◼개요
-
데이터 과학의 목적
- 가정(혹은 인식)을 검증하고 표현하는 것
- 2014-10월 기사 : 서울 강남 3구 체감안전도 높아 => 검증 및 확인
-
활용 :
Googlemaps,Folium,Matplotlib,Seaborn,Pandas,Numpy -
데이터 얻기
- 공공데이터포털
- 서울시 관서별 5대 범죄 현황
- 강의와 똑같은 2016년도 자료 사용
-
데이터 읽기
- numpy, pandas 사용
thousands 옵션: 숫자의 천단위 구분자를 제거하고 숫자형으로 읽는 설정- 숫자에 구분자가 있는 경우 문자로 인식하기 때문에 thousands 옵션 사용
# 데이터 읽기
crime_raw_data = pd.read_csv(
"../data/02. crime_in_Seoul.csv", thousands=',', encoding='euc-kr'
)
# null 데이터 삭제
crime_raw_data = crime_raw_data[crime_raw_data['죄종'].notnull()]
# 데이터 확인
crime_raw_data.head()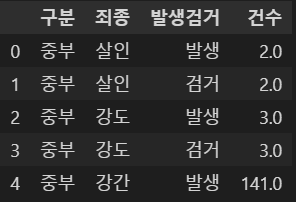
- 사용 모듈 import
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import rc
# 마이너스 부호 때문에 한글이 깨질 수 있기 때문에 설정
plt.rcParams["axes.unicode_minus"] = False
rc('font', family='Malgun Gothic')
%matplotlib inline
import seaborn as sns
import googlemaps
import folium
import json◼서울시 범죄 현황 데이터 정리
Pivot_table
pivot_table: index, columns, values, aggfunc 등의 옵션으로 데이터 정리, 재정렬index: 원하는 기준 선택columns: 원하는 열 선택values: 원하는 출력 선택aggfunc: 중복값을 처리할 방법 선택으로 다중 선택도 가능, 기본값평균-np.meannp.sum,np.mean,len등
fill_value: NaN 데이터 처리margins: 합계 지정(aggfunc에 따라 각 행을 계산)
데이터 정리
- pivot_table을 활용해 데이터 정리
- index : 경찰서 이름
- aggfunc : 합
- multi column 문제 발생
crime_station = crime_raw_data.pivot_table(
crime_raw_data,
index=['구분'],
columns=['죄종', '발생검거'],
aggfunc=[np.sum]
)
crime_station.head()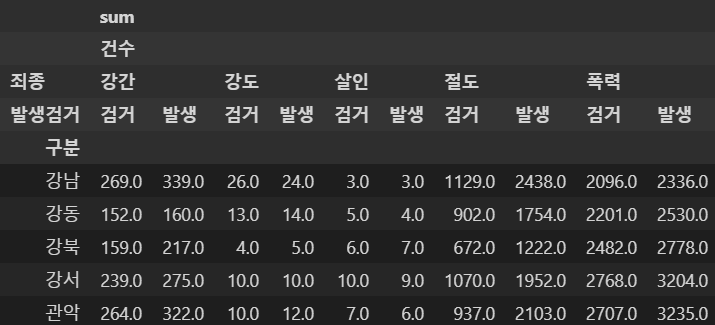
droplevel: 다중 컬럼에서 특정 컬럼 제거
crime_station.columns = crime_station.columns.droplevel([0, 1])
crime_station.head()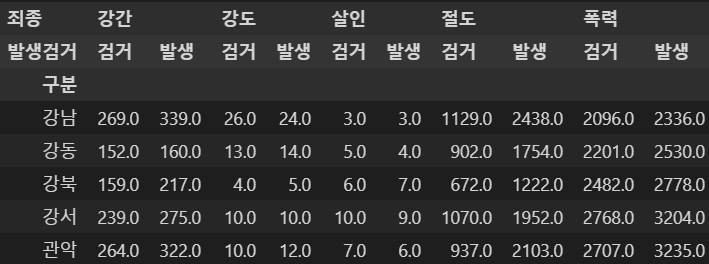
◼구글 maps 구별 정보 정리
Pandas 반복문
iterrow(): pandas에 맞춰진 반복문용 명령- 인덱스와 내용으로 나누어 받는 것 주의
google maps 사용
- 개인키를 사용하여 google maps API 사용
gmaps_key = '개인키'
gmaps = googlemaps.Client(key=gmaps_key)
# 테스트
test = gmaps.geocode("서울영등포경찰서", language='ko')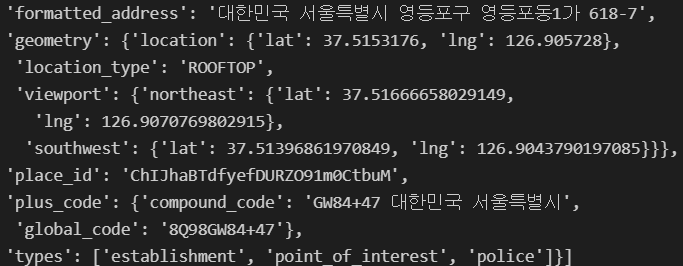
- 결과가
list형이므로 인덱스로 접근하며 내부는dict형이므로 get으로 접근
# 위도
print(test[0].get("geometry")["location"]["lat"])
# 경도
print(test[0].get("geometry")["location"]["lng"])
# 주소
print(test[0].get("formatted_address"))
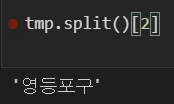
- 주소에서
split을 통해 구를 확인할 수 있다.
