◾앙상블(Ensemble) 기법
- 집중할 것은 기법이 아닌 데이터!
앙상블(Ensemble): 여러 개의 분류기를 생성하고 그 예측을 결합하여 정확한 최종 예측을 기대하는 기법- 목표 : 다양한 분류기의 예측 결과를 결합함으로써 단일 분류기보다 신뢰성이 높은 예측 값을 얻는것
- 정형 데이터를 대상으로 하는 분류기에서는 앙상블 기법이 뛰어난 성과를 보이고 있다.
- 종류 : Voting, Bagging, Boosting, Stacking
voting 기법: 같은 데이터에 대해 여러 알고리즘을 실행하고 투표를 통해 결과를 도출하는 방법- 데이터 -> (Logistic Regression, Decision Tree, ..., K Nearest Neighbor) -> voting(투표) -> 최종 결정
Hard Voting: 분류 예측 값이 다수인 쪽을 선택하는 방식Soft Voting: 분류 예측 값의 평균을 구해 가장 높은 확률을 선택하는 방식
Bagging 기법: 같은 알고리즘에 대해 샘플을 다양하게 생성하여 결과를 도출- 데이터 -> (샘플1, 샘플2, ..., 샘플N) : (학습, 예측) -> voting(투표) -> 최종 결정
- Decision Tree을 주로 사용
- 데이터 중복을 허용해 샘플링하고 각각의 데이터에 같은 알고리즘을 적용한다.
- 각각의 분류기에 데이터를 각각 샘플링해서 추출하는 방식을
부트스트래핑(bootstrapping) 분할 방식이라 한다. Random Forest: 배깅의 대표적인 방법
- 앙상블 방법 중에서 비교적 속도가 빠르고 다양한 영역에서 높은 성능을 보인다.
- Decision Tree(결정 나무)를 기본으로 결과를 예측하고 Soft Voting으로 최종 예측 결론을 얻는다.
- 위키 백과

◾HAR 데이터
1. HAR 데이터
HAR(Human Activity Recognition): 센서를 이용해 사람의 행동을 인식하는 실험- 스마트폰의 IMU 센서를 활용해 데이터 수집
- 자이로 센서(Gyroscope) : 회전 측정
- 가속도 센서(Accelerometer) : 가속도 측정
- 데이터 : UCI HAR 데이터 셋
- 데이터 정보
- 스마트폰을 장착한 사람의 행동을 관찰한 데이터
- 실험 대상 : 19~48세 연령의 30명의 자원 봉사자 모집하여 수행
- 허리에 스마트폰(Galaxy S2)을 착용하여 50Hz의 주파수로 데이터를 얻음
- 6가지 활동(WALKING, WALKING_UPSTAIRS, WALKING_DOWNSTAIRS, SITTING, STANDING, LAYING) 수행
- 내장된 가속도계와 자이로 스코프를 사용하여 50Hz의 일정한 속도로 3축 선형 가속 및 3축 각속도 캡처
- 데이터를 수동으로 라벨링하기 위해 비디오로 기록
- 획득한 데이터 세트는 무작위로 두 세트로 분할
- 훈련 데이터 생성을 위해 자원 봉사자의 70%가 선택되었고 테스트 데이터는 30% 선정
- 중력 및 신체 운동 성분을 갖는 센서 가속 신호는 버터 워스 저역 통과 필터를 사용하여 신체 가속 및 중력으로 분리
- 중력은 저주파 성분만을 갖는 것으로 가정하고 0.3Hz 차단 주파수를 가진 필터 사용
- 스마트폰을 장착한 사람의 행동을 관찰한 데이터
- 데이터 특성
- 가속도계로부터의 3축 가속도(총 가속도) 및 추정된 신체 가속도
- 자이로 스코프의 3축 각속도
- 시간 및 주파수 영역 변수가 포함된 561기능 벡터
- 활동 라벨
- 실험을 수행한 대상의 식별자
- 시간 영역의 데이터를 직접 사용하는 것은 어렵다.
