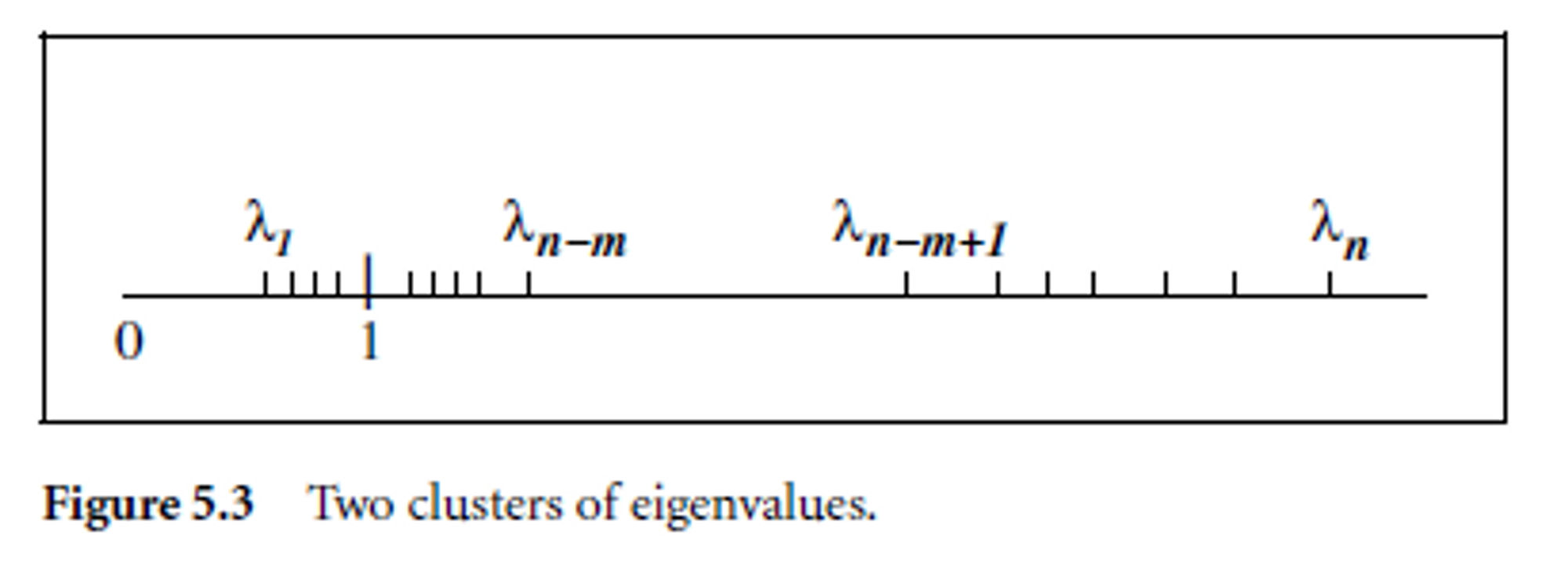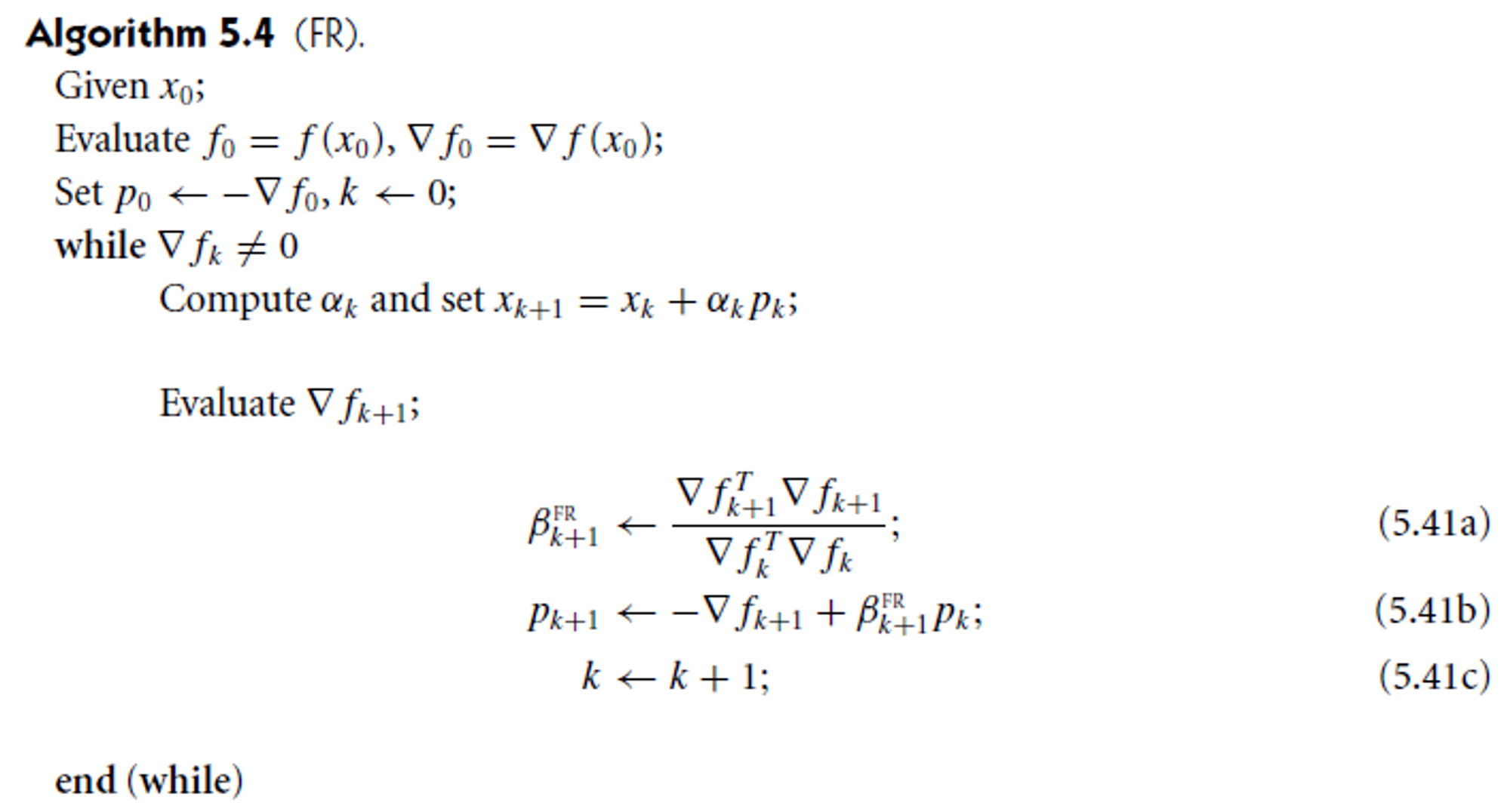Large linear systems을 풀기에 가장 효율적인 방법이다 (이 목적으로 개발된 것이기도 하다). 그리고 이를 nonlinear optimization problem을 풀기위해 활용할 수 있다.
Linear system을 풀기 위해 사용될 때는 (Gaussian elimination을 대신하는 개념, linear conjugate gradient) 성능이 coefficient matrix의 eigenvalue의 분포에 따라 달라지는데, transform하거나, precondition 하는 방법으로 convergence를 향상시킬 수 있다.
Nonlinear conjugate gradient method로 large scale nonlinear optimization problem을 풀 수 있고, 이 때 장점은 steepest descent 보다 빠르고, matrix storage를 필요로 하지 않는다는 점이다.
The linear conjugate gradient method
Ax=b
Linear system of equation을 interative하게 푼다. 이 때, A는 n×n symmetric positive definite matrix이다. 이는 optimization 문제로 바꿔서 표현할 수 있다.
minϕ(x)=21xTAx−bTx
처음의 linear equation의 해와 위의 optimization 문제의 해는 같다. ϕ의 gradient은 linear system의 residual과 같다.
