◾딥러닝의 기초
Tensorflow: 머신러닝을 위한 오픈소스 플랫폼, 딥러닝 프레임워크- 구글이 주도적으로 개발하였으며 구글 코랩에서 기본으로 사용가능하다.
- 최근 2.X 버전 발표
- Keras(고수준 API) 병합
- Tensor : 벡터나 행렬
- Graph : 텐서가 흐르는 경로(공간)
- Tensor Flow : 텐서가 Graph를 통해 흐른다.
Neural Net: 신경망에서 아이디어를 얻어서 시작- 뉴련은 입력, 가중치, 활성화함수, 출력으로 구성
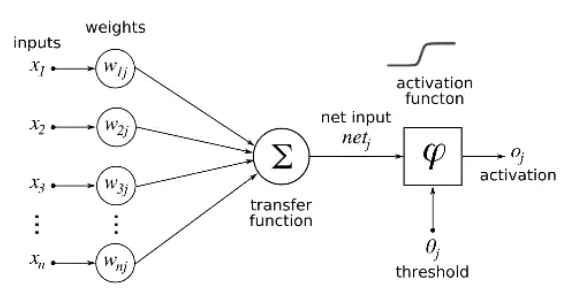
- 뉴런에서 학습할 때 변하는 것은 가중치, 처음에는 초기화를 통해 랜덤값을 넣고 학습과정에서 일정한 값으로 수렴
- 뉴런이 모여서 layer를 구성하고 망(net)이 된다.
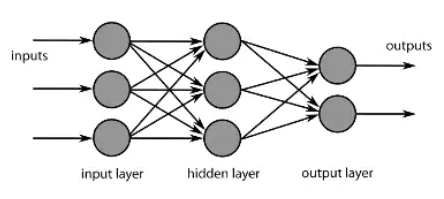
- 계속 층이 쌓여 깊어지면 깊은 신경망 Deep Learning이 된다.
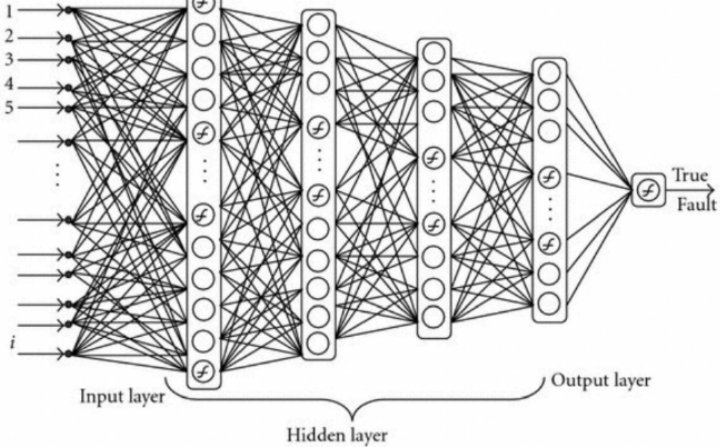
- 뉴련은 입력, 가중치, 활성화함수, 출력으로 구성
◾Blood Fat
- 데이터 읽기
- 몸무게와 나이를 통해 blood fat을 얻는 것이 목표(Linear Regression)
- 결과 :
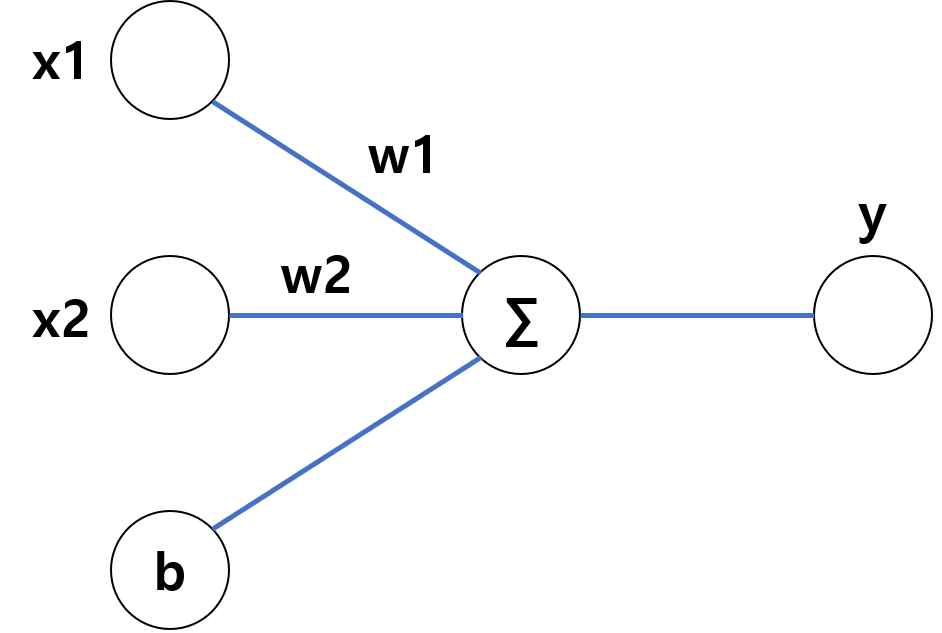
- Age(x1), Weight(x2)를 통해 Blood fat 계산
- x1, x2를 입력해서 y가 나오게 하는 weight와 bias를 구해야한다.