- 구이름, 위도, 경도 추가
crime_station["구별"] = np.nan
crime_station["lat"] = np.nan
crime_station["lng"] = np.nan
crime_station.head()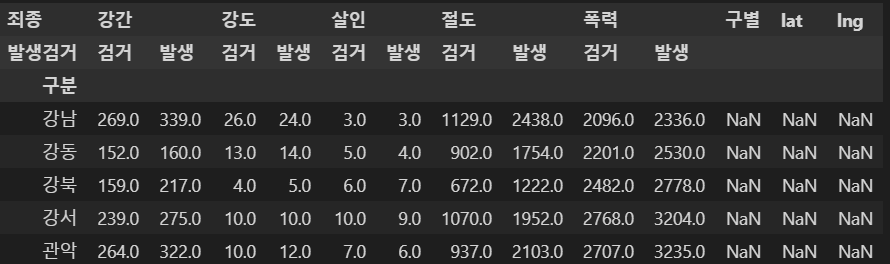
- 반복을 통해 정보 추가
for idx, rows in crime_station.iterrows():
station_name = "서울" + str(idx) + "경찰서"
tmp = gmaps.geocode(station_name, language='ko')
tmp_gu = tmp[0].get("formatted_address")
lat = tmp[0].get('geometry')["location"]["lat"]
lng = tmp[0].get('geometry')["location"]["lng"]
crime_station.loc[idx, "lat"] = lat
crime_station.loc[idx, "lng"] = lng
crime_station.loc[idx, "구별"] = tmp_gu.split()[2]
crime_station.head()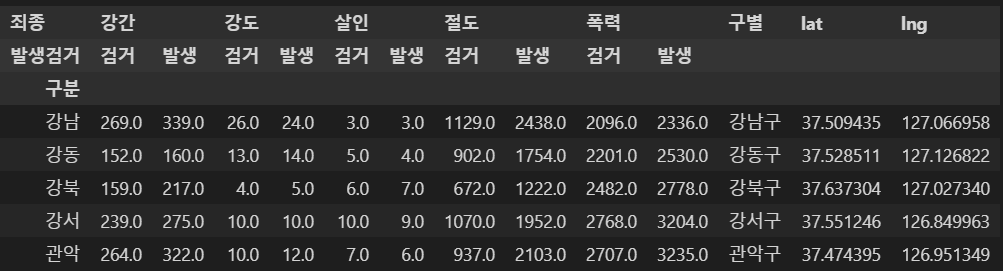
- 다중컬럼 합치기
get_level_values(N): 각 레벨의 컬럼명 추출
# 레벨0, 레벨1의 컬럼명을 합쳐 컬럼명 변경
tmp = [
crime_station.columns.get_level_values(0)[n]
+ crime_station.columns.get_level_values(1)[n]
for n in range(0, len(crime_station.columns.get_level_values(0)))
]
crime_station.columns = tmp
crime_station.head()
- 중간 데이터 저장
crime_station.to_csv("../data/02. crime_in_Seoul_raw.csv", sep=',', encoding='utf-8')◼구별 데이터로 변경
- 경찰서별로 정리되어 있으므로 구별로 재정렬
- 서울은 구별로 경찰서가 2 곳인 곳이 있다.
- pivot_table 활용
crime_anal_station = pd.read_csv(
"../data/02. crime_in_Seoul_raw.csv", index_col = 0, encoding='utf-8')
crime_anal_gu = pd.pivot_table(crime_anal_station, index='구별', aggfunc=np.sum)
# 위도와 경도를 필요없으므로 삭제
del crime_anal_gu["lat"]
del crime_anal_gu["lng"]
# crime_anal_gu.drop("lng", axis=1, inplace=True)
crime_anal_gu.head()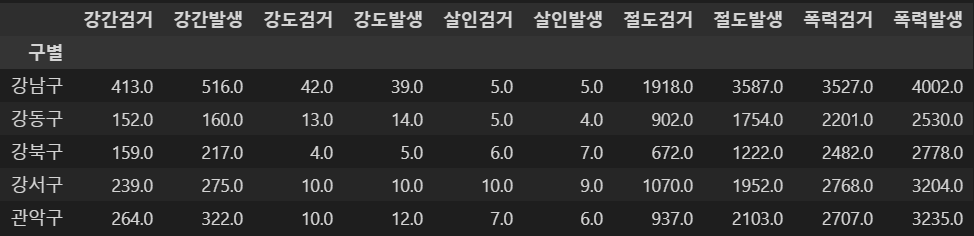
- 검거율 추가
target = ["강간검거율", "강도검거율", "살인검거율", "절도검거율", "폭력검거율"]
num = ["강간검거", "강도검거", "살인검거", "절도검거", "폭력검거"]
den = ["강간발생", "강도발생", "살인발생", "절도발생", "폭력발생"]
crime_anal_gu[target] = crime_anal_gu[num].div(crime_anal_gu[den].values) * 100
crime_anal_gu.head()
- 검거 컬럼 삭제
del crime_anal_gu["강간검거"]
del crime_anal_gu["강도검거"]
del crime_anal_gu["살인검거"]
del crime_anal_gu["절도검거"]
del crime_anal_gu["폭력검거"]
crime_anal_gu.head()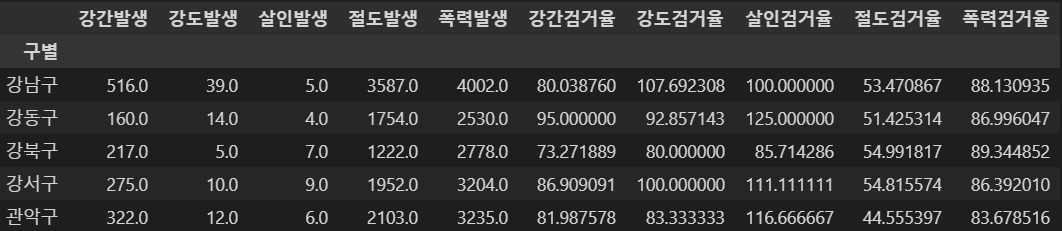
- 검거의 경우 작년 발생 범죄의 검거도 이루어지므로 검거율이 100을 넘을 수 있다.
- 시각화시 문제가 될 수 있으므로 100이상의 수치는 100으로 조정한다.
crime_anal_gu[crime_anal_gu[target] > 100] = 100
crime_anal_gu.head()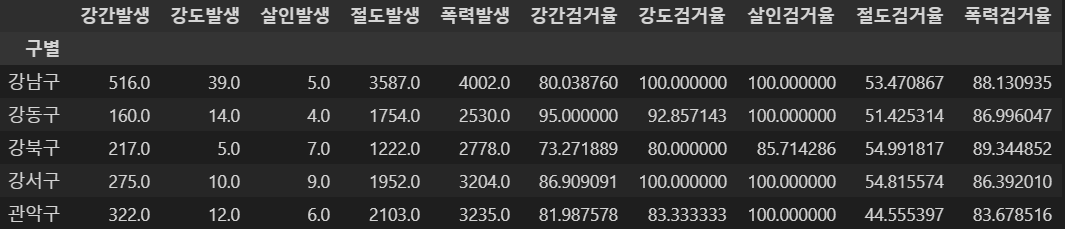
- 검거 컬럼이 삭제되어 '발생'이라 표시할 필요가 없으므로 컬럼명 변경
crime_anal_gu.rename(
columns={"강간발생" : "강간", "강도발생" : "강도", "살인발생" : "살인", "절도발생" : "절도", "폭력발생" : "폭력"},
inplace=True
)
crime_anal_gu.head()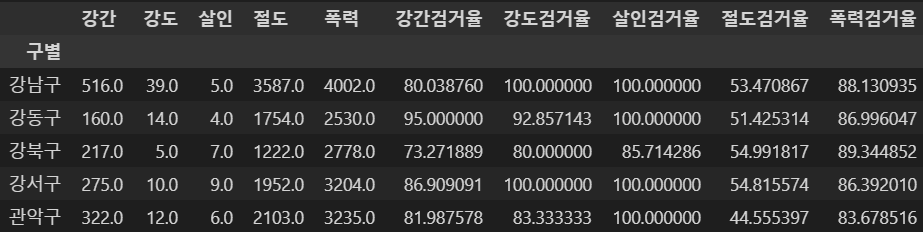
- 중간 데이터 저장
crime_anal_gu.to_csv("../data/02. crime_in_Seoul_gu.csv", sep=',', encoding='utf-8')◼서울시 범죄 현황 데이터 최종 정리
- 각 범죄 발생이 상이하므로 시각화시 문제가될 수 있다.