∇ϕ(x)=Ax−b=r(x)
Nonzero vectors {p0,p1,…,pl}이 symmetric positive definite matrix A에 대해서 conjugate하다는 것은 다음을 만족하는 것이다.
piTApj=0for all i=j
이 vector들은 linearly independent하다는 것을 볼 수 있다. Conjugate gradient method의 장점은 conjugacy를 가지는 vector들의 set을 경제적으로 만들 수 있다는 것이다. Conjugacy를 가지고 있으면 ϕ(⋅)을 n step 동안 각 direction에 따라 minimize 할 수 있다. 이를 보이기 위해 다음의 conjugate direction method를 살펴보자. 시작점 x0∈Rn과 conjugate direction {p0,p1,…,pl−1}에 대해 sequence {xk}를 다음과 같이 얻을 수 있다.
xk+1=xk+αkpk
이 때, αk는 ϕ(⋅)의 xk+αpk 를 따라 얻은 one-dimensional minimizer이고
αk=−pkTApkrkTpk
이다.
Theorem 5.1
아무 시작점 x0∈Rn에 대해, conjugate direction method를 통해 얻어진 sequence {xk}는 linear system의 solution x∗에 최대 n step 안에 converge한다.
증명
{pi}는 서로 linearly independent 하기 때문에 Rn을 span한다. 따라서
x∗−x0=i=0∑n−1σipi
로 표현할 수 있다. 양변의 앞에 pkTA를 곱하고 정리하면
σk=pkTApkpkTA(x∗−x0)
을 얻을 수 있다. xk가 conjugate direction method를 통해 얻어지기 때문에
xk=x0+i=0∑k−1αipi
이고, 양변의 앞에 pkTA를 곱하고 정리하면
pkTA(xk−x0)=0
이고,
pkTA(x∗−x0)=pkTA(x∗−xk)=pkT(b−Axk)=−pkTrk
따라서 αk=σk이다.
Conjugate direction method의 k iteration 후 얻어진 xk는 span{p0,p1,…,pk−1}에서 ϕ(⋅)이 minimize되는 점이다.
Theorem 5.2
아무 시작점 x0∈Rn에 대해, sequence {xk}가 conjugate direction method를 통해 얻어진다고 가정하자. 그러면,
rkTpi=0for i=0,1,…,k−1
이고, xk는 ϕ(x)=21xTAx−bTx의 set
{x∣x=x0+span{p0,p1,…,pk−1}}
에서의 minimizer이다.
증명
먼저 점 x~가 set {x∣x=x0+span{p0,p1,…,pk−1}}에서 ϕ를 minimize한다와 i=0,1,…,k−1에 대해 r(x~)Tpi=0 이다가 동치임을 보이자. h(σ)=ϕ(x0+σ0p0+⋯+σk−1pk−1) (이 때, σ=(σ0,…,σk−1)T을 정의하자. h(σ)는 strictly convex quadratic이기 때문에,
∂σi∂h(σ∗)=0i=0,1,…,k−1
을 만족하는 unique minimizer σ∗가 존재한다. Chain rule에 따라
∇ϕ(x0+σ0∗p0+⋯+σk−1∗pk−1)Tpi=0i=0,1,…,k−1
이다. 이 때, ∇ϕ(x)=Ax−b=r(x)로 정의했었으니, minimizer x~=x0+σ0∗p0+⋯+σk−1∗pk−1에 대해서, r(x~)Tpi=0임을 보인 것이다.
이제 xk가 rkTpi=0 (i=0,1,…,k−1)을 만족함을 보이자. k=1인 경우, x1=x0+α0p0이 p0을 따라 ϕ를 minimize한다는 점에서 r1Tp0=0이다. 이제 i=0,1,…,k−2에 대해서 rk−1Tpi=0이라 가정하자.
rk=rk−1+αk−1Apk−1
의 앞에 pk−1T을 곱하면
pk−1Trk=pk−1Trk−1+αk−1pk−1TApk−1=0
αk−1의 정의에 의해 rkTpk−1=0을 얻는다. i=0,1,…,k−2인 pi에 대해서는
piTrk=piTrk−1+αk−1piTApk−1=0
가정에 의해 piTrk−1=0 이고, pi의 conjugacy에 의해 piTApk−1=0이다. 따라서 i=0,1,…,k−1에 대해 rkTpi=0이다.