- 컬럼 정보
- 1열 : 인덱스
- 2열 : 구분자
- 3열 : 몸무게
- 4열 : 나이
- 5열 : blood fat
import numpy as np
raw_data = np.genfromtxt('./data/01/x09.txt', skip_header=36)
raw_data
- 3D 시각화
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
import set_matplotlib_korean
xs = np.array(raw_data[:, 2], dtype=np.float32)
ys = np.array(raw_data[:, 3], dtype=np.float32)
zs = np.array(raw_data[:, 4], dtype=np.float32)
fig = plt.figure(figsize=(7, 7))
ax = fig.add_subplot(111, projection='3d')
ax.scatter(xs, ys, zs)
ax.set_xlabel('Weight')
ax.set_ylabel('Age')
ax.set_zlabel('Blood fat')
ax.view_init(15, 15)
plt.show()
- 데이터 정리
x_data = np.array(raw_data[:, 2:4], dtype=np.float32)
y_data = np.array(raw_data[:, 4], dtype=np.float32)
y_data = y_data.reshape((25, 1))- 모델 구현
- 학습을 위해 loss(cost) 함수를 정해주어야 한다.
- loss 함수는 정답까지 얼마나 멀리 있는지를 측정하는 함수
- 이번 모델은 mse:Mean Square Error(오차 제곱 평균) 사용
- Optimizer는 loss를 어떻게 줄일 것인지를 결정하는 방법을 의미한다.
- loss 함수를 최소화하는 가중치를 찾아가는 과정에 대한 알고리즘
- 이번 모델에서는 rmsprop 사용
import tensorflow as tf
model = tf.keras.models.Sequential([
# 출력, 입력 형태를 정해주어야 한다.
# 여러 레이어로 형성가능하며 현재 모델은 1개의 layer가 있다.
tf.keras.layers.Dense(1, input_shape=(2, )),
])
model.compile(optimizer='rmsprop', loss='mse')- summary로 모델 파악
model.summary()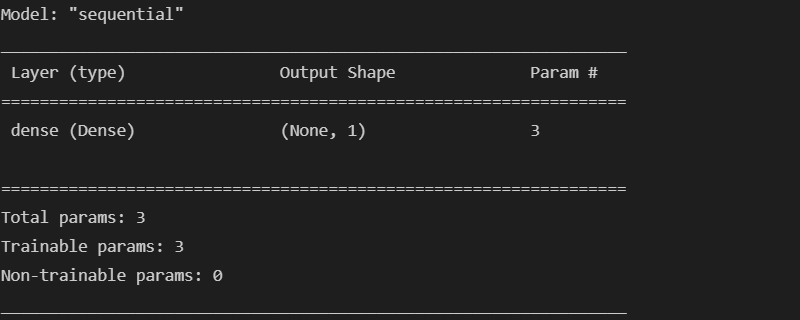
- 모델 학습
- fit을 이용해 학습
# epochs : 학습의 횟수
hist = model.fit(x_data, y_data, epochs=5000)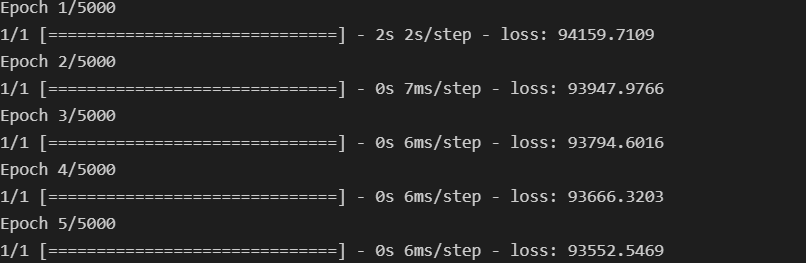
- loss 변화 확인
- 2000 ~ 3000 구간에서 loss의 변화가 크게 없는 것으로 학습 횟수를 변경할 수 있다.