정규화를 통해 0 ~ 1의 값으로 정리한다.- 각 값을 해당 열의 최대값으로 나누어 준다.
crime_anal_gu = pd.read_csv("../data/02. crime_in_Seoul_gu.csv", encoding='utf-8', index_col='구별')
col = ["살인", "강도", "강간", "절도", "폭력"]
col2 = ["강간검거율", "강도검거율", "살인검거율", "절도검거율", "폭력검거율"]
# 각 값을 최대값으로 나누어 저장
crime_anal_norm = crime_anal_gu[col] / crime_anal_gu[col].max()
crime_anal_norm[col2] = crime_anal_gu[col2]
crime_anal_norm.head()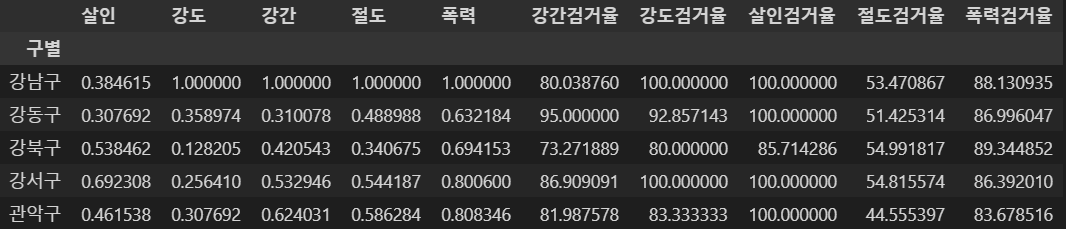
- 이전 프로젝트에서 CCTV수와 인구수 추출하여 추가
result_CCTV = pd.read_csv(
"../data/01. CCTV_result.csv", encoding="utf-8", index_col="구별"
)
crime_anal_norm[["인구수", "CCTV"]] = result_CCTV[["인구수", "소계"]]
crime_anal_norm.head()
- 범죄 발생과 검거율의 평균
범죄: 해당 행의 각 범죄 값의 평균검거: 해당 행의 각 검거율의 평균np.mean: 평균을 구하는 함수, axis에 따라 행(1), 열(0)로 계산- pandas와 달리 numpy의 axis는 0이 열 1이 행
col = ["강간", "강도", "살인", "절도", "폭력"]
crime_anal_norm["범죄"] = np.mean(crime_anal_norm[col], axis=1)
col2 = ["강간검거율", "강도검거율", "살인검거율", "절도검거율", "폭력검거율"]
crime_anal_norm["검거"] = np.mean(crime_anal_norm[col2], axis=1)
crime_anal_norm.head()
- 최종 데이터 저장
crime_anal_norm.to_csv(
"../data/02. crime_in_Seoul_final.csv", sep=',', encoding="utf-8")◼범죄 현황 데이터 시각화
Seaborn
seaborn: 시각화 라이브러리- matplotlib을 기반으로 동작한다.
- 기본 설정
set_style(): white, dark, whitegrid, darkgrid, ticksdespine(): 그래프의 왼쪽과 아래쪽만 선을 그리는 스타일- offset : x축, y축 사이의 거리 조절
1. BoxPlot
boxplot: 0분위(0%), 1분위(25%), 2분위(50%), 3분위(75%), 4분위(100%)의 값을 박스 형태로 표현
# seaborn의 실습용 데이터
tips = sns.load_dataset("tips")
plt.figure(figsize=(8,6))
sns.boxplot(x=tips["total_bill"])
plt.show()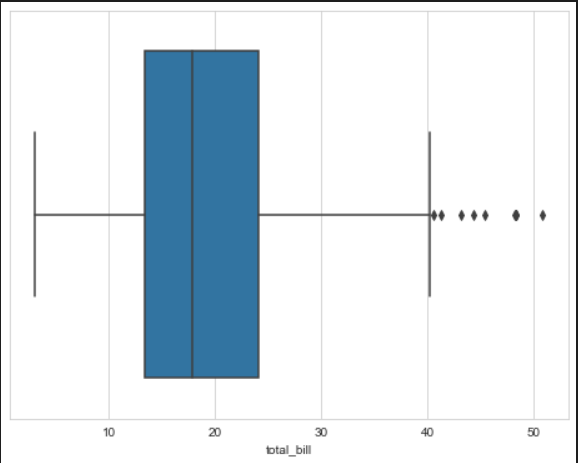
- 컬럼 지정
x: x축 지정y: y축 지정data: 데이터 지정hue: 값을 구분할 기준palette: seaborn이 제공하는 색상 선택(Set1~3)
plt.figure(figsize=(8, 6))
sns.boxplot(x="day", y ="total_bill", hue="smoker", data=tips, palette="Set3")
plt.show()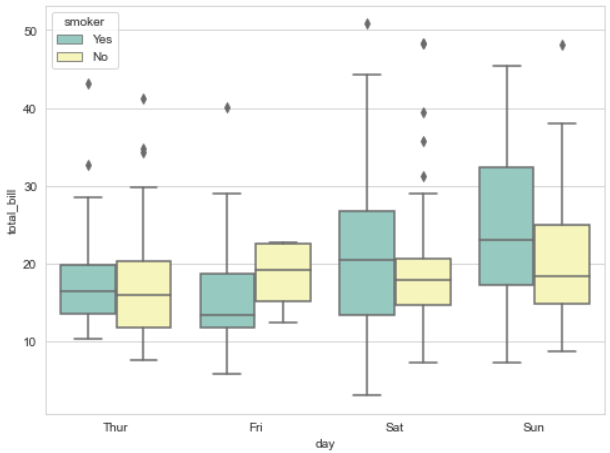
2. SwarmPlot
swarmplot: 범주별 분포를 그리며 데이터의 분산까지 고려하여, 데이터 포인트가 서로 중복되지 않도록 그린다. 즉, 데이터가 퍼져 있는 정도를 입체적으로 볼 수 있다.
