 441 | S-OIL | 범아주유소 | 중랑구 | 서울 중랑구 동일로 881 (묵동) | 1669 | 1869 | N | Y | Y |
| 442 | SK에너지 | 신일셀프주유소 | 중랑구 | 서울 중랑구 상봉로 58 (망우동) | 1698 | 1899 | Y | Y | Y |
| 443 | SK에너지 | 용마로주유소 | 중랑구 | 서울 중랑구 용마산로 309 (면목동) | 1698 | 1858 | Y | Y | N |
444 rows × 9 columns
# 편의점 여부
conv_data = []
driver.find_element(By.XPATH,'//*[@id="MAINT_YN"]').click()
driver.find_element(By.XPATH,'//*[@id="CVS_YN"]').click()
for gu_name in tqdm_notebook(gu_names):
time.sleep(0.5)
driver.find_element(By.ID,"SIGUNGU_NM0").send_keys(gu_name)
req = driver.page_source
soup = BeautifulSoup(req, "html.parser")
datas = soup.select('#body1 > tr')
for item in datas :
address = item.find("a")['href'].split(",")[-11].replace("'","")
cvs = 'Y'
data = {
"주소" : address,
"편의점 여부" : cvs
}
conv_data.append(data)
len(conv_data)
C:\Users\User\AppData\Local\Temp\ipykernel_14728\3283546689.py:7: TqdmDeprecationWarning: This function will be removed in tqdm==5.0.0
Please use `tqdm.notebook.tqdm` instead of `tqdm.tqdm_notebook`
for gu_name in tqdm_notebook(gu_names):
0%| | 0/25 [00:00<?, ?it/s]
40df_cvs = pd.DataFrame(conv_data)
df = pd.merge(df,df_cvs, how="outer", on="주소")
df = df.fillna("N")
df.tail()| 브랜드 | 주유소명 | 구 | 주소 | 휘발유 가격 | 경유 가격 | 셀프 여부 | 세차장 여부 | 경정비 여부 | 편의점 여부 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 439 | S-OIL | (주)기지에너지 | 중랑구 | 서울 중랑구 용마산로 716 (신내동) | 1645 | 1845 | N | N | N | N |
| 440 | SK에너지 | 신내주유소 | 중랑구 | 서울 중랑구 용마산로 705 (신내동) | 1658 | 1859 | Y | Y | N | N |
| 441 | S-OIL | 범아주유소 | 중랑구 | 서울 중랑구 동일로 881 (묵동) | 1669 | 1869 | N | Y | Y | N |
| 442 | SK에너지 | 신일셀프주유소 | 중랑구 | 서울 중랑구 상봉로 58 (망우동) | 1698 | 1899 | Y | Y | Y | N |
| 443 | SK에너지 | 용마로주유소 | 중랑구 | 서울 중랑구 용마산로 309 (면목동) | 1698 | 1858 | Y | Y | N | N |
# 24시간 여부
for24_data = []
driver.find_element(By.XPATH,'//*[@id="CVS_YN"]').click()
driver.find_element(By.XPATH,'//*[@id="SEL24_YN"]').click()
for gu_name in tqdm_notebook(gu_names):
time.sleep(0.2)
driver.find_element(By.ID,"SIGUNGU_NM0").send_keys(gu_name)
req = driver.page_source
soup = BeautifulSoup(req, "html.parser")
datas = soup.select('#body1 > tr')
for item in datas :
address = item.find("a")['href'].split(",")[-11].replace("'","")
sel24 = 'Y'
data = {
"주소" : address,
"24시간 여부" : sel24
}
for24_data.append(data)C:\Users\User\AppData\Local\Temp\ipykernel_14728\1138770683.py:8: TqdmDeprecationWarning: This function will be removed in tqdm==5.0.0
Please use `tqdm.notebook.tqdm` instead of `tqdm.tqdm_notebook`
for gu_name in tqdm_notebook(gu_names):
0%| | 0/25 [00:00<?, ?it/s]df_24 = pd.DataFrame(for24_data)
df = pd.merge(df,df_24, how="outer", on="주소")
df = df.fillna("N")
df.tail()| 브랜드 | 주유소명 | 구 | 주소 | 휘발유 가격 | 경유 가격 | 셀프 여부 | 세차장 여부 | 경정비 여부 | 편의점 여부 | 24시간 여부 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 439 | S-OIL | (주)기지에너지 | 중랑구 | 서울 중랑구 용마산로 716 (신내동) | 1645 | 1845 | N | N | N | N | N |
| 440 | SK에너지 | 신내주유소 | 중랑구 | 서울 중랑구 용마산로 705 (신내동) | 1658 | 1859 | Y | Y | N | N | N |
| 441 | S-OIL | 범아주유소 | 중랑구 | 서울 중랑구 동일로 881 (묵동) | 1669 | 1869 | N | Y | Y | N | N |
| 442 | SK에너지 | 신일셀프주유소 | 중랑구 | 서울 중랑구 상봉로 58 (망우동) | 1698 | 1899 | Y | Y | Y | N | Y |
| 443 | SK에너지 | 용마로주유소 | 중랑구 | 서울 중랑구 용마산로 309 (면목동) | 1698 | 1858 | Y | Y | N | N | N |
- 다른 옵션들도 위와 같은 방식으로 기존 옵션 체크해제 -> 새로운 옵션 클릭 후 데이터 가져오기 순으로 진행했다.
