
Downward API
Downward API는 생성된 pod에 대한 정보를 알 수 있는 리소스다.
pod가 생성되기 전에 알 수 없는 pod의 manifest나 속성들을 알 수 있는 것이다.
Downward API는 kube-API 서버로부터 정보를 얻어 환경변수나 볼륨 형태로 제공한다.
Downward API를 통해 전달할 수 있는 정보들
- pod의 이름
- pod의 IP주소
- pod가 속한 네임스페이스
- pod가 실행 중인 node의 이름
- 각 컨테이너의 CPU와 메모리 request
- 각 컨테이너의 CPU와 메모리 limit
- pod의 Label과 annotation
Downward API를 이용하는 방법
-
환경변수를 이용한 방법
- pod 생성 이후, 외부에서 변경할 수 없는 정보를 사용하는 경우
-
볼륨을 이용한 방법
- pod 단위로 정의되기 때문에 다른 컨테이너 정보를 활용할 때 용이
- 실행되는 동안 수정될 수 있는 정보를 저장하기에 적합
일부 정보는 둘 중 하나의 방법만 사용할 수 있다.
< 환경변수를 이용한 방법 >
apiVersion: v1
kind: Pod
metadata:
name: dapi-envars-fieldref
spec:
containers:
- name: test-container
image: k8s.gcr.io/busybox
command: [ "sh", "-c"]
args:
- while true; do
echo -en '\n';
printenv MY_NODE_NAME MY_POD_NAME MY_POD_NAMESPACE;
printenv MY_POD_IP MY_POD_SERVICE_ACCOUNT;
sleep 10;
done;
env:
- name: MY_NODE_NAME # Pod가 생성된 node명 환경변수 저장
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: MY_POD_NAME # 현재 생성된 pod명을 환경변수로 저장
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: MY_POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: MY_POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: MY_POD_SERVICE_ACCOUNT
valueFrom:
fieldRef:
fieldPath: spec.serviceAccountName
restartPolicy: Never< 볼륨을 이용한 방법 >
apiVersion: v1
kind: Pod
metadata:
name: kubernetes-downwardapi-volume-example
labels:
zone: us-est-coast
cluster: test-cluster1
rack: rack-22
annotations:
build: two
builder: john-doe
spec:
containers:
- name: client-container
image: k8s.gcr.io/busybox
command: ["sh", "-c"]
args:
- while true; do
if [[ -e /etc/podinfo/labels ]]; then
echo -en '\n\n'; cat /etc/podinfo/labels; fi;
if [[ -e /etc/podinfo/annotations ]]; then
echo -en '\n\n'; cat /etc/podinfo/annotations; fi;
sleep 5;
done;
volumeMounts:
- name: podinfo
mountPath: /etc/podinfo
volumes:
- name: podinfo
downwardAPI: # 생성된 pod의 label과 annotations를 볼륨으로 저장
items:
- path: "labels"
fieldRef:
fieldPath: metadata.labels
- path: "annotations"
fieldRef:
fieldPath: metadata.annotationslabel, annotation 파일은 심볼릭 링크를 사용하므로 메타데이터의 동적, 원자적 갱신이 가능
Downward API의 한계
- downward api를 통해서 pod 자기 자신의 메타데이터 및 속성 정보를 얻을 수 있지만, 다른 pod의 리소스를 얻을 수는 없다.
- 다른 pod의 리소스 정보를 얻을 때는 api 서버를 직접 거쳐야 한다.
- pod내에서 API 서버에 접근할 때는 다음을 참고
HPA
- Horizontal pod autoscaling
- CPU 또는 메모리 사용량을 기반으로 실행되는 포드의 개수를 조절
- 사용자 정의 메트릭, 다른 애플리케이션 메트릭을 관찰하여 스케일링
- 데몬셋과 같은 오브젝트에 적용되지 않음
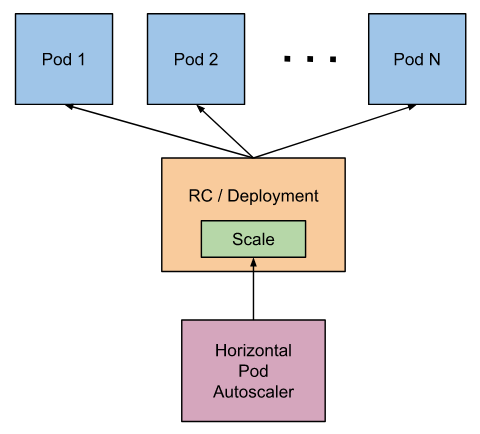
동작원리(cAdvisor + Metric server 조합)
-
각 노드에서 pod의 metric은 kubelet의 cAdvisor를 통해서 수집된다.
