◾MNIST 데이터
- 데이터 읽기
- Tensorflow에서 MNIST를 제공한다.
- 각 픽셀이 255값이 최대값이여서 0~1사이의 값으로 조정(일종의 Min Max Scaler)
import tensorflow as tf
import numpy as np
import pandas as pd
mnist = tf.keras.datasets.mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train, X_test = X_train / 255.0, X_test / 255.0
X_train.shape, X_test.shape, y_train.shape, y_test.shape
- 데이터 정리
- One hot Encoding을 진행해야하지만 loss 함수를
sparse_categorical_crossentropy로 설정하면 같은 효과를 낼 수 있다.
- 모델 구현
- 784개의 입력, 1000개의 노드를 가진 Layer, 10개의 출력으로 구성
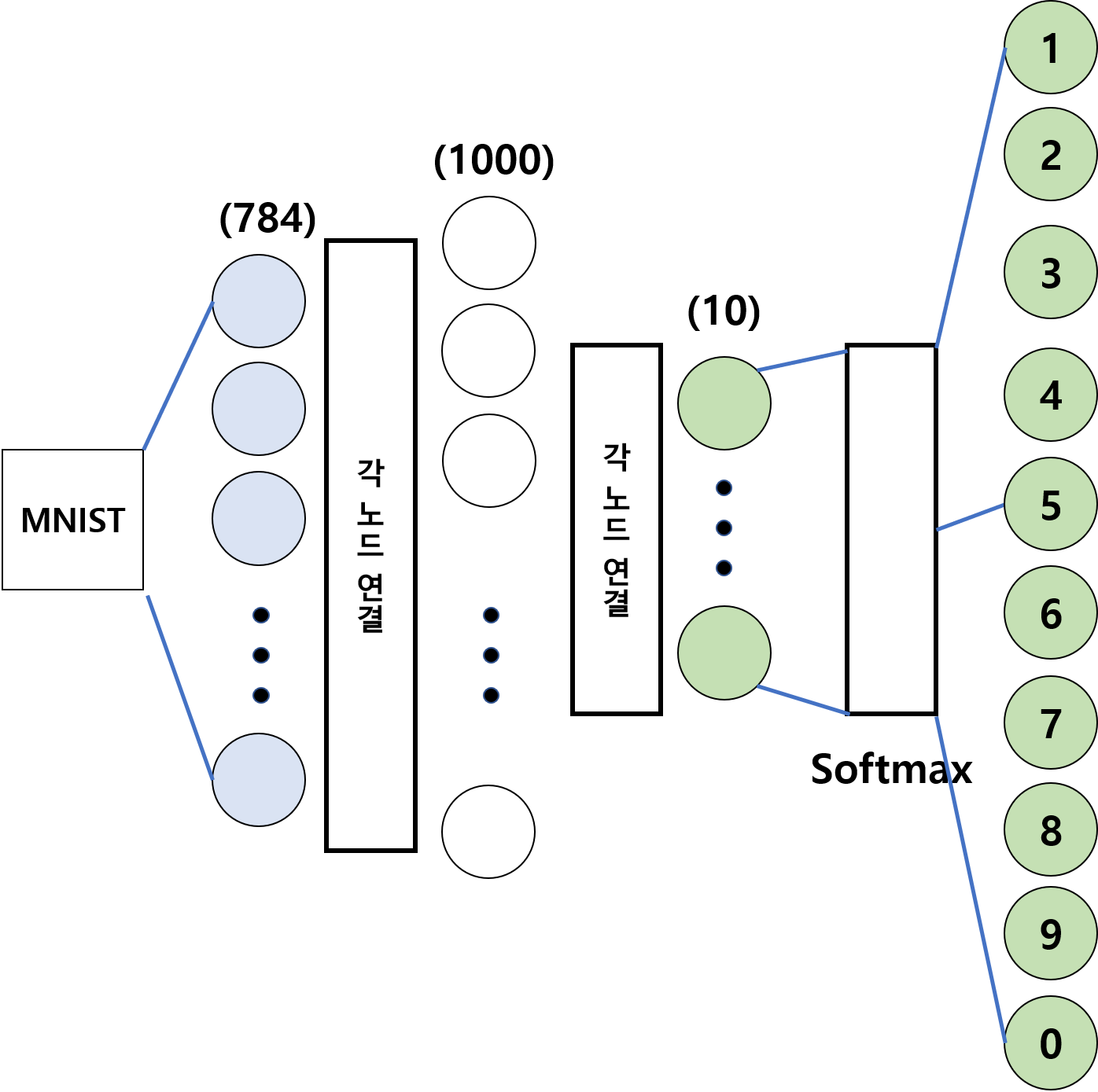
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(1000, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.summary()
- 모델 학습
hist = model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=100, verbose=1)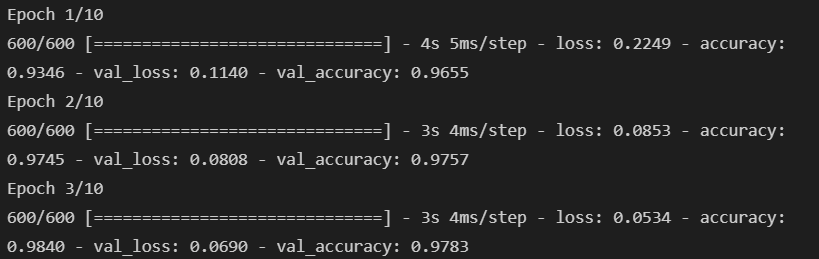
- 모델 결과
- 결과 그리기
import matplotlib.pyplot as plt
plot_target = ['loss', 'val_loss', 'accuracy', 'val_accuracy']
plt.figure(figsize=(12, 8))
for each in plot_target:
plt.plot(hist.history[each], label=each)
plt.legend()
plt.grid()
plt.show()
- 결과 확인(evaluate)
score = model.evaluate(X_test, y_test)
print('Test loss : {}'.format(score[0]))
print('Test accuracy : {}'.format(score[1]))
- 잘못 예측한 경우 확인
- 예측 확률이 높은 경우 해당 값을 선택한다.
np.argmax: 각 행(axis=1), 열(axis=0)에서의 최대값의 인덱스를 반환한다.
predicted_result = model.predict(X_test)