- 충전소의 경우 서울시 전체 주유소로 출력한 리스트 중 해당되지 않는 충전만 하는 주소도 포함이 되었던 걸로 기억한다. 기존 주유소 데이터와 중복되는 장소만 따로 빼서 데이터프레임에 합쳐주었다.
# 충전소 여부
driver.find_element(By.XPATH,'//*[@id="LPG_BTN"]').click()
driver.find_element(By.ID,"SIDO_NM0").send_keys("서울")
LPG_data= []
for gu_name in tqdm_notebook(gu_names):
time.sleep(0.5)
driver.find_element(By.ID,"SIGUNGU_NM0").send_keys(gu_name)
req = driver.page_source
soup = BeautifulSoup(req, "html.parser")
datas = soup.select('#body1 > tr')
for item in datas :
address = item.find("a")['href'].split(",")[-11].replace("'","")
charge = "Y"
data = {
"주소" : address,
"충전소 여부" : charge
}
LPG_data.append(data)
len(LPG_data)C:\Users\User\AppData\Local\Temp\ipykernel_14728\2424661217.py:8: TqdmDeprecationWarning: This function will be removed in tqdm==5.0.0
Please use `tqdm.notebook.tqdm` instead of `tqdm.tqdm_notebook`
for gu_name in tqdm_notebook(gu_names):
0%| | 0/25 [00:00<?, ?it/s]
74df_LPG = pd.DataFrame(LPG_data)
df_LPG = pd.merge(df_oil,df_LPG,on="주소")
del df_LPG ["브랜드"]
del df_LPG ["주유소명"]
del df_LPG ["구"]
del df_LPG ["휘발유 가격"]
del df_LPG ["경유 가격"]
del df_LPG ["셀프 여부"]
df_LPG | 주소 | 충전소 여부 | |
|---|---|---|
| 0 | 서울 서초구 양재대로12길 73-71 | Y |
df = pd.merge(df,df_LPG , how="outer", on="주소")
df = df.fillna("N")
df.tail() | 브랜드 | 주유소명 | 구 | 주소 | 휘발유 가격 | 경유 가격 | 셀프 여부 | 세차장 여부 | 경정비 여부 | 편의점 여부 | 24시간 여부 | 충전소 여부 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 439 | S-OIL | (주)기지에너지 | 중랑구 | 서울 중랑구 용마산로 716 (신내동) | 1645 | 1845 | N | N | N | N | N | N |
| 440 | SK에너지 | 신내주유소 | 중랑구 | 서울 중랑구 용마산로 705 (신내동) | 1658 | 1859 | Y | Y | N | N | N | N |
| 441 | S-OIL | 범아주유소 | 중랑구 | 서울 중랑구 동일로 881 (묵동) | 1669 | 1869 | N | Y | Y | N | N | N |
| 442 | SK에너지 | 신일셀프주유소 | 중랑구 | 서울 중랑구 상봉로 58 (망우동) | 1698 | 1899 | Y | Y | Y | N | Y | N |
| 443 | SK에너지 | 용마로주유소 | 중랑구 | 서울 중랑구 용마산로 309 (면목동) | 1698 | 1858 | Y | Y | N | N | N | N |
- 컬럼명이 같아도 합치게 되면 브랜드-x, 브랜드-y 두개씩 생성되어서 중복된 컬럼은 따로 삭제를 했다.