plt.figure(figsize=(8, 6))
# color : 0 ~ 1(검정색 ~ 흰색)
sns.swarmplot(x="day", y ="total_bill", data=tips, color="0.5")
plt.show()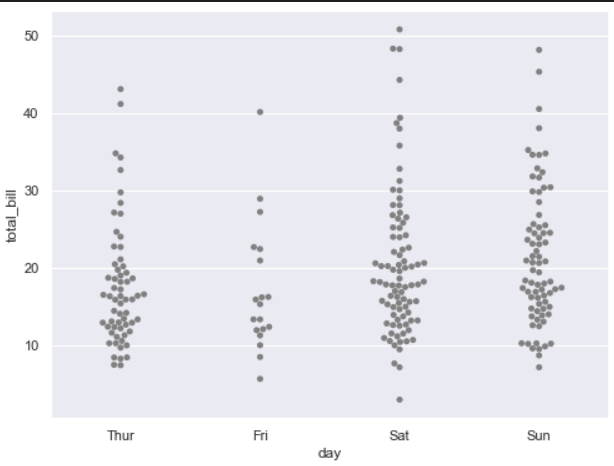
3. LmPlot
lmplot: 각 데이터의 분포와 회귀선을 그린다.
sns.set_style("darkgrid")
sns.lmplot(x="total_bill", y="tip", hue='smoker', data=tips, height=7)
plt.show()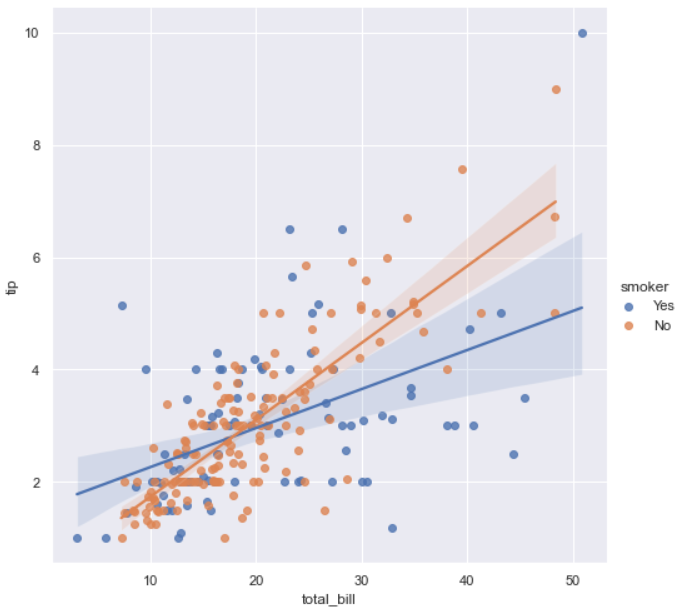
4. HeatMap
- 데이터 정리
flights = sns.load_dataset("flights")
flights = flights.pivot(index="month", columns="year", values="passengers")heatmap: 열분포 형태와 같은 시각화 도구- annot : 값 표시 True, 값 미표시 False
- fmt : 자료형 결정(d - 정수, f - 실수)
- cmap : 컬러맵 설정
plt.figure(figsize=(10, 8))
sns.heatmap(flights, annot=True, fmt="d", cmap="YlGnBu")
plt.show()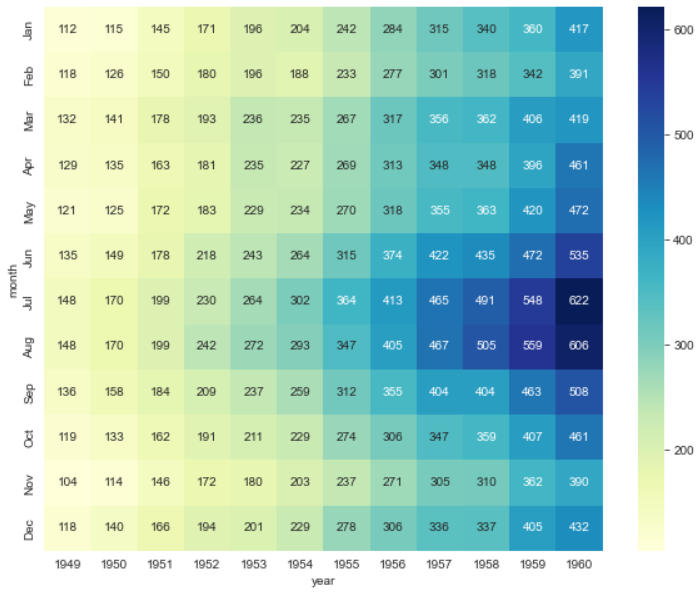
5. PairPlot
- iris 데이터
sns.set(style="ticks")
iris = sns.load_dataset("iris")pairplot: 다수의 컬럼을 비교하여 그래프로 시각화
sns.pairplot(iris, hue="species")
