CUDA Thread Organization
Launch Kernel with grid and block dimension
dim3 three unsigned integer field(x,y,z)
- set y,z to 1 to make 1D
- set z to 1 to make 2D
dim3 dimGrid(ceil(n/256.0), 1, 1); #vary grid accordingly to n
dim3 dimBlock(256, 1, 1);
vecAddKernel<<<dimGrid, dimBlock>>>(...);Block Configuration
- total size of a block is limited to 1024 (512,1,1), (8,16,4), ...
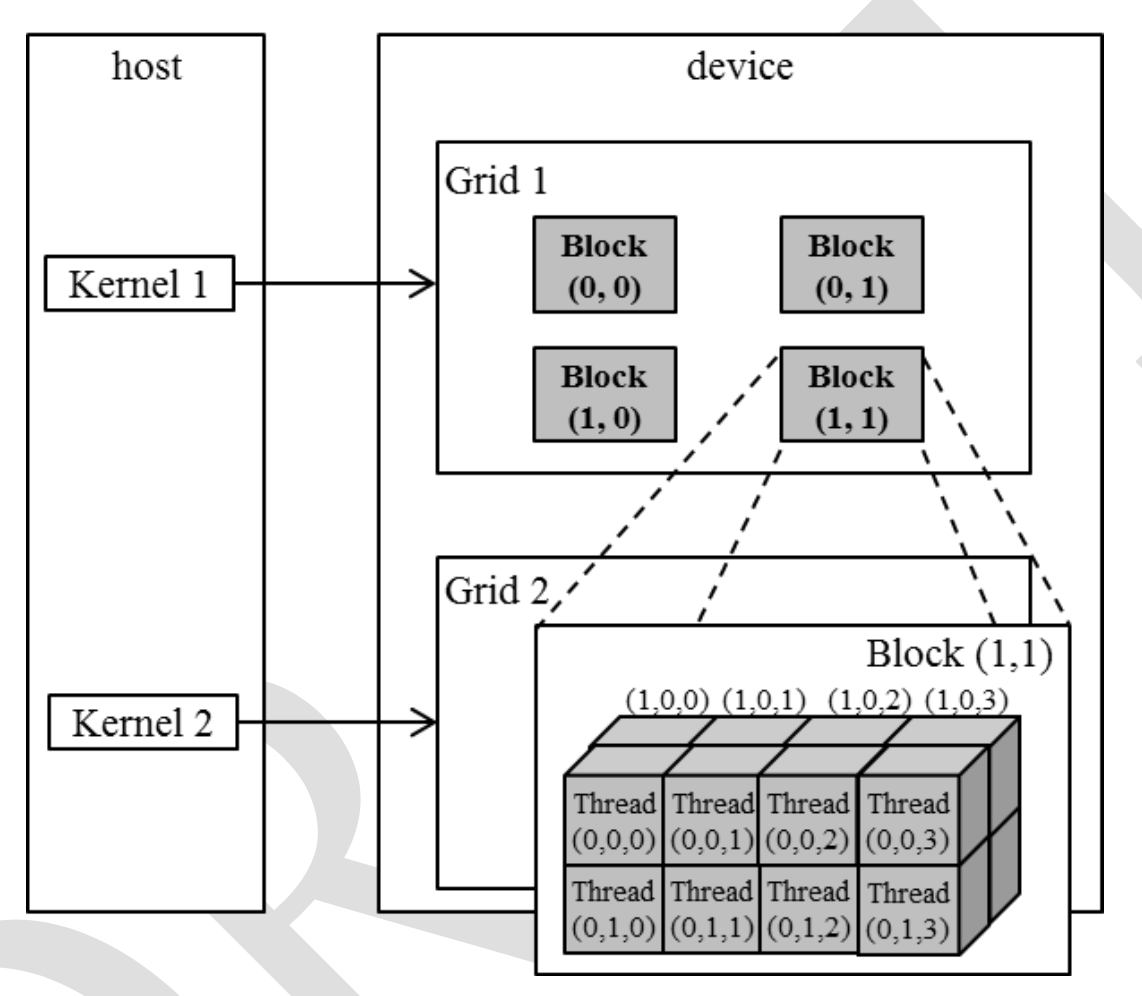
dim3 dimGrid(2, 2, 1);
dim3 dimBlock(4, 2, 2);
KernelFunction<<<dimGrid, dimBlock>>>(...);Mapping Threads to Multi-Dimensional Data
Launch a 2D kernel to process the picture

dim3 dimGrid(ceil(m/16.0), ceil(n/16.0), 1);
dim3 dimBlock(16, 16, 1);
colorToGreyscaleConversion<<<dimGrid,dimBlock>>>(d_Pin,d_Pout,m,n );The information of columns are not known to the compiler, thus it has to be flattened in CUDA C, also memory space is flat in modern computers.