-
cAdvisor 에이전트로 수집된 메트릭을 바탕으로 전체 클러스터에 대한 리소스 연산은 Metric 서버에서 진행된다.
-
HPA는 Metric 서버의 API 호출을 통해 메트릭을 관찰하고 이를 바탕으로 스케일링한다.
참고: 메트릭 서버 VS 프로메테우스
프로메테우스는 커스텀 메트릭까지 수집할 수 있다.
Autoscaling 메커니즘
원하는 replicas = ceil[ 현재 replicas * (현재 target 값/ 목표 target 값) ]
HPA 사용하기
imperative way로 hpa 생성하기
php-apache pod에 HPA를 적용하여 CPU 50%를 목표 target으로 한다.
(php-apache deployment는 이미 생성되어 있음을 가정)
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50VPA
- Vertical pod autoscaling
- pod의 사용량에 맞게 리소스 양을 조절해 pod가 노드에 스케줄링 될때 적절한 크기의 리소스를 할당 받을 수 있도록 한다.
- stateful 서비스를 위해서 사용된다.
- HPA와 동시적용이 힘들다.
- HPA와 마찬가지로 메트릭 서버를 통해서 스케일 여부를 결정
- 현재까지는 미완성된 Beta 버전
동작방식
VPA를 설치하면 다음과 같이 세가지 기능을 하는 Pod를 확인할 수 있다.

-
VPA-admission-controller는 VPA를 통해 api 서버로 요청이 들어왔을 때, 유효성 체크, 수정 등의 작업을 한후, 요청을 실행할지 말지 결정한다.
-
vpa-recommender는 metric-server에서 받아온 리소스 사용량 히스토리와 현재 리소스 사용량을 비교해서 각각의 Pod에 알맞는 리소스크기를 추천한다.
-
vpa update는 1분에 한번씩 정기적으로 돌면서 실행되고 있는 Pod의 리소스가 recommender의 추천 리소스 범위에 있는지 체크한다.
만약 그렇지 않다면, pod를 노드에서 evict시켜 pod가 재시작되도록 한다.
VPA 사용하기
apiVersion: "autoscaling.k8s.io/v1beta2"
kind: VerticalPodAutoscaler
metadata:
name: hamster-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: hamster
resourcePolicy:
containerPolicies:
- containerName: '*'
minAllowed:
cpu: 100m
memory: 50Mi
maxAllowed:
cpu: 1
memory: 500Mi
controlledResources: ["cpu", "memory"]minAllowed와 maxAllowed를 통해 리소스의 범위를 제한할 수 있다.
이후, describe 커맨드를 통해서 VPA가 추천하는 리소스양을 확인할 수 있다.
kubectl describe vpa hamster-vpa기본적으로 VPA의 default 설정은 Auto이므로 Pod의 리소스 크기를 알아서 수정한다. 만약 자동수정을 원치 않는다면 spec.updatePolicy.updateMode: "Manual"로 수정하면 된다.
다른 블로그를 참고 했습니다.
Pod Disruption Budget
PDB는 시스템 관리자가 노드 업그레이드 등과 같이 일시적으로 노드를 disable 해야하는 상황에서
최소한의 가용성을 보장해야 할때 사용할 수 있다.
노드 스케줄링 비활성화
Taint와 Toleration을 이용해서 노드에 스케줄링을 제한 할 수 있지만,
다음과 같이 명시적으로 노드의 사용을 제한하는 cordon과 drain이라는 방법 또한 있다.
노드 업그레이드와 같이 일시적으로 노드 사용을 중지 시켜야 하는 상황에서 cordon과 drain을 사용한다.
- cordon과 drain
-
cordon
cordon을 노드에 적용하면, pod들이 스케줄링 되지 않는다.(SchedulingDisabled)
그리고 기존 노드 위에 실행중인 pod들은 존재하기만 할뿐, 종료되지 않는다. (단지 트래픽이 해당 pod에 전달되지 않는다)
-
drain
drain은 cordon과 같이 노드를 unschedule 상태로 만든다는 것은 같지만, 기존에 실행 중이던 포드들을 다른 노드로 이동시킨다.(ReplicasSet으로 지정되어 있는 경우)describe node을 통해 내부적으로 살펴보면 Taints 항목에 node.kubernetes.io/unschedulable:NoSchedule, Unschedulable: true로 설정된다.
