개요
Line search는 search direction을 먼저 정하고, 그에 맞는 step length를 구한다. Trust-region은 모델이 objective function을 잘 나타내는 영역을 정의한다음, 그 영역에서의 minimzer를 선택한다. direction과 step length를 동시에 정한다 볼 수 있다.
본 챕터에서는 모델 mk가 quadratic 하다고 가정한다.
mk(p)=fk+gkTp+21pTBkp
Bk는 이 때 symmetric matrix이고 gk=∇f(xk), fk=f(xk)이다. 이는 f의 Taylor series expansion에 기반한 것이다.
f(xk+p)=fk+gkTp+21pT∇2f(xk+tp)p
이니 mk−f(xk+p)=O(∥p∥2)인 것을 볼 수있다. 각 iteration에서 다음 step은 아래의 subproblem 통해 얻을 수 있다.
p∈Rnlimmk(p)s.t.∥p∥≤Δk
이 때, Δk>0이 trust-region의 radius이다. Constraint이 pTp≤Δk2로 나타내어질 수도 있으니 objective와 constraint이 모두 quadratic하다. Bk가 positive definite이고 ∥Bk−1gk∥≤Δk면 이 subproblem은 쉽게 pkB=−Bk−1gk (full step이라고 부름)로 풀린다. 그 외의 경우는 다른 방법을 사용해야한다.
Trust-region radius를 정하기 위해 actual reduction(아래 식의 분자)과 predicted reduction(아래 식의 분모) 사이의 ratio ρk를 사용한다.
ρk=mk(0)−mk(pk)f(xk)−f(xk+pk)
pk는 p=0을 포함한 region에서 mk가 minimize되도록 구했을테니, predicted reduction은 non-negative일 것이다.
- 만약 ρk가 negative라면 f(xk+pk)>f(xk)이니 step을 reject한다. 더 작은 Δk를 시도해본다.
- 만약 ρk가 1에 가까우면 mk가 f를 잘 모델링 하는 것이니 trust region의 크기를 키워본다.
- 만약 ρk가 positive지만 값이 1보다 많이 작으면, 그 값을 그대로 사용한다.

이 때, pk를 얻기 위해서는 subproblem을 풀어야하는데 다음의 theorem을 이용한다.
Theorem 4.1
Vector p∗가 trust-region problem
p∈Rnlimm(p)=f+gTp+21pTBps.t.∥p∥≤Δ
의 global solution이다는 다음과 동치이다. p∗가 feasible하고 다음의 세 조건을 만족하는 scalar λ≥0이 존재한다.
- (B+λI)p∗=−g
- λ(Δ−∥p∗∥)=0
- B+λI가 positive semidefinite
Theorem 4.1의 두번째 조건으로 인해 ∥p∗∥<Δ인 경우(strictly inside) λ=0이어야 하고 따라서 Bp∗=−g, B는 positive semidefinite이 된다. ∥p∗∥=Δ인 경우 λ는 positive value를 가질 수 있다. 따라서 첫번째 조건으로 인해
λp∗=−Bp∗−g=−∇m(p∗)
이다. 따라서, λ>0일 때는 p∗가 m의 negative gradient에 colinear하다(m의 contour에 normal).
Algorithms based on the Cauchy point
Line search에서 꽤 loose한 조건만 만족하는 step length면 globally converge하는 것을 보장할 수 있었듯, trust region에서도 subproblem의 최적해 대신 sufficient reduction하는 approximation pk만으로도 globally converge한다. Sufficient reduction을 정량화하기 위해 Cauchy point pkc라는 개념을 도입한다. pkc는 다음과 같은 과정을 통해 구할 수 있다.
pks=p∈Rnargminfk+gkTps.t.∥p∥≤Δk
τk=τ≥0argminmk(τpks)s.t.∥τpks∥≤Δk
위 두 문제를 풀고 나면 pkc=τkpks이다. 개념적으로는, 먼저 linear model 버전의 (Talyor expansion의 order 얘기, mk는 quadratic이다.) 문제를 풀고 step length τk를 정한다. 이 두 문제의 solution은 closed-form으로 나타낼 수 있다. 먼저
pks=−∥gk∥Δkgk
τk의 경우는 case를 나누어 생각해야하는데, gkTBkgk≤0인 경우에는 mk(τpks)가 monotonically decrease 하기 때문에 τk는 trust-region bound를 만족하는 가장 큰 값 (τk=1)을 선택하면 된다. gkTBkgk>0인 경우, mk(τpks)가 convex quadratic이니 ∥gk∥3/(ΔkgkTBkgk) 또는 boundary value인 1이 된다. 즉,
τk={1ifgkTBkgk≤0min(∥gk∥3/(ΔkgkTBkgk),1)otherwise
이 Cauchy step pkc는 계산복잡도가 낮고, subproblem의 approximate solution이 적합한지 결정하는데 중요한 역할을 한다. Trust-region method는 step pk에서의 decrease가 Cauchy step에서의 decrease의 특정 상수배보다 크면 globally converge 한다.
그런데 그냥 Cauchy step으로 매 iteration 업데이트하는 것은 steepest descent (pks를 계산하는 데 linear model 버전의 문제를 품)와 같고 rate of convergence가 느릴 수 있다. Bk를 step length 뿐 아니라 direction을 계산하는데도 사용해야 (또, Bk가 curvature를 잘 approximate해야) 빠르게 converge 할 수 있다. 따라서 주로, Bk가 positive definite 할 때마다 pkB=−Bk−1gk (이 때, ∥pkB∥≤Δk)을 선택한다.