Row-major Layout (used by CUDA C)
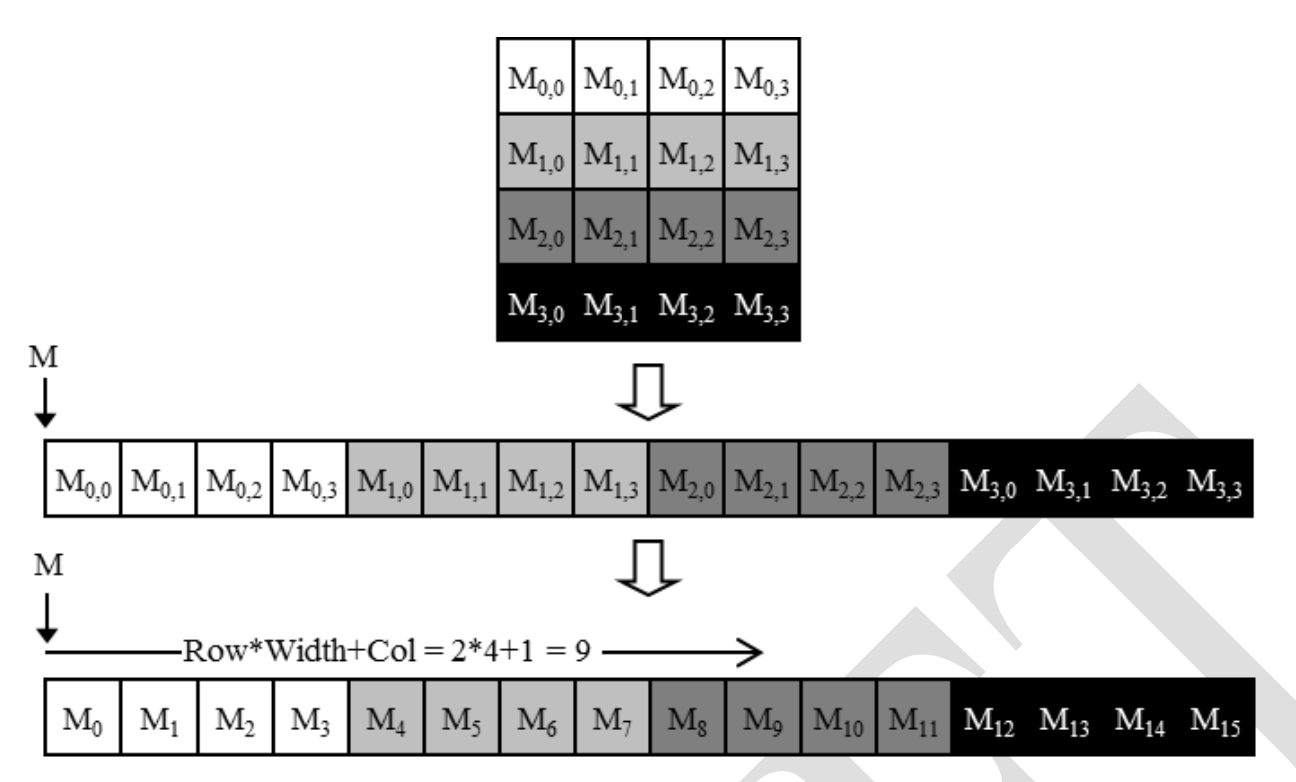
There are Column-major layout, which is used by FORTRAN. It is equivalent to transposed form of row-major layout.
