Llama
in-context learning
-
zero - shot
프롬프트에 추가적인 설명 예제없이 바로 문제를 해결하려는 세팅 -
one - shot
추가적인 설명 예제 1개와 함께 문제를 해결하려는 세팅 -
Few - shot
예제 n개와 함께 문제 해결하려는 세팅창발 능력(Emergent abilities)
-
큰 llm 모델 학습 과정에서 특정 임계치 (파라미터 수)를 넘으면 기존 작은 llm 에서 발생하지 않았던 새로운 능력이 발현
( 상태가 변함) -
예측 불가능한 현상
-
시스템의 양적 변화가 행동의 질적 변화롤 이어질 때 발생
-
언어 모델의 규모를 늘리는 것이 다양한 하위 NLP 작업에서 더나은 성능으로 이어질 수 있다
-
few- shot promt
: 업데이트 없이 성능 극대화
-
예측은 단어 집합에 softmax regression값
( 층수 자리에 p로 나눈다)
→ 작을 경우 예측확률 증폭 → 그럴 듯한 토큰 뽑힐 확률 증가
→ 클경우 : 모든 토큰의 확률값이 평평 → 더욱 다양성있는 텍스트 생성 확률 증가
중간단위
- byte pair encoding
- 초기 단계 각문자를 기본단위로 취급하고 빈도 수를 계산
2.가장 빈도가 높은 연속문자쌍을 찾아 새로운 단위로 합친다 - 더이상 합칠 수 있는 문자쌍이 없거난 지정된 다어가 없을
- 초기 단계 각문자를 기본단위로 취급하고 빈도 수를 계산
- 동작과정
aaabdaaabac → ZabdZabac Z=aa → ZYdZYac Y =ab z= aa → XdXac x =ZY Y=ab Z=aa
close - book
-
llm을 테스트하기 위해
-
질문을하면 받는 모델을 찾아 비교
-
제로 샷 퓨샷 설정 어쩌구
제너레이션 모델을 파인튜닝해서 소스로 변환
llms의 능력은 트랜스포터머는 자기 지도 데이터의 광범위한 말몽치에 사전 학습되며, 인간의 선호와 맞추기위해 강화학습과 인간 피드백
-
높은 연산요구(리소스)
-페쇄된 제품 llms는 인간의 선호에 맞게 크게 세밀하게 조정되어 있어, 그들의 사용성과 안정성 크게 향상
70B 700억 파라미터 규모로 사전 훈련된 및 세밀하게 조정된 llms, Llama 2 계열을 개발하고 공개
lamma1 ▶ lamma2 (사전 훈련 말뭉치의 크기 40% 증가)
- 토큰 4k
- grouped - query attention채택
: 멀티쿼리 어텐션 쿼리여러개 당 키와 values - 7B, 13B, 70B 파라미터의 변형을 공개 34B변형도 훈련했지만 공개 x
SentencePiece
- 자연어 처리에서 텍스트를 토큰화하는 데 사용되는 오픈 소스 라이브러리
- SentencePiece는 단어를 서브워드 단위로 분할
- BPE와 Unigram 모델
SentencePiece는 두 가지 주요 알고리즘을 사용하여 토큰화를 수행
Byte Pair Encoding (BPE): 가장 자주 등장하는 바이트 쌍을 병합하여 새로운 토큰을 생성하는 방식
Unigram Language Model: 각 서브워드의 확률을 기반으로 최적의 서브워드 집합을 선택
fine tuning
- 지시어 튜닝과 RLHF 포함
- 다중턴에 걸친 대화 흐름을 제어하는데 도움이되는 고스트 어텐션(어떠한 사실을 부여, 어떤 지위를 부여) 공유
- 두번의 에포크
SFT (Supervised Fine-Tuning)
- 쿼리티가 모든것
- 고품질의 SFT 데이터의 수천가지 예시를 수집하는 데 중점을 둠
- 수만개 정도으 SFT 주석만으로 높은 품질 결과 달성 가능
- SFT를 통해 모델의 성능을 향상시킬 수 있으며, 특정 도메인이나 어플리케이션에 맞는 최적화된 결과 가능
파인튜닝 세분화
프로프트와 답변 세그먼트를 구분하기 위해 특별한 토큰 사용
-사용자 프롬프트 토큰에서 손실을 0 → 답변 토큰에만 역전파
RLHF
- 인간의 어노데이터들은 모델 출력중 어느것을 선호하는지 선택