주의: 이후로 k 인덱스를 생략하고, 최적해가 trust region radius Δ에 따라 결정된다는 것을 강조하기 위해 p∗(Δ)로 표기한다.
Dogleg method
B가 positive definite하면 pB=−B−1g 이다. Δ≥∥pB∥면 p∗(Δ)=pB이고, Δ가 작을 때는 model function의 quadratic term을 없애고 p∗(Δ)≈−Δ∥g∥g로 쓸 수 있다. Δ가 너무 작지도 않은 값일 때는 일반적으로 아래 그림의 곡선처럼 궤도를 따른다.
Wikipedia 설명: 각 iteration에서 만약 Gauss-Newton 알고리즘의 step이 trust region 안에 있으면 이를 선택한다. 아닐 경우, Cauchy point를 구한다. Cauchy point가 trust region의 바깥에 있으면 boundary에서 truncate해서 사용한다. Cauchy point가 trust region의 안에 있으면, Cauchy point와 Gauss-Newton을 잇는 선분과 trust-region의 교차점을 선택한다. 이게 책의 설명보다 조금 더 직관적인 것 같다.
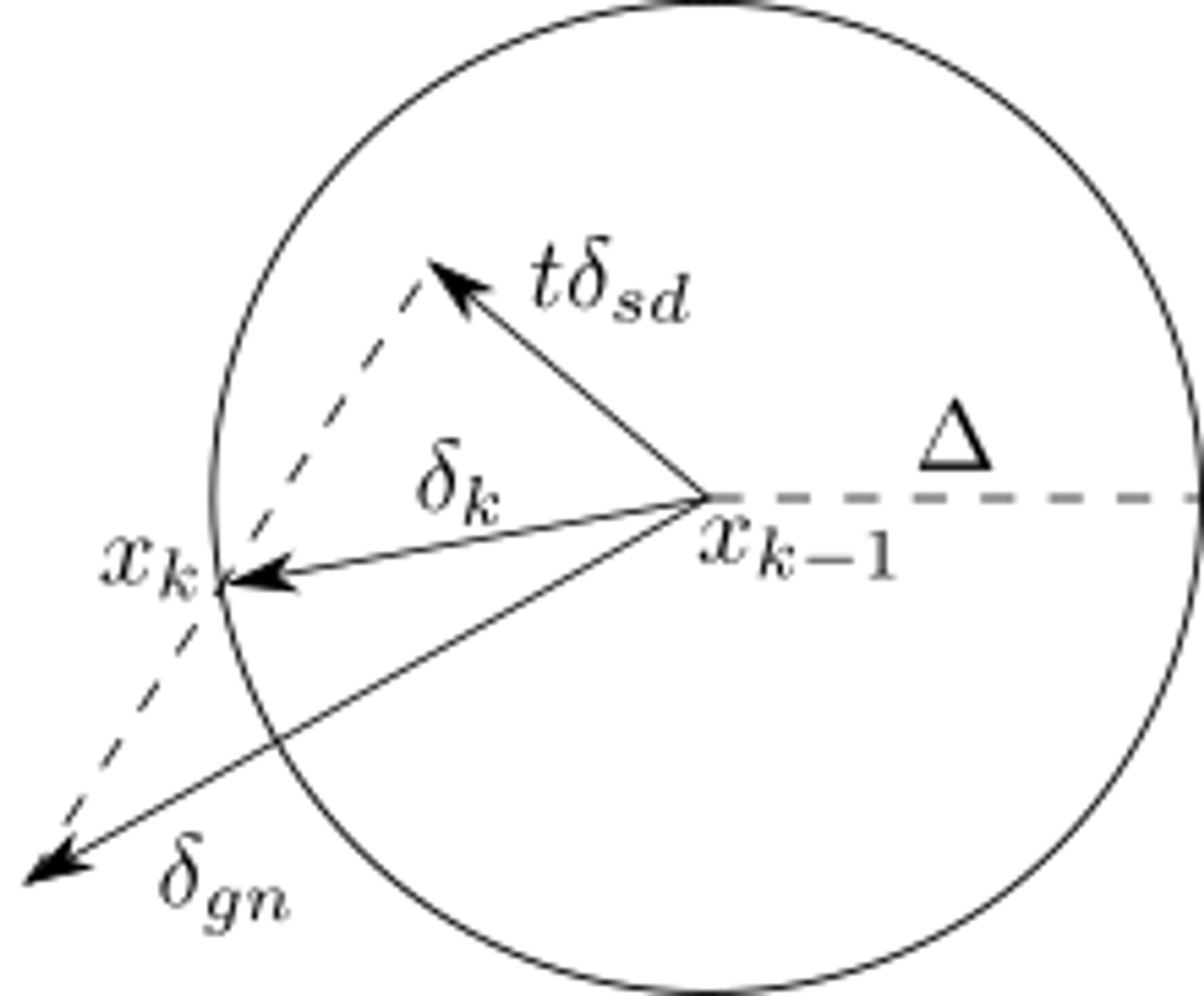
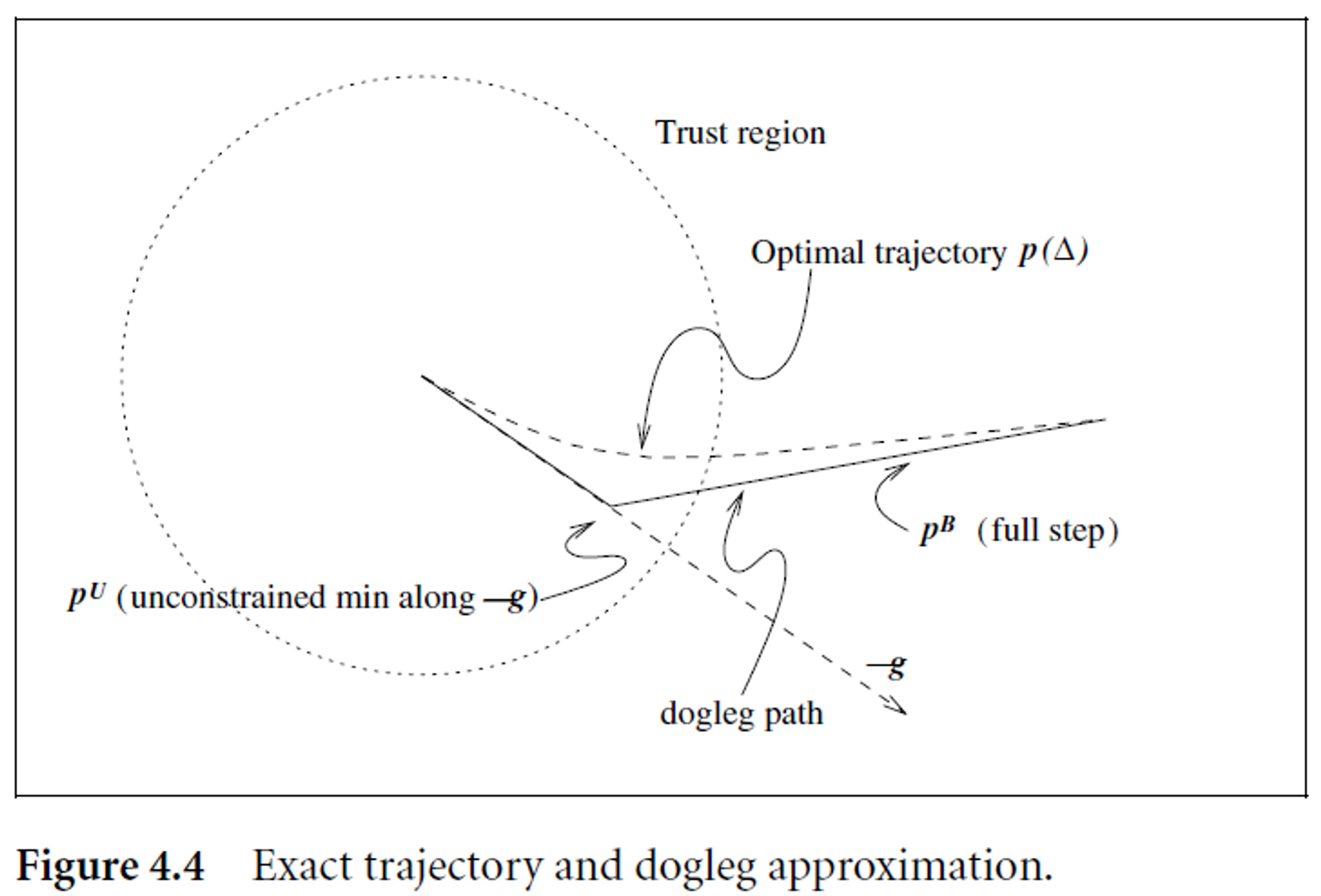
Dogleg method는 곡선 궤도를 두 line으로 approximation 한다. 첫번째 line은 origin에서 steepest descent 방향의 m의 minimzer이다.
pU=−gTBggTgg
두번째 라인은 pU에서 pB방향이다. 그러면 trajectory p~(τ) (τ∈[0,2])는