Source code of 2D img: color -> grey conversion
/ we have 3 channels corresponding to RGB
// The input image is encoded as unsigned characters [0, 255]
__global__
void colortoGreyscaleConvertion(unsigned char * Pout, unsigned char * Pin, int width, int height)
{
int Col = threadIdx.x + blockIdx.x * blockDim.x;
int Row = threadIdx.y + blockIdx.y * blockDim.y;
if (Col < width && Row < height) {
// get 1D coordinate for the grayscale image
int greyOffset = Row*width + Col;
// one can think of the RGB image having
// CHANNEL times columns than the gray scale image
int rgbOffset = greyOffset*CHANNELS; // CHANNELS= 3(r,g,b)
unsigned char r = Pin[rgbOffset ]; // red value for pixel
unsigned char g = Pin[rgbOffset + 1]; // green value for pixel
unsigned char b = Pin[rgbOffset + 2]; // blue value for pixel
// perform the rescaling and store it
// We multiply by floating point constants
Pout[grayOffset] = 0.21f*r + 0.71f*g + 0.07f*b;
}
}If you want to make it 3D, introduce
// m(# of columns), n(# of rows)
int Plane = blockIdx.z*blockDim.z + threadIdx.z
P[Plane*m*n + Row * m + Col]Image Blur
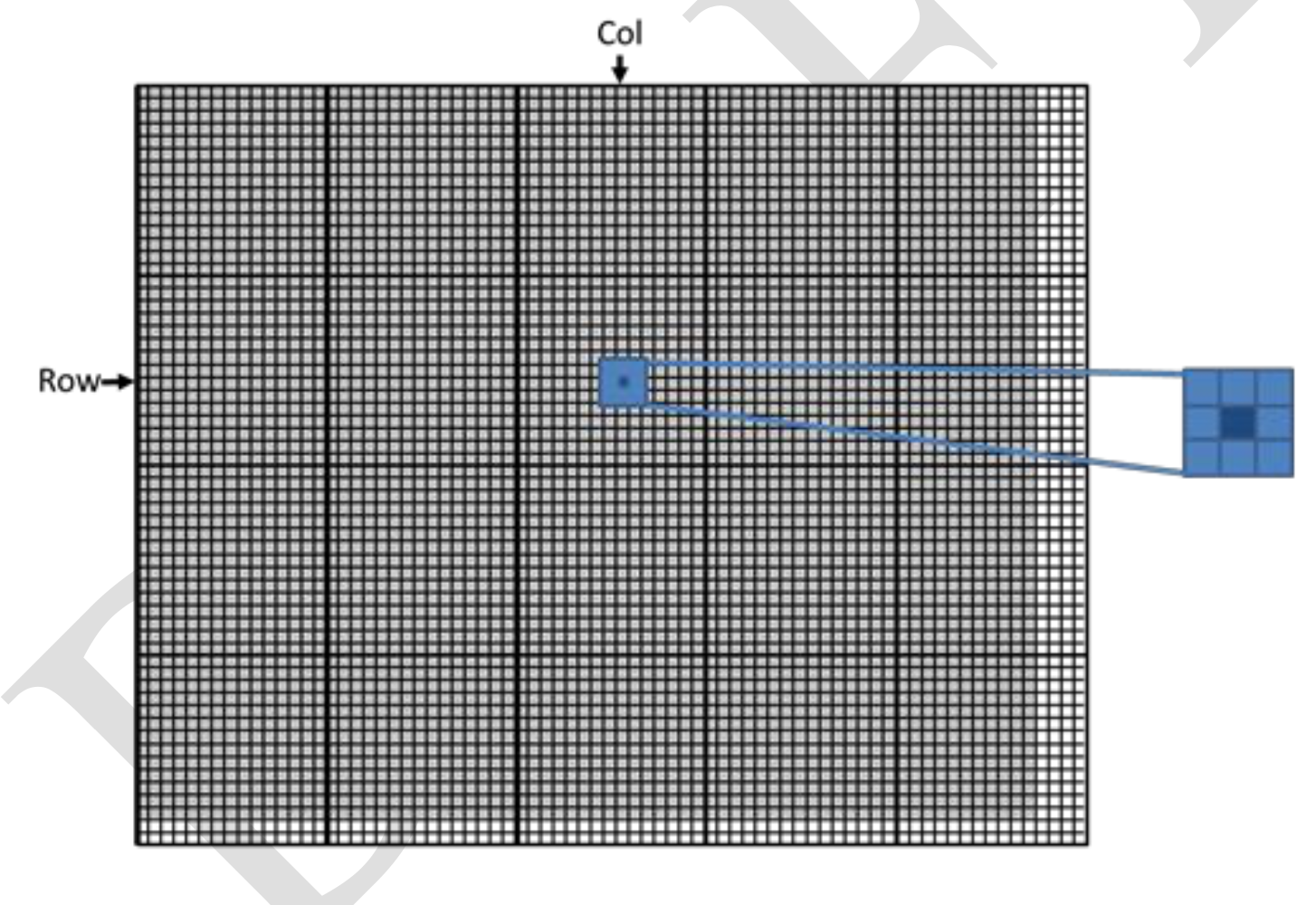
Source Code for image blur kernel
__global__
void blurKernel(unsigned char * in, unsigned char * out, int w, int h) {
int Col = blockIdx.x * blockDim.x + threadIdx.x;
int Row = blockIdx.y * blockDim.y + threadIdx.y;
if (Col < w && Row < h) {
int pixVal = 0;
int pixels = 0;
// Get the average of the surrounding BLUR_SIZE x BLUR_SIZE box
for(int blurRow = -BLUR_SIZE; blurRow < BLUR_SIZE+1; ++blurRow) {
for(int blurCol = -BLUR_SIZE; blurCol < BLUR_SIZE+1; ++blurCol){
int curRow = Row + blurRow;
int curCol = Col + blurCol;
if(curRow > -1 && curRow < h && curCol > -1 && curCol < w) {
pixVal += in[curRow * w + curCol];
pixels++; // Keep track of number of pixels in the avg
}
}
}
// Write our new pixel value out
out[Row * w + Col] = (unsigned char)(pixVal / pixels);
