◼데이터 준비
- 서울시 CCTV 현황 분석(2)와 같이 준비
◼결과 데이터 그래프로 표현
- 표로만 정보를 전달하는 것은 한계가 있다.
- 이를 보완하기 위해
시각화(Visualization)한다. - matplotlib에서 한글 사용을 위해 폰트 변경
import matplotlib.pyplot as plt
from matplotlib import rc
# 마이너스 부호 때문에 한글이 깨질 수 있기 때문에 설정
plt.rcParams["axes.unicode_minus"] = False
rc('font', family='Malgun Gothic')- Pandas DataFrame은 데이터 변수에서 바로 plot() 명령을 사용할 수 있다.
- 데이터(컬럼)이 많은 경우 정렬 후 사용하는 것이 효과적일 때가 많다.
- Bar 그래프 : CCTV 수 활용
- bar : 수직 그래프, barh : 수평 그래프
data_result["소계"].plot(kind="barh", grid=True, figsize=(10,10))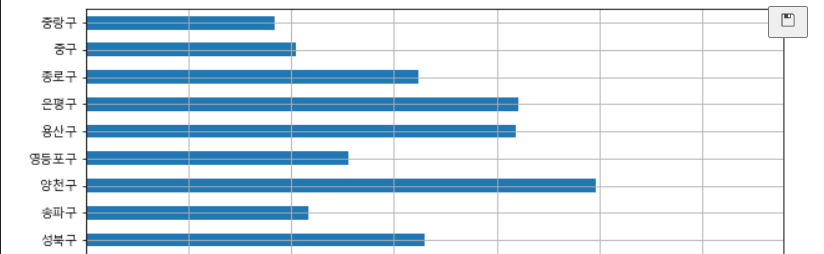
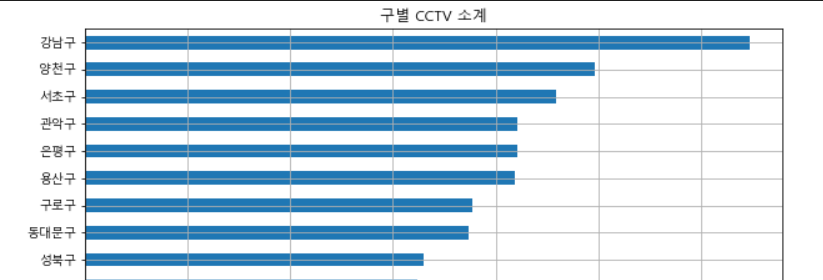
- 정렬 후 사용하여 더 쉽게 정보를 파악할 수 있게 변경
def drawGraph():
data_result["소계"].sort_values().plot(
kind="barh",
grid = True,
title = "구별 CCTV 소계",
figsize=(10,10)
)
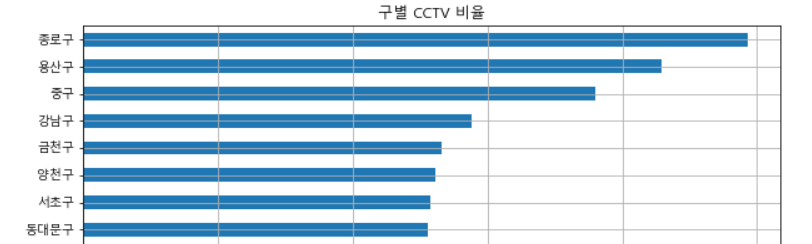
- Bar 그래프 : CCTV 비율 활용
def drawGraph():
data_result["CCTV 비율"].sort_values().plot(
kind = "barh",
grid = True,
title = "구별 CCTV 비율",
figsize=(10, 10)
)
◼데이터 경향
1. 데이터 경향 그리기
- 경향을 파악할 필요
- 단순 CCTV 수와 인구대비 CCTV 비율
- 단순 CCTV 수 : 강남, 양천, 서초, 관악, 은평, 용산
- 인구대비 CCTV 수 : 종로, 용산, 중구
- 전체 경향을 함께 보지 않으면 데이터를 제대로 이해하기 어렵다
- 인구수 대비 CCTV 수를
scatter로 표현
def drawGraph():
plt.figure(figsize=(14, 10))
plt.scatter(data_result["인구수"], data_result["소계"], s=50)
plt.xlabel("인구수")
plt.ylabel("CCTV")
plt.grid()
plt.show()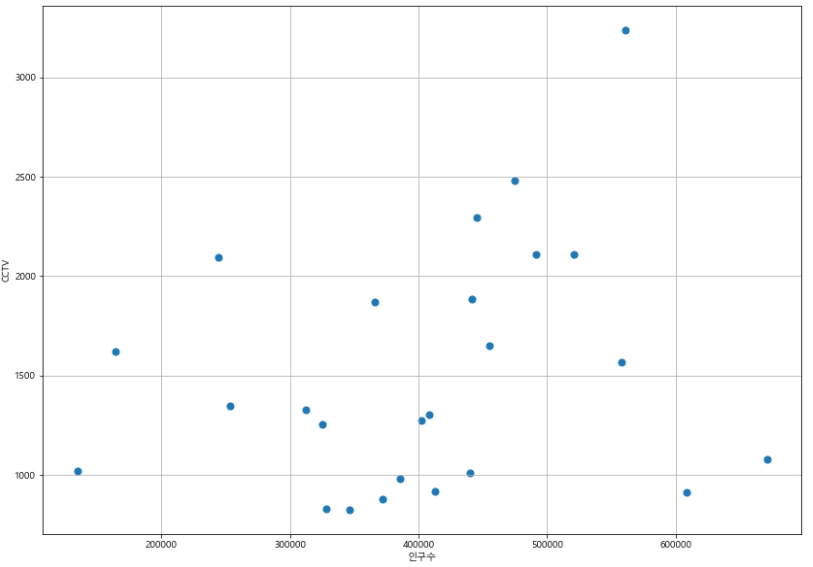
- 데이터 경향 직선으로 표현
- Linear Regression(선형회귀) 이라고도 한다.