- 시간 영역 데이터를 머신 러닝에 적용하기 위해 여러 통계적 데이터로 변환
- 시간 영역의 평균, 분산, 피크, 중간값, 주파수 영역의 평균, 분산 등으로 변환한 수치
- 행동 인식 연구
- 센서 신호(Raw Sensor Signal)
- 특징 추출(Feature Extraction)
- 모델 학습(Model Training)
- 행동 추론(Activity Inference)
2. HAR 데이터 Decision Tree 적용
데이터 정리
import pandas as pd
import matplotlib.pyplot as plt
import set_matplotlib_korean# 특성 이름 읽기
feature_name_df = pd.read_csv('../data/02/HAR_Dataset/UCI_HAR_Dataset/features.txt',
sep='\s+', header=None,
names=['column_index', 'column_name'])
feature_name_df.head()
feature_name_df.info()
# feature 이름 추출
feature_name = feature_name_df.iloc[:, 1].values.tolist()
feature_name[:5]
- 대용량 데이터이므로 시간이 조금 소요된다.
- X_train : 31Mb
- X_test : 12Mb
# X 데이터 읽기
X_train = pd.read_csv('../data/02/HAR_Dataset/UCI_HAR_Dataset/train/X_train.txt',
sep='\s+', header=None)
X_test = pd.read_csv('../data/02/HAR_Dataset/UCI_HAR_Dataset/test/X_test.txt',
sep='\s+', header=None)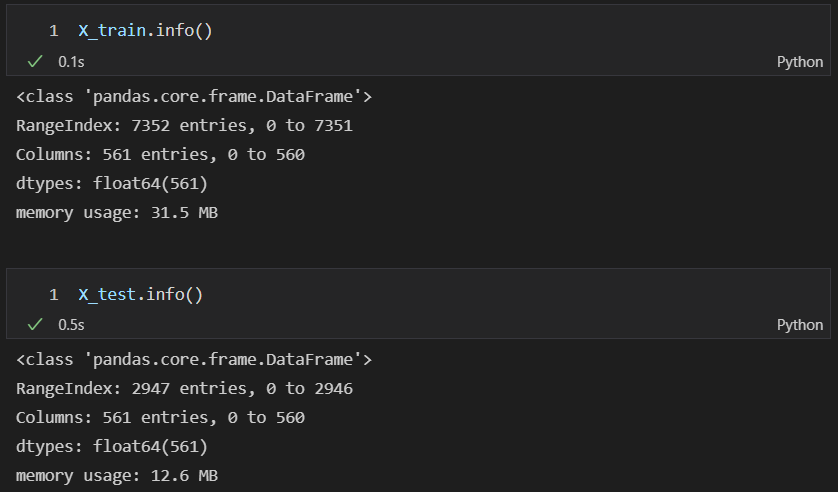
# 컬럼명 변경
X_train.columns = feature_name
X_test.columns = feature_name# Y 데이터 읽기
y_train = pd.read_csv('../data/02/HAR_Dataset/UCI_HAR_Dataset/train/Y_train.txt',
sep='\s+', header=None,
names=['action'])
y_test = pd.read_csv('../data/02/HAR_Dataset/UCI_HAR_Dataset/test/Y_test.txt',
sep='\s+', header=None,
names=['action'])
X_train.shape, X_test.shape, y_test.shape, y_test.shape
- 각 라벨별 정의
- Walking
- WalkingUpstairs
- WalkingDownstairs
- Sitting
- Standing
- Laying
- Imbalanced Data(불균형 데이터)임을 확인
# 라벨의 분포 확인
y_train['action'].value_counts()
결정 나무
# Decision Tree 모델 생성
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
dt_clf = DecisionTreeClassifier(max_depth=4, random_state = 13)
dt_clf.fit(X_train, y_train)
pred = dt_clf.predict(X_test)
accuracy_score(y_test, pred)
GridSearchCV(하이퍼파라미터 튜닝)
# GridSearchCV를 활용해 다양한 조건으로 확인
from sklearn.model_selection import GridSearchCV
params={
'max_depth' : [6, 8, 10, 12, 16, 20, 24]
}
grid_cv = GridSearchCV(dt_clf, param_grid=params, scoring='accuracy',
cv=5, return_train_score=True)
grid_cv.fit(X_train, y_train)# best_score_ 확인
grid_cv.best_score_
# best_params_ 확인
grid_cv.best_params_
- train과 test의 score 차이가 있다. 과적합인지 생각해볼 필요가 있다.