plt.figure(figsize=(7, 5))
plt.plot(hist.history['loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epochs')
plt.show()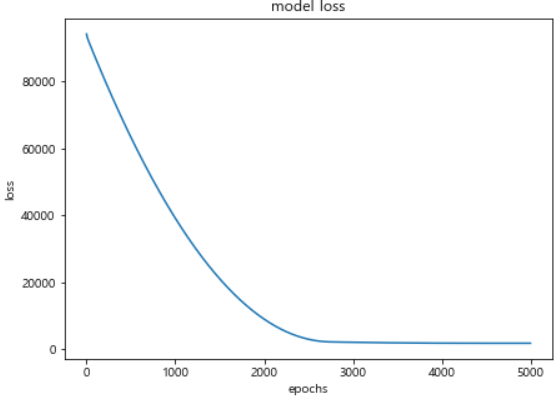
- 예측
- 사용법은 sklearn과 비슷하게
predict를 활용한다.
model.predict(np.array([100, 44]).reshape(1, 2))
model.predict(np.array([60, 25]).reshape(1, 2))
- 가중치와 bias 확인
W_, b_ = model.get_weights()
print('Weight is : ', W_)
print('Bias is : ', b_)
- 모델 확인
- 새로운 데이터로 확인
x = np.linspace(20, 100, 50).reshape(50, 1)
y = np.linspace(10, 70, 50).reshape(50, 1)
X = np.concatenate((x, y), axis=1)
Z = np.matmul(X, W_) + b_- 3D로 표현
fig = plt.figure(figsize=(12, 12))
ax = fig.add_subplot(111, projection='3d')
ax.scatter(xs, ys, zs)
ax.scatter(x, y, Z)
ax.set_xlabel('Weight')
ax.set_ylabel('Age')
ax.set_zlabel('Blood fat')
ax.view_init(15, 15)
plt.show()
◾XOR
- XOR : 참 입력의 개수가 홀수일 때 참 (1/HIGH) 출력을 내보내는 디지털 논리 게이트
- 논리식 :
- 진리표
| 입력 | 출력 | |
|---|---|---|
| A | B | F |
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
- 기호
- 선형 모델로는 XOR 문제를 풀 수 없다.(OR, AND의 경우는 가능하다.)

- 데이터 준비
import numpy as np
X = np.array([[0, 0],
[1, 0],
[0, 1],
[1, 1]])
y = np.array([[0], [1], [1], [0]])- 모델 구현
- 2개의 레이어로 이루어진 모델을 구현한다.