# 위도/경도 추가하기
import googlemaps
gmaps_key = "AIzaSyCB3zeKUulnVUj_yDjKqaqoqVsF0MGvx_o"
gmaps = googlemaps.Client(key=gmaps_key)
loc_data = []
for item in tqdm_notebook(df['주소']):
tmp = gmaps.geocode(item, language="ko")
lat = tmp[0].get("geometry")["location"]["lat"]
lng = tmp[0].get("geometry")["location"]["lng"]
data = {
"주소" : item,
"위도" : lat,
"경도" : lng
}
loc_data.append(data)
len(loc_data)C:\Users\User\AppData\Local\Temp\ipykernel_14728\563219376.py:9: TqdmDeprecationWarning: This function will be removed in tqdm==5.0.0
Please use `tqdm.notebook.tqdm` instead of `tqdm.tqdm_notebook`
for item in tqdm_notebook(df['주소']):
0%| | 0/444 [00:00<?, ?it/s]
444df_loc = pd.DataFrame(loc_data)
df = pd.merge(df,df_loc, how="outer", on="주소")
df = df.fillna("N")
df.tail()| 브랜드 | 주유소명 | 구 | 주소 | 휘발유 가격 | 경유 가격 | 셀프 여부 | 세차장 여부 | 경정비 여부 | 편의점 여부 | 24시간 여부 | 충전소 여부 | 위도 | 경도 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 439 | S-OIL | (주)기지에너지 | 중랑구 | 서울 중랑구 용마산로 716 (신내동) | 1645 | 1845 | N | N | N | N | N | N | 37.614704 | 127.101898 |
| 440 | SK에너지 | 신내주유소 | 중랑구 | 서울 중랑구 용마산로 705 (신내동) | 1658 | 1859 | Y | Y | N | N | N | N | 37.614120 | 127.100916 |
| 441 | S-OIL | 범아주유소 | 중랑구 | 서울 중랑구 동일로 881 (묵동) | 1669 | 1869 | N | Y | Y | N | N | N | 37.609176 | 127.077662 |
| 442 | SK에너지 | 신일셀프주유소 | 중랑구 | 서울 중랑구 상봉로 58 (망우동) | 1698 | 1899 | Y | Y | Y | N | Y | N | 37.590907 | 127.093834 |
| 443 | SK에너지 | 용마로주유소 | 중랑구 | 서울 중랑구 용마산로 309 (면목동) | 1698 | 1858 | Y | Y | N | N | N | N | 37.579873 | 127.092160 |
df.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 444 entries, 0 to 443
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 브랜드 444 non-null object
1 주유소명 444 non-null object
2 구 444 non-null object
3 주소 444 non-null object
4 휘발유 가격 444 non-null object
5 경유 가격 444 non-null object
6 셀프 여부 444 non-null object
7 세차장 여부 444 non-null object
8 경정비 여부 444 non-null object
9 편의점 여부 444 non-null object
10 24시간 여부 444 non-null object
11 충전소 여부 444 non-null object
12 위도 444 non-null float64
13 경도 444 non-null float64
dtypes: float64(2), object(12)
memory usage: 52.0+ KBdf["휘발유 가격"] = df["휘발유 가격"].astype("float")
df["경유 가격"] = df["경유 가격"].astype("float")
df.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 444 entries, 0 to 443
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 브랜드 444 non-null object
1 주유소명 444 non-null object
2 구 444 non-null object
3 주소 444 non-null object
4 휘발유 가격 444 non-null float64
5 경유 가격 444 non-null float64
6 셀프 여부 444 non-null object
7 세차장 여부 444 non-null object
8 경정비 여부 444 non-null object
9 편의점 여부 444 non-null object
10 24시간 여부 444 non-null object
11 충전소 여부 444 non-null object
12 위도 444 non-null float64
13 경도 444 non-null float64
dtypes: float64(4), object(10)
memory usage: 52.0+ KB문제 2)
- 휘발유와 경유 가격이 셀프 주유소에서 정말 저렴한지 분석 결과를 작성.
