◾HAR USING PCA
- HAR 데이터 읽기
import pandas as pd
feature_name_df = pd.read_csv('UCI_HAR_Dataset/features.txt', sep='\s+', header=None,
names=['column_index', 'column_name'])
feature_name = feature_name_df.iloc[:, 1].values.tolist()
X_train = pd.read_csv('UCI_HAR_Dataset/train/X_train.txt', sep='\s+', header=None)
X_test = pd.read_csv('UCI_HAR_Dataset/test/X_test.txt', sep='\s+', header=None)
X_train.columns = feature_name
X_test.columns = feature_name
y_train = pd.read_csv('UCI_HAR_Dataset/train/y_train.txt', sep='\s+', header=None, names=['action'])
y_test = pd.read_csv('UCI_HAR_Dataset/test/y_test.txt', sep='\s+', header=None, names=['action'])
X_train.shape, X_test.shape, y_train.shape, y_test.shape
- PCA 함수
from sklearn.decomposition import PCA
def get_pca_data(ss_data, n_components=2):
pca = PCA(n_components=n_components)
pca.fit(ss_data)
return pca.transform(ss_data), pca- PCA fit(2개의 주성분)
# pca 결과 저장 함수
def get_pd_from_pca(pca_data, col_num):
cols = ['pca_'+str(n) for n in range(col_num)]
return pd.DataFrame(pca_data, columns=cols)
HAR_pca, pca = get_pca_data(X_train, n_components=2)
HAR_pca.shape
pca.mean_.shape, pca.components_.shape
# 결과 저장
HAR_pd_pca = get_pd_from_pca(HAR_pca, pca.components_.shape[0])
HAR_pd_pca['action'] = y_train
HAR_pd_pca.head()
- PCA 결과 시각화(2개의 주성분)
import numpy as np
def print_variance_ratio(pca):
print('variance_ratio :', pca.explained_variance_ratio_)
print('sum of variance_ratio :', np.sum(pca.explained_variance_ratio_))- 몇 가지 동작은 잘 구분되지만 나머지는 겹쳐있어 구분하기 힘들 것으로 보인다.
import matplotlib.pyplot as plt
import seaborn as sns
sns.pairplot(HAR_pd_pca, hue='action', height=5,
x_vars=['pca_0'], y_vars=['pca_1']);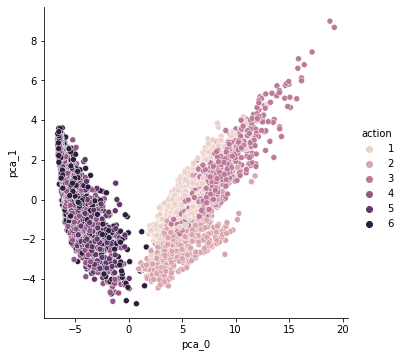
# 500개를 2개로 줄인 것치고는 괜찮은 성능으로 보인다.
print_variance_ratio(pca)
- PCA fit(3개의 주성분)
HAR_pca, pca = get_pca_data(X_train, n_components=3)
HAR_pca.shape
pca.mean_.shape, pca.components_.shape
# 결과 저장
HAR_pd_pca = get_pd_from_pca(HAR_pca, pca.components_.shape[0])
HAR_pd_pca['action'] = y_train
HAR_pd_pca.head()
print_variance_ratio(pca)
- PCA fit(10개의 주성분)
HAR_pca, pca = get_pca_data(X_train, n_components=10)
HAR_pca.shape
pca.mean_.shape, pca.components_.shape
결과 저장
HAR_pd_pca = get_pd_from_pca(HAR_pca, pca.components_.shape[0])
HAR_pd_pca['action'] = y_train
HAR_pd_pca.head()
print_variance_ratio(pca)
- 하이퍼파라미터 튜닝
- RandomForest
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
params = {
'max_depth' : [6, 8, 10],
'n_estimators' : [50, 100, 200],
'min_samples_leaf' : [8, 12],
'min_samples_split': [8, 12]
}
rf_clf = RandomForestClassifier(random_state=13, n_jobs = -1)
