Importance of Memory Access Efficiency
for(int blurRow = -BLUR_SIZE; blurRow < BLUR_SIZE+1; ++blurRow) {
for(int blurCol = -BLUR_SIZE; blurCol < BLUR_SIZE+1; ++blurCol) {
int curRow = Row + blurRow;
int curCol = Col + blurCol;
// Verify we have a valid image pixel
if(curRow > -1 && curRow < h && curCol > -1 && curCol < w) {
pixVal += in[curRow * w + curCol];
pixels++; // Keep track of number of pixels in the avg
} }
}Above code takes 4 bytes per each FLOP.
Global memory bandwidth is around 1000Gb/s, but with 4 bytes in each FLOP (floating point operation),
이말은 즉, one can load only 1000/4 = 250giga FLOP per second.
compute-to-global-memory-access ratio : number of of floating-point calculations performed for each access to the global memory.
memory bound program : program whose execution speed is limited by memory access.
결국 메모리 엑세스를 낮춰야 GLOP을 늘릴수 있는데 어케해야되나..?!
Matrix Multiplication
Inefficient compute-to-global-memory-access ratio의 또다른 예.
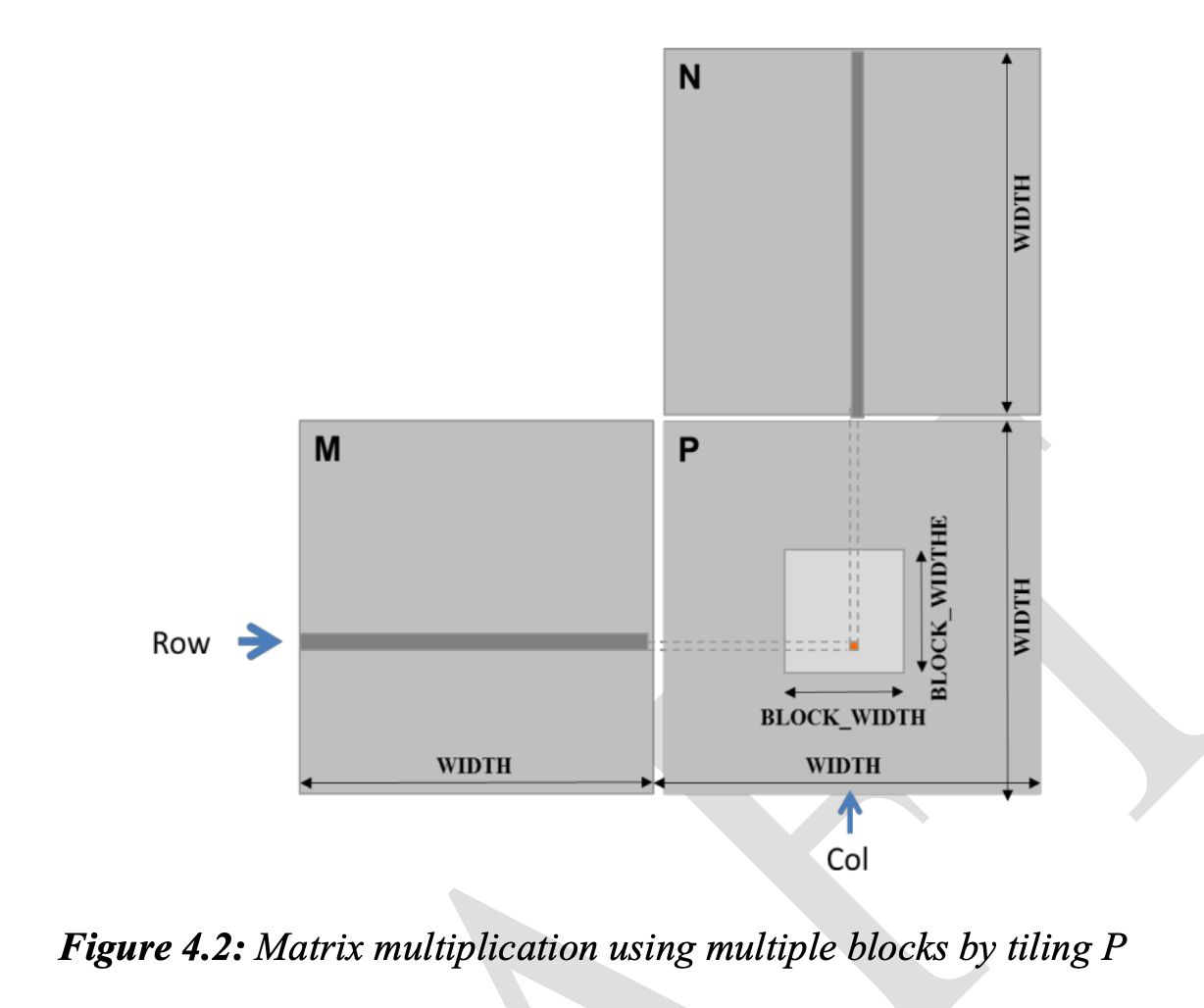
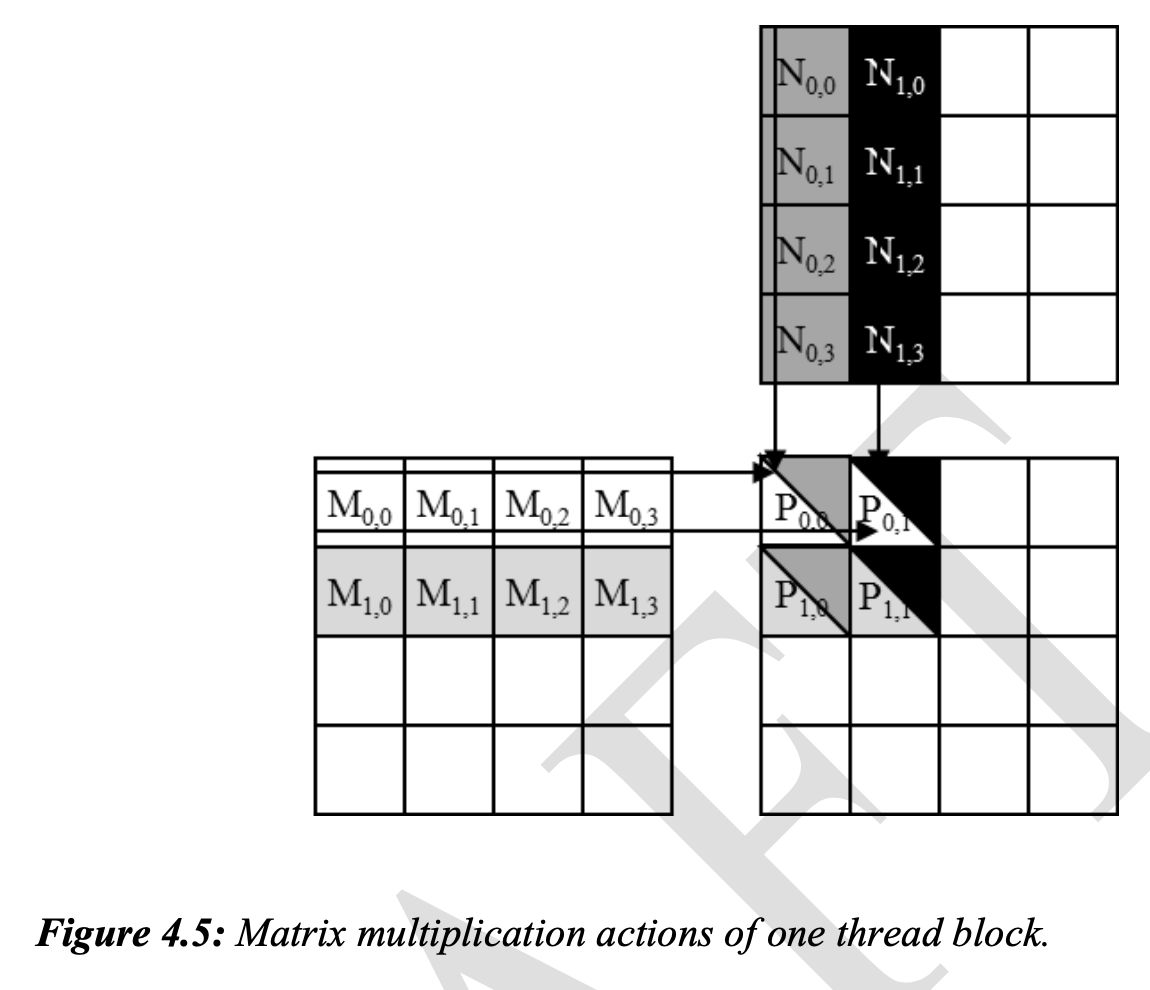