import tensorflow as tf
model = tf.keras.Sequential([
tf.keras.layers.Dense(2, activation='sigmoid', input_shape=(2,)),
tf.keras.layers.Dense(1, activation='sigmoid')
])- 옵티마이저와 학습률 선정
- loss 함수 설정(mse)
# model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.1), loss='mse') : lr 변경
model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=0.1), loss='mse')- model 확인
model.summary()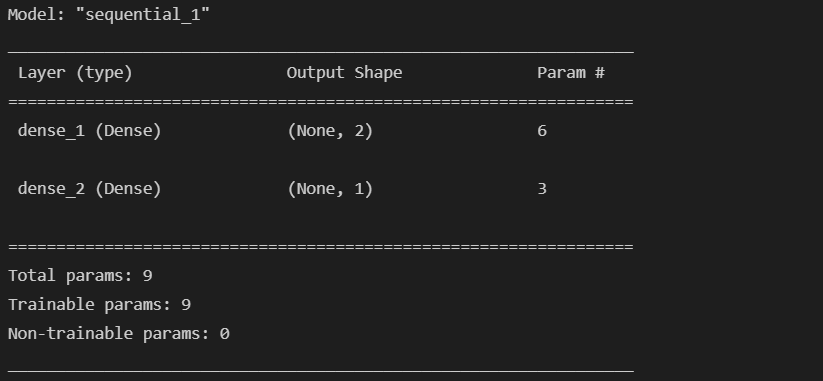
- 모델 학습
epochs: 지정된 횟수만큼 학습을 하는 것batch_size: 한번의 학습에 사용될 데이터의 수
hist = model.fit(X, y, epochs=5000, batch_size=1)
- 학습 결과
- 학습 결과 확인
model.predict(X)
- loss 상황 확인
import matplotlib.pyplot as plt
import set_matplotlib_korean
plt.figure(figsize=(7, 5))
plt.plot(hist.history['loss'])
plt.ylabel('loss')
plt.xlabel('epochs')
plt.show()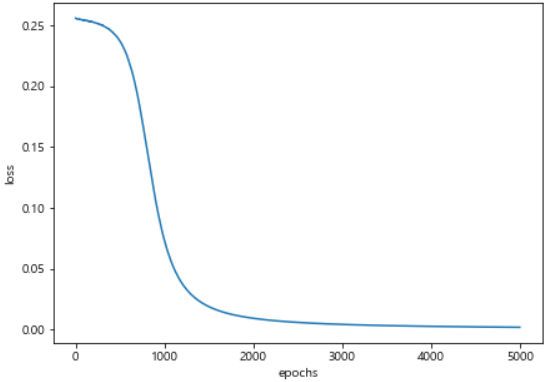
- 가중치 확인
for w in model.weights:
print('---')
print(w)
◾분류 문제
- 데이터 읽기
- iris 데이터 사용
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
X.shape, y.shape
- 데이터 정리
- 수치로 표현된 범주형을 예측하는 경우 편향된 결과를 얻을 수 있다.
- 방지하기 위해 One Hot Encoding을 사용한다.
| id | Color | - | White | Red | Black | Purple | Gold |
|---|---|---|---|---|---|---|---|
| 1 | White | - | 1 | 0 | 0 | 0 | 0 |
| 2 | Red | - | 0 | 1 | 0 | 0 | 0 |
| 3 | Black | - | 0 | 0 | 1 | 0 | 0 |
| 4 | Purple | - | 0 | 0 | 0 | 1 | 0 |
| 5 | Gold | - | 0 | 0 | 0 | 0 | 1 |
- OneHotEncoding 적용
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder(sparse=False, handle_unknown='ignore')
