✔표준 입출력
- 표준 입출력
- System.in
- System.out
- System.err : 오류를 따로 출력하기 위해서 사용.
- 표준 입출력의 대상 변경
- System.setIn()
- System.setOut()
- System.setErr()
1. Scanner
- java.util.Scanner : 파일, 입력 스트림 등에서 데이터를 읽어 구분자로 토큰화하고 다양한 타입으로 형변환하여 리턴해주는 클래스
- Scanner([File / inputStream / String])
- 입력 스트림 다루는 방법을 몰라도 쉽게 사용 가능.
- 데이터 형 변환으로 인한 편리함
- 대량의 데이터 처리시 수행 시간 비효율적.
- 주요 메소드
- nextInt() : int 타입 반환. White space 문자 만나면 처리.
- nextDouble() : double 타입 반환. White space 문자 만나면 처리.
- next() : 문자열 반환. White space 문자 만나면 처리.
- nextLine() : 문자열 반환. 개행(Enter) 만나면 처리. (next와 달리 space, tab 등의 공백 포함 가능.)
- 기존 입력의 white space가 다음 입력에 영향을 줄 수 있음.
- nextLine은 잔재를 인식하지 않고, 나머지는 잔재를 인식하고 뒤의 유효 문자열만 읽고 반환.
- 따라서, 개행 문자가 남았다면 nextLine()을 하더라도 이후의 문자열이 반환되지 않고 개행 문자만 반환.
String = "123\nhello";
Scanner sc = new Scanner(System.in);
sc.nextIne(); // 123
sc.nextLine(); // \n
sc.nextLine(); // hello2. BufferedReader
- java.io.BufferedReader : 필터 스트림 유형.
- 줄(line)단위로 문자열 처리 기능 제공 : readLine();
- Reader타입만 인자로 받기 때문에 표준 입력(InputStream 계열)을 InputStreamReader를 통해 전달.
- 대량의 데이터 처리시 수행 시간이 효율적임.
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String a = br.readLine();
System.out.println(a);
char[] ch = br.readLine().toCharArray();
for(char c : ch){
System.out.println(c);
}
// StringTokenizer : 문자열 토큰화 클래스. 구분자 기준 문자열 토큰화.
// 기본 구분자 : " "
// 구분자 포함 여부 : false(default)
// ★여러 구분자로 토큰을 생성할 수 있다. (ex) new StringTokenizer("-:")
// ★nextToken의 인자로 다음 구분자를 지정할 수 있음.
StringTokenizer st = new StringTokenizer(br.readLine(), " ");
int i = Integer.parseInt(st.nextInt());
int j = Integer.parseInt(st.nextToken());
System.out.println(i+"//"+j);3. StringBuilder
- java.lang.StringBuilder : 문자열의 조작을 지원하는 클래스
- 자바에서 상수로 취급되는 문자열을 조작시마다 새로운 문자열이 생성되는 것 방지.
- append(String str) : 기존 StringBuilder에 str 문자열 연결
- toString() : StringBuilder의 내용 문자열로 반환.
✔알고리즘
유한한 단계를 통해 문제를 해결하기 위한 절차나 방법. 컴퓨터가 어떤일을 수행하기 위한 단계적 방법
- 고민해야할 문제들
- 문제 해결을 위한 다양한 알고리즘 존재.
- 알고리즘의 성능 분석 필요.
- 알고리즘 문제 해결 과정 : 의사코드와 순서도로 표현하여 1차 검증.
- 문제를 읽고 이해한다.
- 문제를 익숙한 용어로 재정의한다.
- 어떻게 해결할지 계획을 세운다.
- 계획을 검증한다.
- 프로그램으로 구현한다.
- 어떻게 풀었는지 돌아보고, 개선할 방법이 있는지 찾아본다.
- 문제 해결 전략 (체계적인 접근 질문)
- 비슷한 문제가 있었던가?
- 단순한 방법에서 시작할 수 있을까?
- 그림으로 그려볼 수 있을까?
- 수식으로 표현할 수 있을까?
- 문제를 분해할 수 있을까?
- 뒤에서부터 생각해서 문제를 풀 수 있을까?
- 특정 형태의 답만을 고려할 수 있을까?
1. 알고리즘 성능
-
좋은 알고리즘
- 정확성 : 얼마나 정확하게 동작하는가
- 작업량 : 얼마나 적은 연산으로 원하는 결과를 얻어내는가 (1억 연산 -> 1초)
- 메모리 사용량 : 얼마나 적은 메모리를 사용하는가
- 단순성 : 얼마나 단순한가
- 최적성 : 더 이상 개선할 여지없이 최적화되었는가
-
알고리즘 성능
시간 복잡도: 연산의 작업량, 수행 시간- 최선의 경우(Best Case)
- 빅 오메가 표기법 사용(Ω(f(n)))
- 최선의 시나리오로 최소 이만큼의 시간이 걸림을 의미.
- 최악의 경우(Worst Case)
- 빅 오 표기법 사용(Ο(n))
- 최악의 시나리오로 아무리 오래 걸려도 이 시간보다 덜 걸림.
- 평균적인 경우(Average Case)
- 빅 세타 표기법 사용(Θ(n))
- 평균 시간을 나타냄.
- 최선의 경우(Best Case)
공간 복잡도: 메모리 사용량
-
빅-오(O) 표기법
- 위키백과
- 시간 복잡도 함수 중 가장 큰 영향력을 주는 n에 대한 항만 표시
- 계수(Coefficient)는 생략.
- (ex) O(3n + 2) = O(3n) = O(n)
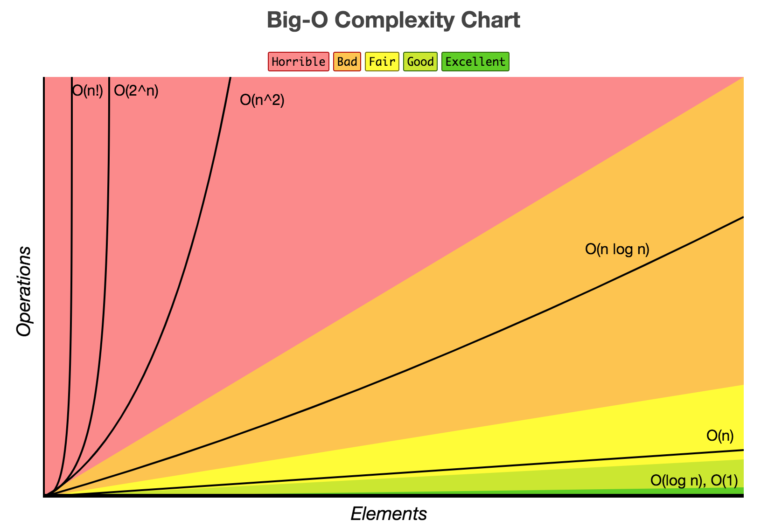
- 시간 복잡도 그래프 : 대부분 효율이 좋은 알고리즘은 nlogn

후라이드 치킨