강의에서 배운 몇가지 시각화 방법을 통해 셀프 여부에 따른 가격차이를 확인
# barplot
sns.barplot(data=df, x= "셀프 여부", y="휘발유 가격")<AxesSubplot:xlabel='셀프 여부', ylabel='휘발유 가격'>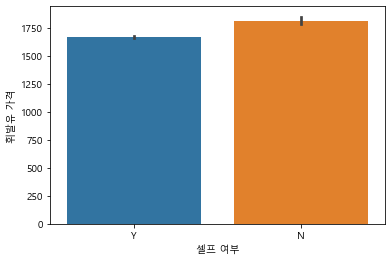
sns.barplot(data=df, x= "셀프 여부", y="경유 가격")<AxesSubplot:xlabel='셀프 여부', ylabel='경유 가격'>
셀프 여부에 따라 나눈 휘발유/ 경유 가격의 차이가 barplot으로 비교 시 셀프 주유소가 더 저렴한 편으로 보이나 차이가 커보이지는 않는다. 하지만 주유소 가격은 몇 백원의 차이도 큰 편이기 때문에 다른 방법을 통해 확인을 더 해보자.
# 브랜드 별로 확인한 셀프 여부에 따른 휘발유 가격의 차이
plt.figure(figsize=(10,6))
sns.barplot(data=df, x= "브랜드", y="휘발유 가격",hue="셀프 여부")<AxesSubplot:xlabel='브랜드', ylabel='휘발유 가격'>
# 브랜드 별로 확인한 셀프 여부에 따른 경유 가격의 차이
plt.figure(figsize=(10,6))
sns.barplot(data=df, x= "브랜드", y="경유 가격",hue="셀프 여부")<AxesSubplot:xlabel='브랜드', ylabel='경유 가격'>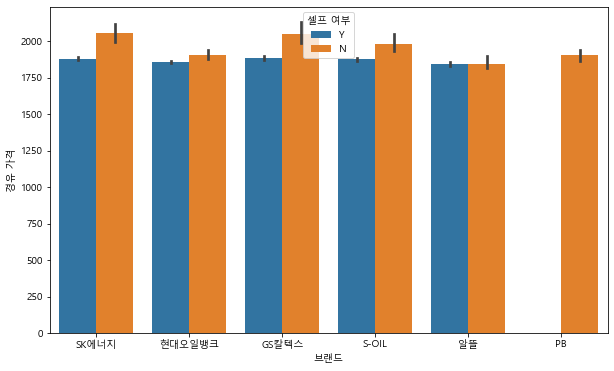
편차를 더 확실히 비교하기 위해 boxplot 그래프로도 확인해보자.
# boxplot 으로 확인한 브랜드 별 휘발유 가격 차이
plt.figure(figsize=(15, 10))
sns.boxplot(x="브랜드", y="휘발유 가격", hue="셀프 여부", data=df, palette="Set2")