{pi}는 conjugacy를 가지기만 하면 어떤 것이든 상관이 없다. 가장 쉽게 생각해볼 수 있는 건 Eigenvector일텐데 계산 복잡도가 커서 현실적이지 못하다. Gram-Schmidt orthogonalization을 이용하는 것도 마찬가지이다.
Conjugate gradient method는 conjugate direction method의 한 종류이다. Conjugate vector pk를 만드는 과정에서 pk−1만을 이용하여 만드는데, pk는 p0,…,pk−2와 conjugate하다. 이 때문에, conjugate gradient method는 memory 사용과 computational cost 측면에서 우수하다. 각 direction pk는
pk=−rk+βkpk−1
을 통해서 구해지는데, 이 때, βk는 pk−1와 pk가 A에 대해서 conjugate 하도록 정한다.
βk=pk−1TApk−1rkTApk−1
p0은 x0에서의 steepest direction으로 잡는다. Conjugate direction method 처럼 각 direction에 대해 one-dimensional minimization을 하게 된다.
이제, p0,p1,…,pn−1이 서로 conjugate하고, residual ri들이 서로 orthogonal하고, search direction pk와 residual rk가 다음과 같이 정의되는 r0의 Krylov subspace of degree k에 포함됨을 보이자.
K(r0;k)=span{r0,Ar0,…,Akr0}
Theorem 5.3
Conjugate gradient method에 의해 k번째 생성된 점이 solution x∗가 아니라 가정하자. 다음의 네 성질이 성립한다.
따라서 (5.21)의 우변의 두 term이 모두 0가 되어 k+1에 대해 성립함을 보였다.
마지막으로 1번 성질은 비 귀납적인 방법으로 증명한다. Direction set이 conjugate하므로 모든 i=0,1,…,k−1과 아무 k=1,2,…,n−1에 대해서 rkTpi=0이다.
pi=−ri+βipi−1
이므로, 모든 i=0,1,…,k−1에 대해서 ri∈span{pi,pi−1}이다. 따라서 모든 i=1,…,k−1에 대해서 rkTri=0이다. p0의 정의에 의해 rkTr0=−rkTp0=0이다. 따라서 증명이 성립한다.
Theorem 5.2와 5.3의 결과를 이용하여 더 경제적인 conjugate gradient method를 도출할 수 있다. 먼저 Theorem 5.2의 rkTpi=0for i=0,1,…,k−1을 이용해서 αk의 업데이트 식을 다음으로 대체할 수 있다.
αk=pkTApkrkTrk
두번째로, αkApk=rk+1−rk임을 이용해서 βk+1식을 단순화 할 수 있다.
βk+1=rkTrkrk+1Trk+1
요약하자면, 일반적으로 사용하는 conjugate gradient method는 다음의 알고리즘과 같다.
계산복잡도가 낮고, 메모리 효율적이나 문제의 크기가 작은 경우 round error가 적은 Gaussain elimination이나 SVD 같은 방식을 고려하는게 낫다.
기본적으로 정확히 계산했을 때 (수치해석적 오차를 고려하지 않았을 때) n step 안에 solution을 찾는데, 만약에 A의 eigenvalue가 특정한 성질을 가지고 있다면 이보다 더 빠를 수 있다. 이에 대해 얘기하기 위해 Theorem 5.2를 살짝 다르게 바라보자.