p~(τ)={τpU0≤τ≤1pU+(τ−1)(pB−pU)1≤τ≤2
Lemma 4.2
B가 positive definite이면
- ∥p~(τ)∥는 τ에 대한 increasing function이다.
- m(p~(τ))는 τ에 대한 decreasing function이다.
-
증명
τ∈[0,1]에 대해서는 자명하다. τ∈[1,2]을 가정하자. h(α)를 다음과 같이 정의한다.
h(α)=21∥p~(1+α)∥2=21∥pU+α(pB−pU)∥2=21∥pU∥+α(pU)T(pB−pU)+21α2∥pB−pU∥2
이를 미분하면,
h′(α)=−(pU)T(pU−pB)+α∥pU−pB∥2≥−(pU)T(pU−pB)=gTBggTggT(−gTBggTgg+B−1g)=gTggTBggTB−1g[1−(gTBg)(gTB−1g)(gTg)2g]≥0
따라서 ∥p~(τ)∥는 τ에 대한 increasing function이다. 또 h^(α)=m(p~(1+α))로 정의하고, 이를 미분하면
h^′(α)=(pB−pU)T(g+BpU)+α(pB−pU)TB(pB−pU)≤(pB−pU)T(g+BpU+B(pB−pU))=(pB−pU)T(g+BpB)=0
따라서 ∥pB∥≥Δ이면, p~(Δ)는 trust region boundary와 딱 한군데서만 intersect한다. m이 decreasing function이므로, ∥pB∥≤Δ일 때는 p는 pB이고, 그 외에는 dogleg과 trust region boundary의 intersection이다. 이 때, τ는 ∥pU+(τ−1)(pB−pU)∥2=Δ2를 풀어서 구한다.