plt.show()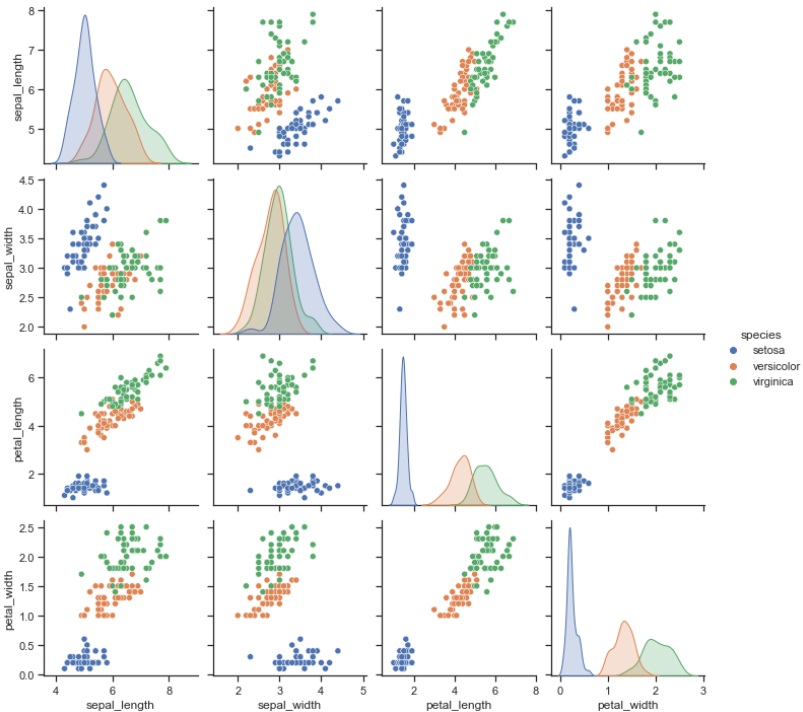
- 원하는 컬럼만 비교
- x_var : x축으로 사용할 컬럼
- y_var : y축으로 사용할 컬럼
sns.pairplot(
iris,
x_vars=["sepal_width", "sepal_length"],
y_vars=["petal_width", "petal_length"],
hue = 'species'
)
plt.show()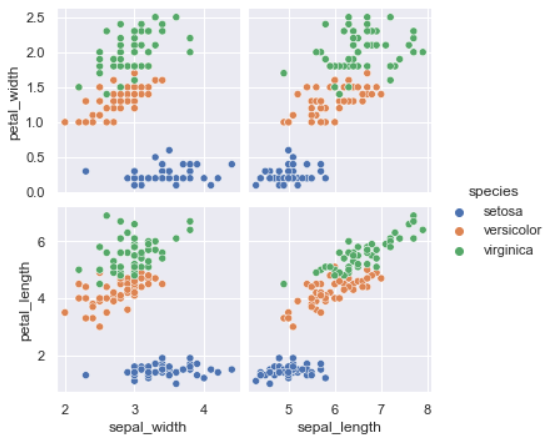
데이터 시각화
- 데이터
crime_anal_norm = pd.read_csv("../data/02. crime_inSeoul_final.csv", encoding='utf-8', index_col='구별')1. pairplot을 활용한 상관관계 파악
- 강도, 살인, 폭력
- 살인과 폭력 사이의 관계 파악
sns.pairplot(crime_anal_norm, vars=["강도","살인","폭력"], kind="reg", height=3)
plt.show()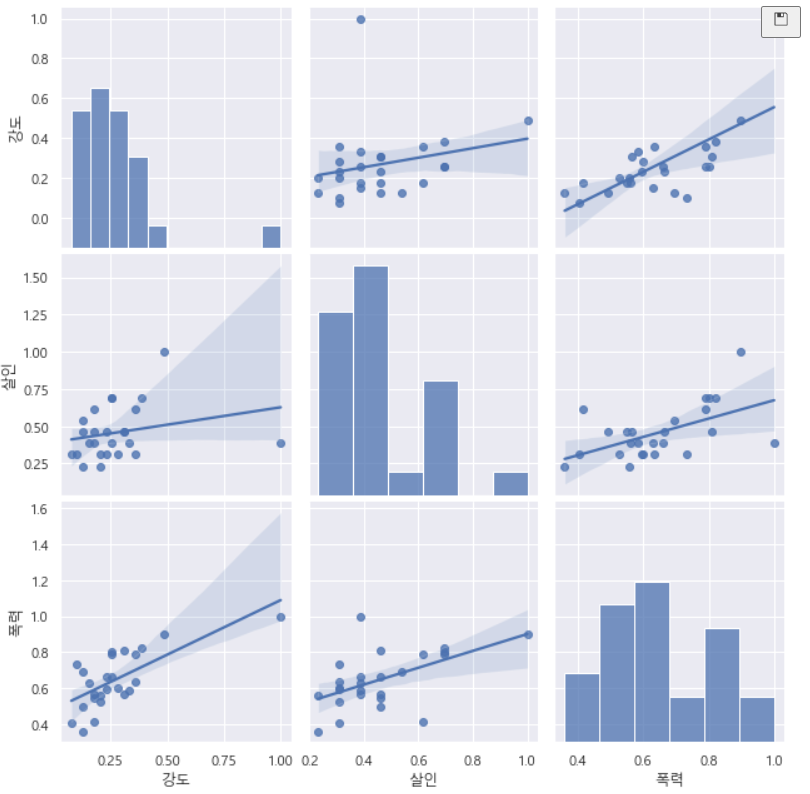
- (인구수, CCTV)와 (살인, 강도)
- 인구수가 증가한다고 강도, 살인이 증가한다고 볼 수 없다
- 강도 사건이 많이 발생하여 CCTV가 증가한 것으로 볼 수 있다.
sns.pairplot(
crime_anal_norm,
x_vars=["인구수","CCTV"],
y_vars=["살인", "강도"],
kind="reg",
height=4)
plt.show()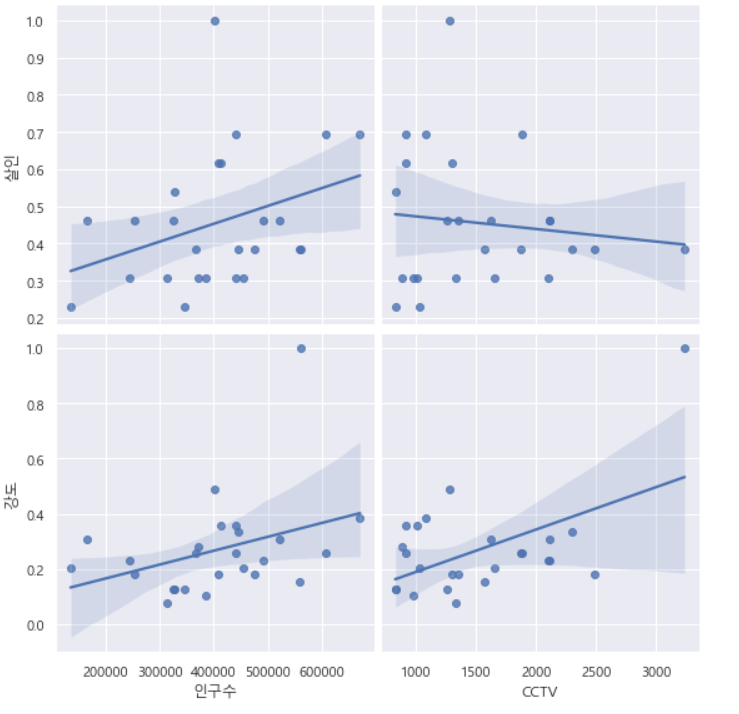
- (인구수, CCTV)와 (살인검거율, 폭력검거율)
- 인구수가 증가할 수록 폭력 검거율이 떨어진다.