predicted_labels = np.argmax(predicted_result, axis=1)
predicted_labels[:10]
y_test[:10]
- 잘못된 결과 저장
wrong_result = []
for n in range(0, len(y_test)):
if predicted_labels[n] != y_test[n]:
wrong_result.append(n)
len(wrong_result)
- 틀린 예측 중 16개 랜덤 선택
import random
samples = random.choices(population=wrong_result, k = 16)- 선택된 16개의 데이터 그리기
plt.figure(figsize=(14, 12))
for idx, n in enumerate(samples):
plt.subplot(4, 4, idx+1)
plt.imshow(X_test[n].reshape(28, 28), cmap='Greys')
plt.title("Label : " + str(y_test[n]) + ' | Predict : ' + str(predicted_labels[n]))
plt.axis('off')
plt.show()
◾MNIST fashion 데이터
- MNIST fashion data : 숫자로 된 MNIST 데이터처럼 28*28 크기의 패션과 관련된 10개 종류의 데이터
- 데이터 읽기
- tensorflow를 통해 데이터 읽기
import tensorflow as tf
fashion_mnist = tf.keras.datasets.fashion_mnist
(X_train, y_train), (X_test, y_test) = fashion_mnist.load_data()
X_train, X_test = X_train / 255, X_test / 255- 데이터 확인
import random
import matplotlib.pyplot as plt
samples = random.choices(population=range(0, len(y_train)), k=16)
plt.figure(figsize=(14, 12))
for idx, n in enumerate(samples):
plt.subplot(4, 4, idx+1)
plt.imshow(X_train[n].reshape(28, 28), cmap='Greys', interpolation='nearest')
plt.title('Label : ' + str(y_train[n]))
plt.axis('off')
plt.show()
- 모델 구현
- MNIST 데이터와 동일하게 구성
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(1000, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])- 모델 학습