__global__ void MatrixMulKernel(float* M, float* N, float* P,
int Width) {
// Calculate the row index of the P element and M
int Row = blockIdx.y*blockDim.y+threadIdx.y;
// Calculate the column index of P and N
int Col = blockIdx.x*blockDim.x+threadIdx.x;
if ((Row < Width) && (Col < Width)) {
float Pvalue = 0;
// each thread computes one element of the block sub-matrix
for (int k = 0; k < Width; ++k) {
Pvalue += M[Row*Width+k]*N[k*Width+Col];
}
P[Row*Width+Col] = Pvalue;
}
}
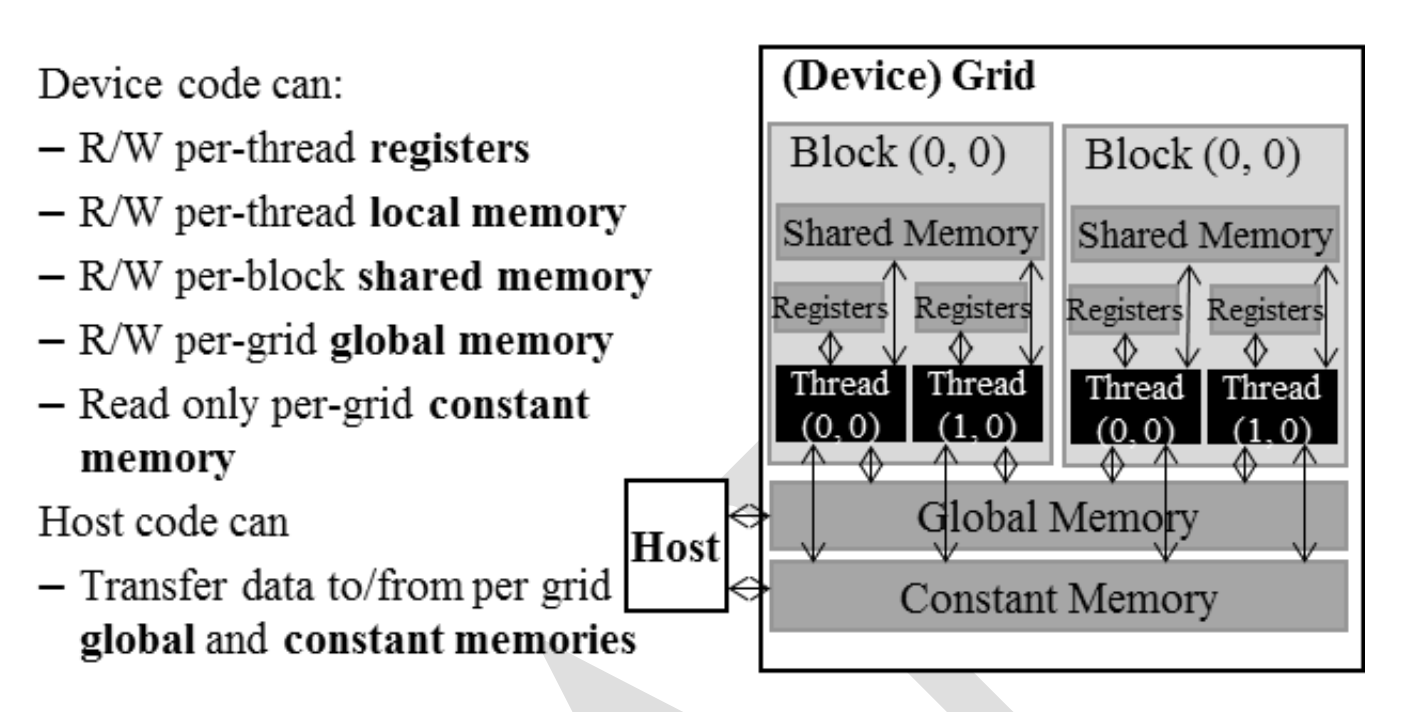
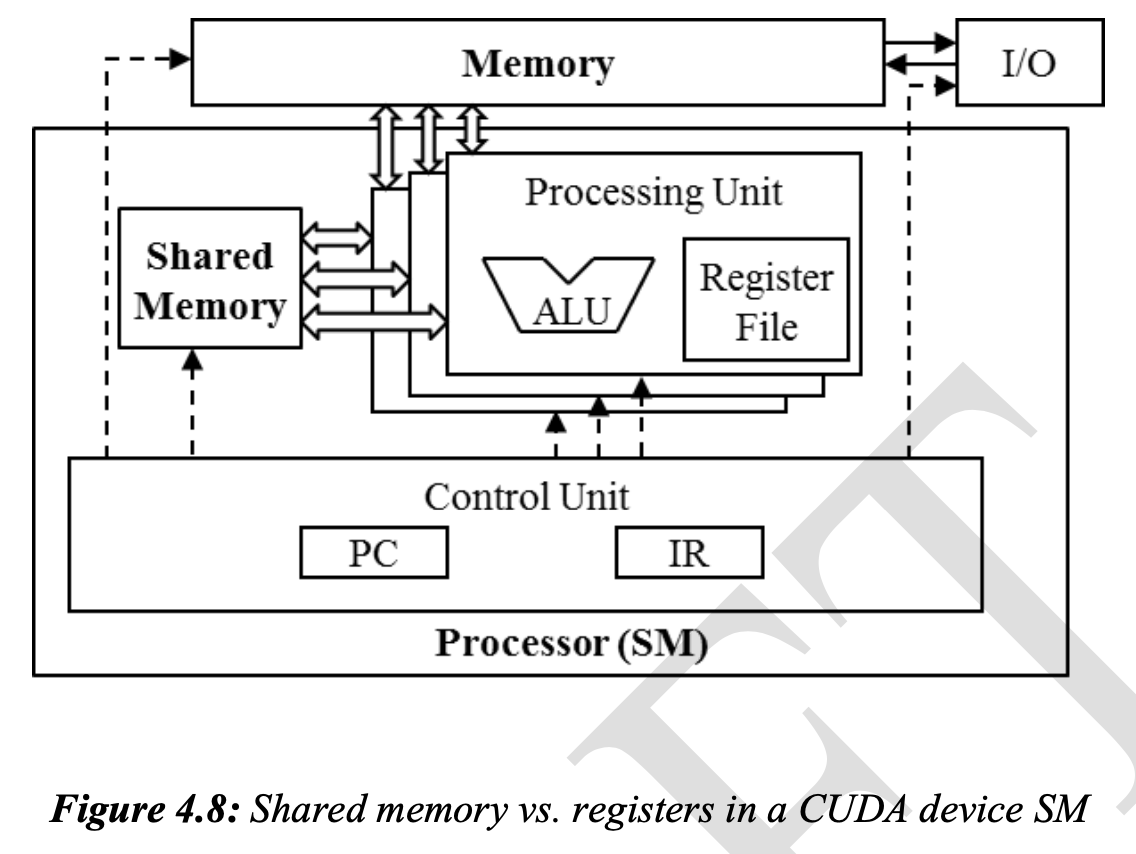
4.3 CUDA Memory Types
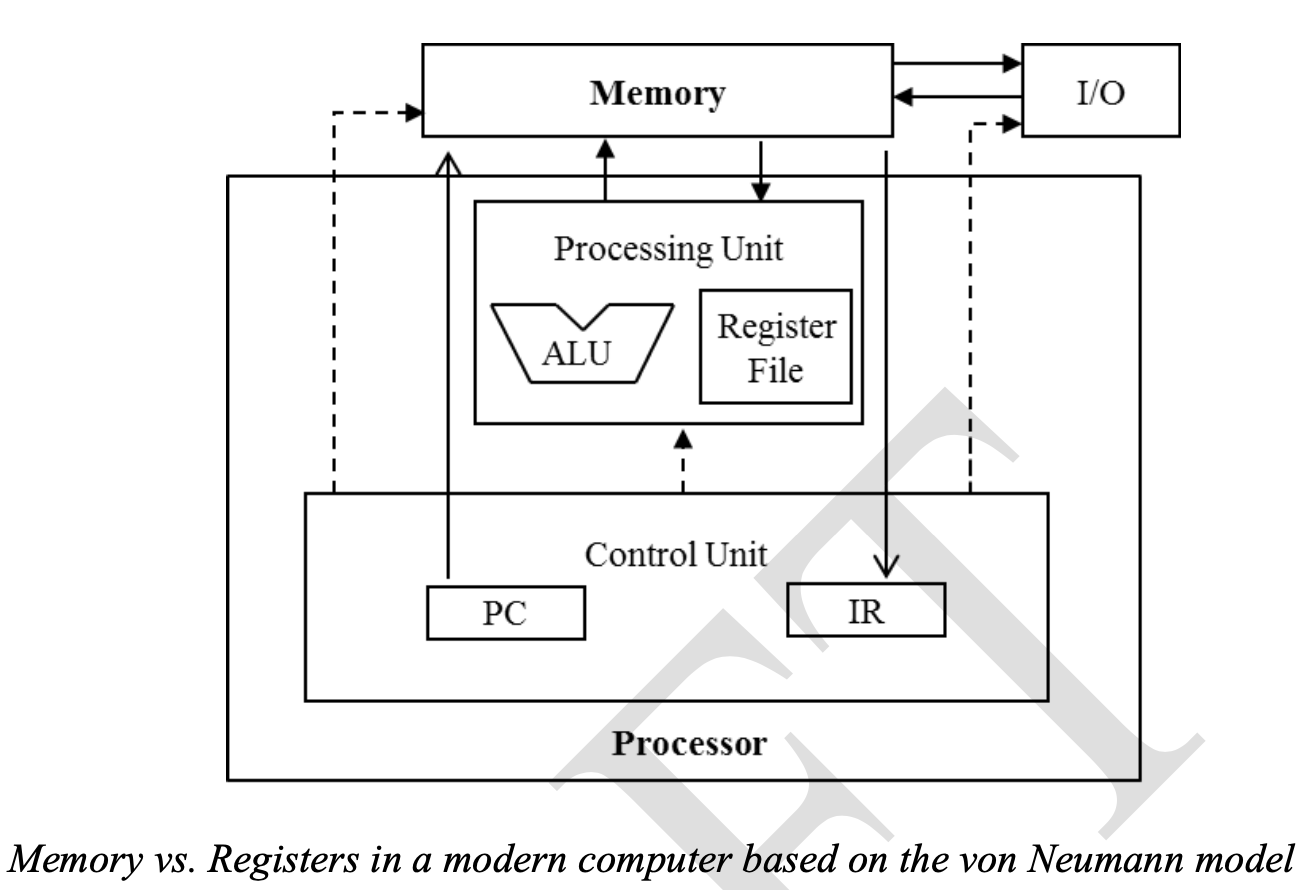
All modern processros find their root in the model proposed by John vonNeumann.