# max_depth 별로 표로 성능 정리
cv_results_df = pd.DataFrame(grid_cv.cv_results_)
cv_results_df[['param_max_depth', 'mean_test_score', 'mean_train_score']]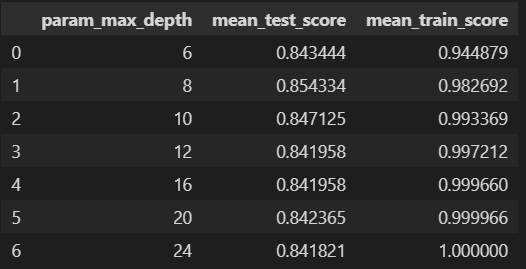
- 검증 결과도
max_depth = 8인 경우가 가장 높다 - Decision Tree에서의 베스트 모델은
Max_depth = 8인 경우이다.
# test 데이터로 검증(validation)
max_depth = [6, 8, 10, 12, 16, 20, 24]
for depth in max_depth:
dt_clf = DecisionTreeClassifier(max_depth = depth, random_state= 13)
dt_clf.fit(X_train, y_train)
pred = dt_clf.predict(X_test)
accuracy = accuracy_score(y_test, pred)
print(f'Max_Depth : {depth}, Accuracy : {accuracy}')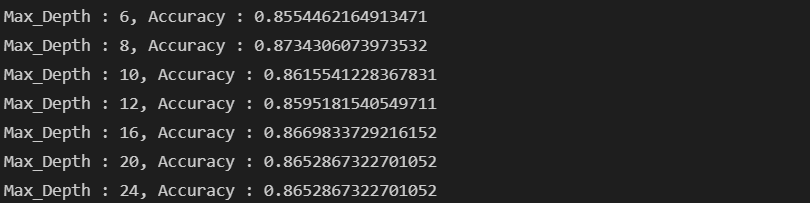
# GridSearchCV 결과 활용
# best_estimator_로 확인
best_dt_clf = grid_cv.best_estimator_
pred_best = best_dt_clf.predict(X_test)
accuracy_score(y_test, pred_best)
3. HAR 데이터 Random Forest 적용
데이터 정리(2번에서 정리한 데이터 사용)
랜덤 포레스트
# 랜덤 포레스트(Random Forest) 적용
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
params = {
'max_depth' : [6, 8, 10], # depth 설정
'n_estimators' : [50, 100, 200], # tree의 개수
'min_samples_leaf' : [8, 12], # 각 결과 데이터의 최소 개수
'min_samples_split' : [8, 12] # 분할의 최소 개수
}
# n_jobs : cpu 코어의 개수
rf_clf = RandomForestClassifier(random_state=13, n_jobs=1)
grid_cv = GridSearchCV(rf_clf, param_grid=params, cv=2, n_jobs=-1)
grid_cv.fit(X_train, y_train)# 결과 정리
cv_results_df = pd.DataFrame(grid_cv.cv_results_)
target_col = ['rank_test_score', 'mean_test_score', 'param_n_estimators', 'param_max_depth']
cv_results_df[target_col].sort_values(by='rank_test_score').head()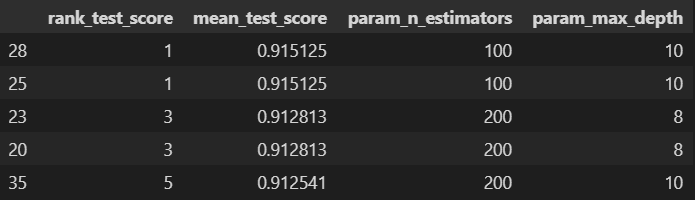
# best 모델 확인
grid_cv.best_params_
# best score 확인
grid_cv.best_score_
# GridSearchCV 결과 활용
# best_estimator_로 확인
best_rf_clf = grid_cv.best_estimator_
pred_best = best_rf_clf.predict(X_test)
accuracy_score(y_test, pred_best)
결과
- Decision Tree에 비해 Random Forest를 사용한 모델이 더 좋은 성능을 기록하였다.
