◾Boosting Algorithm
Boosting Algorithm: 머신러닝 앙상블 기법 중 하나로 sequential한 weak learner(약한 모델)들을 여러 개 결합하여 예측 혹은 분류 성능을 높이는 알고리즘Boosting: 여러 개의 (약한)분류기가 순차적으로 학습하며, 앞에서 학습한 분류기가 예측이 틀린 데이터에 대해 다음 분류기가 가중치를 인가해서 학습을 이어 진행하는 방식- 예측 성능이 뛰어나서 앙상블 학습을 주도하고 있음
- 그래디언트 부스트, XGBoost(eXtra Gradient Boost), LightGBM(Light Gradient Boost) 등
- Bagging은 한 번에 병렬적으로 결과를 얻는 반면 Boosting은 순차적으로 진행
Adaboost: 순차적으로 가중치를 부여해 최종 결과를 얻는다.(Decision Tree 기반의 알고리즘)- SETP1 : 첫 번째 학습기가 분류 기준으로 분류
- SETP2 : 잘못 분류된 데이터에 가중치 부여
- SETP3 : 두 번째 학습기가 분류 기준으로 분류
- SETP4 : 잘못 분류된 데이터에 가중치 부여
- SETP5 : 세 번째 학습기가 분류 기준으로 분류
- SETP6 : 분류기들을 결합하여 최종 예측 수행
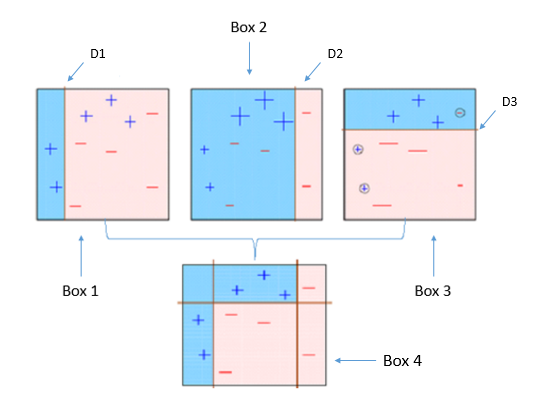
GBM(Gradient Boosting Machine): AdaBoost 기법과 비슷하지만, 가중치를 업데이트할 때 경사하강법(Gradient Descent) 사용XGBoost: GBM에서 PC의 파워를 효율적으로 사용하기 위한 다양한 기법에 채택되어 빠른 속도와 효율을 가짐LightGBM: XGBoost보다 빠른 속도를 가짐
- 와인 데이터를 이용해 실습
# 데이터 읽기
import pandas as pd
wine = pd.read_csv('../data/02/wine.csv', index_col=0)
wine.head()
# taste 추가
wine['taste'] = [1. if grade > 5 else 0. for grade in wine['quality']]
X = wine.drop(['taste', 'quality'], axis=1)
y = wine['taste']# StandardScaler 적용
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_sc = sc.fit_transform(X)# 데이터 나누기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_sc, y, train_size=0.2, random_state=13)# 모든 컬럼 히스토그램