- Trend 파악 : Numpy 활용
- Numpy를 이용한 1차 직선 만들기
np.polyfit: 직선을 구성하기 위한 계수 계산np.poly1d: polyfit으로 찾은 계수로 python에서 사용할 함수를 만들어줌
import numpy as np
fp1 = np.polyfit(data_result["인구수"], data_result["소계"], 1)
f1 = np.poly1d(fp1)
# 인구수 40000인 구에서의 CCTV 개수 경향
f1(400000) # 1509.780925 => 인구 40만에 약 1500개의 CCTV의 경향이 있다.- 경향선을 그리기 위해 X 데이터 생성
fx = np.linspace(a, b, n): a부터 b까지 n개의 동간격 데이터 생성
fx = np.linspace(100000, 700000, 100)
def drawGraph():
plt.figure(figsize=(14,10))
plt.scatter(data_result["인구수"], data_result["소계"], s = 50)
plt.plot(fx, f1(fx), ls="dashed", lw=3, color="g")
plt.xlabel("인구수")
plt.ylabel("CCTV")
plt.grid()
plt.show()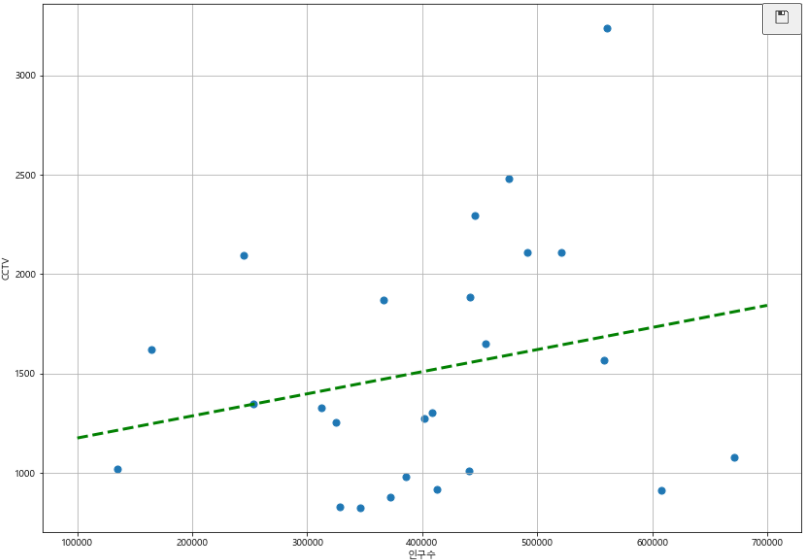
2. 데이터 강조
- 경향과 오차
- 오차 = (CCTV의 수) - 경향선(인구수)
- 경향선을 구하는 함수를 활용해 오차를 구한다.
