◾CNN 개념
CNN(Convolutional Neural Networks): 주로 이미지나 영상 데이터를 처리할 떄 쓰이며Convolution전처리 작업이 들어가는 Neural Net 모델Convolution연산을 이용해 필터를 만들고 해당 필터를 이용해 이미지를 변환하는 작업은 원래 이루어졌다.CNN은Convolution연산을 딥러닝으로 해결한다.- 특징을 검출하는 구간과 분류하는 구간으로 나누어져있다.

Convolution: 특정 패턴이 있느지를 박스로 훓으며 마킹- 위아래선 필터, 좌우선 필터, 대각선 필터, 동그라미 필터 등 다양한 필터로 해당 패턴이 그림위에 있는지 확인
- Convolution 박스로 밀고나면, 숫자가 나온다, 그 숫자를 Activation(주로 ReLU)에 넣어 나온 값으로 이미지 지도를 새로 그린다.
Pooling(풀링): 데이터의 공간적인 특성을 유지하면서 크기를 줄여주는 것으로 특정 위치에서 큰 역할을 하는 특징을 추출(Max Pooling)하거나, 전체를 대변하는 특징을 추출(Average Pooling)할 수 있다.- Convolution 과정 뒤에 많이 나오게 된다.
- 조금씩 전체적인 그림을 볼 수 있도록 이미지의 크기를 줄여준다.
MaxPooling: 사이즈를 점진적으로 줄이는 방법- nXn(Pool)을 중요한 정보(MAX)한 개로 줄인다.
- 선명한 정보만 남겨서 판단과 학습이 쉬워지고 노이즈가 줄면서 덤으로 융통성도 확보된다.
- 보통 2X2로 화면 전역에 적용한다.
stride: 좌우로 몇 칸씩 뛸지 설정. 보통 2X2
Conv Layer: 패턴들을 쌓아가며 점차 복잡한 패턴을 인식한다.(conv)- 사이즈를 줄여가며, 더욱 추상화 해나간다.(MaxPooling)
Padding: 반복적으로 합성곱 연산을 했을 때 특성의 행렬의 크기가 작아지는 것을 방지하고 외곽부분의 정보손실을 줄이고자 이미지의 외곽에 값을 채워넣는 방법- 일반적으로 0으로 채워넣는
zero padding사용
- 일반적으로 0으로 채워넣는
Dropout: Neural Net에게 융통성을 기르는 방법으로 학습 시킬 때 일부러 정보를 누락시키거나 중간중간 노드를 Off 한다.- 과적합을 최소화 하는 방법 중 하나로 의도적으로 정보를 줄이는 형식이다.

◾CNN 실습
- 데이터 읽기
- tensorflow를 통해 mnist 데이터 읽기
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train, X_test = X_train / 255, X_test / 255
X_train = X_train.reshape((60000, 28, 28, 1))
X_test = X_test.reshape((10000, 28, 28, 1))- 모델 구현
- Conv2D, MaxPooling2D, Dropout, Flatten 등을 이용해 모델을 구성한다.
from tensorflow.keras import layers, models
model = models.Sequential([
layers.Conv2D(32, kernel_size=(5, 5), strides=(1, 1),
padding='same', activation='relu', input_shape=(28, 28, 1)),
layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)),
layers.Conv2D(64, (2, 2), activation='relu', padding='same'),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Dropout(0.25),
