◾책 추천 시스템
0. 데이터
- goodbooks-10k : Kaggle
1. 유사한 책 찾기
- 데이터 읽기
import pandas as pd
import numpy as np
import warnings; warnings.filterwarnings('ignore')- 책 데이터 읽기
books = pd.read_csv('./data/01/goodbooks-10k/books.csv', encoding='ISO-8859-1')
print(books.shape)
books.head(2)
- 평점 데이터 읽기
ratings = pd.read_csv('./data/01/goodbooks-10k/ratings.csv', encoding='ISO-8859-1')
print(ratings.shape)
ratings.head(2)
- 책 태그 읽기
book_tags = pd.read_csv('./data/01/goodbooks-10k/book_tags.csv', encoding='ISO-8859-1')
print(book_tags.shape)
book_tags.head(2)
- 태그 정보 읽기
tags = pd.read_csv('./data/01/goodbooks-10k/tags.csv')
print(tags.shape)
tags.tail(2)
- book_tags와 tags merge
tags_join_df = pd.merge(book_tags, tags, left_on='tag_id', right_on='tag_id', how='inner')
tags_join_df.head(2)
- 사용자 독서 내역
to_read = pd.read_csv('./data/01/goodbooks-10k/to_read.csv')
print(to_read.shape)
to_read.head(2)
- authors 기준 TfidfVectorize
- 책의 작가 확인
books['authors'][:5]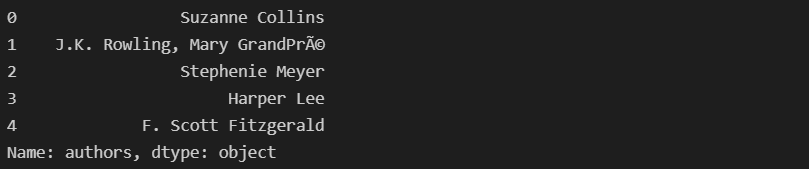
- authors로 Tfidf 수행
from sklearn.feature_extraction.text import TfidfVectorizer
tf = TfidfVectorizer(analyzer='word', ngram_range=(1, 2), min_df=0, stop_words='english')
tfidf_matrix = tf.fit_transform(books['authors'])
tfidf_matrix
- linear_kernel을 통한 유사도 측정
linear_kernel: 코사인 유사도를 구하는 다른 방법
from sklearn.metrics.pairwise import linear_kernel
cosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)
cosine_sim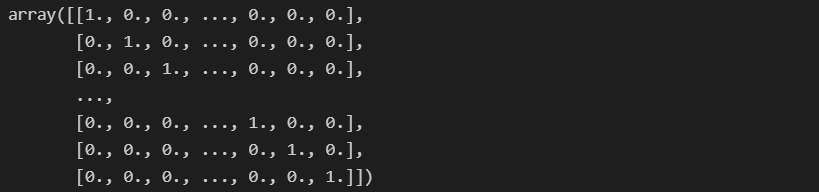
- authors 기준 유사한 책 찾기
- 원하는 책의 인덱스 찾기
titles = books['title']
indices = pd.Series(books.index, index=books['title'])
indices['The Hobbit']
- 해당 책의 유사도 값 호출
cosine_sim[indices['The Hobbit']]
- 가장 유사한 책의 인덱스 찾기
# 유사도 결과 인덱스를 가진 list형으로 변형
sim_scores = list(enumerate(cosine_sim[indices['The Hobbit']]))
sim_scores = sorted(sim_scores, key=lambda x : x[1], reverse=True)
sim_scores[:3]
- 작가로 본 유사책 찾기
sim_scores_10 = sim_scores[1: 11]
book_indices = [i[0] for i in sim_scores_10]
titles.iloc[book_indices]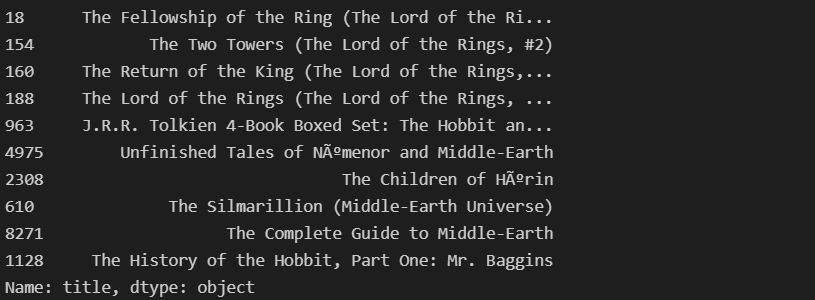
- Tag 추가
books_with_tags = pd.merge(books, tags_join_df, left_on='book_id', right_on='goodreads_book_id', how='inner')
books_with_tags.head(2)
- tag 기준 TfidfVectorize
- tag로 Tfidf 수행