enc.fit(y.reshape(len(y), 1))
enc.categories_
y_onehot = enc.transform(y.reshape(len(y), 1))
y_onehot[:3]
- 데이터 분리
- train_test_split를 통해 데이터 분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y_onehot, test_size=0.2, random_state=13)- 모델 구현
- 32개의 노드가 있는 3개의 layer 3개의 노드가 있는 1개의 layer로 구성
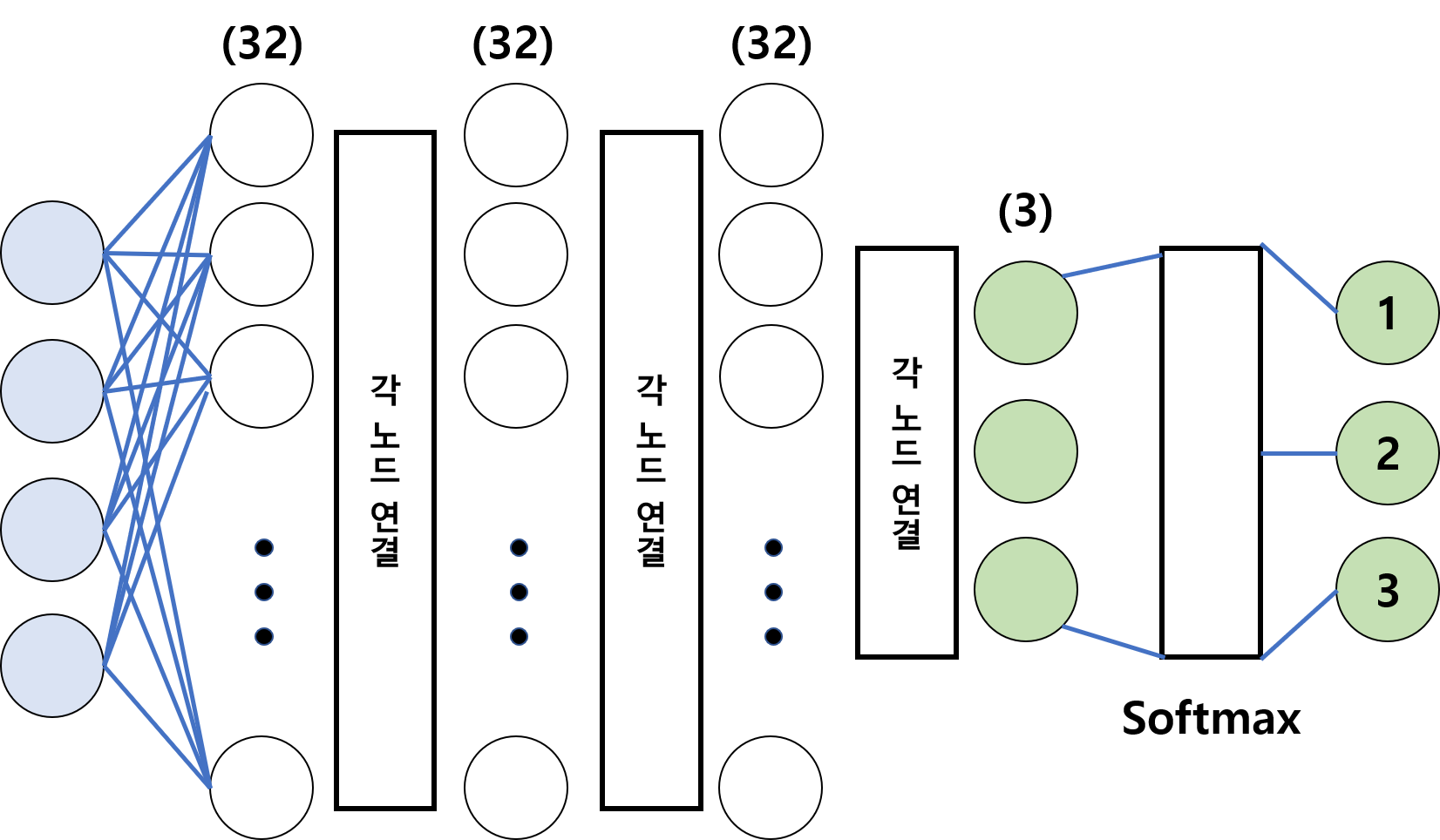
activation: 노드에 입력된 값들을 비선형 함수에 통과시킨 후 다음 레이어로 전달하는데 이 때 사용하는 함수를 말한다.역전파(Back-Propagation): 뉴럴 네트워크의 파라미터들에 대한 그래디언트(gradient)를 계산하는 방법- target과 모델이 계산한 output이 얼마나 차이가 나는지 구한 후 그 오차값을 뒤로 전파해가며 변수들을 갱신한다.
- sigmoid의 경우 역전파에서 발생하는 문제가 있다.
- 특정 부분의 경우 기울기가 0이므로 뒤로 전달할 값이 없게된다.
Gradient Vanishing 현상: 레이어가 깊을 수록 업데이트가 사라지는 현상으로 따라서 fitting이 잘되지 않는다.(underfitting)- 입력에 가까울 수록 학습이 잘 안된다.
ReLU(Rectified Linear Units): 입력값이 0보다 작으면 0으로 출력, 0보다 크면 입력값 그대로 출력하는 유닛이다.

- 에러가 계속 발생하므로 뒤의 경우라도 전달이 잘 된다.
- 따라서 은닉층의 경우 대부분 ReLU를 사용한다.
softmax: 로지스틱 함수의 다차원 일반화로 각 결과의 확률의 합을 1로 유지하고, 가장 값이 큰 것으로 예측한다.
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(32, input_shape=(4, ), activation='relu'),
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dense(3, activation='softmax')
])- 기존 뉴럴넷이 가중치들을 최적화하는 방법
Gradient Decent: loss function의 현 가중치에서의 기울기(gradient)를 구해서 loss를 줄이는 방향으로 업데이트해 나간다.- 뉴럴넷은 loss(or cost) function을 가지고 있다. 거기서 미분하여 에러를 줄이는 방향을 알 수 있다.(현재 기울기 * 반대방향)
- 정해진 스텝량(learning rate)을 곱해서 weight를 이동시킨다.