-
- uncordon
cordon이나 drain 커맨드를 통해 노드가 unschedule 상태일 때 uncordon 커맨드를 통해 노드의 상태를 schedule로 바꾸어줄 수 있다.
PDB 사용하기
정해진 수의 Pod가 필수적으로 돌아가야하는 경우 PDB를 사용한다.
다음은 app: zookeeper 레이블을 갖는 파드를 최소 2개를 유지하겠다는 PDB yaml이다.
(zookeeper deployment는 이미 배포되었다는 것을 가정)
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: zk-pdb
spec:
minAvailable: 2
selector:
matchLabels:
app: zookeeper위와 같은 PDB가 선언되었을 때 drain이나 cordon을 노드에 적용하면
zoopkeeper pod의 가용성을 최소한으로 보장할 수 있다.
위 PDB가 적용되는 pod는 반드시 2개 이상의 replicas를 유지하여야 하며,
예외 발생시 drain 또는 cordon 커맨드는 fail이 발생한다.
PDB 활용
- stateful한 애플리케이션에 사용
- 일정 성능 이상을 요하는 애플리케이션에 사용
DaemonSet
데몬셋은 모든 노드에 동일한 pod를 하나씩 배포해야하는 상황에서 사용된다.
데몬셋으로 파드 생성시 클러스터에 노드가 새롭게 추가되거나 제거되었을 때 자동으로 파드가 생성되거나 제거된다.
DaemonSet 활용
- 로그수집기
- 노드를 모니터링할 때
- 네트워킹(Kube-proxy, calico)
DaemonSet 사용하기
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
updateStrategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v2.5.2
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers참고할 부분이라고 한다면 daemonset은 deployment와 달리 replicas가 없고,
이 yaml의 경우 master에도 pod를 생성해주기 위해 master에 대한 toleration을 추가하였다.
StatefulSet
statefulset이라는 이름 그대로 상태를 갖는(Stateful) 포드를 관리하기 위한 오브젝트이다.
StatefulSet의 특징
- 생성된 파드들은 무작위 이름이 아닌 정해진 이름을 갖는다.
- web-0, web-1, web-2...
- spec.serviceName을 통해 헤드리스 서비스를 정의한다.
- 헤드리스 서비스: 기존의 서비스는 포드로 무작위 접근이었다면 헤드리스 서비스는 [파드의 이름].[서비스 이름]으로 정해진 포드에 접근한다.(stateful을 가능하게 하는 이유)
- ClusterIP: None 상태를 갖는다.
- spec.volumeClaimTemplates 속성을 통해 각 파드마다 퍼시스턴트 볼륨 클레임을 자동으로 생성하여 다이나믹 프로비저닝 기능을 사용할 수 있도록 한다.
- 만약 statefulset에 의해 3개의 파드가 생성된다면, pvc, pvc도 각각 3개씩 생성되어 각 포드에 마운트된다.
- statefulset을 삭제해도 생성된 볼륨은 함께 삭제되지 않는다.