4. HAR 데이터 중요 특성 추출
- 중요 특성 확인
- 상위 8개정도에서 급격히 감소하는 것을 확인할 수 있다.
# 중요 특성 확인
best_cols_values = best_rf_clf.feature_importances_
best_cols = pd.Series(best_cols_values, index=X_train.columns)
top20_cols = best_cols.sort_values(ascending=False)[:20]
top20_cols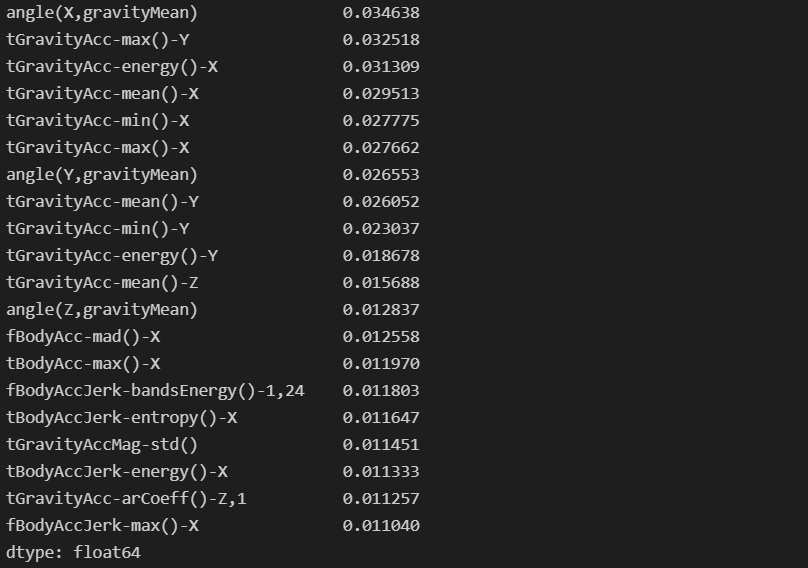
# seaborn을 활용한 시각화
import seaborn as sns
plt.figure(figsize=(8, 8))
sns.barplot(x=top20_cols, y=top20_cols.index)
plt.show()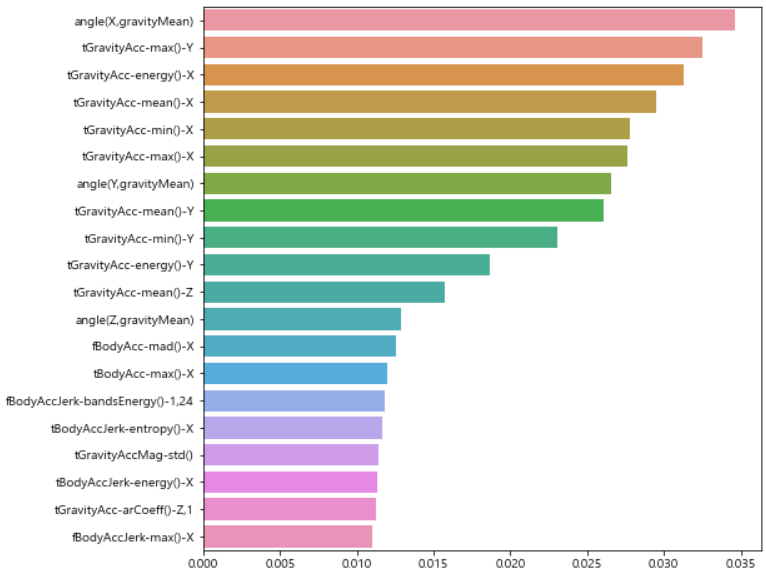
# 20개의 특성을 이용해 다시 성능 확인
# acc는 조금 떨어지더라도 빠른 속도로 계산이 가능하다.
X_train_re = X_train[top20_cols.index]
X_test_re = X_test[top20_cols.index]
best_rf_clf_re = grid_cv.best_estimator_
best_rf_clf_re.fit(X_train_re, y_train.values.reshape(-1,))
pred_re = best_rf_clf_re.predict(X_test_re)
accuracy_score(y_test, pred_re)

후라이드 치킨