sns.pairplot(
crime_anal_norm,
x_vars=["인구수","CCTV"],
y_vars=["살인검거율", "폭력검거율"],
kind="reg",
height=4)
plt.show()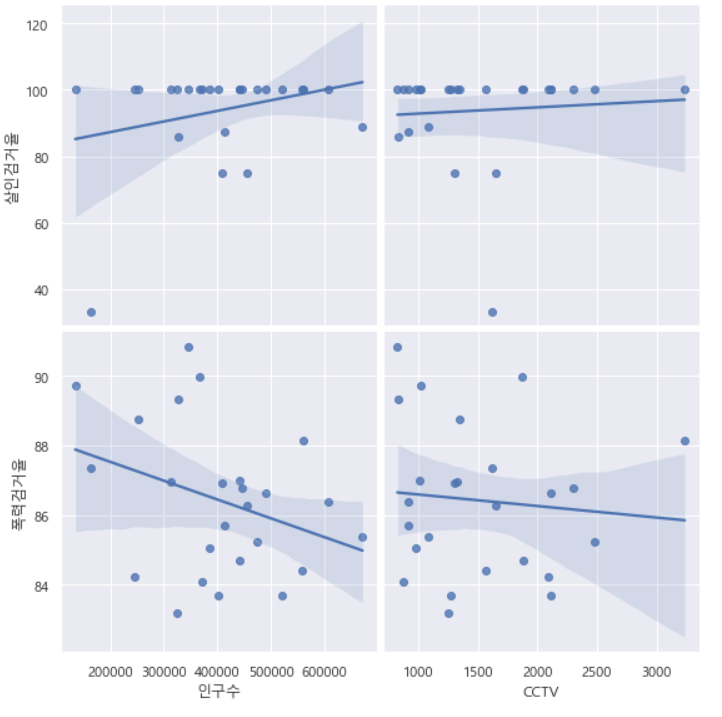
- (인구수, CCTV)와 (절도/강도 검거율)
- 큰 관계가 있다고 보기 어렵다
sns.pairplot(
crime_anal_norm,
x_vars=["인구수","CCTV"],
y_vars=["절도검거율", "강도검거율"],
kind="reg",
height=4)
plt.show()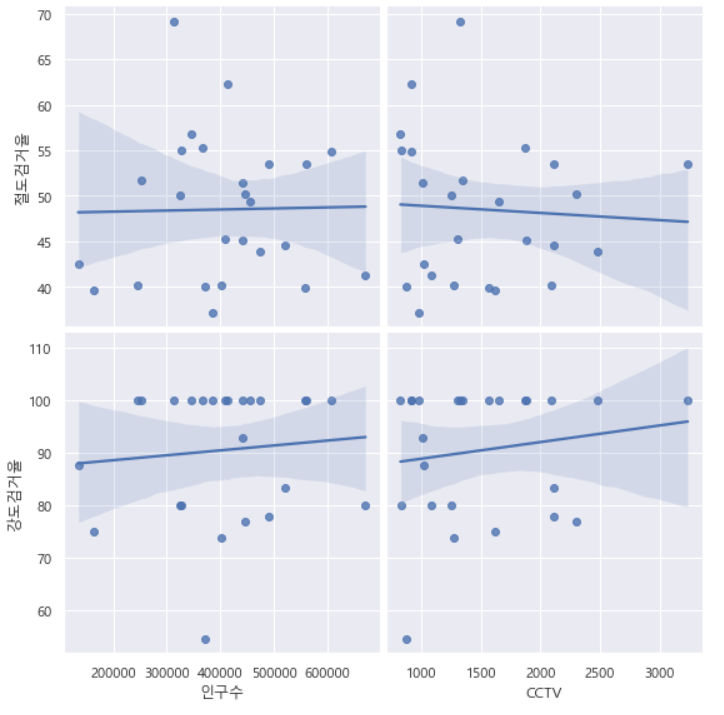
2. heatmap
- 전체 검거율의 대표값인 검거를 기준으로 시각화
target_col = ["강간검거율", "강도검거율", "살인검거율", "절도검거율", "폭력검거율", "검거"]
crime_anal_norm_sort = crime_anal_norm.sort_values(by="검거", ascending=False)
plt.figure(figsize=(10,10))
sns.heatmap(
crime_anal_norm_sort[target_col],
annot=True,
fmt="f",
# 간격설정
lineWidths=0.5,
cmap="RdPu",
)
plt.title("범죄 검거 비율 (정규화된 검거의 값으로 정렬)")
plt.show()
- 전체 범죄 발생의 대표값인 범죄를 기준으로 시각화
target_col = ["강간", "강도", "살인", "절도", "폭력", "범죄"]
crime_anal_norm_sort = crime_anal_norm.sort_values(by="범죄", ascending=False)
plt.figure(figsize=(10,10))
sns.heatmap(
crime_anal_norm_sort[target_col],
annot=True,
fmt="f",
lineWidths=0.5,
cmap="RdPu",
)
plt.title("범죄 발생 비율 (정규화된 발생 건수로 정렬)")
plt.show()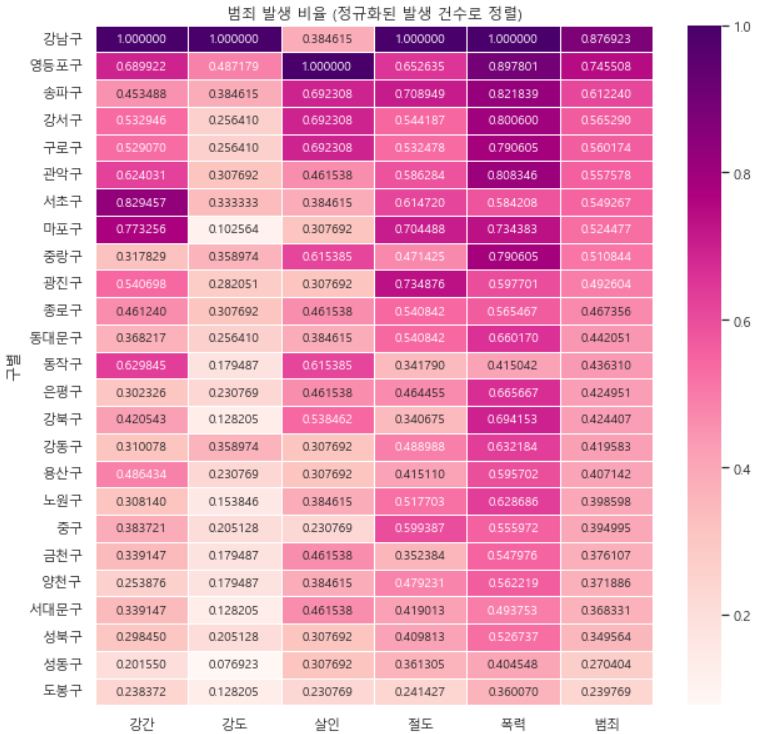
- 강남 3구의 범죄 발생 건수가 낮지 않고, 범죄 검거율 조차 높지 않다. 따라서 인구대비 현황 등을 고려할 필요가 있다.