- 단점 : 모든 데이터를 읽어 최적의 1스텝을 이동한다.
Stochastic Gradient Decent(SGD): 데이터의 일부분(batch)으로 작은 토막마다 1스텝을 진행한다.- 시간이 오래 걸리는 GD보다 SGD를 주로 사용한다.
- SGD의 개선된 다른 optimizer도 많이 존재한다.
- GD : 모든 자료 검토
- SGD : 일부분을 보며 검토 (<- GD)
- Momentum : 스텝 방향 조절, 스텝 계산해서 움직인 후, 이전 관성 방향으로 이동 (<- SGD)
- Adagrad : 스텝 사이즈 조절, 이용하지 않은 것은 빠르게, 이용한 것은 점점 세밀하게 탐색 (<- SGD)
- NAG : 관성 방향으로 움직인 후, 움직인 자리에 스텝을 계산 (<- Momentum)
- AdaDelta : 너무 세밀하게 움직여 정지하는 것 금지 (<- Momentum)
- RMSProp : 스텝 사이즈를 조절하지만 이전 상황도 비교하며 판단 (<- Adagrad)
- Adam : RMSProp + Momentum, 방향, 스텝사이즈 적절히 조절 (<- RMSProp, Momentum)
- Nadam : Adam에 Momentum 대신 NAG 추가 (<- Adam, NAG)
- 현 시점에서는
Adam이 가장 많이 사용된다.
loss : categorical_crossentropy: 다중 분류 손실함수. 출력값이 one-hot encoding 된 결과로 나오고 실측 결과와의 비교시에도 실측 결과는 one-hot encoding 형태로 구성
model.compile(optimizer='adam', loss='categorical_crossentropy',
metrics=['accuracy'])
model.summary()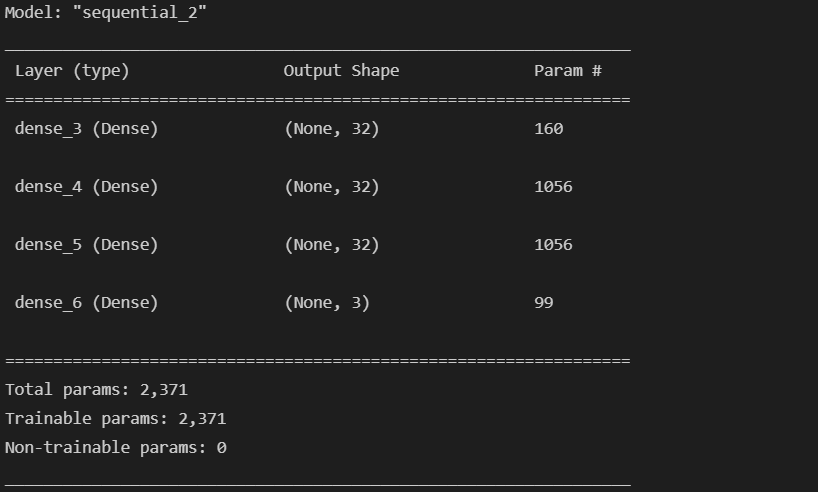
- 모델 학습
hist = model.fit(X_train, y_train, epochs=100)
evaluate: 모델 평가
model.evaluate(X_test, y_test, verbose=1)
- loss 그래프
plt.figure(figsize=(7, 5))
plt.plot(hist.history['loss'], label='loss')
plt.plot(hist.history['accuracy'], label = 'accuracy')
plt.legend()
plt.grid()
plt.show()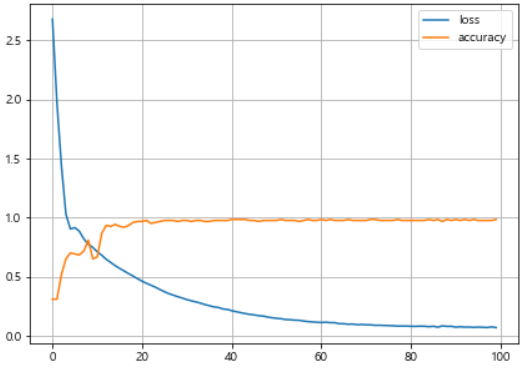

후라이드 치킨