Tiling for Reduced Memory Traffic
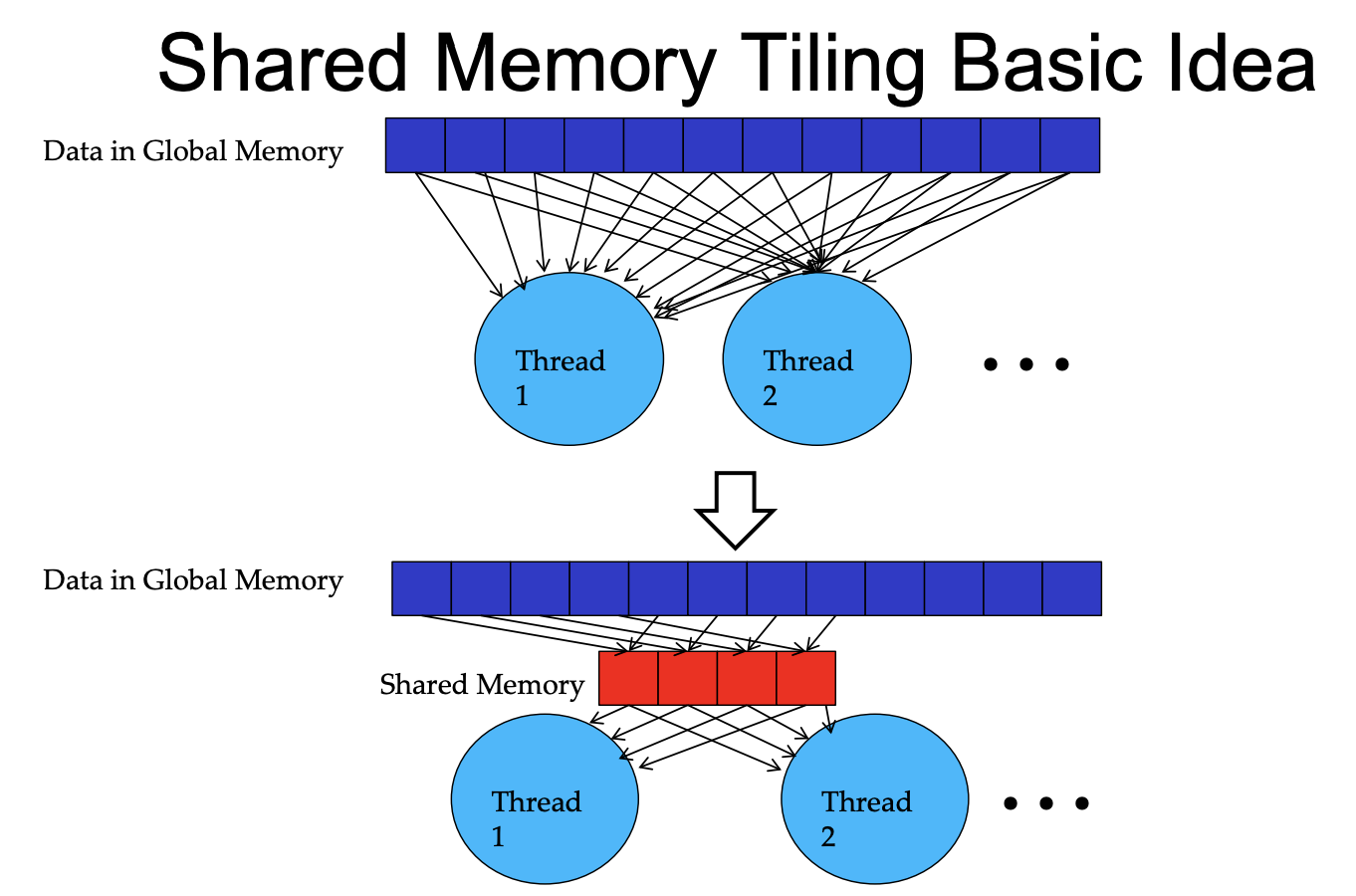
threads that need same data access the data at the similar timing.
Tiling is a program transformation technique that localizes the memory locations accessed among threads and the timing of their accesses.It controls the amount of on-chip memory required by localizing the accesses both in time and in space.