grid_cv = GridSearchCV(rf_clf, param_grid=params, cv=2, n_jobs=-1)
grid_cv.fit(HAR_pca, y_train.values.reshape(-1, ))성능 확인
cv_results_df = pd.DataFrame(grid_cv.cv_results_)
target_col = ['rank_test_score', 'mean_test_score', 'param_n_estimators',
'param_max_depth']
cv_results_df[target_col].sort_values('rank_test_score').head()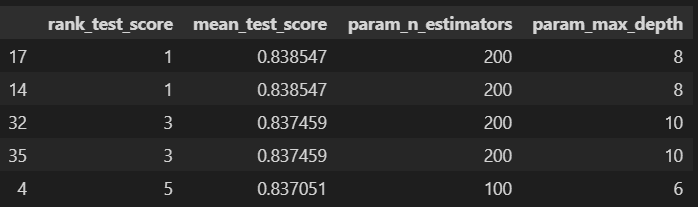
# best 파라미터
grid_cv.best_params_
# best 파라미터
grid_cv.best_estimator_
- 테스트 데이터 적용
from sklearn.metrics import accuracy_score
rf_clf_best = grid_cv.best_estimator_
rf_clf_best.fit(HAR_pca, y_train.values.reshape(-1, ))
pred1 = rf_clf_best.predict(pca.transform(X_test))
accuracy_score(y_test, pred1)
- XGBOOST 테스트
from xgboost import XGBClassifier
evals = [(pca.transform(X_test), y_test)]
xgb = XGBClassifier(n_estimators=400, learning_rate=0.1, max_depth=3)
xgb.fit(HAR_pca, y_train.values.reshape(-1, ),
early_stopping_rounds=10, eval_set=evals)
accuracy_score(y_test, xgb.predict(pca.transform(X_test)))
◾MNIST Data
- NIST 데이터 셋(National Insitute of Standards and Technology)
- 필기체 인식을 위해 수집한 자료들
- MNIST 데이터 셋(Modified National Institue of Standards and Technology)
- NIST 데이터 중 숫자만으로 분류된 데이터
- 28*28 픽셀의 0~9 사이의 숫자 이미지와 레이블로 구성된 데이터
- 60000개의 훈련용 셋과 10000개의 실험용 셋으로 구성
- https://www.kaggle.com/oddrationale/mnist-in-csv
- 데이터 읽기
import pandas as pd
import numpy as np
df_train = pd.read_csv('../data/04/mnist_train.csv')
df_test = pd.read_csv('../data/04/mnist_test.csv')
df_train.shape, df_test.shape
- train, test 데이터 확인
- 785개의 컬럼으로 이루어진 것을 확인
- 28*28 이미지 이므로 784개의 각 픽셀값과 라벨로 이루어져있다.
df_train.head(2)
df_test.head(2)
- 데이터 정리
X_train = np.array(df_train.iloc[:, 1:])
y_train = np.array(df_train['label'])
X_test = np.array(df_test.iloc[:, 1:])
y_test = np.array(df_test['label'])
X_train.shape, y_train.shape, X_test.shape, y_test.shape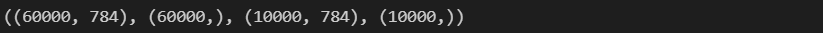
- 데이터 확인
import random
# 16개의 인덱스 선택
samples = random.choices(population=range(0, 60000), k =16)
import matplotlib.pyplot as plt
plt.figure(figsize=(14, 12))
for idx, n in enumerate(samples):
plt.subplot(4, 4, idx+1)
plt.imshow(X_train[n].reshape(28, 28), cmap='Greys', interpolation='nearest')
plt.title(y_train[n])
plt.show()
- kNN 학습 및 예측
from sklearn.neighbors import KNeighborsClassifier
import time
# 최근접 5개의 데이터까지 확인
clf = KNeighborsClassifier(n_neighbors=5)
clf.fit(X_train, y_train)- kNN은 차원이 많을 수록 시간이 오래 걸린다.
%%time
from sklearn.metrics import accuracy_score
pred = clf.predict(X_test)
print('Acc Test : {}'.format(accuracy_score(y_test, pred)))
- kNN With PCA
- PCA를 이용해 차원을 줄여서 kNN을 예측해본다.
