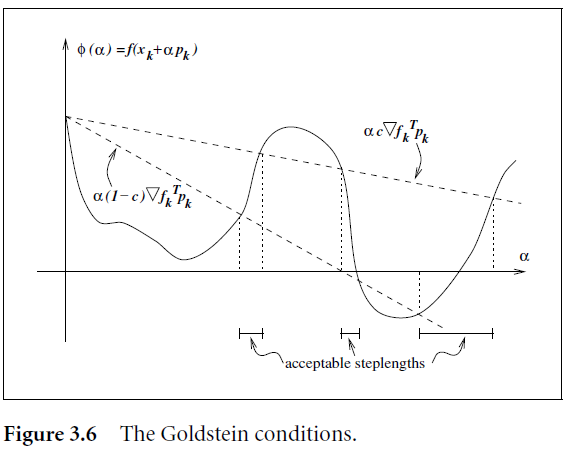
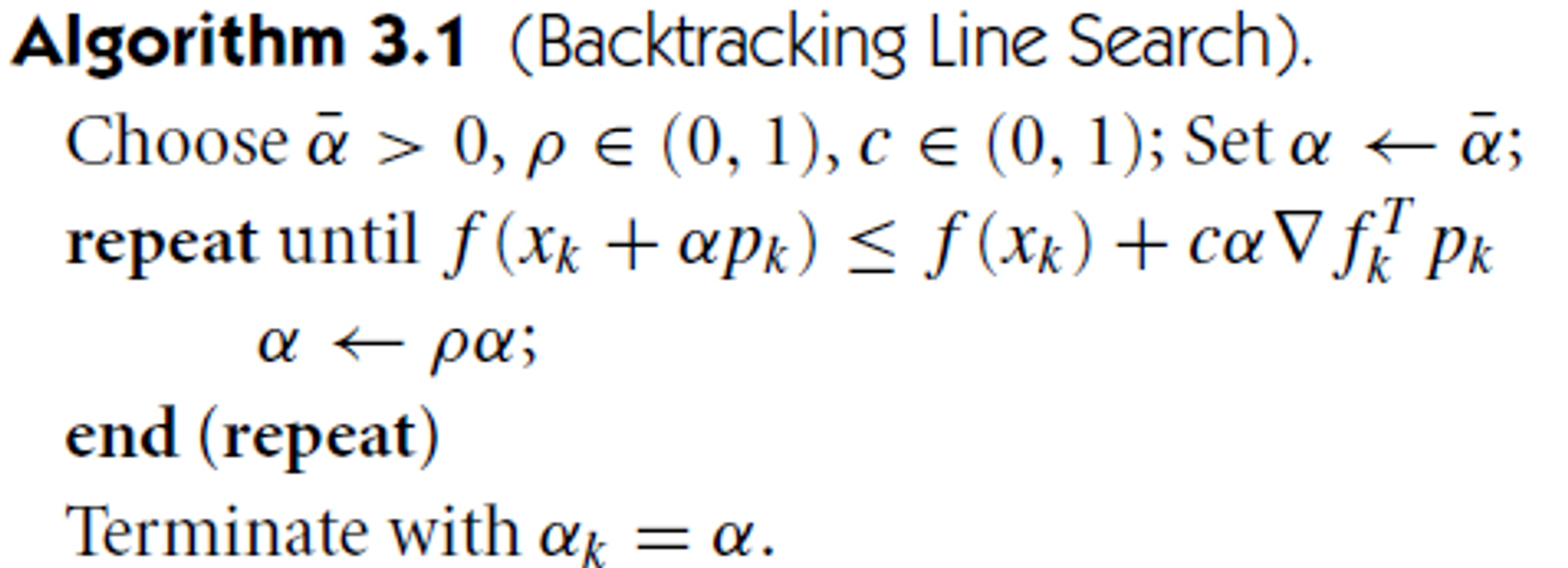sufficient decrease 하면서 너무 작은 step length는 제외하도록 만든 조건.
Backtracking
Sufficient decrease를 만족할 때까지 α를 업데이트함. (조건을 만족하는 가장 큰 α 값이 선택됨.)