Dogleg method는 B가 positive definite 할 때 적용하기 좋고, Hessian modification이 필요한 경우라면 다른 method를 사용하는 것이 낫다.
Two-dimensional subspace minimization
B가 positive definite일 때, dogleg method 처럼 p를 line에서 찾지 않고, pU와 pB이 span하는 공간에서 찾도록 개선할 수 있다.
pminm(p)=f+gTp+21pTBps.t.∥p∥≤Δ,p∈span[g,B−1g]
이를 B가 indefinite할 경우에 사용하기 위해 수정할 수 있다. 즉, B가 negative eigenvalues를 가지면 subspace를 span[g,(B+αI)−1g] (이 때, α∈(−λ1,−2λ1], λ1은 가장 작은 eigenvalue)로 바꾼다.
Global convergence
Reduction obtained by the Cauchy point
먼저 Cauchy point를 통해 얻어지는 global convergence에 대해 분석하고, 이를 위에서 다룬 method에 적용한다. Dogleg이나 two-dimensional subspace minimization 알고리즘은 다음을 만족하는 근사해 pk를 구한다. c1∈(0,1]에 대해,
mk(0)−mk(pk)≥c1∥gk∥min(Δk,∥Bk∥∥gk∥)(4.20)
먼저 Cauchy point pkC가 (4.20) 조건을 c1=1/2로 만족함을 보이자.
Lemma 4.3
Cauchy point pkC에 대해
mk(0)−mk(pkC)≥21∥gk∥min(Δk,∥Bk∥∥gk∥)
- 증명
-
gkTBkgk≤0인 경우,
mk(pkC)−mk(0)=mk(−Δgk/∥gk∥)−f=−∥gk∥Δk∥gk∥2+21∥gk∥2Δk2gkTBkgk≤−Δk∥gk∥≤−∥gk∥min(Δk,∥Bk∥∥gk∥)
-
gkTBkgk>0인 경우,
a. ∥gk∥3/(ΔkgkTBkgk)≤1인 경우,
τk=∥gk∥3/(ΔkgkTBkgk) (Cauchy point 계산하는 부분 참조) 이므로
mk(pkC)−mk(0)=−gkTBkgk∥gk∥4+21gkTBkgk(gkTBkgk)2∥gk∥4=−21gkTBkgk∥gk∥4≤−21∥Bk∥∥gk∥2∥gk∥4=−21∥Bk∥∥gk∥2≤−21∥gk∥min(Δk,∥Bk∥∥gk∥)
b. ∥gk∥3/(ΔgkTBkgk)>1 인 경우,
위 식을 다시 쓰면 gkTBkgk<∥gk∥3/Δk 이다. 이 때 τk=1이고,
mk(pkC)−mk(0)=−∥gk∥Δk∥gk∥2+21∥gk∥2Δk2gkTBkgk≤−Δk∥gk∥+21∥gk∥2Δk2Δk∥gk∥3=−21Δk∥gk∥≤−21∥gk∥min(Δk,∥Bk∥∥gk∥)
이제 pk가 최소한 Cauchy point로 얻어지는 reduction의 c2배 만큼의 reduction을 달성하면 (4.20) 조건을 만족함을 보이자.
Lemma 4.4
pk를 ∥pk∥≤Δk, mk(0)−mk(pk)≥c2(mk(0)−mk(pkC)) 을 만족하는 임의의 vector라고 하자. 그러면, pk는 c1=c2/2로 (4.20) 조건을 만족한다. 특히 pk가 exact solution pk∗면 (4.20) 조건을 c1=1/2로 만족한다.
- 증명
mk(0)−mk(pk)≥c2(mk(0)−mk(pkC))≥21c2∥gk∥min(Δk,∥Bk∥∥gk∥)
Dogleg, two-dimensional subspace minimization 모두 exact solution을 approximate하며 mk(pk)≤mk(pkC)이므로 (4.20) 조건을 c1=1/2로 만족한다.
Convergence to stationary points
Bk의 norm이 uniformly bounded 되어있고, f를 level set
S={x∣f(x)≤f(x0)}
로 정의한다. 또, 이 set의 open neigborhood를 다음과 같이 정의한다. R0>0에 대해
S(R0)={x∣∥x−y∥<R0 for some y∈S}
결론이 더 일반적으로 적용되도록 approximate solution pk의 길이가 trust-region bound를 넘을 수 있도록 허용하자. 구체적으로, γ≥1에 대해
∥pk∥≤γΔk(4.25)
먼저 η=0 (알고리즘 4.1 참조, 이 경우 f값이 낮아지기만 한다면(ρ≥0이면) 항상 그 step 을 취한다.)에 대해 논의하자.