◼서울시 범죄 현황 지도 시각화
Folium
folium: 지도 시각화 라이브러리- 크롬에서 가장 동작이 좋다
- 기본적인 명령
Map(location=[위도, 경도],Map(location=(위도, 경도)tiles: 스타일 설정(OpenStreetMap, Stamen Terrain/Toner/Watercolor, CartoDB positron, CartoDB dark_matter 등)zoom_start: 줌 설정(0~18)
save: 지도를 html 형식으로 저장Marker: 지도에 마커 추가popup,tooltip: 마커 클릭 또는 커서 이동 시 문구 출력(html 문법 사용 가능)icon: 다양한 모양의 아이콘 지원add_to: Map을 매개변수로 받아 해당 지도에 마커 추가
my_map = folium.Map(location=[45.372, -121.6972], tiles="Stamen Terrain")
folium.Marker([45.3288, -121.6625], popup="<i>Mt. Hood Meadows</i>").add_to(my_map)
folium.Marker(
[45.3311, -121.7113],
popup="<b>Timberline Lodge</b>",
tooltip="팀버라인 롯지").add_to(my_map)
my_map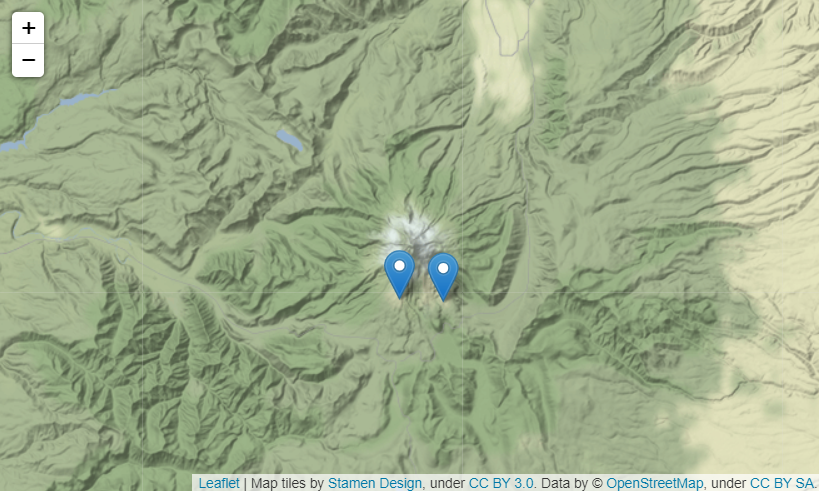
icon옵션- folium.Icon()으로 매개변수를 받는다.
icon: 아이콘 형태 결정icon_color: 아이콘 컬러 설정color: 마커 컬러 설정andgle: 기울기 설정prefix: 아이콘에 따라 'fa', 'glyphicon' 사용- fa : font-awesome
- glyphicon : glyphicon
m = folium.Map(location=[45.372, -121.6972], zoom_start=12, tiles="Stamen Terrain")
folium.Marker(
location = [45.3288, -121.6625],
popup = "Mt. Hood Meadows",
icon = folium.Icon(icon="cloud", icon_color="blue", color="red")).add_to(m)
folium.Marker(
[45.3311, -121.7113],
popup="Timberline Lodge",
icon = folium.Icon(color ="green")).add_to(m)
folium.Marker(
[45.3300, -121.6823],
popup="한글테스트",
icon = folium.Icon(icon="info_sign", color="red")).add_to(m)
folium.Marker(
[45.41, -121.700],
popup="TEST",
tooltip="TEST",
icon = folium.Icon(
icon="android",
color="purple",
icon_color="white",
angle=0,
prefix="fa")).add_to(m)
m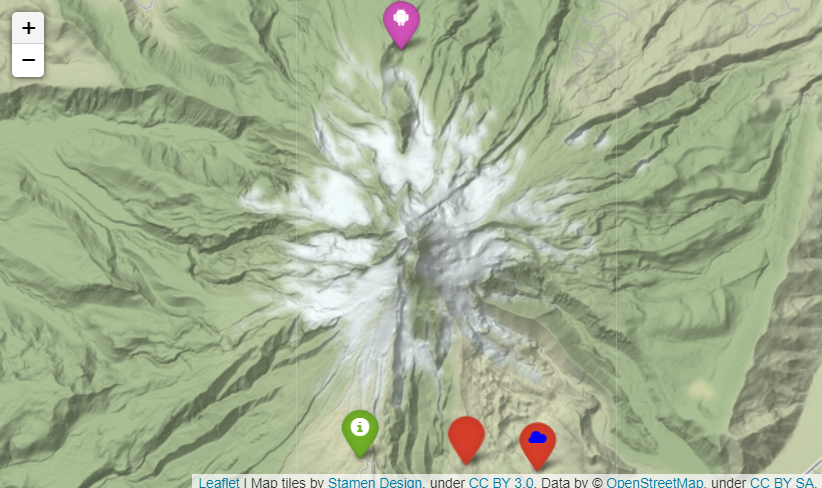
ClickForMarker: 지도위에 마우스로 클릭 시 마커 생성- 맵.add_child(folium.ClickForMarket()
popup: 마커 클릭 시 문구 출력
m = folium.Map(
location=[37.544564958079896, 127.05582307754338], # 상수역
zoom_start=14,
titles="OpenStreetMap"
)
# popup : 기본값 - 위도 경도 / 문구 출력
m.add_child(folium.ClickForMarker(popup="ClickForMarker"))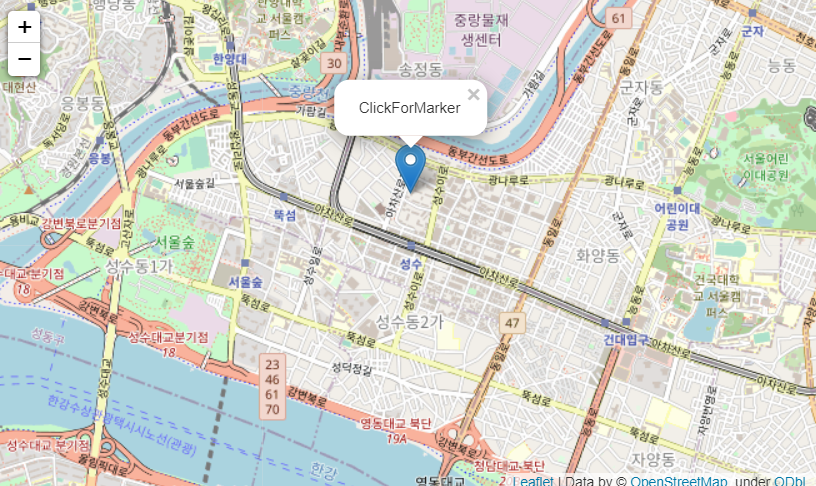
LatLngPopup(): 지도위에 마우스 클릭시 위도, 경도 문구 출력- 맵.add_child(folium.LatLngPopup()
m = folium.Map(
location=[37.544564958079896, 127.05582307754338], # 상수역
zoom_start=14,
titles="OpenStreetMap"
)
m.add_child(folium.LatLngPopup())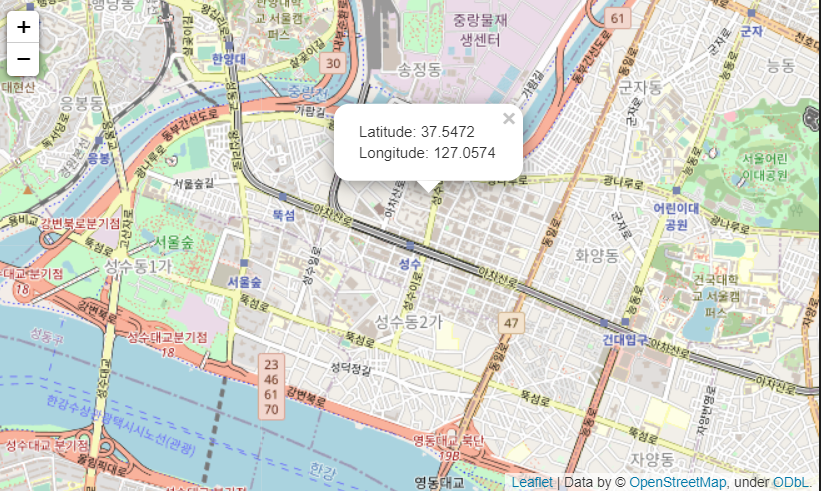
- Circle 마커
