◾MNIST
- 데이터 읽기
torch.nn as nn: 뉴럴넷 구성 요소torch.nn.functional as F: 딥 러닝에 자주 사용되는 수학적 함수torch.optim as optim: 최적화 함수from torchvision import datasets, transformstorchvision: 딥 러닝에 사용되는 여러 데이터셋에 대한 모듈datasets: 여러 데이터를 가지고 있다.transforms: 데이터의 형태 지정 가능
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import set_matplotlib_korean
from torchvision import datasets, transforms
from matplotlib import pyplot as plt- cuda가 가능하다면 cuda 아니면 cpu 설정
is_cuda = torch.cuda.is_available()
device = torch.device('cuda' if is_cuda else 'cpu')
print('Current cuda device is', device)
- 파라미터 설정
batch_size = 50
learning_rate = 0.0001
epoch_num = 15- MNIST 데이터 불러오기
- datasets를 이용해 MNIST 데이터를 다운로드 한다.
train_data = datasets.MNIST(root = './data/02/',
train=True,
download=True,
transform=transforms.ToTensor())
test_data = datasets.MNIST(root = './data/02/',
train=False,
download=True,
transform=transforms.ToTensor())
print('number of training data : ', len(train_data))
print('number of test data : ', len(test_data))
- 데이터 확인
squeeze(): 차원이 1인 차원을 제거한다.- pytorch에서 불러오는 MNIST 데이터의 경우 [1, 28, 28]로 구성된다.
- 따라서 1을 없애야 이미지를 그릴 수 있다.
image, label = train_data[0]
plt.imshow(image.squeeze().numpy(), cmap='gray')
plt.title('label : %s' % label)
plt.show()
- 미니 배치 구성
torch.utils.data.DataLoader- 배치 사이즈로 구성
- shuffle하는 이유는 데이터의 순서를 학습하지 못하게 하는 것이다.
train_loader = torch.utils.data.DataLoader(dataset=train_data,
batch_size = batch_size, shuffle = True)
test_loader = torch.utils.data.DataLoader(dataset=test_data,
batch_size = batch_size, shuffle = True)
first_batch = train_loader.__iter__().__next__()- batch 확인
print('{:15s} | {:<25s} | {}'.format('name', 'type', 'size'))
print('{:15s} | {:<25s} | {}'.format('Num of Batch', '', len(train_loader)))
print('{:15s} | {:<25s} | {}'.format('first_batch', str(type(first_batch)), len(first_batch)))
print('{:15s} | {:<25s} | {}'.format('first_batch[0]', str(type(first_batch[0])), first_batch[0].shape))
print('{:15s} | {:<25s} | {}'.format('first_batch[1]', str(type(first_batch[1])), first_batch[1].shape))
- 모델 구성
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1, padding='same')
self.conv2 = nn.Conv2d(32, 64, 3, 1, padding='same')
self.dropout = nn.Dropout2d(0.25)
# (입력 뉴런, 출력 뉴런)
self.fc1 = nn.Linear(3136, 1000) # 7 * 7 * 64 = 3136
self.fc2 = nn.Linear(1000, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
model = CNN().to(device)
optimizer = optim.Adam(model.parameters(), lr = learning_rate)
criterion = nn.CrossEntropyLoss()- 모델 학습
model.train()
i = 1
for epoch in range(epoch_num):
for data, target in train_loader:
data = data.to(device)
target = target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if i % 1000 == 0:
print("Train Step : {}\tLoss : {:3f}".format(i, loss.item()))
i += 1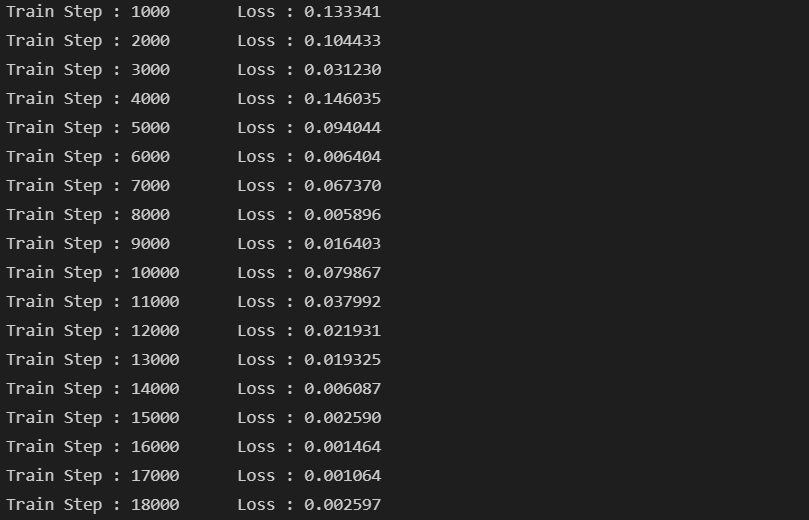
- 모델 평가
model.eval() # 평가시에는 dropout이 OFF 된다.
correct = 0
for data, target in test_loader:
data = data.to(device)
target = target.to(device)
output = model(data)
prediction = output.data.max(1)[1]
correct += prediction.eq(target.data).sum()
print('Test set Accuracy : {:.2f}%'.format(100. * correct / len(test_loader.dataset)))

후라이드 치킨