}
}
Synchronization and Transparent Scalability
__syncthreads() coordinate activitiesof threads in the same block using barrier synchronization.
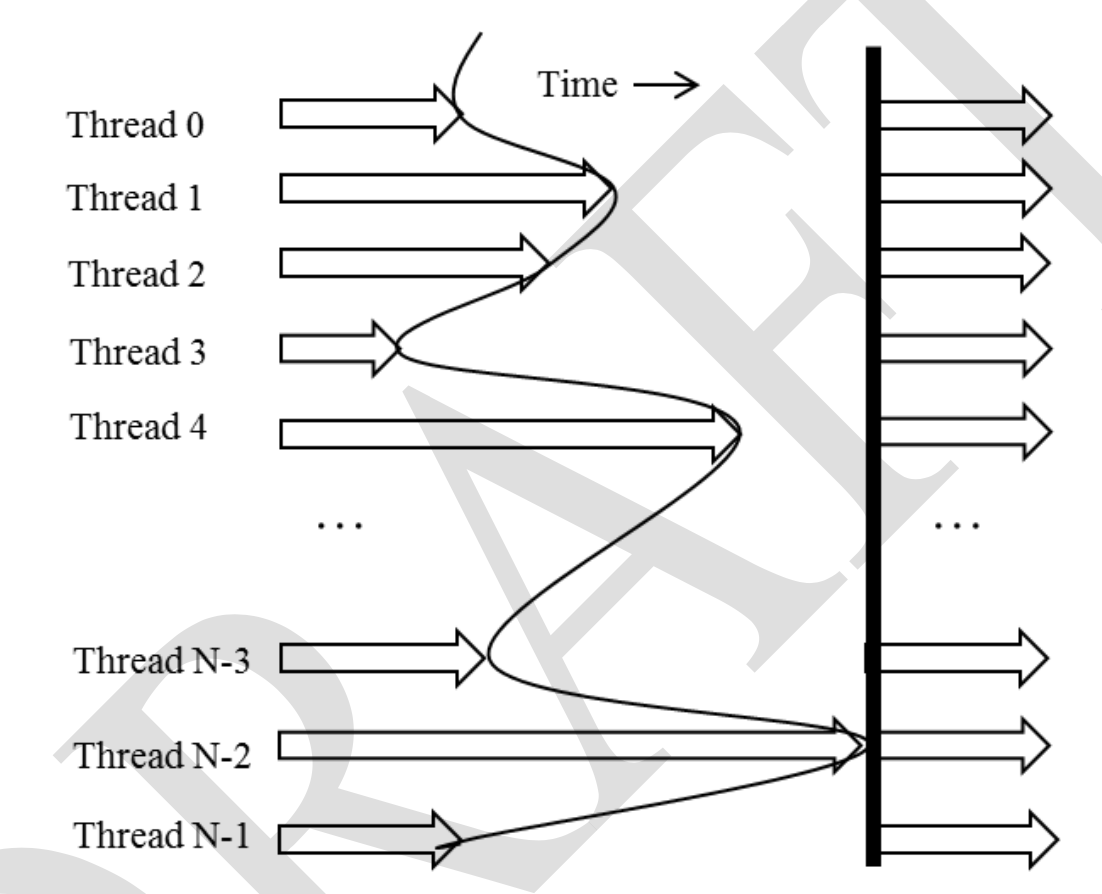
Threads will wait untill all threads finish their process so that no thread is left behind.
However, for if-else caluse, if each path has a __syncthreads() statement, either all threads execute if path or all threads execute else path. If some go into if and some go into else, they would be waiting at different barrier synchronizaiton points forever. So be careful!
Threads should execute in close time proximity. If one takes too long, others have to wait...
Also, all threads should have access to necessary resources, otherwise, same waiting occurs. In order to prevent this problem, bloack begins execution only after the run-time system has secured all necessary resources, and threads in the same block are also assigne to the same resource.