Theorem 4.5
알고리즘 4.1에서 η=0을 가정하자. ∥Bk∥≤β, f는 level set에 의해 아래로 bound 되어있고, neighborhood S(R0)에서 Lipschitz continuously differentiable하다. 그리고 모든 approximate solution이 (4.20)과 (4.25) 조건을 만족한다고 가정하자. 그러면
k→∞liminf∥gk∥=0
-
증명
ρk에 약간의 조작을 가하면
∣ρk−1∣=∣∣∣∣∣mk(0)−mk(pk)(f(xk)−f(xk+pk))−(mk(0)−mk(pk))∣∣∣∣∣=∣∣∣∣∣mk(0)−mk(pk)mk(pk)−f(xk+pk)∣∣∣∣∣
f(xk+pk)에 Taylor’s theorem을 적용하면
∣mk(pk)−f(xk+pk)∣=∣∣∣∣∣21pkTBkpk−∫01[g(xk+tpk)−g(xk)]Tpkdt∣∣∣∣∣≤(β/2)∥pk∥2+β1∥pk∥2
여기서 β1은 g의 S(R0)에서의 Lipshcitz constant이다. 또한 xk와 xk+tpk 둘 다 S(R0)에 있도록 ∥pk∥≤R0을 가정했다. 여기서 liminfk→∞∥gk∥=0이라고 가정하자. 즉 ϵ>0과 K>0에 대해서
∥gk∥≥ϵfor allk≥K(4.28)
이 때, (4.20)을 생각해보면, k≥K에 대해,
mk(0)−mk(pk)≥c1∥gk∥min(Δ,∥Bk∥∥gk∥)≥c1ϵmin(Δk,βϵ)
처음 ∣ρk−1∣의 식에 분모, 분자에 관한 논의를 각각 했으니 이를 조합하면
∣ρk−1∣≤c1ϵmin(Δk,ϵ/β)γ2Δk2(β/2+β1)
이 때, 충분히 작은 Δk에 대해서 위 식의 오른쪽 term이 bound 됨을 보이자. 구체적으로, Δk≤Δˉ을 만족하는 Δk에 대해 얘기하자.
Δˉ=min(21γ2(β/2+β1)c1ϵ,γR0)
이 때, R0/γ가 들어간 이유는 ∥pk∥≤γΔk≤γΔˉ≤R0 이 성립하기 위함이다. c1≤1이고 γ≥1, β1≥0이므로 Δˉ≤ϵ/β이다. 따라서, min(Δk,ϵ/β)=Δk가 성립한다. 이 사실들을 다시 적용하면
∣ρk−1∣≤c1ϵγ2Δk(β/2+β1)≤c1ϵγ2Δˉ(β/2+β1)≤21
따라서 ρk>41가 된다. 알고리즘 4.1을 참조하면, Δk≤Δˉ일 때마다 trust region radius를 키운다는 말이고, radius에 reduction이 있는 경우는 Δk>Δˉ 일 때 뿐이라는 말이다. 결론을 정리하면,
Δk≥min(ΔK,Δˉ/4)for allk≥K(4.32)
모든 k∈K에 대해서 ρk≥41를 만족하는 infinite subsequence K가 있다고 가정하자. k≥K에 대해서
f(xk)−f(xk+1)=f(xk)−f(xk+pk)≥41[mk(0)−mk(pk)]≥41c1ϵmin(Δk,ϵ/β)
두번째 줄 부등호는 ρk≥41에서, 세번째 줄 부등호는 위에 있는 중간 결과에서 성립한다. f는 아래로 bound 되어있으니
k∈K,k→∞limΔk=0
이는 (4.32)에 모순이다. 따라서 우리가 가정한 infinite subsequence K는 존재할 수 없고, 모든 충분히 큰 k에 대해서 ρk<41이어야 한다. 이 경우, Δk는 매 iteration마다 41가 곱해질 것이고, 이는 다시 limk→∞Δk=0을 의미함으로 (4.32)에 모순이다. 따라서 처음 가정했던 (4.28)이 모순이 되어서 증명이 성립한다.
이제 η>0 (update 조건이 좀 더 strict 한 경우)에 대해 논의하자.
Theorem 4.6
알고리즘 4.1에서 η∈(0,41)을 가정하자. ∥Bk∥≤β, f는 level set에 의해 아래로 bound 되어있고, neighborhood S(R0)에서 Lipschitz continuously differentiable하다. 그리고 모든 approximate solution이 (4.20)과 (4.25) 조건을 만족한다고 가정하자. 그러면
k→∞limgk=0
- 증명
gm=0인 index m을 생각해보자. Lipschitze constant β1에 대해∥g(x)−gm∥≤β1∥x−xm∥ ϵ과 R을 다음을 만족하도록 정의하자.ϵ=21∥gm∥R=min(β1ϵ,R0) R≤R0이므로 ballB(xm,R)={x∣∥x−xm∥≤R} 은 S(R0)에 포함되고, g의 Lipschitz continuity는 B(xm,R)에서 성립한다. x∈B(xm,R)에 대해∥g(x)−gm∥≤β1∥x−xm∥≤β1R≤ϵ=21∥gm∥ 이므로∥g(x)∥≥∥gm∥−∥g(x)−gm∥≥21∥gm∥=ϵ 만약에 entire sequence {xk}k≥m이 ball B(xm,R)안에 있다면, 모든 k≥m에 대해서 ∥gk∥≥ϵ>0일 것이다. 그럼 theorem 4.5의 (4.28) 가정 이후의 논리 전개를 다시 한번 적용할 수 있고, 결론적으로 sequence {xk}k≥m 는 ball B(xm,R)을 벗어난다. Index l≥m을 xl+1이 xm 후 처음으로 B(xm,R)를 벗어난 것이 되도록 설정하자. 그러면 k=m,…,l에 대해서 ∥gk∥≥ϵ 이므로f(xm)−f(xl+1)=k=m∑l[f(xk)−f(xk+1)]≥k=m,xk=xk+1∑lη[mk(0)−mk(pk)]≥k=m,xk=xk+1∑lηc1ϵmin(Δk,βϵ) Sum 기호에 xk=xk+1은 step이 취해진 경우에만 더하겠다는 뜻이다. 만약에 Δk≤ϵ/β이면f(xm)−f(xl+1)≥ηc1ϵk=m,xk=xk+1∑lΔk≥ηc1ϵR=ηc1ϵmin(β1ϵ,R0) 만약에 Δk>ϵ/β이면f(xm)−f(xl+1)≥ηc1ϵβϵ Sequence {f(xk)}k=0∞은 decreasing 하며 아래로 bound 되어있으므로 f(xk)↓f∗ 이 때, f∗>−∞. 따라서,f(xm)−f∗≥f(xm)−f(xl+1)≥ηc1ϵmin(βϵ,β1ϵ,R0)=21ηc1∥gm∥min(2β∥gm∥,2β1∥gm∥,R0)>0 f(xm)−f∗↓0이므로 gm→0이다.