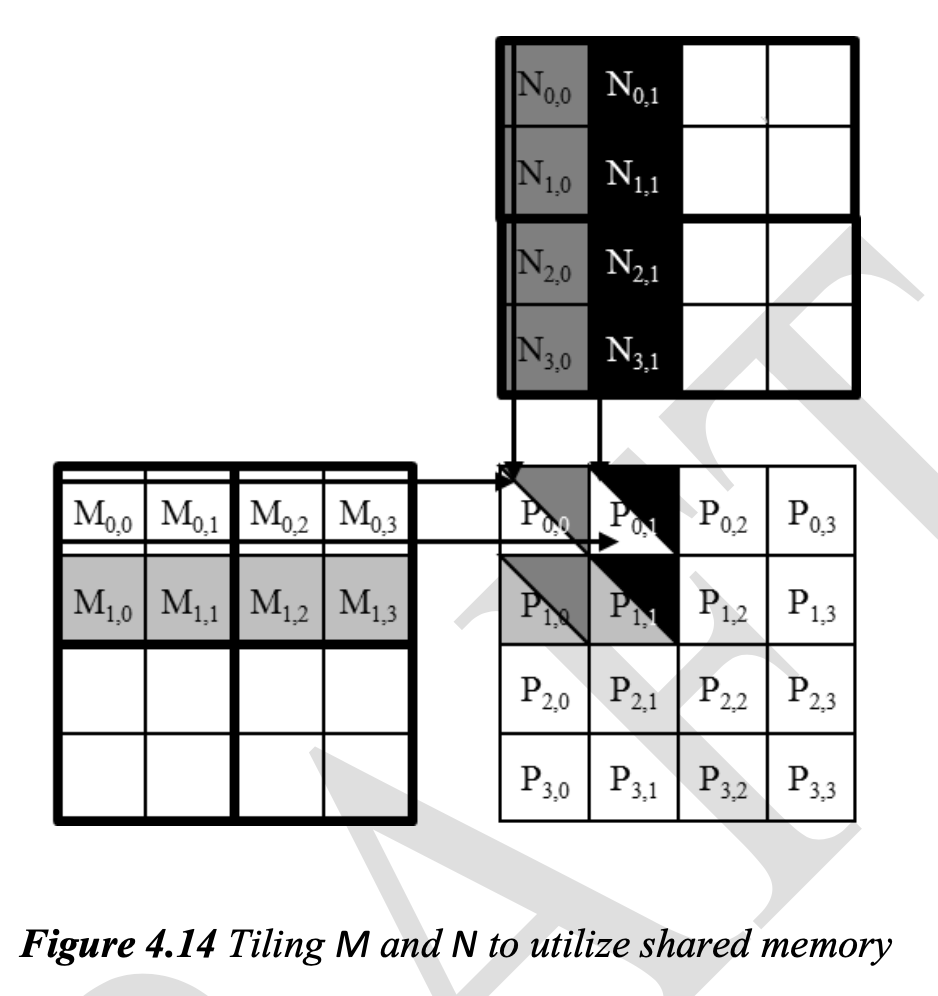
By loading each global memory value into shared memoryso that it can be used multiple times, we reduce the number of accesses to the global memory. In the above case, number of accesses to the global memoryh is reduced by half.
locality
-
Note also that Mds and Nds are re-used to hold the input values. In each phase, the same Mds and Nds are used to hold the subset of M and N elements used in the phase. This allows a much smaller shared memory to serve most of the accesses to global memory. This is due to the fact that each phase focuses on a small subset of the input matrix elements. Such focused access behavior is called locality.
-
Use small, high-speed memories to serve most of the accesses and remove these accesses from the global memory.