Algorithm 5.2의 xk+1 업데이트 식과 theorem 5.3의 세번째 성질로부터
이 때, γi는 임의의 상수이다. γ0,γ1,…,γk를 coefficient로 가지는 degree k의 polynomial Pk∗(⋅)을 정의하면
Pk∗(A)=γ0I+γ1A+⋯+γkAk
따라서 xk+1의 식을 Pk∗(⋅)을 이용해서 표현할 수 있다.
xk+1=x0+Pk∗(A)r0
이제, 첫 k step이 Krylov subspace K(r0;k)으로 제한된 모든 가능한 method 중 Algorithm 5.2가 weighted norm measure ∥⋅∥A (∥z∥A=zTAz)로 측정된 거리 관점에서 k step 후 최적임을 보이자.
21∥x−x∗∥A2=21(x−x∗)TA(x−x∗)=ϕ(x)−ϕ(x∗)
Theorem 5.2에 의해 xk+1은 set x0+span{p0,p1,…,pk} (x0+span{r0,Ar0,…,Akr0}과 같다.)에서 ϕ를 minimize한다. (따라서 ∥x−x∗∥A2도 minimize한다.). Polynomial Pk∗는 다음의 문제를 가능한 모든 degree k의 polynomial 공간에서 최소화하는 것이다.
Pkmin∥x0+Pk(A)r0−x∗∥A
이 섹션동안 이 optimality property를 반복적으로 이용할것이다.
r0=Ax0−b=Ax0−Ax∗=A(x−x∗)
이므로
xk+1−x∗=x0+Pk∗(A)r0−x∗=[I+Pk∗(A)A](x0−x∗)
이다. 0<λ1≤λ2≤⋯≤λn을 A의 eigenvalue라 하고, v1,v2,…,vn을 각 eigenvalue에 해당하는 eigenvector라고 하자. 그러면
A=i=1∑nλiviviT
Eigenvector가 Rn 전체를 span하므로 임의의 상수 ξi에 대해
x0−x∗=i∑nξivi
이다. A의 eigenvector는 polynomial Pk(A)의 eigenvector이기도 하다. 그러므로,
따라서 CG method의 convergence rate를 다음의 값을 가지고 나타낼 수 있다.
Pkmin1≤i≤nmax[1+λiPk(λi)]2
바꿔말하면, 이 식을 가능한 최소화하는 polynomial Pk를 탐색한다. 몇몇 경우 explicit하게 찾을 수 있다.
Theorem 5.4
만약 A가 r개에 서로 구분되는 eigenvalue를 가지고 있다면, CG는 최대 r iteration안에 solution을 찾는다.
비슷한 추론 방식으로 얻을 수 있는 CG method의 다른 유용한 성질로 다음이 있다.
Theorem 5.5
만약 A가 eigenvalue λ1≤λ2≤⋯≤λn을 가지면,
∥xk+1−x∗∥A2≤(λn−k+λ1λn−k−λ1)2∥x0−x∗∥A2
이다. (증명 생략. (5.33)에서 유도됨.)
Theorem 5.5가 어떻게 CG의 동작들 예측하는지 보자.
그림처럼 Eigenvalue들이 cluster 되어있는 경우(특히 n−m개의 eigen value가 1주변에 모여있음에 주목)를 가정하자. Theorem 5.5에 따르면 m+1 step후 conjuagte gradient 알고리즘에 의해
∥xm+1−x∗∥A≈ϵ∥x0−x∗∥A
따라서, m+1 step만으로도 충분히 좋은 solution을 얻을 수 있다.
CG의 convergence를 A의 Euclidean condition number
κ(A)=∥A∥2∥A−1∥2=λn/λ1
을 이용하여 표현하면
∥xk−x∗∥A≤2(κ(A)+1κ(A)−1)k∥x0−x∗∥A
인데, 일반적으로 over estimation이 심하지만 λ1과 λn 밖에 모를 때는 유용하게 사용할 수 있다.