Iterative solution of the subproblem
Problem의 크기가 상대로 작을 때 (n이 너무 크지 않을 때), B의 factorization을 몇번 더 하는 대신 (일반적으로 총 3회, dogleg이나 two-dimensional subspace minimization은 1회 함) subproblem의 더 좋은 approximated solution을 찾을 수 있다. Theorem 4.1에서 언급한 global solution의 성질과 단변수의 Newton’s method를 이용한다. 요약하자면,
p∈Rnminm(p)=f+gTp+21pTBps.t.∥p∥≤Δ
의 solution이
(B+λI)p∗=−g
을 만족하도록 만드는 λ 값을 찾는 것이다. Theorem 4.1을 생각해보면 λ=0이 ∥p∥≤Δ로 1, 3번 조건을 만족하거나, 그렇지않으면 B+λI가 positive definite이 되는 λ에 대해
p(λ)=−(B+λI)−1g
를 정의해서,
∥p(λ)∥=Δ
를 만족하는 λ>0의 값을 찾는다. 이 문제는 λ에 대한 one-dimensional root-finding 문제이다. 원하는 성질을 가지는 λ가 존재하는지를 보기 위해서, B를 EVD해 ∥p(λ)∥의 성질을 공부한다. B는 symmetric이므로 B=QΛQT를 만족하는 orthogonal matrix Q와 diagonal matrix Λ가 존재한다. 이 때, Λ=diag(λ1,…,λn), λ1≤λ2≤⋯≤λn은 B의 eigenvalue 이다. 그렇다면, B+λI=Q(Λ+λI)QT 이고, λ=λj라면
p(λ)=−Q(Λ+λI)−1QTg=−j=1∑nλj+λqjTgqj
이 때, qj는 Q의 j번째 column이다. 그런데 Q는 orthogonal이므로
∥p(λ)∥2=j=1∑n(λj+λ)2(qjTg)2
따라서 ∥p(λ)∥는 구간 (−λ1,∞)에서 continuous, nonincreasing function이며
λ→∞lim∥p(λ)∥=0
이고, qjTg=0이면,
λ→−λjlim∥p(λ)∥=∞
따라서, ∥p(λ∗)∥=Δ를 만족하는 λ∗∈(−λ1,∞)가 존재한다 (∥p(λ)∥=Δ를 만족하는 더 작은 λ값이 있을 수 있지만 λ<−λ1인 경우 B+λI가 positive definite 해야한다는 조건을 만족하지 못할것이다.).
이제 λ∗를 구하는 iterative algorithm에 대해 얘기하자. 먼저, B가 positive definite하고 ∥B−1g∥≤Δ면, λ∗=0으로 즉시 종료할 수 있다. 이 외의 경우, root-finding Newton’s method를 이용하는데, 중간과정 생략하고 결론은 다음과 같다.

q1Tg=0이라면, limλ→λ1∥p(λ)∥=∞이고, 따라서 ∥p(λ)∥=Δ를 만족하는 λ∈(−λ1,∞)이 존재하지 않는다. 그런데 Theorem 4.1에 의해 구간 [−λ1,∞)에는 존재하니 남은 것은 λ=−λ1밖에 없다. 이 때,
p(λ)=j:λj=λ1∑λj+λqjTgqj
처럼 단순히 λj=λ1인 term들을 제거하는 것으로는 충분하지 않다. B−λ1I가 singular이기 때문에 (B−λ1I)z=0이고 ∥z∥=1인 vector z가 존재한다 (λ1에 해당하는 eigenvector). 따라서, 임의의 scalar τ에 대해서,
p(λ)=j:λj=λ1∑λj+λqjTgqj+τz
로 설정하면,
∥p(λ)∥2=j:λj=λ1∑(λj+λ)2(qjTg)2+τ2
이므로, τ값을 잘 골라서 ∥p(λ)∥=Δ가 되도록 할 수 있다.
Theorem 4.1 증명
먼저 Lemma 하나 증명하자.
Lemma 4.7
B가 symmetric matrix일 때, m을 아래와 같은 quadratic function이라 하자.
m(p)=gTp+21pTBp
그러면 다음의 두 진술은 참이다.
