6. 데이터의 경향 표시
인구 수와 소계 컬럼으로 scatter plot 그리기
def drawGraph():
plt.figure(figsize=(14, 10))
plt.scatter(data_result["인구수"], data_result["소계"], s=50)
plt.xlabel("인구수")
plt.ylabel("CCTV")
plt.grid(True)
plt.show()
drawGraph()
numpy를 이용한 1차 직선 만들기
- np.polyfit() : 직선 구성하기 위한 계수를 계산
- np.poly1d(): polyfit으로 찾은 계수로 파이썬에서 사용할 수 있는 함수로 만들어주는 기능
import numpy as npfp1 = np.polyfit(data_result["인구수"], data_result["소계"], 1)
fp1array([1.11155868e-03, 1.06515745e+03])f1 = np.poly1d(fp1)
f1poly1d([1.11155868e-03, 1.06515745e+03])f1(400000) #- 인구 40만인 구에서 서울시 전체 경향에 맞는 적당한 CCTV의 수 1509.7809252413333- 경향선 그리기 위한 X데이터 생성
- np.linspace(a, b, n): a부터 b까지 n개의 동간격 데이터 생성
fx = np.linspace(100000, 700000, 100)def drawGraph():
plt.figure(figsize=(14, 10))
plt.scatter(data_result["인구수"], data_result["소계"], s=50)
plt.plot(fx, f1(fx), ls="dashed", lw=3, color="g") #plt.plot(x축,y축)
plt.xlabel("인구수")
plt.ylabel("CCTV")
plt.grid(True)
plt.show()
drawGraph()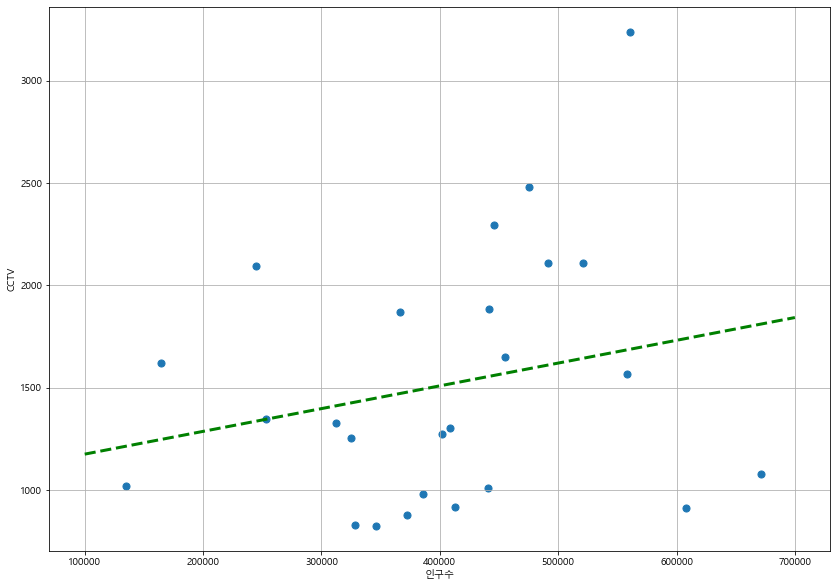
7. 강조하고 싶은 데이터를 시각화해보자.(경향에서 벗어난 데이터 강조하기)
그래프 다듬기
경향과의 오차 만들기
- 경향(trend)과의 오차를 만들기
- 경향은 f1함수에 해당 인구를 입력
- f1(data_result["인구수"])
fp1 = np.polyfit(data_result["인구수"], data_result["소계"], 1)
f1 = np.poly1d(fp1)
fx = np.linspace(100000, 700000, 100)# 오차 생성
data_result["오차"] = data_result["소계"] - f1(data_result["인구수"])data_result.head()| 소계 | 최근 증가율 | 인구수 | 한국인 | 외국인 | 고령자 | 외국인 비율 | 고령자 비율 | CCTV비율 | 오차 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 구별 | ||||||||||
| 강남구 | 3238 | 150.619195 | 561052 | 556164 | 4888 | 65060 | 0.871220 | 11.596073 | 0.577130 | 1549.200326 |
| 강동구 | 1010 | 166.490765 | 440359 | 436223 | 4136 | 56161 | 0.939234 | 12.753458 | 0.229358 | -544.642322 |
| 강북구 | 831 | 125.203252 | 328002 | 324479 | 3523 | 56530 | 1.074079 | 17.234651 | 0.253352 | -598.750923 |
| 강서구 | 911 | 134.793814 | 608255 | 601691 | 6564 | 76032 | 1.079153 | 12.500021 | 0.149773 | -830.268578 |
| 관악구 | 2109 | 149.290780 | 520929 | 503297 | 17632 | 70046 | 3.384722 | 13.446362 | 0.404854 | 464.799395 |
# 경향과 비교하여 오차가 너무 나는 데이터를 계산
df_sort_f = data_result.sort_values(by="오차", ascending=False) #내림차순
df_sort_t = data_result.sort_values(by="오차", ascending=True) #오름차순# 경향 대비 CCTV 많이 가진 구
df_sort_f.head()| 소계 | 최근 증가율 | 인구수 | 한국인 | 외국인 | 고령자 | 외국인 비율 | 고령자 비율 | CCTV비율 | 오차 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 구별 | ||||||||||
| 강남구 | 3238 | 150.619195 | 561052 | 556164 | 4888 | 65060 | 0.871220 | 11.596073 | 0.577130 | 1549.200326 |