plt.grid(True)
plt.show()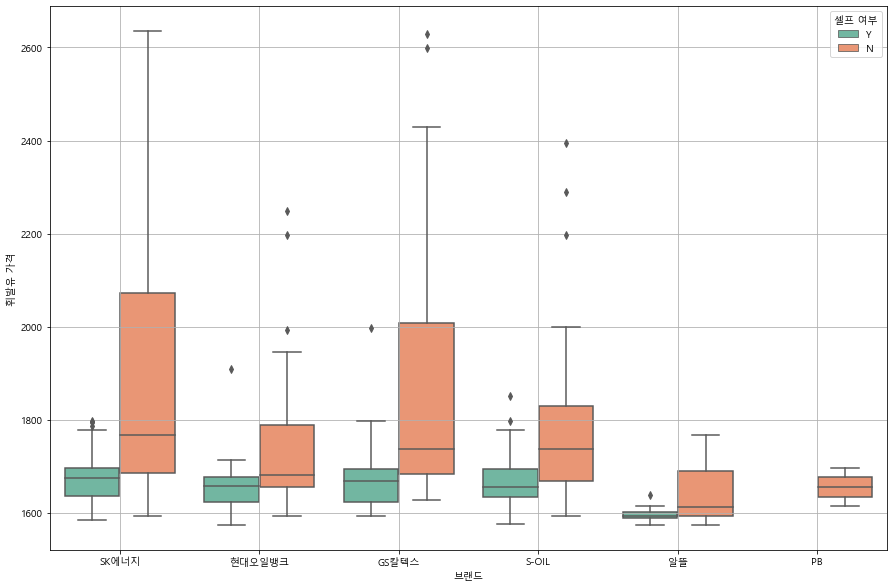
plt.figure(figsize=(15, 10))
sns.boxplot(x="브랜드", y="경유 가격", hue="셀프 여부", data=df, palette="Set1")
plt.grid(True)
plt.show()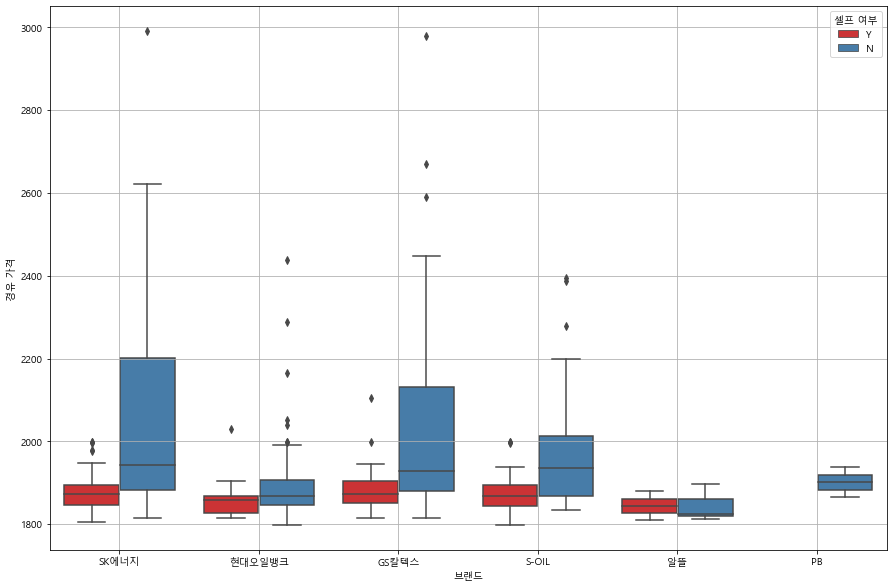
브랜드 별로 약간의 차이가 있긴 하지만 대부분의 경우 셀프 주유소가 더 저렴한 것을 알 수 있다.
결론
: boxplot에서 볼 수 있듯이, 셀프 여부에 따른 평균, 중앙값 차이가 거의 모든 케이스에서 셀프 주유소가 더 저렴하게 확인된다. 하지만 "알뜰"주유소나 소수의 경우 표본 값이 작아 신뢰도가 낮긴 하지만 거의 비슷한 경우도 있는 것으로 보여서 '모든 주유소에서 셀프가 더 저렴하다'는 확실한 결론 보다는 '대부분의 경우 더 저렴하다'는 결론이 맞는 듯하다.
느낀 점

: 과제내용만 봤을 때는 지난 EDA 과제와 비슷해서 금방 할 수 있을 줄 알았는데 옵션 몇 개만 달라졌다고 초반에 갈피를 잡지 못했다.😱 운 좋게 주소 값은 그대로 출력이 되어 과제 마무리까지 진행했지만 주유소명으로만 조회를 해야 된다면 나처럼 이름이 끝까지 출력이 안되는 경우에 대한 해답을 찾지 못해서 결론 단계까지 가지 못했을 것 같다.
구글링으로 어떻게 검색할 지 조차 모르겠어서 다른 변수로 넘어갔었는데 생각보다 비슷한 에러가 자주 나오는지 자동검색에 잘 나오더라..😭 에러 원인을 찾는 시도를 좀 더 적극적으로 해봐야겠고, 한번 해봤다고 해도 코드 식 같은 거는 휘발성이 워낙 강하다 보니 유사 사례로 분석해볼 자료가 있다면 좀 더 연습할 필요를 느꼈다. ✊✊

데이터분석 스터디노트🧐✍️