Convergence of line search method
Zoutendijk’s theorem
xk+1=xk+αkpk (이 때, pk는 descent direction이고, αk는 Wolfe condition을 만족)을 iterate 할 때, f가 Rn 에서 아래로 bound 되어있고, f가 level set L={x:f(x)≤f(x0)} (x0은 iteration의 시작점)을 포함하는 open set Y∈N안에서 continuously differentiable 하다고 가정하자. 또, gradient ∇f가 N에서 Lipschitz continuous 하다고 가정하면
이 결과를 다시 Wolfe condition의 sufficient decrease에 넣으면
fk+1≤fk−c1L1−c2∣∣pk∣∣2(∇fkTpk)2
steepest descent direction −∇fk와 임의의 search direction pk 사이의 angle은
cosθk=∣∣∇fk∣∣∣∣pk∣∣−∇fkTpk
임을 활용하고, 임의의 상수들을 뭉뚱그려 c로 표현하면
fk+1≤fk−ccos2θk∣∣∇fk∣∣2
따라서 fk는 monotonic decreasing 한다. 그런데 fk 아래로 bound 되어 있으니,
k=0∑∞cos2θk∣∣∇fk∣∣2<∞
cos2θk∣∣∇fk∣∣2→0
여기서 θ가 90도에서 충분히 멀다면 cosθk>0 이므로,
k→∞lim∣∣∇fk∣∣=0
위 조건을 만족하는 알고리즘들을 globally convergent 하다고 한다. 하지만, 위 조건은 단순히 알고리즘이 stationary point로 converge 한다는 것만 보장하고 그 point가 minimizer일 것은 보장하지 못한다. 후자를 위해서는 curvature ∇2f(xk)가 negative 하다는 추가 조건이 필요하다.
Newton-like method에 위 결과를 적용해보자. (Newton-like method : p=−B−1∇f) Bk가 positive definite 이고, uniformly conditioned condition number를 갖는다면 (즉, 모든 k에 대해 ∣∣Bk∣∣∣∣Bk−1∣∣≤M)
cosθk≥1/M>0
증명
cos(θ)=−∣∣∇f∣∣∣∣p∣∣∇fTp=∣∣Bp∣∣∣∣p∣∣pTBp
이 때, ∣∣Ax∣∣≥∣∣A∣∣∣∣x∣∣ (Cauchy-Schwarz inequality) 이므로
Square real matrix A가 positive semidefinite이다와 어떤 matrix B에 대해 A=BTB이다는 동치이다. 이런 matrix B는 여럿이 존재할 수 있는데 positive semidefinite한 것은 오직 하나만 존재할 수 있다. 그러한 B를 principal, non-negative, positive square root라고 부른다.
따라서 동일하게 limk→∞∣∣∇fk∣∣=0 이다.
그런데 conjugate gradient에서는 이것이 성립하지않고 약한 inflimk→∞∣∣∇fk∣∣=0 까지만 성립한다.
증명
만약 모든 k>K에 대해서 ∣∣∇fk∣∣≥γ를 만족하는 γ>0이 존재하다면, cosθk→0 이다. 그런데, 0으로부터 떨어진 {cosθj} subseqeuence가 존재함을 보일 수 있으므로 모순이다.
위의 증명 테크닉을 응용하면 1) 매 iteration이 objective function을 감소시키고 2) 매 m 번째 iteration이 steepest descent step이며 step size가 Wolfe condition이나 Goldstein condition을 만족시키는 모든 알고리즘에 대해서 gloabl convergence를 증명할 수 있다.
Rate of convergence
Global convergence를 위한 조건과 rapid convergence를 달성하는 알고리즘은 때로 서로 상충한다. Rate of convergence를 분석하기 위해 다음의 objective function을 가정하자.
f(x)=21xTQx−bTx
이 때, Q는 symmetric, positive definite. Gradient는 ∇f(x)=Qx−b 이고, minimzer x∗는 Qx=b의 유일해다. Exact step size αk는 f(xk−α∇fk)의 미분값이 0이 되도록 계산하면 쉽게 얻을 수 있다.
αk=∇fkTQ∇fk∇fkT∇fk
Steepest descent method는 그럼 다음과 같다.
xk+1=xk−(∇fkTQ∇fk∇fkT∇fk)∇fk
Convergence of steepest descent method
weighted norm ∣∣x∣∣Q2=xTQx 라고 정의하자. Qx∗=b 이므로
⁍
따라서 ∣∣⋅∣∣Q2은 현재 objective function 값과 optimal 값의 차이의 측도이다. xk와 xk+1에 대해 위 식을 적용하면
이 때, 0<λ1≤⋯≤λn 는 Q의 eigen value이다. 모든 eigen value의 값이 같다면 한 iteration만에 converge 한다. λn/λ1의 값이 커질수록 iteration할 때 지그재그로 움직이는 성질이 두드러진다.