# 잘 분포된 컬럼(정규분포 형태)이 좋을때가 많다.
import matplotlib.pyplot as plt
import set_matplotlib_korean
wine.hist(bins=10, figsize=(15, 10))
plt.show()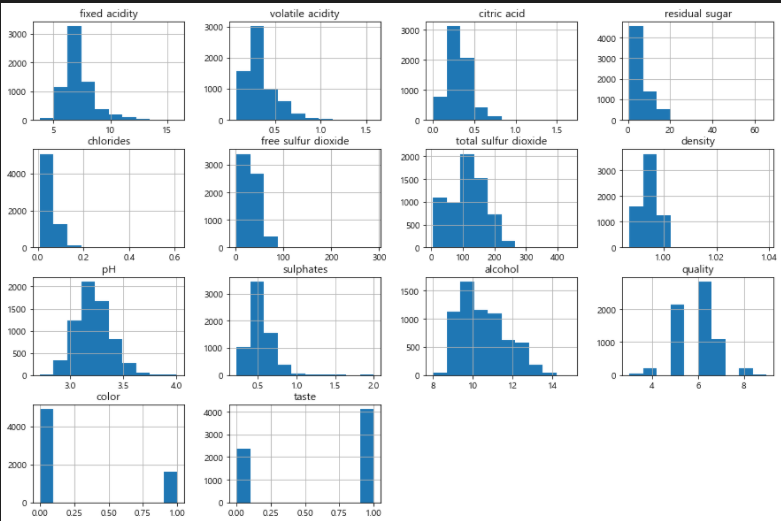
# quality별 특성 확인
column_names = ['fixed acidity', 'volatile acidity', 'citric acid', 'residual sugar',
'chlorides', 'free sulfur dioxide', 'total sulfur dioxide', 'density',
'pH', 'sulphates', 'alcohol']
df_pivot_table = wine.pivot_table(column_names, ['quality'], aggfunc='median')
df_pivot_table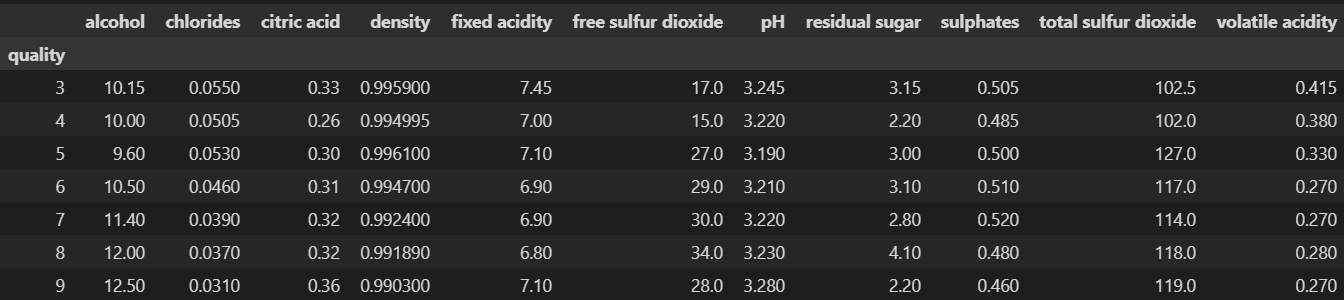
# quality에 대한 나머지 특성들의 상관관계
import seaborn as sns
corr_matrix = wine.corr()
plt.figure(figsize=(12, 7))
sns.heatmap(corr_matrix, fmt='.2f', annot=True, cmap='bwr')
plt.show()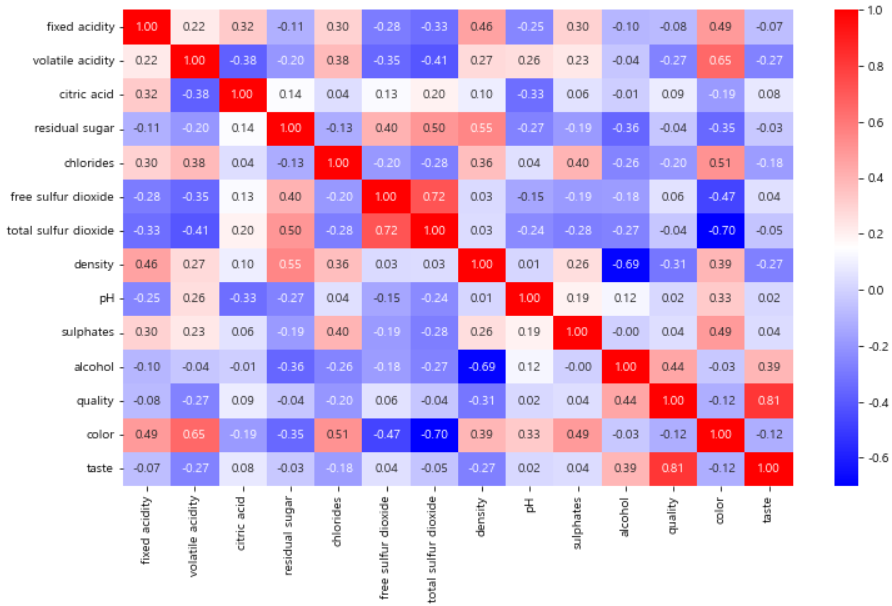
# taste 컬럼의 분포
sns.countplot(x='taste', data=wine)
plt.show()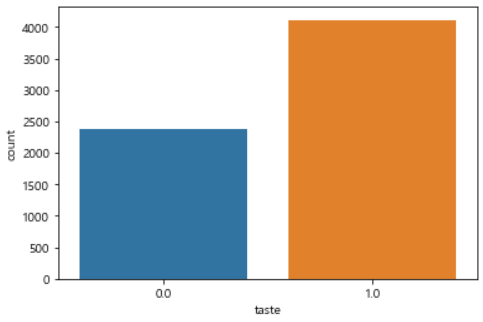
# 다양한 모델 한번에 테스트
from sklearn.ensemble import AdaBoostClassifier, GradientBoostingClassifier, RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
models = []
models.append(('RandomForestClassifier', RandomForestClassifier()))
models.append(('DecisionTreeClassifier', DecisionTreeClassifier()))
