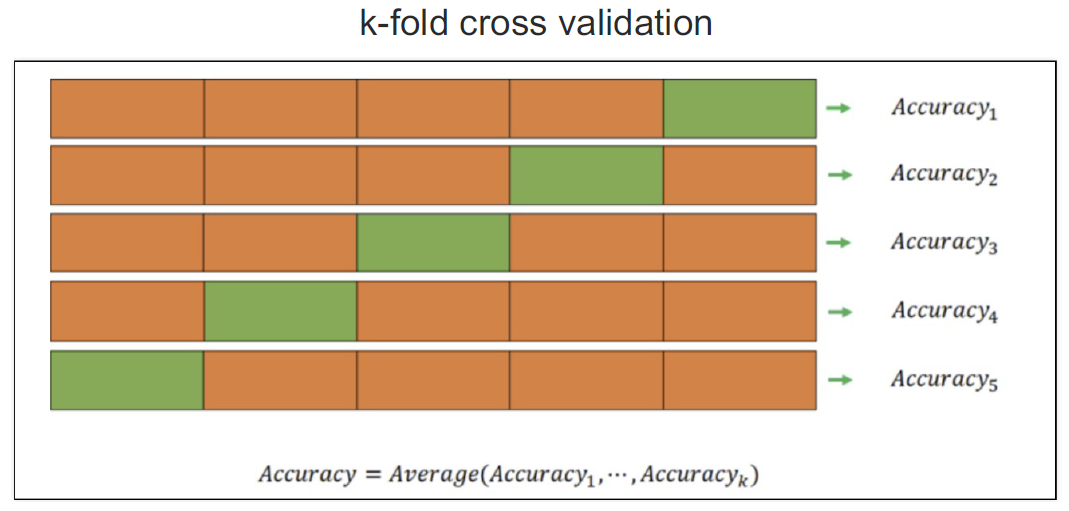
⏹교차검증
과적합: 모델이 학습 데이터에만 과도하게 최적화된 현상.
그로 인해 일반화된 데이터에서는 예측 성능이 과하게 떨어지는 현상
과적합을 방지하기 위해 train / test 데이터 중 train 데이터를 다시 나누어 검증
import numpy as np
from sklearn.model_selection import KFoldX = np.array([
[1,2],[3,4],[1,2],[3,4]
])
y = np.array([1,2,3,4])kf = KFold(n_splits=2)
# 2등분으로 분리
print(kf.get_n_splits(X))
print(kf)2
KFold(n_splits=2, random_state=None, shuffle=False)for train_idx, test_idx in kf.split(X):
print('--- idx')
print(train_idx, test_idx)
print('--- train data')
print(X[train_idx])
print('--- validation data')
print(X[test_idx])--- idx
[2 3] [0 1]
--- train data
[[1 2]
[3 4]]
--- validation data
[[1 2]
[3 4]]
--- idx
[0 1] [2 3]
--- train data
[[1 2]
[3 4]]
--- validation data
[[1 2]
[3 4]]와인데이터 다시 가져오기
import pandas as pd
red_url = "https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-red.csv"
white_url = "https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-white.csv"
red_wine = pd.read_csv(red_url, sep=';')
white_wine = pd.read_csv(white_url, sep=';')
red_wine['color']= 1.
white_wine['color'] = 0.
wine = pd.concat([red_wine, white_wine])# 와인 맛 분류기를 위한 데이터 정리
wine['taste'] = [1.if grade >5 else 0. for grade in wine['quality']]
X = wine.drop(['taste','quality'],axis=1)
y = wine['taste']from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2, random_state=13)
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train,y_train)
y_pred_tr = wine_tree.predict(X_train)
y_pred_test = wine_tree.predict(X_test)
print('Train Acc : ', accuracy_score(y_train,y_pred_tr))
print('test Acc : ', accuracy_score(y_test,y_pred_test))Train Acc : 0.7294593034442948
test Acc : 0.7161538461538461◼ KFold
from sklearn.model_selection import KFold
kfold = KFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)# KFold는 idx를 반환한다
for train_idx, test_idx in kfold.split(X):
print(len(train_idx), len(test_idx))5197 1300
5197 1300
5198 1299
5198 1299
5198 1299cv_accuracy = []
for train_idx,test_idx in kfold.split(X):
X_train = X.iloc[train_idx]
X_test = X.iloc[test_idx]
y_train = y.iloc[train_idx]
y_test = y.iloc[test_idx]
wine_tree_cv.fit(X_train,y_train)
pred = wine_tree_cv.predict(X_test)
cv_accuracy.append(accuracy_score(y_test, pred))
# 성능이 60~78%까지 가능
cv_accuracy[0.6007692307692307,
0.6884615384615385,
0.7090069284064665,
0.7628945342571208,
0.7867590454195535]np.mean(cv_accuracy)0.709578255462782◼ StratifiedKFold
from sklearn.model_selection import StratifiedKFold
skfold = StratifiedKFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)
cv_accuracy = []
for train_idx, test_idx in skfold.split(X,y):
X_train = X.iloc[train_idx]
X_test = X.iloc[test_idx]
y_train = y.iloc[train_idx]
y_test = y.iloc[test_idx]
wine_tree_cv.fit(X_train,y_train)
pred = wine_tree_cv.predict(X_test)
cv_accuracy.append(accuracy_score(y_test, pred))
cv_accuracy[0.5523076923076923,
0.6884615384615385,
0.7143956889915319,
0.7321016166281755,
0.7567359507313318]np.mean(cv_accuracy)0.6888004974240539# 한번에 처리
from sklearn.model_selection import cross_val_score
skfold = StratifiedKFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)
cross_val_score(wine_tree_cv, X,y, cv=skfold)array([0.55230769, 0.68846154, 0.71439569, 0.73210162, 0.75673595])#max_depth 조절
skfold = StratifiedKFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=4, random_state=13)
cross_val_score(wine_tree_cv, X,y, cv=skfold)array([0.51230769, 0.63153846, 0.72363356, 0.73210162, 0.7182448 ])from sklearn.model_selection import cross_validate
cross_validate(wine_tree_cv, X, y, cv=skfold, return_train_score=True){'fit_time': array([0.01453233, 0. , 0.01529408, 0.00806761, 0.00799203]),
'score_time': array([0. , 0. , 0. , 0.00799561, 0. ]),
'test_score': array([0.51230769, 0.63153846, 0.72363356, 0.73210162, 0.7182448 ]),
'train_score': array([0.77563979, 0.76813546, 0.75779146, 0.74644094, 0.74259331])}⏹하이퍼파라미터 튜닝
: 모델의 성능을 확보하기 위해 조절하는 설정 값
red_url = "https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-red.csv"
white_url = "https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-white.csv"
red_wine = pd.read_csv(red_url, sep=';')
white_wine = pd.read_csv(white_url, sep=';')
red_wine['color']= 1.