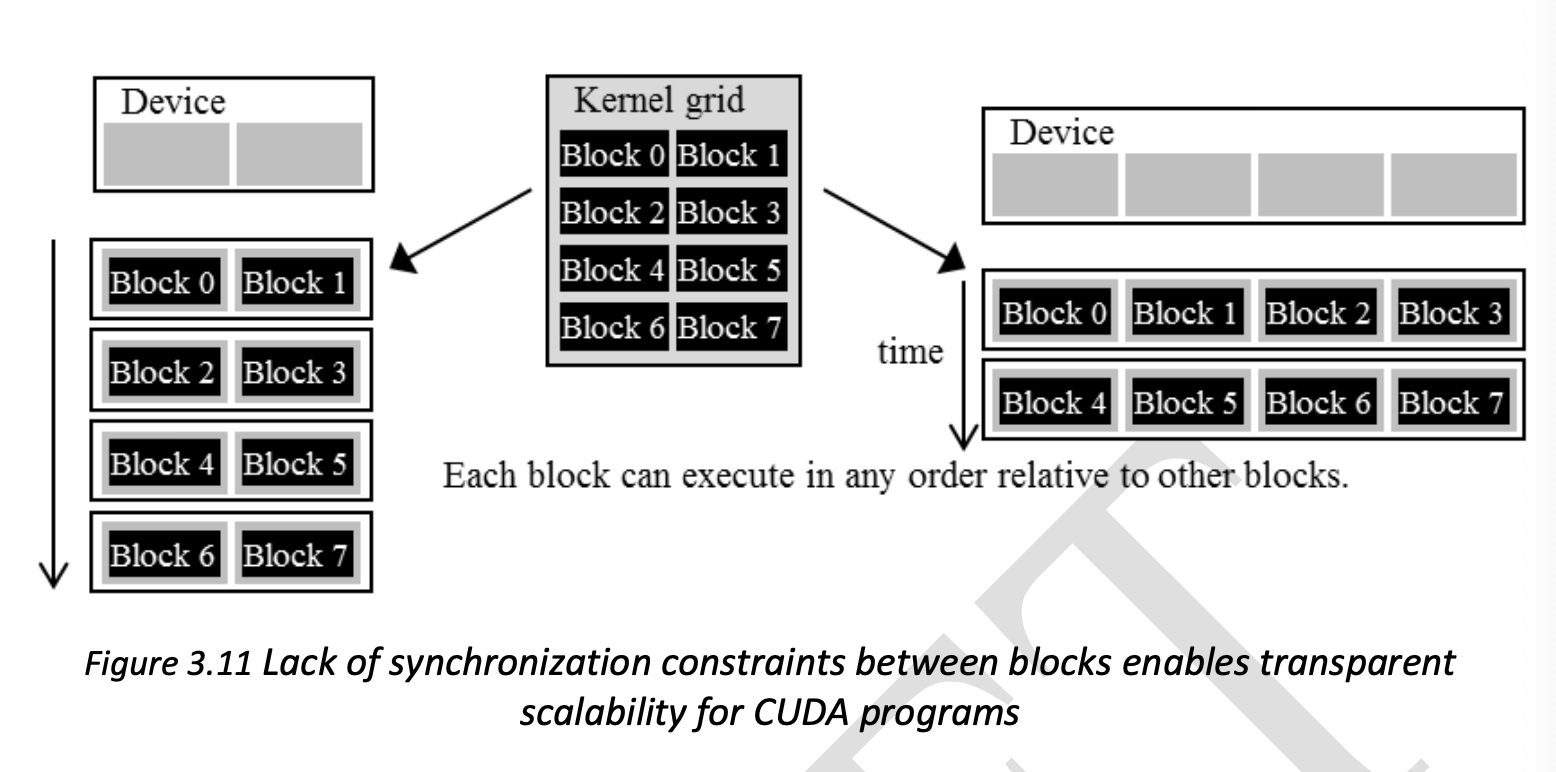
Since each block is independent of each other, blocks can be executed in any order, giving transparent scalability and flexbility.
transparent scalability : ability to execute the same application code on hardware with different number of execution resources. It reduces the burden on applicaition developers and improves usability of applications.
Ex. run slowly on mobile with low power, but run with high speed on desktop with high power.
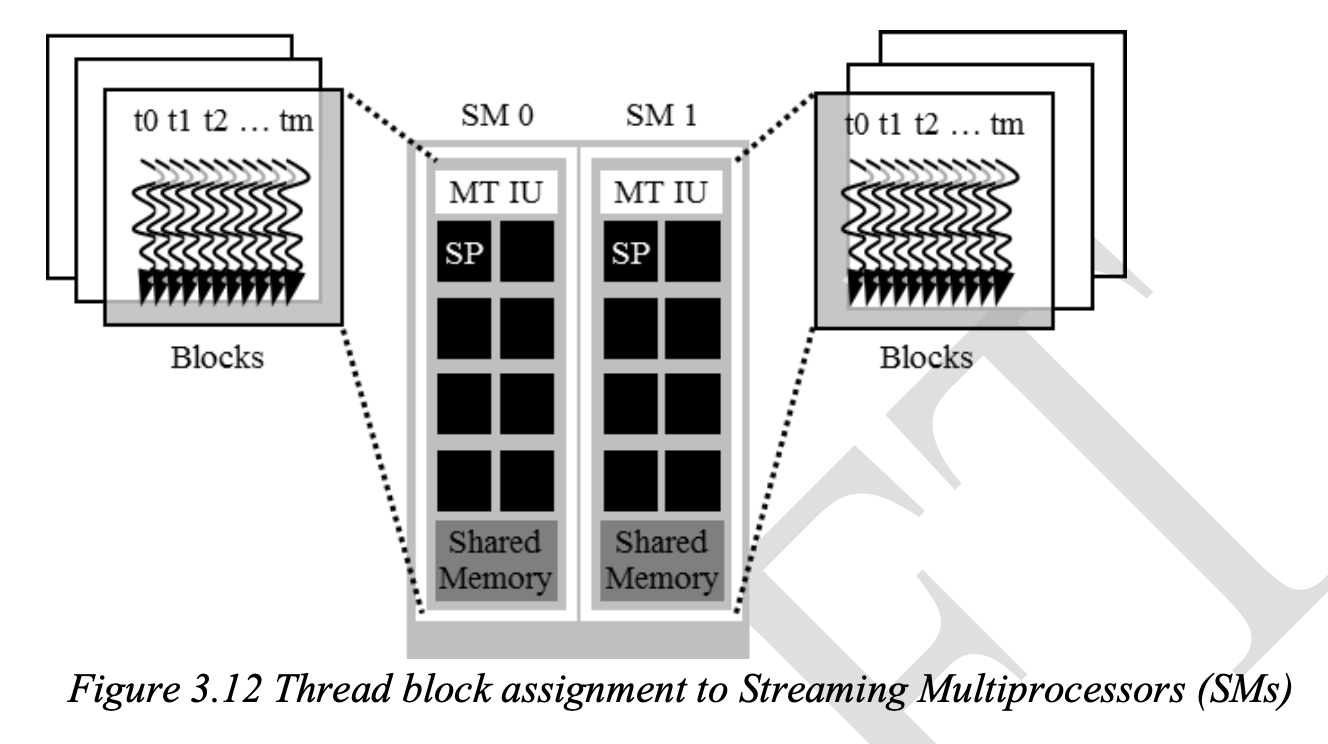
Resource Assignment
The execution resources are organized into SMs (Streaming Multiprocessors), and each SM has a limit on the number of blocks that can be assigned (In CUDA, 8 block and 1536 threads), thus limiting the active block numbers. If the device has 30 SMs, it can have up to 46,080 threads simultaneously for execution.
Querying Device Properties
Returns number of available CUDA devices in the system
int dev_count;
cudaGetDeviceCount(&dev_count);CUDA run-time numbers all the avilable devices in the system from 0 to dev_count-1.
Returns the properties of the device whose number is given as an argument
cudaDeviceProp dev_prop; //
cudaGetDeviceProperties( &dev_prop, device_number);
//decide if device has sufficient resources and capabilities }cudaDeviceProp C struct type with properties of CUDA device
.maxThreadsPerBlcok max number of threads allowed in a block
.multiProcessorCOunt number of SMs
.clockRate clock frequency
.maxThreadsDim[i] max number of threads allowed along each dim of a block (i=0:x i=1:y i=2:z)
.maxGridSize[i] max number of blocks allowed along each dim of a grid (i=0:x i=1:y i=2:z)
Threads Scheduling and Latency Tolerance
Once block is assigned to a SM, it is further divied into 32-thread units called warps. Its size can vary, but can be found in dev_prop.warpSize.
warp : unit of thread scheduling in SMs with threadIdx (0 - 31),(32 - 63) ... per warp.