위에서 가정했던 objective function이 아니어도, 일반적인 nonlinear objective function에도 똑같이 적용된다. f:Rn→R 이 twice continuously differentiable 하고, exact line search를 이용한 steepest descent가 x∗ (∇2f(x∗)는 positive definite)으로 수렴한다 가정하자. 그러면 모든 k>K에 대해
f(xk+1)−f(x∗)≤r2[f(xk)−f(x∗)]
이 때, r∈(λn+λ1λn−λ1,1)
Newton method
pkN=−∇2fk−1∇fk
여기서 ∇2fk가 positive definite이 아니라면 pkN가 descent direction이 아닐 수 있다. 그러면 Convergence of steepest descent method에서 나온 결과가 적용될 수 없다. 자세한 건 나중에 더 논의하고, 일단은 local rate-of-convergence에 대해 얘기하자. ∇2f(x∗)가 positive definite인 x∗의 neighborhood 역시 Hessian이 positive definite 할 것이다. 이 영역에서 step length αk가 1이라면 Newton’s method는 quadratic하게 converge 한다.
Theorem 3.5
f가 twice differentiable이고, x∗(∇f(x∗)=0, ∇2f(x∗)는 positive definite)의 neighborhood에서 ∇2f(x)가 Lipschitz continuous하고, xk+1=xk+pkN라 하자. 그러면
이 때, L~=L∥∇2f∗−1∥이다. 초기값 x0을 ∥x0−x∗∥≤min(r,1/(2L~))을 만족하도록 잡으면 sequence {xk}는 x∗로 quadratic 하기 수렴한다. (min에서 정확히 1/(2L~)일 필요 없이 1/L~보다 작은 값이면 될 것 같다.)
Step length αk는 Wolfe condition을 만족하도록 back tracing을 통해 얻는 상황을 가정 (αkˉ=1).
Theorem 3.6
f가 twice continuously differentiable이라 가정하자. xk+1=xk+αkpk를 통해서 업데이트하는데, 이 때, pk가 descent direction이고 αk가 Wolfe condition을 c1≤1/2로 만족한다고 하자. 만약 {xk}가 ∇f(x∗)=0이고 ∇2f(x∗)가 positive definite인 점 x∗로 수렴한다 가정하고, 또 만약 search direction pk가
k→∞lim∥pk∥∥∇fk+∇2fkpk∥=0
을 만족하면
모든 k>k0에 대해 ak=1이 허용되고,
1의 경우 {xk}가 x∗로 superlinearly converge 한다.
마지막 search direction 조건은 quasi-Newton method에서
k→∞lim∥pk∥∥(Bk−∇2f(x∗))pk∥=0
와 동등하다. 즉 Bk가 pk를 따라서만 ∇2f(x∗)를 approximation하면 성립한다. 이 조건은 필요충분조건이다.
Theorem 3.7
f가 twice continuously differentiable이라 가정하자. xk+1=xk+pk를 통해서 업데이트하는데, 이 때, pk=−Bk−1∇fk라고 하자. 만약 {xk}가 ∇f(x∗)=0이고 ∇2f(x∗)가 positive definite인 점 x∗로 수렴한다 가정하자. 그러면, {xk}이 superlinearly converge한다는 아래의 조건과 동치이다.
O가 들어간 등호는 x∗에 충분히 가까운 xk에 대해서 ∥∇2fk−1∥가 위로 bound 되어 있다는 점에서 성립한다 (∇2f(x∗)이 positive definite해서. Theorem 3.5 증명의 링크 참조). 마지막 o가 들어간 등호는 search direction 조건이 만족한다는 조건하에 성립한다. 거꾸로 pk−pkN=o(∥pk∥)이면 search direction 조건이 만족된다는 증명은
O 항은 Theorem 3.5의 증명에서 왔다(Newton method에 대한 정리). 마지막 inequality는 ∥pk∥=O(∥xk−x∗∥) (∥pk∥≤∥xk−x∗∥+∥xk+pk−x∗∥)에서 왔다. 결론적으로 superlinearly converge 한다.
o, O, Ω 정의
ηk=O(vk)
충분히 큰 모든 k에 대해 ∣ηk∣≤C∣vk∣를 만족하는 상수 C>0이 존재
ηk=o(vk)
limk→∞vkηk=0
ηk=Ω(vk)
C0∣vk∣≤∣ηk∣≤C1∣vk∣을 만족하는 상수 0<C0≤C1<∞가 존재
Newton’s method with Hessian modification
Hessian matrix가 positive definite 하지 않으면 Newton direction이 descent direction이 아닐 수 있다. Hessian을 살짝 수정해서 pkN과 크게 차이나지 않는 pk를 구하는 일련의 알고리즘들에 대해 얘기하자. 제너럴하게 알고리즘을 적어보자면 아래와 같다. 이 때 Ek가 modification matrix이다. (일부 알고리즘은 Ek를 explicit하게 구하지 않기도 한다.)