- PCA : 2, 5, 10개의 차원으로 축소하여 최고의 분류기를 사용
from sklearn.pipeline import Pipeline
from sklearn.decomposition import PCA
from sklearn.model_selection import GridSearchCV, StratifiedKFold
pipe = Pipeline([
('pca', PCA()),
('clf', KNeighborsClassifier())
])
parameters = {
'pca__n_components' : [2, 5, 10],
'clf__n_neighbors' : [5, 10, 15]
}
# StratifiedKFold 라벨의 비율을 유지하며 교차검증
kf = StratifiedKFold(n_splits=5, shuffle=True, random_state=13)
# verbose = 1간단한 메시지 출력
grid = GridSearchCV(pipe, parameters, cv=kf, n_jobs=-1, verbose=1)
grid.fit(X_train, y_train)- best score 출력
print("Best score : {:.3f}".format(grid.best_score_))
print("Best parameters Set : ")
best_parameters = grid.best_params_
for param_name in sorted(parameters.keys()):
print('\t%s : %r' % (param_name, best_parameters[param_name]))
print('Acc Test : {}'.format(accuracy_score(y_test, grid.best_estimator_.predict(X_test))))
- 결과 확인
from sklearn.metrics import classification_report, confusion_matrix
def results(y_pred, y_test):
print(classification_report(y_test, y_pred))# Train 데이터
results(grid.predict(X_train), y_train)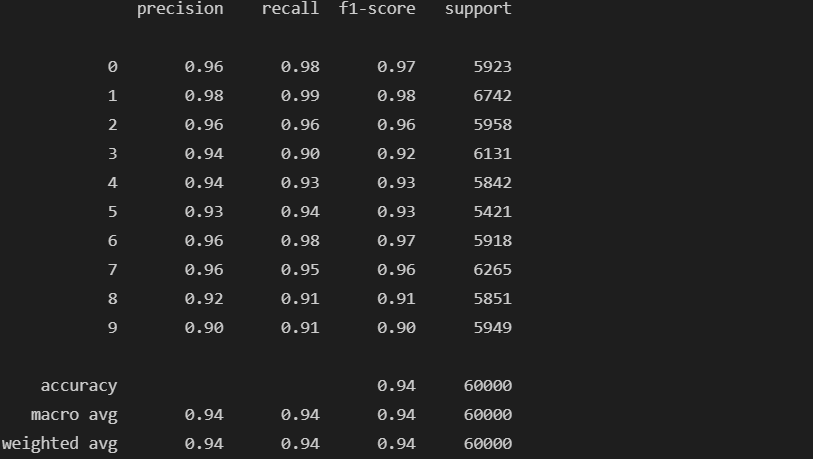
# Test 데이터
results(grid.predict(X_test), y_test)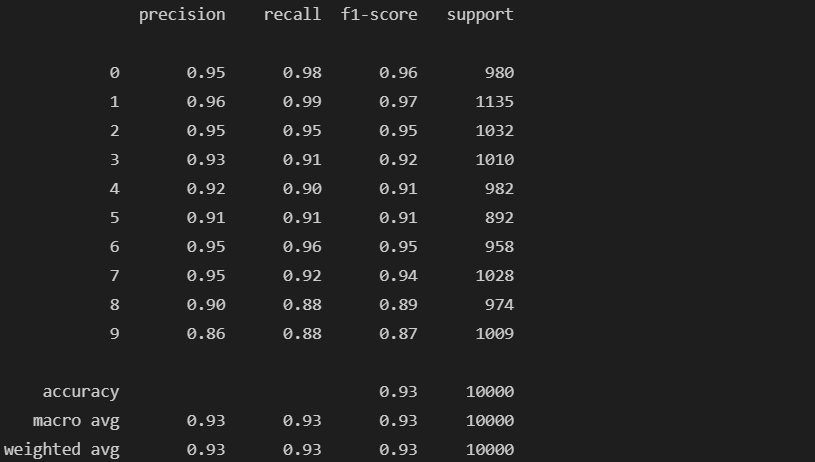
- 숫자 재확인
n = 700
plt.imshow(X_test[n].reshape(28, 28), cmap='Greys', interpolation='nearest')
plt.show()
print("Answer is :", grid.best_estimator_.predict(X_test[n].reshape(1, 784)))
print('Real Label is :', y_test[n])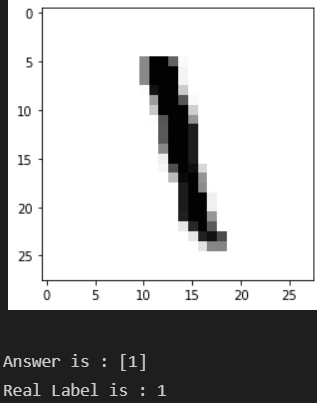
- 틀린 데이터 확인
preds = grid.best_estimator_.predict(X_test)
preds
y_test
wrong_results = X_test[y_test != preds]
samples = random.choices(population=range(0, wrong_results.shape[0]), k=16)
plt.figure(figsize=(14, 12))
for idx, n in enumerate(samples):
plt.subplot(4, 4, idx+1)
plt.imshow(wrong_results[n].reshape(28, 28), cmap='Greys', interpolation='nearest')
pred_digit = grid.best_estimator_.predict(wrong_results[n].reshape(1, 784))
plt.title(str(pred_digit))
plt.show()

후라이드 치킨