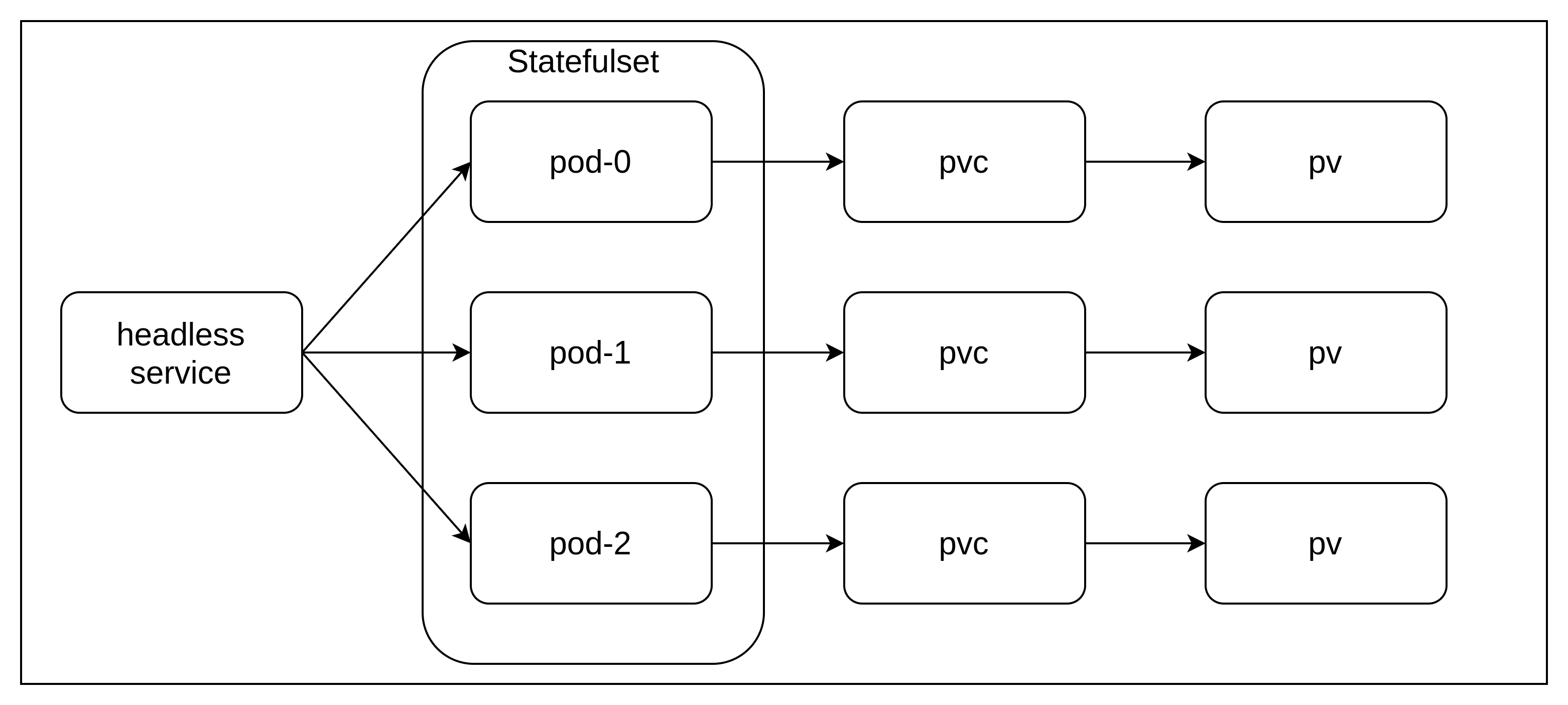
StatefulSet 사용하기
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
selector:
matchLabels:
app: nginx # has to match .spec.template.metadata.labels
serviceName: "nginx" # headless service
replicas: 3 # by default is 1
template:
metadata:
labels:
app: nginx # has to match .spec.selector.matchLabels
spec:
terminationGracePeriodSeconds: 10
containers:
- name: nginx
image: k8s.gcr.io/nginx-slim:0.8
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "my-storage-class"
resources:
requests:
storage: 1Gi3개의 Pod를 갖는 statefulset을 생성한다.
이때 nginx라는 이름을 갖는 headless service도 함께 생성된다.
volumeClaimTemplates를 필드를 보면, storageclass를 통해서 pv, pvc도 동적으로 함께 생성된다.
Job
job은 포드를 생성하여 그 안에서 특정 동작을 수행하고 종료되면 pod를 삭제하는 오브젝트
Job 활용
- 배치 워크로드
- 메시지큐에 저장해 둔 작업을 Job이 꺼내와 처리하는 패턴을 사용
Job 사용하기
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never특정 일을 하는 job을 실행시킨다.
restartPolicy: Never를 통해서 Pod가 종료되어도 다시 시작하지 않는다.
만약 Never가 아닌 onFailure라면 Pod가 실패했을 때(0이 아닌 종료코드를 반환했을 때) job은 재시작 된다.
세부옵션
- spec.completions 몇 개의 파드가 성공해야 Job이 성공하는지를 명시
- spec.parallelism 동시에 실행될 수 있는 파드의 개수를 명시
CronJob
크론잡은 리눅스의 크론탭과 동일하게 특정 주기로 잡을 주기적으로 실행하는 오브젝트이다.
CronJob 활용
- 주기적 데이터 백업
- 주기적 이메일 전송
CronJob 사용하기
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailureJob과는 달리 spec.schedule 필드가 추가되어 job을 주기적으로 실행시킨다.
위 cronjob manifest는 1분마다 현재 시간과 hello를 출력하는 job을 생성한다.

잘 보고 갑니다~~