hist = model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=100, verbose=1)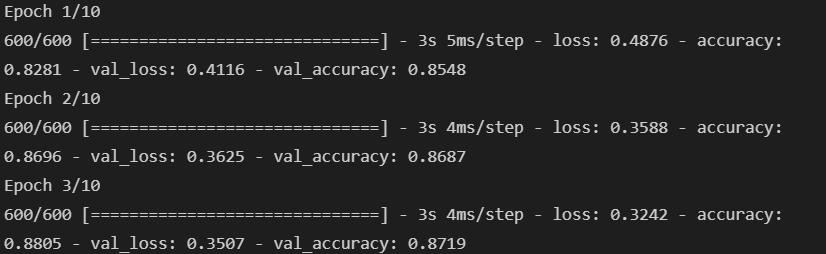
- 모델 결과
- 결과 그리기
import matplotlib.pyplot as plt
plot_target = ['loss', 'val_loss', 'accuracy', 'val_accuracy']
plt.figure(figsize=(12, 8))
for each in plot_target:
plt.plot(hist.history[each], label=each)
plt.legend()
plt.grid()
plt.show()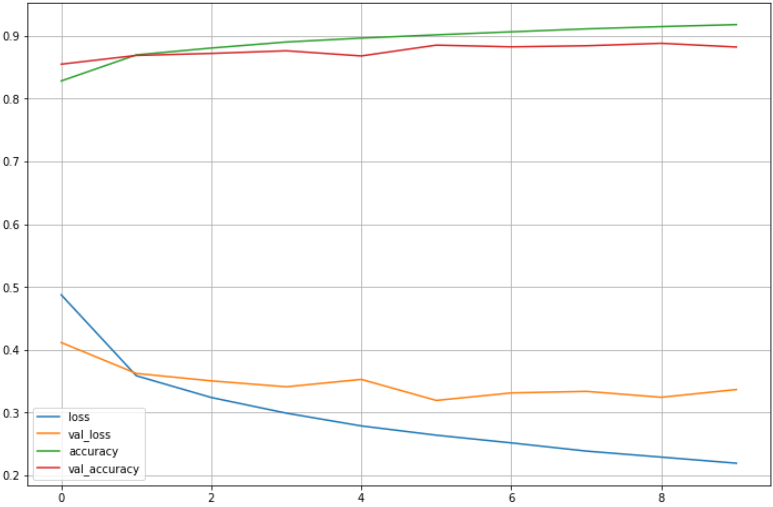
- 결과 확인(evaluate)
score = model.evaluate(X_test, y_test)
print('Test loss : {}'.format(score[0]))
print('Test accuracy : {}'.format(score[1]))
- 잘못 예측한 경우 확인
- 예측 확률이 높은 경우 해당 값을 선택한다.
np.argmax: 각 행(axis=1), 열(axis=0)에서의 최대값의 인덱스를 반환한다.
import numpy as np
predicted_result = model.predict(X_test)
predicted_labels = np.argmax(predicted_result, axis=1)
predicted_labels[:10]
y_test[:10]
- 잘못된 결과 저장
wrong_result = []
for n in range(0, len(y_test)):
if predicted_labels[n] != y_test[n]:
wrong_result.append(n)
len(wrong_result)
- 틀린 예측 중 16개 랜덤 선택
import random
samples = random.choices(population=wrong_result, k = 16)- 선택된 16개의 데이터 그리기
plt.figure(figsize=(14, 12))
for idx, n in enumerate(samples):
plt.subplot(4, 4, idx+1)
plt.imshow(X_test[n].reshape(28, 28), cmap='Greys')
plt.title("Label : " + str(y_test[n]) + ' | Predict : ' + str(predicted_labels[n]))
plt.axis('off')
plt.show()

후라이드 치킨