white_wine['color'] = 0.
wine = pd.concat([red_wine, white_wine])
wine['taste'] = [1.if grade >5 else 0. for grade in wine['quality']]
X = wine.drop(['taste','quality'],axis=1)
y = wine['taste']◼ GridSearchCV
from sklearn.model_selection import GridSearchCV
params = {'max_depth': [2,4,7,10]}
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
gridsearch = GridSearchCV(estimator = wine_tree, param_grid = params, cv=5)
gridsearch.fit(X,y) #train_test_split 따로 해주지 않아도 됨.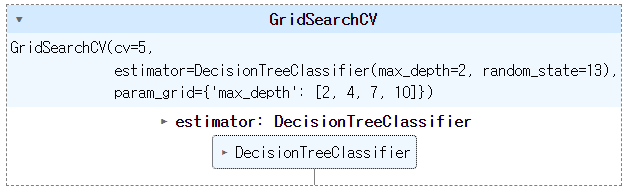
# gridSearchCV 결과
import pprint
pp = pprint.PrettyPrinter(indent=4)
pp.pprint(gridsearch.cv_results_){ 'mean_fit_time': array([0.00501895, 0.0056623 , 0.01583157, 0.01885033]),
'mean_score_time': array([0.00118647, 0.00060296, 0. , 0. ]),
'mean_test_score': array([0.6888005 , 0.66356523, 0.65340854, 0.64401587]),
'param_max_depth': masked_array(data=[2, 4, 7, 10],
mask=[False, False, False, False],
fill_value='?',
dtype=object),
'params': [ {'max_depth': 2},
{'max_depth': 4},
{'max_depth': 7},
{'max_depth': 10}],
'rank_test_score': array([1, 2, 3, 4]),
'split0_test_score': array([0.55230769, 0.51230769, 0.50846154, 0.51615385]),
'split1_test_score': array([0.68846154, 0.63153846, 0.60307692, 0.60076923]),
'split2_test_score': array([0.71439569, 0.72363356, 0.68360277, 0.66743649]),
'split3_test_score': array([0.73210162, 0.73210162, 0.73672055, 0.71054657]),
'split4_test_score': array([0.75673595, 0.7182448 , 0.73518091, 0.72517321]),
'std_fit_time': array([0.00060967, 0.00326196, 0.00027139, 0.00641571]),
'std_score_time': array([0.00040828, 0.00049232, 0. , 0. ]),
'std_test_score': array([0.07179934, 0.08390453, 0.08727223, 0.07717557])}최적의 성능 확인
gridsearch.best_estimator_
gridsearch.best_score_0.6888004974240539gridsearch.best_params_{'max_depth': 2}### pipeline을 적용한 모델에 GridSearch 적용하는 경우?
from sklearn.pipeline import Pipeline
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
estimators = [
('scaler', StandardScaler()),
('clf', DecisionTreeClassifier())]
pipe = Pipeline(estimators)param_grid = [{'clf__max_depth': [2, 4, 7, 10]}]
Gridsearch = GridSearchCV(estimator=pipe, param_grid=param_grid, cv=5)
Gridsearch.fit(X, y)
# 마찬가지로 최적의 성능 따로 확인 가능
Gridsearch.best_score_0.6888004974240539깔끔하게 표로 성능결과 정리하는 법
import pandas as pd
score_df = pd.DataFrame(Gridsearch.cv_results_)
score_df[['params', 'rank_test_score', 'mean_test_score','std_test_score']]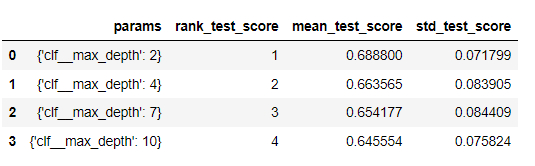

데이터분석 스터디노트🧐✍️