fp1 = np.polyfit(data_result["인구수"], data_result["소계"], 1)
f1 = np.poly1d(fp1)
fx = np.linspace(100000, 700000, 100)
data_result["오차"] = data_result["소계"] - f1(data_result["인구수"])
# 경향과 비교해서 데이터의 오차가 너무 나는 데이터 계산
df_sort_f = data_result.sort_values(by="오차", ascending=False)
df_sort_t = data_result.sort_values(by="오차", ascending=True)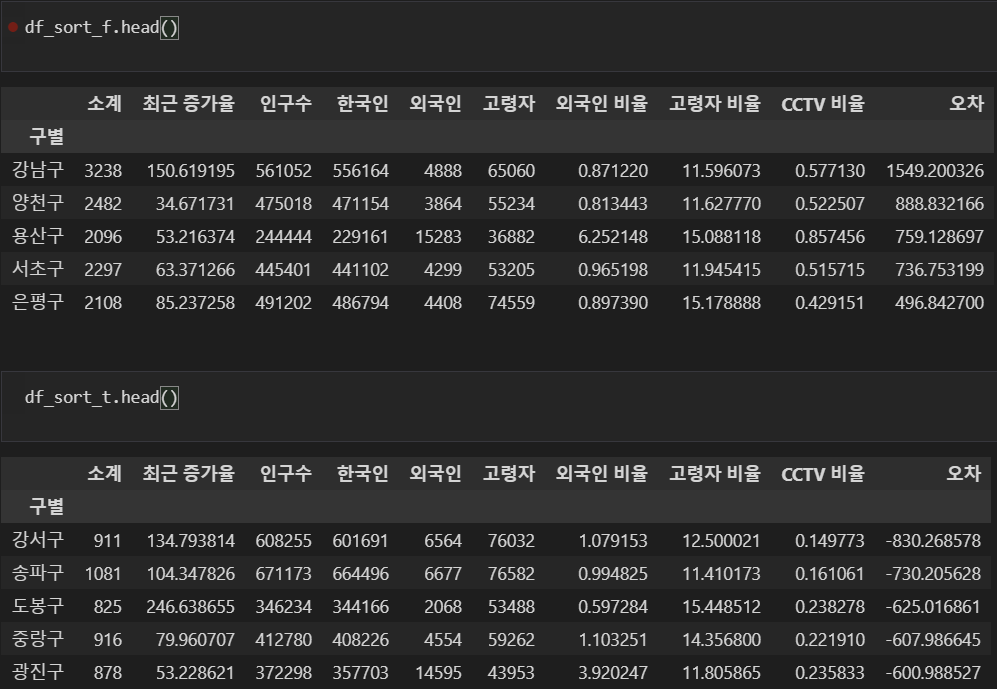
- 강조를 위해
colormap사용자 정의로 설정
from matplotlib.colors import ListedColormap
color_step = ["#e74c3c", "#2ecc71", "#95a5a6", "#2ecc71", "#3498db", "#3498db"]
my_cmap = ListedColormap(color_step)
def drawGraph():
plt.figure(figsize=(14,10))
plt.scatter(data_result["인구수"], data_result["소계"], c=data_result["오차"], s=50, cmap=my_cmap)
plt.plot(fx, f1(fx), ls="dashed", lw=3, color="grey")
for n in range(5):
# 텍스트 출력
# plt.text(a, b, c, d) : x좌표, y좌표, 텍스트, 폰트 사이즈
# 좌표는 원래 좌표에서 살짝 거리를 두어 scatter를 가리지 않게 한다.
plt.text(
df_sort_f["인구수"][n] * 1.02,
df_sort_f["소계"][n] * 0.98,
df_sort_f.index[n],
fontsize=15,
)
plt.text(
df_sort_t["인구수"][n] * 1.02,
df_sort_t["소계"][n] * 0.98,
df_sort_t.index[n],
fontsize=15,
)
plt.xlabel("인구수")
plt.ylabel("CCTV")
plt.colorbar()
plt.grid()
plt.show()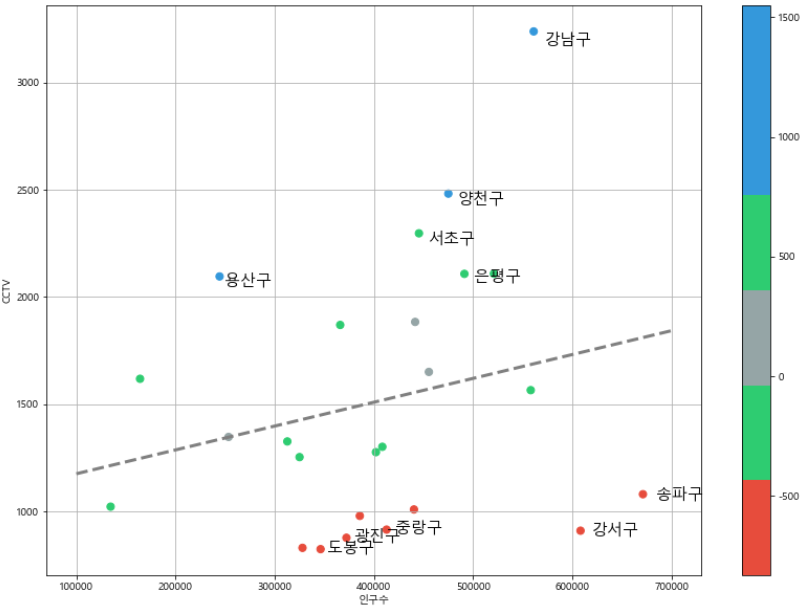
◼완성
- 상관관계를 파악해 인구수 대비 CCTV의 수가 의미있음을 확인
- 인구수 대비 CCTV 수의 비율을 계산해 scaater로 표현
- 경향선을 계산해 각 구별 경향 파악 및 시각화
- 완성한 데이터 저장
to_csv: DataFrame을 csv파일로 저장
data_result.to_csv("../data/01. CCTV_result.csv", sep=',', encoding='utf-8')
후라이드 치킨