Preconditioning
Eigenvalue의 분포에 따라 CG의 수렴이 빨라질 수 있음을 알았다. 그렇다면 A를 적절히 transform해서 이런 성질을 유도할 수 없을까? 이를 위해 nonsingular matrix C를 이용해 x를 x^로 바꾼다.
x^=Cx
그러면 처음 우리가 linear system을 optimization으로 바꾸기 위해 사용했던 식 ϕ가
ϕ^(x^)=21x^T(C−TAC−1)x^−(C−Tb)Tx^
로 바뀐다. 그러면 CG의 convergence rate은 A대신 C−TAC−1의 eigenvalue에 따를 것이다. Eigenvalue가 잘 cluster 되거나, condition number가 작도록 C를 고르면 된다. 이런 transform을 explicit하게 하지는 않고 \hat{x}에 대해 CG를 풀고 transform을 되돌릴 수 있다. matrix M=CTC를 이용하여 M=I일 때 standard CG이다. 참고로 orthogonality property는 이렇게 표현된다.
riTM−1rj=0∀i=j
Preconditioned CG에서는 (5.39d)의 계산이 추가됐다.
Practical Preconditioners
통용되는 최고의 preconditioning 방법이 있지는 않다. M의 효과, M의 저장과 계산복잡도, (5.39d)의 계산 복잡도를 고려해야한다.
PDE 풀기 위한 방법은 연구 많이 됐다는데 잘 이해 못해서 생략.
General-purpose preconditioner 중에 제일 대중적인 건 incomplete Cholesky 가 있다. 정확한 Cholesky decomposition A=LLT를 하는 대신 L보다 sparse한 approximation L~을 이용하여 A≈L~L~T을 만드는 방식이다. C=L~T로 잡으면 M=L~L~T이고
C−TAC−1=L~−1AL~−T≈I
가 돼서 C−TAC−1의 eigen value들이 1 주위로 모이게 된다. M을 직접적으로 계산하지 않고 L~을 저장하고 My=r을 두번의 triangular substitution으로 푼다. L~의 sparsity가 A랑 비슷하므로 My=r을 푸는 비용은 Ap를 계산하는 것과 비슷하다.
단, matrix A가 충분히 positive definite하지 않아 L~을 구하기 위해서는 diaognal element의 값을 증가시켜야 할 수도 있고, sparsity condition 때문에 numerically instable 할 수 있다.
Nonlinear conjugate gradient method
CG를 앞서 언급한 ϕ 말고 일반적인 (nonlinear까지) function을 minimize하는 데 사용할 수는 없을까?
Fletcher-Reeves Method
CG 알고리즘에서 1) step length αk를 line search를 통해 찾고, 2) residual r을 f의 gradient로 수정한 버전이다. f가 strongly convex quadratic이고 αk가 exact minimizer면 linear CG가 된다. FR은 f의 값과 gradient 만 계산하면 되고 matrix operation도 필요 없고 vector 몇개만 저장하면 돼서 좋다.
다만 αk를 어떻게 계산하냐에 따라서 pk+1이 descent direction이 아닐 수 있다. (5.41b)에 ∇fk를 곱하면
∇fkTpk=−∥∇fk∥2+βkFR∇fkTpk−1
이다. 만약 line search가 정확했다면 αk−1이 pk−1 방향으로 minimizer라 ∇fkTpk−1=0이고 따라서 ∇fkTpk<0이고 pk는 descent direction이다. Line search가 정확하지 않은 경우에는 pk가 descent direction이라고 확신할 수 없는데, 이를 αk가 strong Wolfe condition을 만족하도록 요구하면 해결된다.
Polak-Ribiere Method와 변형
Fletcher-Reeves에서 βk를 바꾼 변형들이 여럿 있는데 그 중 하나가 Polak-Ribiere이다.
βk+1PR=∥∇fk∥2∇fk+1T(∇fk+1−∇fk)
f가 strongly convex quadratic이고 line search가 exact할 때 FR과 동일하다. Line search가 정확하지 않을 때 PR이 더 robust하고 효율적인 편이라 한다.
PR에서는 strong Wolfe condition이 pk가 descent direction임을 보장해주지 않는다. 이 문제를 해결한 버전이 PR+ 이다.
βk+1+=max{βk+1PR,0}
Hestenes-Stiefel 도 f가 strongly convex quadratic이고 line search가 exact할 때 FR과 동일하다.