- 인간의 피드벡은 이후 보상 모델을 훈련하는데 사용
- 모델은 인간 어노데이터의 선호패턴을 학습해 결정
-다양성을 최대화하기 위해 주로 이진 비교 프로토콜 선택
- 유용성과 안전성에 중점을 둔다
모델응답
1. 선호하는 응답이 안전하고 다른 응답은 그렇지 않음
2. 두 응답 모두 안전함
3. 두 응답 모두 안전하지 않음
Reward modeling
- 보상 모델을 미리 훈련된 채킹 모델 체크포인트에서 초기화
- 두개의 별도의 보상 모델을 훈련 → 하나는 도움성을최적화하기 위한것
- 스칼라 보상을 출력하기 위한
- 한번의 에포크 동안
- 70B
- 배치크기 512 고정
irerative fine - tuning
- 연속된 RLHF
- 강화 몇개 등등
human evaluation
alpaca
-
Llama 1 7B 모델을 지시어 튜닝
-
사전훈련된 베이스 모델과 고품질명령수행 데이터 필요 (첫번째 도전과제 해결)
-
self instruct눈문 어쩌구
parameter-Efficient Fine-Tuning
(PEFT)
- 모든 모델의 매개변수를 미세조정하지 않고도 사전 훈련된 언어모델을 다양한 하위 작업에 효과적으로 적응
- PEFT 소수 모델 매개변수만을 미세조정하여 계산 및 저장 비용을 크게 줄인다
lora(row rank adaptation)
- 학습된 과도하게 매개변수화된 모델이 실제로는 낮은 본질적 차원에서 존재함을 보여줌 (작은 부분 공간으로으 무작위 투영에도 불구하고 효율적)
- 사전 훈련된 가중치를 고정시킨 상태에서 적응동안의 밀집 계층의 변화의 순위 분해 행렬
- 공유 모델을 고정 시키고 행렬을 교체함으로써 효율적 작ㅂ업 전환
- 하드웨어 진입 장벽을 최대 3배ㄱ까지 낮춘다
- 횔씬 작은 저랭크 행렬만 최적화 자기 주의 모듈
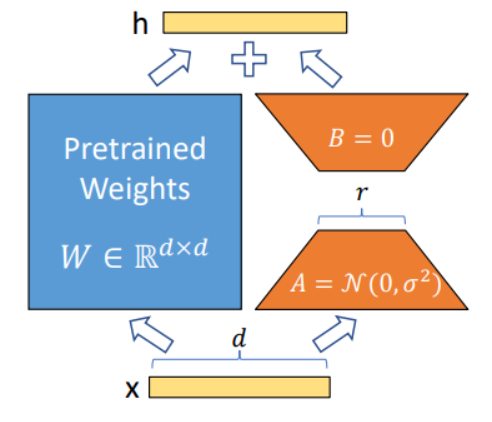
W_q : query layer 를 뜻한다. (차원은 d x k 이다.)
W_k : key layer 를 뜻한다. (차원은 d x k 이다.)
W_v : value layer 를 뜻한다. (차원 은 d x k 이다.)
W_o : self-attention layer 를 뜻한다. (차원은 k x d 이다.)
훈련죽 W_0가 고정되어 경사 업데이트를 받지 않으면, a와 b는 훈련가능한 매개변수를 포함
-추가추론지연시간 없음
랭체인
언어모델로 구동되는 애플리케이션 개발 프레임워크
라이브러리
llm에 학습과정에 포함되지 않은 지식을 주입하는 방법(할루시네이션 방지)
파인튜닝 : 새로운 지식에 관한 텍스트 데이터 소스를 이용해 파라미터를 파인튜닝
peft : 일부 갱신
retrieval- augmented generation(RAG)
새로운 지식에 관한 텍스트 소스를 embedding 해서 vectior stores에 저장하고, 프롬프트 구성을 진행할 때 외부데이터 소스로 부터 가져온 텍스트 데이터를 이용해 프롬프트를 구성한뒤 llm에서 답변을 얻는다.
외부텍스트소스와 주어진 질문을 결합해서 답변 생성
Large Language Models are Zero-Shot Reasoners
https://velog.io/@nochesita/%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-Large-Language-Models-are-Zero-Shot-Reasoners
TAKE A STEP BACK:
https://velog.io/@ingeol/TAKE-A-STEP-BACK-EVOKING-REASONING-VIA-ABSTRACTION-IN-LARGE-LANGUAGE-MODELS
👉 word2vec 연산 체험 사이트
https://word2vec.kr/search/
embedding
사칙연산
tSNE 이용 2개의 차원으로
openai 활용
검색
클러스터링
추천
이상탐지
다양성 측정
분류