Convergence of line search method에서 언급했듯 {Bk}가 bounded condition number을 가지도록 Ek를 설정하면 (κ(Bk)=∥Bk∥∥Bk−1∥≤C. 이 때, C>0, k=0,1,…) global convergence를 만족할 것이다.
Theorem 3.8
f가 open set D에서 twice continuously differentiable하다 가정하고, level set L={x∈D:f(x)≤f(x0)}이 compact하도록 Algorithm 3.2의 시작점 x0을 잡자. {Bk}가 bounded condition number을 가지면
k→∞lim∇f(xk)=0
∇2f(x∗)가 충분히 positive definite 하다면 iteration이 충분히 진행되면 k>k0에 대해 Ek=0이 되며 pure Newton method와 마찬가지로 quadratic하게 수렴한다. ∇2f(x∗)가 singular의 가까운 경우 Ek가 vanish 할 것이라 보장할 수 없고 convergence rate도 linear 할 수 있다. Ek는 condition number 조건을 만족하는 동시에 modification을 최소화 하여야 하며, 현실적인 문제로 계산이 용이해야한다.
EVD 후 negative eigenvalue인 부분을 numerical analysis 측면에서 가장 작은 양수δ로 바꾼다. 그런데 이렇게 바꿀 경우 pk=−Bk−1∇fk의 방향이 eigenvalue가 δ인 eigenvector로 치우치게 된다. 이를 해결하기 위한 방법에는 여러가지가 있고, 어떤게 최선인지는 합의된 바 없다. (생략) 그래도 이게 어떤 측면에서는 최선인 부분이, A=QΛQT가 symmetric matrix라면, 모든 eigenvalue가 δ보다 크도록 만들고 minimum Frobenius norm을 가지는 ΔA는
ΔA=Qdiag(τi)QTwith{0λi≥δδ−λiλi<δ
ΔA는 일반적으로 non-diagonal이다. 조건을 바꿔 minimum Euclidean norm을 달성하도록 만들면 diagonal한 ΔA를 얻을 수 있다.
ΔA=τIwithτ=max(0,δ−λmin(A))
∇2f(xk)+τI가 충분히 positive definite 하도록 만드는 τ는 다음 같은 알고리즘을 통해 찾을 수 있다.
다른 접근법으로는 Cholesky factorization을 하면서 diagnoal element의 값을 수정하는 방법이다. 이 방법은 modified Cholesky factor가 존재하고, 그 factor가 actual Hessian의 norm에 relative하게 bound 되고, Hessian이 충분히 positive definite 한 경우에는 modify하지 않는 것을 보장한다. 일반적인 Cholesky factorization은 A=MMT의 형태를 띄지만 여기서는 A=LDLT인 방식을 다루자. A가 indefinite하면 factorization이 존재하지 않거나, Cholesky factorization이 numerical하게 unstable해서 특정 element의 값이 지나치게 커질 수 있다. 따라서 분해하고 modify하는 것이 아니라 분해 과정 자체를 수정할 필요가 있다.
modify하는 경우 여기서 3번째의 dj를 구하는 식만
dj=max(∣cjj,(βθj)2,δ),withθj=j<i≤nmax∣cij∣
로 바꾸면 된다. 이렇게 구한 Bk는 bounded condition number 조건을 만족한다.
마지막으로 symmetric indefinite factorization을 이용하는 방법을 소개하자. Symmetric matrix A는 다음과 같이 쓸 수 있다.
PAPT=LBLT
이 때, L은 unit lower triangular, B는 1(or 2)-dimensional block diagonal, P는 permutation matrix이다. Block diagonal matrix B를 사용함으로써 factorization이 numerically stable해진다. 또 B의 2x2 block은 항상 1개의 positive eigenvalue와 1개의 negative eigenvalue를 가지므로 분해하고나면 positive eigenvalue, negative eigenvalue 세기가 용이하다. symmetric indefinite factorization을 이용한 modification 방법은 먼저 LBLT로 분해한 다음 다시 B=QΛQT로 EVD한다 (B의 구조때문에 계산복잡도가 낮다). 그 후 modification matrix F를 L(B+F)LT가 충분히 positive definite 하도록
F=Qdiag(τi)QTwith{0λi≥δδ−λiλi<δ
을 통해 구한다. Cholesky와 다르게 nondiagonal하다.