βk+1HS=(∇fk+1−∇fk)Tpk∇fk+1T(∇fk+1−∇fk)
HS는 연속된 search direction들이 line segment [xk,xk+1]의 average Hessian에 대해 conjuagte 하도록 만드는 것에서 유도됐다. Average Hessian은
Gˉk=∫01[∇2f(xk+ταkpk)]dτ
Taylor’s theorem에 의하면 ∇fk+1=∇fk+αkGˉkpk 인데 pk+1=−∇fk+1+βk+1pk 꼴로 표현되는 어느 direction이든, pk+1TGˉkpk=0 조건을 달면 βk+1이 HS의 꼴이 되어야 한다.
나중에 보게되겠지만, 모든 k≥2에 대해
∣βk∣≤βkFR
를 만족하는 모든 βk는 global convergence를 보장한다. 이 성질을 이용하기 위해 PR을 수정하면
최근에 (이라지만 각각 1999년A nonlinear conjugate gradient method with a strong global convergence property, 2005년A new conjugate gradient method with guaranteed descent and an efficient line search이다. 아무래도 CG가 1950년대 나와서 상대적 최근인듯) 나온 방식 두개가 있는데 PR과 견줄만하다 한다.
Restart 라는 방식은 n step 마다 βk=0으로 설정해서 steepest descent step을 택하고 nonlinear conjugate gradient를 재시작하는 방식이다. f가 solution의 neighborhood에서 strongly convex quadratic하지만 다른 곳에선 nonquadratic하다고 가정하면, solution에 다가가다가 strongly convex quadratic 한 region에서 nonlinear CG를 재시작할 것이고, 그렇게 되면 linear CG처럼 동작하고 quadratic하게 converge 할 것이다. 다시말해,
∥xk+n−x∥=O(∥xk−x∗∥2)
그런데 CG는 일반적으로 n이 클 때 사용하는데 그런 경우 restart는 현실적으로 불가능하다. 그래서 일반적으로 restarts를 안하거나 consecutive gradient가 orthogonal에서 많이 벗어났는지 확인하고 결정한다. 일반적으로 v=0.1로 설정하고
∥∇fk∥2∣∇fkT∇fk−1∣≥v
Fletcher-Reeves Method 분석
아까 증명없이 언급했던 global convergence에 대해 얘기해보자.
Lemma 5.6
Strong Wolfe condition이 0<c2<21로 만족하도록 하는 step length αk로 Fletcher-Reeves 알고리즘이 구현됐다고 가정하자. FR은 다음의 부등식을 만족하는 descent direction pk를 만든다.
−1−c21≤∥∇fk∥2∇fkTpk≤1−c22c2−1,∀k=0,1,…
증명
t(ξ)=(2ξ−1)/(1−ξ)가 [0,21]에서 단조증가하고 t(0)=−1, t(21)=0이라고 하자. c2∈(0,21)니까
−1<1−c22c2−1<0
이다. 따라서 descent condition ∇fkTpk<0이 성립한다.
귀납적으로 증명하자. k=0에 대해서 steepest descent일 테니 ∇fkTpk=−1이고 부등식이 만족한다. 이제 k에 대해서 부등식이 만족한다 가정하면 k+1에 대해서
증명 과정에서 strong Wolfe condition의 한가지 성질만 사용했는데 다른 성질을 이용하면 global convergence도 증명할 수 있다. 우선 여기선 ∇fkTpk의 bound가 step의 norm ∥pk∥가 커지는 속도에 제약을 건다는 점을 주목하자.