- B가 positive semidefinite하고 g가 B의 range에 있을 때, 그리고 오직 그 때만, m은 minimum을 달성한다. B가 positive semidefinite 하다면, Bp=−g를 만족하는 모든 p는 m의 gloabl minimizer이다.
- B가 positive definite할 때, 그리고 오직 그 때만, m은 unique minimizer를 갖는다.
-
증명
‘B가 positive semidefinite하고 g가 B의 range에 있을 때, m은 minimum을 달성한다’를 증명하자. Bp=−g를 만족하는 p가 존재한다. 모든 w∈Rn에 대해
m(p+w)=gT(p+w)+21(p+w)TB(p+w)=(gTp+21pTBp)+gTw+(Bp)Tw+21wTBw=m(p)+21wTBw≥m(p)
따라서 p는 m의 minimizer이다.
역을 증명하자. p가 m의 minimizer라 하자. ∇m(p)=Bp+g=0이므로 g는 B의 range에 있다. ∇2m(p)=B 가 positive semidefinite하다.
‘B가 positive definite할 때, m은 unique minimizer를 갖는다.’를 증명하려면, 첫번째 논증에서 wTBw>0으로 바꾸면 된다. 역을 증명하려면, wTBw=0인 w=0이 존재한다고 가정하자. 그럼 m(p+w)=m(p)이므로 minimizer가 unique하지 않아서 모순이다.
Theorem 4.1의 조건들을 만족하는 λ≥0이 존재한다고 가정하자. Lemma 4.1의 (1)에 의해 p∗는 아래 quadratic function의 global minimum이다.
m^(p)=gTp+21pT(B+λI)p=m(p)+2λpTp
m^(p)≥m^(p∗)이므로
m(p)≥m(p∗)+2λ((p∗)Tp∗−pTp)
λ(Δ−∥p∗∥)=0이고 따라서 λ(Δ2−(p∗)Tp∗)=0이므로,
m(p)≥m(p∗)+2λ(Δ2−pTp)
λ≥0이므로, ∥p∥≤Δ인 모든 p에 대해 m(p)≥m(p∗)이고 따라서 p∗는 global minimizer이다.
역을 증명하기 위해 p∗가 gloabl minimizer라고 가정하고 조건들을 만족하는 λ≥0이 존재함을 보이자. ∥p∗∥<Δ일 때, ∇m(p∗)=Bp∗+g=0이고, ∇2m(p∗)=B는 positive semideifinite이다. 따라서 조건은 λ=0에 대해 만족한다. ∥p∗∥=Δ일 때, p∗는 constrained problem
minm(p)subject to ∥p∥=Δ
을 해결하는데, Lagrangian function으로 나타내면
L(p,λ)=m(p)+2λ(pTp−Δ2)
이다. 이 Lagrangian function이 p∗에서 stationary point를 갖게 만드는 λ를 찾는다. ∇pL(p∗,λ)를 0으로 설정하면
Bp∗+g+λp∗=0⇒(B+λI)p∗=−g
따라서 첫번째 조건이 성립한다. pTp=(p∗)Tp∗=Δ2를 만족하는 p에 대해서 m(p)≥m(p∗)이므로,
m(p)≥m(p∗)+2λ((p∗)Tp∗−pTp)
여기서 g=−(B+λI)p∗를 대입하고 정리하면,
21(p−p∗)T(B+λI)(p−p∗)≥0
이 때,
{w:w=±∥p−p∗∥p−p∗, for some p with ∥p∥=Δ}
가 dense 하기 때문에 세번째 조건이 성립한다. 이제 λ가 non-negative 하다는 것만 보이면 된다. 만약에 negative 하다고 가정한다면, ∥p∥≥∥p∗∥=Δ 이면 m(p)≥m(p∗)이다. ∥p∥≤Δ인 범위 내에서 p∗가 minimizer이기 때문에 두 사실을 합치면, p∗는 m의 global, unconstrained minimizer이다. 이 때, Lemma 4.7의 (1)에 의해, Bp=−g이고 B는 positive semidefinite이다. 따라서 조건이 λ=0으로 만족하고 negative하다는 가정에 모순이다.
Convergence of algorithms based on nearly exact solution
Algorithm 4.3을 이용해서 approximate solution을 구할 때, 일반적으로 2, 3 iteration 후 얻어진 결과를 사용하고 비교적 정확한 approximation을 구하려고 하지 않는다. 다만, Theorem 4.5와 4.6이 적용될 수 있도록 safeguard를 적용할 수 있는데 구체적으로
m(0)−m(p)≥c1(m(0)−m(p∗))(4.52a)
∥p∥≤γΔ(4.52b)
를 만족하도록 한다. Cauchy point의 global convergence 분석에서 나온 (4.20) 식과 달리 위의 sufficient decrease 조건은 m의 second-order part도 사용해서 B가 negative eigenvalue를 가지고 g=0인 경우에도 감소할 수 있게 만든다.
Global convergence를 분석하기 위해서 exact Hessian 을 사용하면 limit point에 대해 더 많은 정보를 알 수 있는데,
Theorem 4.8
Theorem 4.6의 가정을 만족하고 f가 level set S에서 twice continuously differentiable하다고 가정하자. 모든 k에 대해서 Bk=∇2f(xk)이고 approximate solution pk가 (4.52)를 만족한다고 가정하자. 그러면 limk→∞∥gk∥=0이다.