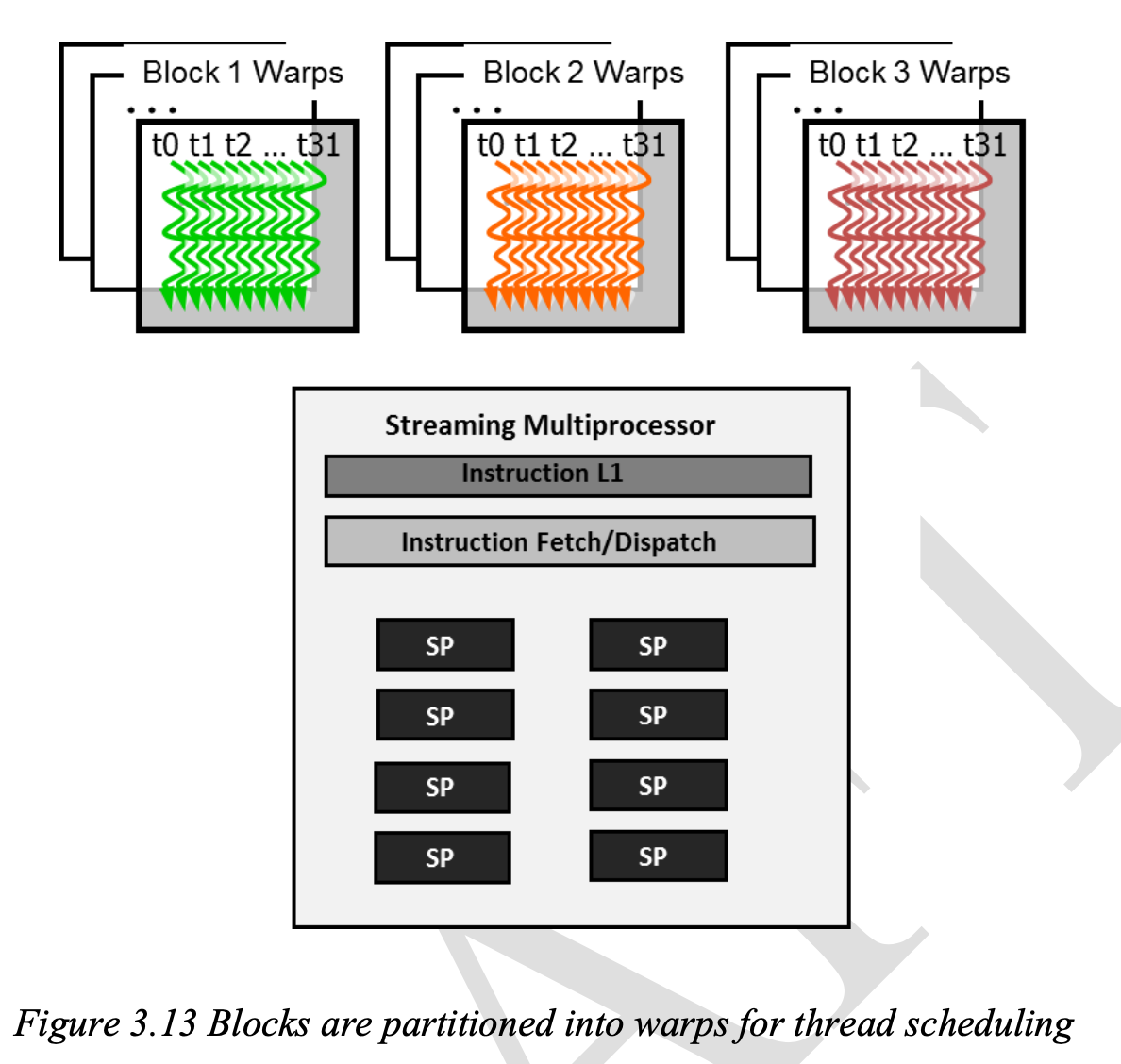
If each block has 256 threads, it has 256/32 = 8 warps, and with three blocks in each SM, 8*3 =24 warps in each SM.
SM execute all threads in a wrap in SIMD.
Single Instruction, Multiple Data (SIMD) : One instruction is fetched and executed for all threads in the warp. Thus, all threads in a warp will always have the same execution timing.
Streaming Processor (SP) :these actually execute instruction.
Hardware can execute instructions for a small subset of all warps im the SM. Then, why so many warps in an SM?
Answer:
Latency tolerance : The mechanism of filling the latency tim eof operations with work from other threads.
If an instruction to be executed by a warp needs to wait for the result of a previous operation, the warp is not selected. Using priority mechanism, other ready warps are selected for execution. ( No waiting :) )
It will make full use of the execution hardware despite long latency operations.
The ability to tolerate long operation latency is the main reason why GPUs do not dedicate nearly as much chip area to cache and branch prediction mechanisms. Thus more to execution!