| 양천구 | 2482 | 34.671731 | 475018 | 471154 | 3864 | 55234 | 0.813443 | 11.627770 | 0.522507 | 888.832166 |
| 용산구 | 2096 | 53.216374 | 244444 | 229161 | 15283 | 36882 | 6.252148 | 15.088118 | 0.857456 | 759.128697 |
| 서초구 | 2297 | 63.371266 | 445401 | 441102 | 4299 | 53205 | 0.965198 | 11.945415 | 0.515715 | 736.753199 |
| 은평구 | 2108 | 85.237258 | 491202 | 486794 | 4408 | 74559 | 0.897390 | 15.178888 | 0.429151 | 496.842700 |
# 경향 대비 CCTV 적게 가진 구
df_sort_t.head()| 소계 | 최근 증가율 | 인구수 | 한국인 | 외국인 | 고령자 | 외국인 비율 | 고령자 비율 | CCTV비율 | 오차 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 구별 | ||||||||||
| 강서구 | 911 | 134.793814 | 608255 | 601691 | 6564 | 76032 | 1.079153 | 12.500021 | 0.149773 | -830.268578 |
| 송파구 | 1081 | 104.347826 | 671173 | 664496 | 6677 | 76582 | 0.994825 | 11.410173 | 0.161061 | -730.205628 |
| 도봉구 | 825 | 246.638655 | 346234 | 344166 | 2068 | 53488 | 0.597284 | 15.448512 | 0.238278 | -625.016861 |
| 중랑구 | 916 | 79.960707 | 412780 | 408226 | 4554 | 59262 | 1.103251 | 14.356800 | 0.221910 | -607.986645 |
| 광진구 | 878 | 53.228621 | 372298 | 357703 | 14595 | 43953 | 3.920247 | 11.805865 | 0.235833 | -600.988527 |
from matplotlib.colors import ListedColormap
#colormap 을 사용자 정의로 세팅
color_step = ["#e74c3c", "#2ecc71", "#95a9a6", "#2ecc71", "#3498db", "#3498db"]
my_cmap = ListedColormap(color_step)def drawGraph():
plt.figure(figsize=(14, 10))
plt.scatter(data_result["인구수"], data_result["소계"], s=50, c=data_result["오차"], cmap=my_cmap)
plt.plot(fx, f1(fx), ls="dashed", lw=3, color="g") #plt.plot(x축,y축)
plt.xlabel("인구수")
plt.ylabel("CCTV")
plt.colorbar()
plt.grid(True)
plt.show()
drawGraph()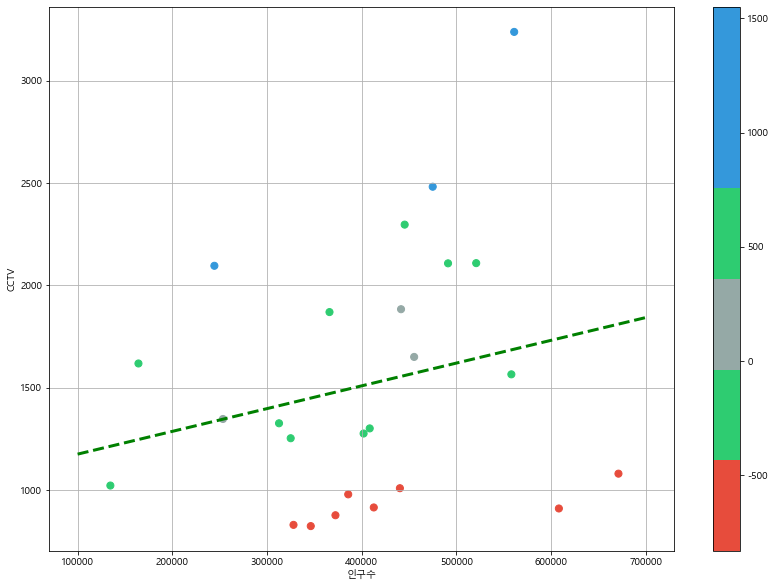
각 점에 해당하는 데이터값 출력
- plt.text() 활용
def drawGraph():
plt.figure(figsize=(14, 10))
plt.scatter(data_result["인구수"], data_result["소계"], s=50, c=data_result["오차"], cmap=my_cmap)
plt.plot(fx, f1(fx), ls="dashed", lw=3, color="g") #plt.plot(x축,y축)
#상위 5 개
for n in range(5):
plt.text(
df_sort_f["인구수"][n] * 1.02, # x좌표
df_sort_f["소계"][n] * 0.98, # y좌표
df_sort_f.index[n], # title
fontsize = 15
)
#하위 5개
plt.text(
df_sort_t["인구수"][n] * 1.02, # x좌표
df_sort_t["소계"][n] * 0.98, # y좌표
df_sort_t.index[n], # title
fontsize = 15
)
plt.ylabel("CCTV")
plt.colorbar()
plt.grid(True)
plt.show()
drawGraph()
# 데이터 저장
data_result.to_csv("../data/01.CCTV_result.csv", sep=",", encoding="utf-8")
데이터분석 스터디노트🧐✍️