또, 만약 S가 compact하다면, 알고리즘은 local solution에 대한 second-order necessary condition을 만족하는 점 xk에서 종료하거나, {xk}가 그러한 조건을 만족하는 점 x∗로 수렴한다.
Local convergence of trust-region Newton method
Trust-region Newton method의 rate of convergence에 대해 분석하기 위해서 iteration이 진행되어 solution의 근처로 갈수록 model이 원 함수를 더 잘 모델링하고 (trust-region 내에서), 따라서 trust-region Newton method의 step이 true Newton method에 수렴한다는 것을 보인다(asymptotically similar).
Theorem 4.9
f가 second-order sufficient condition을 만족하는 점 x∗의 neighborhood에서 twice Lipschitz continuously differentiable 하고, sequence {xk}가 x∗로 수렴하며, 충분히 큰 모든 k에 대해서 Bk=∇2f(xk)로 설정한 trust-region algorithm이 ∥pkN∥≤21Δk일 때마다 Cauchy-point-based model reduction criterion (4.20)을 만족하고 Newton step pkN에 asymptotically similar한 step pk를 선택(∥pk−pkN∥=o(∥pkN∥))한다고 가정하자.
그러면, 충분히 큰 모든 k에 대해서 trust-region bound Δk는 inactive해지고, sequence {xk}는 x∗로 superlinearly 수렴한다.
-
증명
충분히 큰 모든 k에 대해서 ∥pkN∥≤21Δk이고, ∥pk∥≤Δk이어서 iteration이 진행됨에 따라 near-optimal step이 취해질 것이라는 것을 보이자.
먼저 충분히 큰 모든 k에 대해 predicted reduction mk(0)−mk(pk)의 lower bound를 구한다. o(∥pkN∥)가 ∥pkN∥보다 작아질만큼 k가 크다고 가정하자. ∥pkN∥≤21Δk이면, ∥pk∥≤∥pkN∥+o(∥pkN∥)≤2∥pkN∥ 이고, ∥pkN∥>21Δk이면, ∥pk∥≤Δk<2∥pkN∥이다. 두 경우 모두
∥pk∥≤2∥pkN∥≤2∥∇2f(xk)−1∥∥gk∥
이고 따라서 ∥gk∥≥21∥pk∥/∥∇2f(xk)−1∥이다. (4.20)으로부터
mk(0)−mk(pk)≥c1∥gk∥min(Δk,∥∇2f(xk)∥∥gk∥)≥c12∥∇2f(xk)−1∥∥pk∥min(∥pk∥,2∥∇2f(xk)∥∥∇2f(xk)−1∥∥pk∥)=c14∥∇2f(xk)−1∥2∥∇2f(xk)∥∥pk∥2
이다. xk→x∗이므로, 충분히 큰 모든 k에 대해 다음의 bound가 성립함을 보이기 위해 ∇2f(x)의 continuity와 ∇2f(x∗)의 positive definite함을 이용한다.
4∥∇2f(xk)−1∥2∥∇2f(xk)∥c1≥8∥∇2f(x∗)−1∥2∥∇2f(x∗)∥c1=c3
이 때, c3>0이다. 따라서 충분히 큰 모든 k에 대해서
mk(0)−mk(pk)≥c3∥pk∥2
이다. x∗ 주변에서 ∇2f(x)의 Lipschitz continuity와 Taylor’s theorem을 이용하면
∣(f(xk)−f(xk+pk))−(mk(0)−mk(pk))∣=∣∣∣∣∣21pkT∇2f(xk)pk−21∫01pkT∇2f(xk+tpk)pkdt∣∣∣∣∣≤4L∥pk∥3
이 때, L>0은 Lipschitz constant이다. 그러면, 충분히 큰 k에 대해
∣ρk−1∣≤c3∥pk∥2∥pk∥3(L/4)=4c3L∥pk∥≤4c3LΔk
Trust-region radius는 ρk가 1/4보다 클 때만 줄어들 수 있으니 sequence {Δk}는 0으로부터 bounded away 된다. xk→x∗이므로, ∥pkN∥→0이고 따라서 ∥pk∥→0이다. 따라서 trsut-region bound는 충분히 큰 모든 k에 대해서 inactive하고, bound ∥pkN∥≤21Δk는 iteration이 진행됨에 따라 항상 만족할 것이다.
Superlinear convergence를 증명하기 위해, Newton’s method의 quadratic convergence를 이용한다.
∥xk+pkN−x∗∥=o(∥xk−x∗∥2)
∥pkN∥=O(∥xk−x∗∥)이므로
∥xk+pk−x∗∥≤∥xk+pkN−x∗∥+∥pkN−pk∥=o(∥xk−x∗∥2)+o(∥pkN∥)=o(∥xk−x∗∥)
따라서 superlinear하게 converge한다.
Theorem 3.5에 따라 충분히 큰 모든 k에 대해서 pk=pkN라면 {xk}는 x∗로 quadratic하게 converge한다.
Enhancements
Scaling
Poor scaling의 경우 spherical trust region 보다 elliptical이 나을 수 있다. 이는 diagonal matrix D에 대해서 ∥Dp∥≤Δ 로 표현할 수 있다.
Trust region in other norms
일부 상황 (문제의 크기가 너무 크다던지) 같은 경우는 Euclidean norm 대신 l1 또는 ∞ norm 등을 사용할 수 있다.