A Tiled Matrix Mulitplication Kernel
__global__ void MatrixMulKernel(float* M, float* N, float* P, int Width) {
__shared__ float Mds[TILE_WIDTH][TILE_WIDTH];
__shared__ float Nds[TILE_WIDTH][TILE_WIDTH];
int bx = blockIdx.x; int by = blockIdx.y; // save values into autmatic
int tx = threadIdx.x; int ty = threadIdx.y; // variables (registers) for faster access
// Identify the row and column of the P element to work on
int Row = by * TILE_WIDTH + ty;
int Col = bx * TILE_WIDTH + tx;
float Pvalue = 0;
// Loop over the M and N tiles required to compute P element
for (int ph = 0; ph < Width/TILE_WIDTH; ++ph) {
// Collaborative loading of M and N tiles into shared memory
Mds[ty][tx] = M[Row*Width + ph*TILE_WIDTH + tx];
Nds[ty][tx] = N[(ph*TILE_WIDTH + ty)*Width + Col];
__syncthreads();
for (int k = 0; k < TILE_WIDTH; ++k) {
Pvalue += Mds[ty][k] * Nds[k][tx];
}
__syncthreads();
}
P[Row*Width + Col] = Pvalue;
}
}Boundary Chekcs
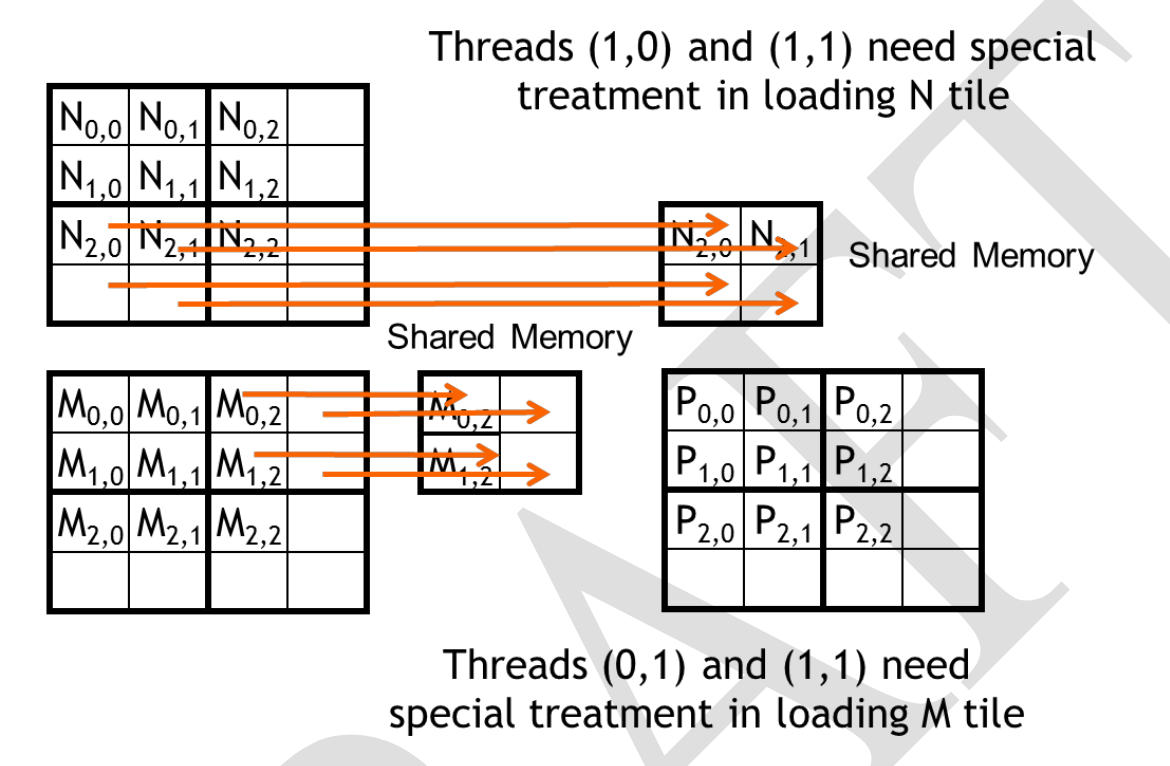
Using dis-proportional tile size can cause problems (accessing the wrong thread due to wrong index). In this case, one has to check index in the following way:
// Loop over the M and N tiles required to compute P element
8. for (int ph = 0; ph < ceil(Width/(float)TILE_WIDTH); ++ph) {
// Collaborative loading of M and N tiles into shared memory
9. if ((Row< Width) && (ph*TILE_WIDTH+tx)< Width)
Mds[ty][tx] = M[Row*Width + ph*TILE_WIDTH + tx];
10. if ((ph*TILE_WIDTH+ty)<Width && Col<Width)
Nds[ty][tx] = N[(ph*TILE_WIDTH + ty)*Width + Col];
11.
__syncthreads();
12. for (int k = 0; k < TILE_WIDTH; ++k) {
13. Pvalue += Mds[ty][k] * Nds[k][tx];
}
14. __syncthreads();
}
15. if ((Row<Width) && (Col<Width)P[Row*Width + Col] = Pvalue;