Step-length selection algorithms
ϕ(α)=f(xk+αpk)
의 minimum을 찾는 문제를 생각해보자. pk는 descent direction (ϕ′(0)<0)이어서 α>0만 탐색하면 된다. 만약에 f가 convex quadratic (f(x)=21xTQx−bTx)이면
αk=−pkTQpk∇fkTpk
이다. f가 일반적인 nonlinear function이면 iterative하게 탐색해야한다. Line search 알고리즘은 사용하는 derivative 정보에 따라 분류된다. 함수 값 자체만 사용하는 방식은 효율이 낮고, first derivative를 사용한다면 Wolfe condition이나 Goldstein condition을 성립하는지 확인할 수 있다. 일반적으로 xk가 x∗에 충분히 가까울 때는 처음 고른 α가 condition들을 만족할 때가 많고 line sarch를 할 필요가 없다.
일반적으로 line search는 1) bracketing phase: interval [aˉ,bˉ]를 구하는 과정, 2) selection phase: 최종 αk를 구하는 과정으로 나뉜다. αk로 적으면 각 iteration에서 정해진 step length, αi로 적으면 한 iteration에서 line search 과정 중에 trial 해보는 step length라고 하자.
Interpolation
line search의 목적은 sufficient decrease 하는 αi 중에 너무 작지 않은 값을 찾는 것이기 때문에 αi는 αi−1에 비해 너무 작지 않게 만든다. Sufficient decrease 조건은
ϕ(αk)≤ϕ(0)+c1αkϕ′(0)
알고리즘이 derivative를 적게 계산할수록 효율적이라고 정의한다. 만약 α0가 sufficient decrease하면 search를 종료한다. 그렇지 않다면, interval [0,α0]을 얻을 것이다. ϕ(0), ϕ′(0), ϕ(α0)을 이용해서 quadratic하게 interpolation 한다.
ϕq(α)=(α02ϕ(α0)−ϕ(0)−α0ϕ′(0))α2+ϕ′(0)α+ϕ(0)
다음 trial value α1은 interpolation 된 함수의 minimzer로 정한다.
α1=−2[ϕ(α0)−ϕ(0)−ϕ′(0)α0]ϕ′(0)α02
만약 α1이 sufficient decrease 조건을 만족하면 search는 종료, 그렇지 않으면 이번에는 ϕ(0), ϕ′(0), ϕ(α0), ϕ(α1) 네 정보를 가지고 cubic하게 interpolation 한다.
일반적으로 cubic interpolation을 이용하면 αi가 quadratic하게 converge한다.
Initial step length
Newton, quasi-Newton method에서는 항상 α0=1을 사용하는 것이 좋다. Steepest descent나 conjugate gradient 같은 경우(scale sensitive한 알고리즘)에는 알고있는 정보를 활용해야하는데, 가장 보편적인 전략은 first-order 변화가 저번 step과 이번 step에서 동일할 것이라 가정하는 것이다. 즉, α0∇fkTpk=αk−1∇fk−1Tpk−1이므로
α0=αk−1∇fkTpk∇fk−1Tpk−1
다른 방법은 f(xk−1), f(xk), ∇fk−1Tpk−1을 이용해서 interpolation 하는 방법이고, 이 경우
α0=ϕ′(0)2(fk−fk−1)
가 된다. xk→x∗ superlinearly converge 할 때, 위 식의 값은 1로 수렴한다.
Line search algorithm for the Wolfe condition
알고리즘은 2단계로 구성되어있다. 먼저 initial trial α1로 시작해서 acceptable한 step length를 찾거나, desired step length가 있을 interval을 찾을 때까지 값을 키운다. 만약에 interval을 구했다면, zoom 과정을 통해 acceptable한 step length를 찾을때까지 값을 줄여나간다.
Algorithm 3.5는 아래의 3 조건 중 하나를 만족하면 interval (αi−1,αi)에 strong Wolfe condition을 만족하는 step length가 포함되어 있다는 사실을 이용한다.
αi가 sufficient decrease 조건을 위배한다.
ϕ(αi)≥ϕ(αi−1)
ϕ′(αi)≥0
다음 trial value ϕ(αi+1)을 찾기 위해서는 interval (αi,αmax) 사이의 값 하나를 찾는다(여러 방법을 생각해볼 수 있다.).