layers.Flatten(),
layers.Dense(1000, activation='relu'),
layers.Dense(10, activation='softmax')
])
model.summary()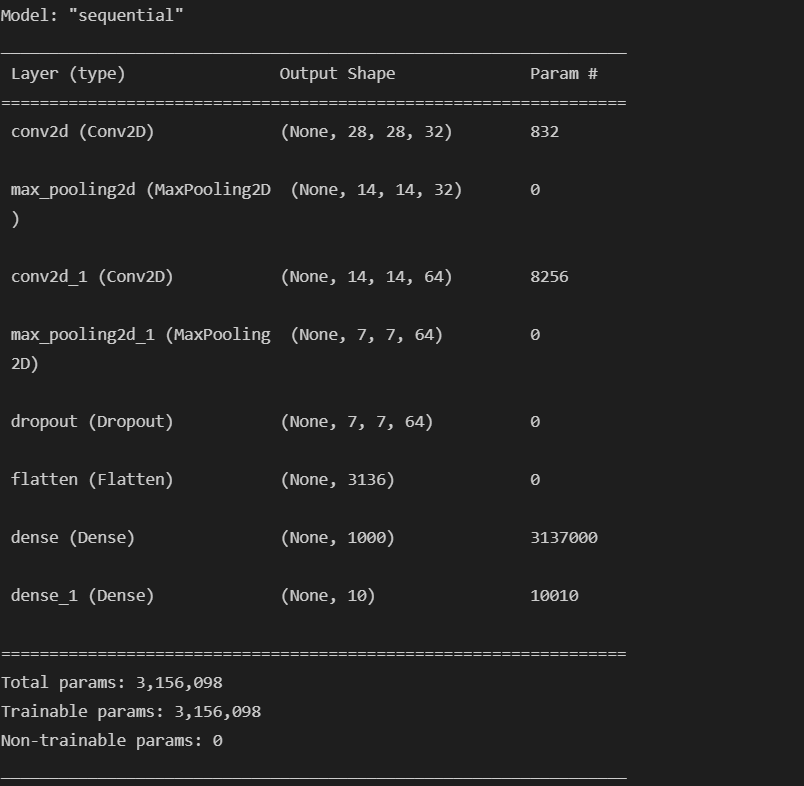
- 모델 compile
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])- 모델 학습
hist = model.fit(X_train, y_train, epochs=5, verbose=1,
validation_data=(X_test, y_test))
- 모델 결과
- 결과 그리기
import matplotlib.pyplot as plt
plot_target = ['loss', 'val_loss', 'accuracy', 'val_accuracy']
plt.figure(figsize=(12, 8))
for each in plot_target:
plt.plot(hist.history[each], label= each)
plt.legend()
plt.grid()
plt.show()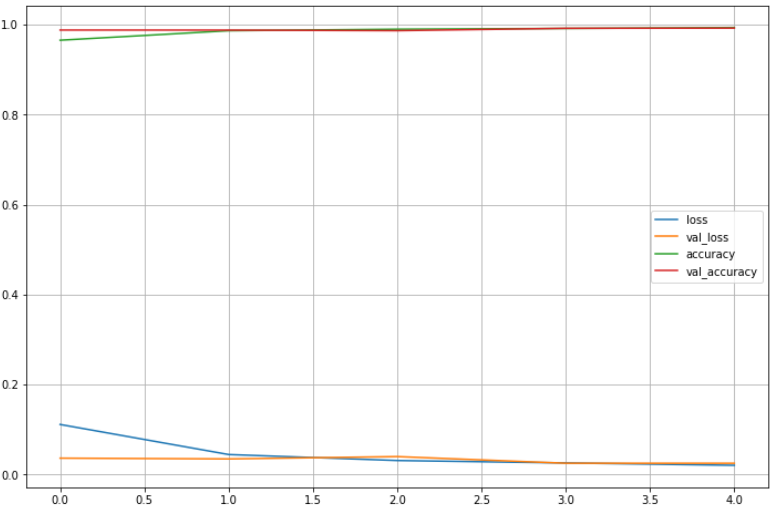
- 결과 확인
score = model.evaluate(X_test, y_test)
print("Test loss : " + str(score[0]))
print("Test accuracy : " + str(score[1]))
- 틀린 결과 확인
- 전체 데이터 인덱스 확인
import numpy as np
predicted_result = model.predict(X_test)
predicted_labels = np.argmax(predicted_result, axis=1)
predicted_labels[:10]
- 틀린 데이터 인덱스 확인
wrong_result = []
for n in range(0, len(y_test)):
if predicted_labels[n] != y_test[n]:
wrong_result.append(n)
len(wrong_result)
- 틀린 데이터 중 16개 랜덤 선택
import random
samples = random.choices(population=wrong_result, k=16)
samples[:3]
- 틀린 데이터 그리기
plt.figure(figsize=(14, 12))
for idx, n in enumerate(samples):
plt.subplot(4, 4, idx+1)
plt.imshow(X_test[n].reshape(28, 28), cmap='Greys', interpolation='nearest')
plt.title('Label : '+str(y_test[n]) + " | Predict : " + str(predicted_labels[n]))
plt.axis('off')
plt.show()
- 모델 저장
- 모델은 훈련 중 및 훈련 후에 저장할 수 있다.
- 즉, 모델이 중단된 위치에서 다시 시작하고 긴 훈련 시간을 피할 수 있다.
- 공유 목록 : 모델을 만드는 코드, 모델의 훈련된 가중치 또는 파라미터
- HDF5 포맷으로 모델 저장 및 사용하기 위해 설치 : pip install pyyaml h5py
- 공식 문서
model.save('./model/MNIST_CNN_model.h5')- 모델 불러오기
load_model을 통해 모델을 다시 불러올 수 있다.
from tensorflow.keras import models
# test_model = models.load_model('./model/MNIST_CNN_model.h5')
후라이드 치킨