Circle,CircleMarker: 동일한 동작, 옵션이지만 radius만 다르게 적용된다.location,popup,tooltipMarker와 동일radius: 원의 반지름fill,fill_color: 원 내부 색상 설정
m = folium.Map(location=[45.5236, -122.6750], zoom_start=13, tiles="Stamen Toner")
folium.Circle(
radius=100,
location = [45.5244, -122.6699],
popup = "The Waterfront",
tooltip = "test",
color="crimson",
fill=True,
fill_color="blue").add_to(m)
folium.CircleMarker(
location=[45.5215, -122.6261],
radius = 50,
popup = "LAurelhurst Park",
color="#3186cc",
fill=True,
fill_color="#3186cc").add_to(m)
m
- json 파일 활용
folium.Choropleth(): 색상이나 패턴을 사용하여 특정 통계에 대한 데이터를 사전 정의된 영역과 관련시켜 시각화한 지도 유형geo_data: 지도 데이터 파일(json 등)data: Series or DataFrame 형태의 시각화 하고자 하는 데이터columns: [지도 데이터와 매핑할 값, 시각화하고자 하는 데이터]key_on: feature.데이터 파일과 매핑할 값fill_color: 시각화에 쓰일 색상fill_opacity: 투명도line_opacity: 투명도legend_name: 컬러 범주명
지도 시각화
# 범죄율 데이터
crime_anal_norm = pd.read_csv(
"../data/02. crime_in_Seoul_final.csv",
index_col = 0,
encoding="utf-8"
)
# 지도 데이터
geo_path="../data/02. skorea_municipalities_geo_simple.json"
geo_str = json.load(open(geo_path, encoding="utf-8"))
# 검거율 데이터
# Circle로 표현하기 위해 위도, 경도가 필요하므로 crime_in_seoul_raw.csv사용
crime_anal_station = pd.read_csv(
"../data/02. crime_in_seoul_raw.csv",
index_col=0,
encoding="utf-8"
)
col = ["살인검거", "강도검거", "강간검거", "절도검거", "폭력검거"]
# 정규화
tmp = crime_anal_station[col] / crime_anal_station[col].max()
# numpy의 axis는 0이 열, 1이 행
crime_anal_station["검거"] = np.mean(tmp, axis = 1)- 구별 범죄 현황과 경찰서별 검거율 지도에 표현
my_map= folium.Map(location=[37.5502, 126.982], zoom_start=11)
# 범죄율 : 지도로 표현
folium.Choropleth(
geo_data = geo_str,
data = crime_anal_norm["범죄"],
columns=[crime_anal_norm.index, crime_anal_norm["범죄"]],
fill_color="PuRd",
key_on="feature.id",
fill_opacity=0.7,
line_opacity=0.2,
).add_to(my_map)
# 검거율 : Circle로 표현
for idx, rows in crime_anal_station.iterrows():
folium.CircleMarker(
[rows["lat"], rows["lng"]],
radius=rows["검거"] * 50,
popup=idx + " : "+"%.2f" % rows["검거"],
color="#3186cc",
fill=True,
fill_color="#3186cc").add_to(my_map)
my_map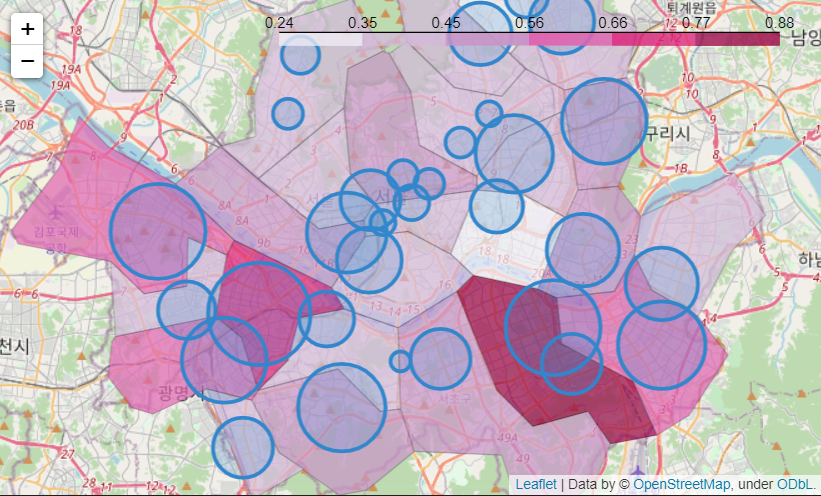
◼완성
- pivot_table을 활용한 데이터 정리
- google Maps API를 활용한 경찰서별 데이터 구별로 정리
- seaborn을 활용한 시각화
- folium을 활용한 지도 시각화

후라이드 치킨