models.append(('AdaBoostClassifier', AdaBoostClassifier()))
models.append(('GradientBoostingClassifier', GradientBoostingClassifier()))
models.append(('LogisticRegression', LogisticRegression()))# 결과를 저장하기 위한 작업
from sklearn.model_selection import KFold, cross_val_score
results = []
names = []
for name, model in models:
kfold = KFold(n_splits=5, random_state=13, shuffle=True)
cv_results = cross_val_score(model, X_train, y_train, cv=kfold, scoring='accuracy')
results.append(cv_results)
names.append(name)
print(name, cv_results.mean(), cv_results.std())
# cross-validation 결과 확인
# box plot 사용
fig = plt.figure(figsize=(14, 8))
fig.suptitle('Algorithm Comparision')
ax = fig.add_subplot(111)
plt.boxplot(results)
ax.set_xticklabels(names)
plt.show()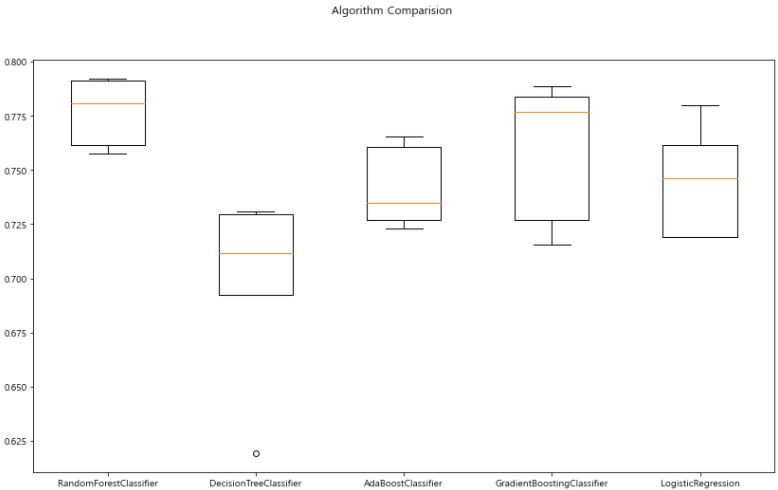
- wine 데이터에 대해서는 RandomForest가 유리해보이는 결과를 얻을 수 있었다.
- 이후로는 GradientBoosting이 높은 값을 보이며 나머지는 대체로 낮은 값을 보인다.
- 테스트 데이터에 대한 평가 결과
from sklearn.metrics import accuracy_score
for name, model in models:
model.fit(X_train, y_train)
pred = model.predict(X_test)
print(name, accuracy_score(y_test, pred))

후라이드 치킨