Lemma 5.6은 FR의 단점도 설명하는데, 한번 direction과 step length가 좋지 못했으면, 다음 step에서도 그럴 가능성이 크다.
cosθk=∥∇fk∥∥pk∥−∇fkTpk
pk가 좋지 못하다는 것은 descent direction으로부터 멀어져 cosθk≈0이라는 것이다. Lemma 5.6의 부등식에 ∥∇fk∥/∥pk∥를 곱하면
와 동치이다. pk가 gradient와 orthogonal에 가깝다면 step도 작을것이고 xk+1≈xk라 한다면 ∇fk+1≈∇fk일테니
βk+1FR≈1
이 될 것이고, 그렇다면 ∥∇fk+1∥≈∥∇fk∥≪∥pk∥라서
pk+1≈pk
가 된다. 새로운 search direction도 비슷할 것이다. PR의 경우는 같은 상황에서 βk+1PR≈0이 되서 사실상 restart를 하게된다. 앞서 언급한 다른 modification들의 경우도 마찬가지라 이런 문제가 생기지 않는다.
Global Convergence
우선 논의를 위해 objective function이 다음의 성질들을 가진다고 가정하자.
Level set L={x∣f(x)≤f(x0)}이 bounded 되어 있다.
L의 어떤 open neighborhood N에 대해 objective function f가 Lipschitz continuously differentiable하다.
가정에 의하면
∥∇f(x)∥≤γˉ,∀x∈L
을 만족하는 상수 γˉ가 존재한다.
Zoutendijk’s theorem에 따라 Wolfe condition을 만족하면
k=0∑∞cos2θk∥∇fk∥2<∞
이다. 이 것을 이용하면 주기적으로 restart하는 알고리즘들의 global convergence를 증명할 수 있다. ki를 i번째 재시작할 때의 index라고 하고, 재시작 할때는 steepest direction임을 (따라서 cosθk=1) 이용하면 limj→∞∥∇fkj∥=0이므로
k→∞liminf∥∇fk∥=0
이다.
이제 restart하지 않은 경우를 분석해보자.
Theorem 5.7
앞의 두 가정이 성립하고 FR이 0<c1<c2<21로 strong Wolfe condition을 만족한다 하면,
k→∞liminf∥∇fk∥=0
증명
귀류적으로 증명하자. 먼저 충분히 큰 모든 k에 대해서
∥∇fk∥≥γ
를 만족하는 γ>0이 존재한다고 가정하자. Lemma 5.6의 부등식을 Zoutendijk’s condition에 대입하면
k=0∑∞∥pk∥2∥∇fk∥4<∞
Wolfe condition과 Lemma 5.6의 부등식에 의해
∣∇fkTpk−1∣≤−c2∇fk−1Tpk−1≤1−c2c2∥∇fk−1∥2
FR 알고리즘의 계산에 의해 (일부 과정 생략)
∥pk∥2≤(1−c21+c2)∥∇fk∥2+(βkFR)2∥pk−1∥2
이 부등식을 반복해서 적용하고 c3=(1+c2)/(1−c2)≥1로 정의하면
∥pk∥2≤c3∥∇fk∥4j=0∑k∥∇fj∥−2
이다. Assumtion에 의한 bound와 귀류법을 위해 만든 가정에 의해
∥pk∥2≤γ2c3γˉ4k
이기 때문에, positive 상수 γ4에 대해
k=1∑∞∥pk∥21≥γ4k=1∑∞k1
이다. 그런데
k=1∑∞∥pk∥21<∞
이므로
k=1∑∞k1<∞
여야 한다. 이는 사실이 아니므로 모순이다.
일반적인 (nonconvex까지) 함수의 경우에는 Theorem 5.7같은 증명이 불가능하다. PR이 FR보다 잘 동작한다는 점을 생각해봤을 때 이는 다소 충격적이다. 다음 theorem은 ideal line search인 경우에도 PR이 solution point에 다가가지 못하고 영원히 cycle 돌수도 있음을 보여준다.
Theorem 5.8
Ideal line search를 사용하는 PR을 생각해보자. Gradient의 sequence {∥∇fk∥}이 0으로부터 bounded away 되도록 만드는 twice continuously differentiable한 function f:R3→R과 시작점 x0∈R3이 존재한다.
PR+를 이용하면 Theorem 5.8의 문제를 피할 수 있고 global convergence가 증명 가능하다고 한다.