from sklearn.feature_extraction.text import TfidfVectorizer
tf1 = TfidfVectorizer(analyzer='word', ngram_range=(1, 2), min_df=0, stop_words='english')
tfidf_matrix1 = tf1.fit_transform(books_with_tags['tag_name'].head(10000))
tfidf_matrix1
- linear_kernel을 통한 유사도 측정
from sklearn.metrics.pairwise import linear_kernel
cosine_sim1 = linear_kernel(tfidf_matrix1, tfidf_matrix1)
cosine_sim1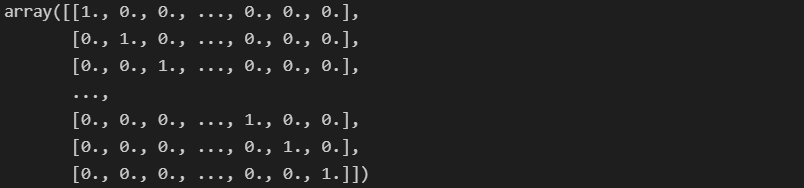
- tag 기준 유사한 책 찾기
- 추천책 반환 함수
titles1 = books['title']
indices1 = pd.Series(books.index, index=books['title'])
def tags_recommendations(title, top_n=10):
idx = indices1[title]
sim_scores = list(enumerate(cosine_sim1[idx]))
sim_scores = sorted(sim_scores, key=lambda x : x[1], reverse=True)
sim_scores = sim_scores[1:top_n+1]
book_indices = [i[0] for i in sim_scores]
return titles1.iloc[book_indices]
tags_recommendations('The Hobbit', 15)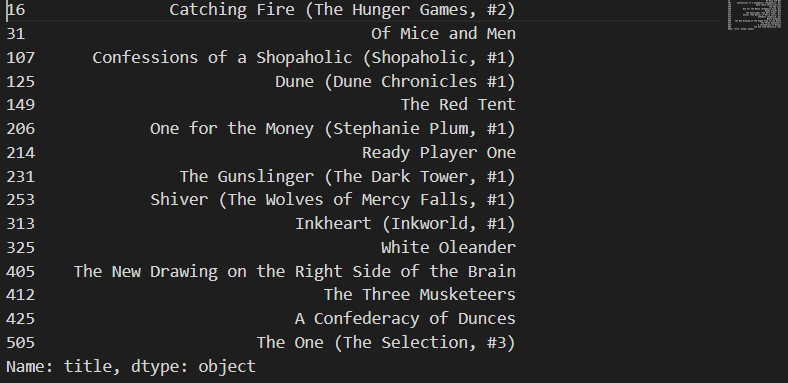
- corpus(author + Tag) 추가
- 각 영화의 태그를 합쳐 문자열로 구성
temp_df = books_with_tags.groupby('book_id')['tag_name'].apply(' '.join).reset_index()
temp_df.head(2)
- books에 merge
books = pd.merge(books, temp_df, left_on='book_id', right_on='book_id', how='inner')
books.head(2)
- 저자 이름과 태그 합치기
books['corpus'] = (pd.Series(books[['authors', 'tag_name']].fillna('').values.tolist())).str.join(' ')
books['corpus'][:3]
- corpus 기준 TfidfVectorize
- corpus로 Tfidf 수행
from sklearn.feature_extraction.text import TfidfVectorizer
tf_corpus = TfidfVectorizer(analyzer='word', ngram_range=(1, 2), min_df=0, stop_words='english')
tfidf_matrix_corpus = tf_corpus.fit_transform(books['corpus'])
cosine_sim_corpus = linear_kernel(tfidf_matrix_corpus, tfidf_matrix_corpus)
titles = books['title']
indices = pd.Series(books.index, index=books['title'])- corpus 기준 유사한 책 찾기
- 추천책 반환 함수
def corpus_recommendations(title, top_n=10):
idx = indices[title]
sim_scores = list(enumerate(cosine_sim_corpus[idx]))
sim_scores = sorted(sim_scores, key=lambda x : x[1], reverse=True)
sim_scores = sim_scores[1:top_n+1]
book_indices = [i[0] for i in sim_scores]
return titles.iloc[book_indices]- 호빗 결과
corpus_recommendations('The Hobbit', 15)
- Twilight 결과
corpus_recommendations('Twilight (Twilight, #1)', 15)

후라이드 치킨