◾KNN
KNN(K Nearest Neighber): 분류나 회귀에 사용되는 비모수 방식- 새로운 데이터가 있을 때, 기존 데이터의 그룹 중 어떤 그룹에 속하는지를 분류하는 문제
- k는 몇 번째 가까운 데이터까지 볼 것인가를 정하는 수치
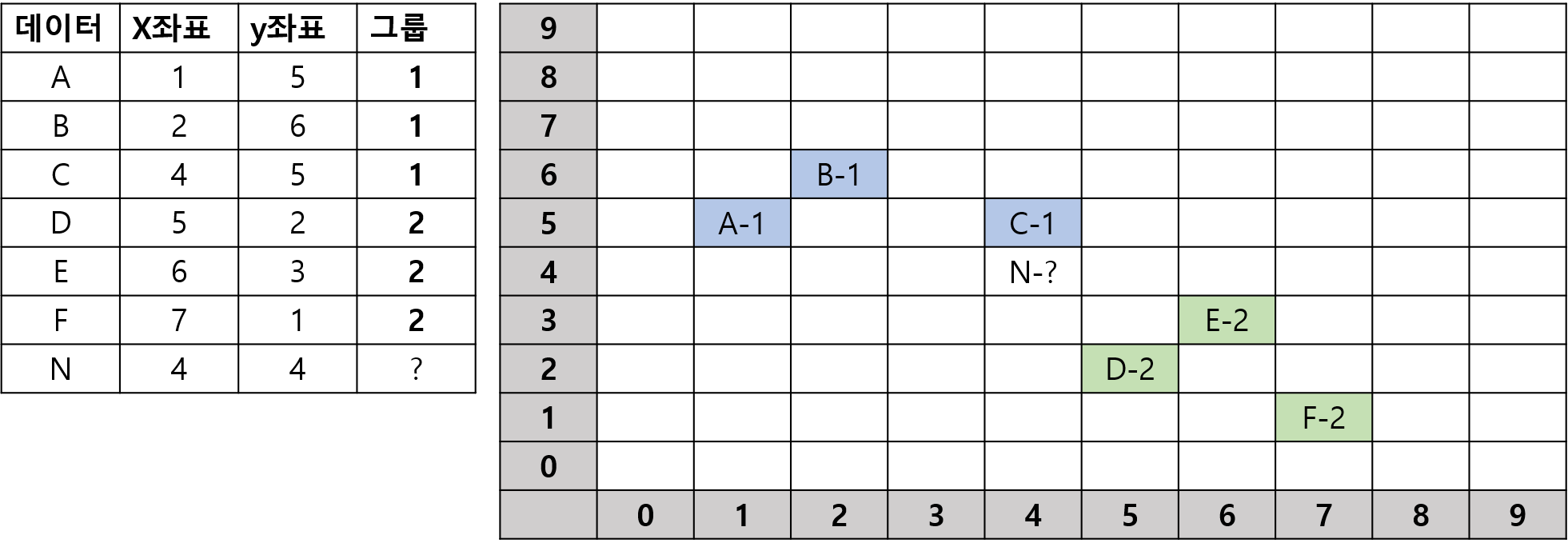
- k에 따라 결과가 바뀐다. 단위에 따라 바뀔 수도 있다.(표준화 작업 필요)
- 거리 계산 : 유클리드 기하학
- 실시간 예측을 위한 학습이 필요하지 않아 속도가 빠르지만 고차원 데이터에는 적합하지 않다.
# iris 데이터
from sklearn.datasets import load_iris
iris = load_iris()from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=13, stratify=iris.target)# kNN 학습
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)# 정확성 확인
from sklearn.metrics import accuracy_score
pred = knn.predict(X_test)
accuracy_score(y_test, pred)
from sklearn.metrics import classification_report, confusion_matrix
print(confusion_matrix(y_test, pred))
print('-'*53)
print(classification_report(y_test, pred))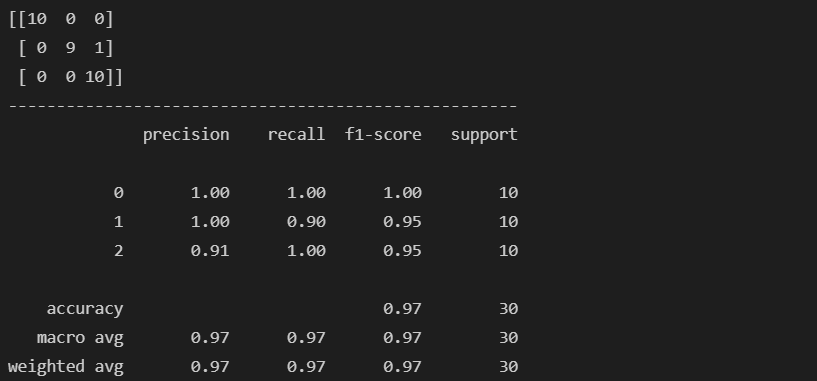

후라이드 치킨