가) 오늘 내 학습목표는 무엇이었나요?
- 3X2X3-class classifier multi model test
- 다양한 Data Augmentation 적용
- 5-fold cross-validation, ensemble test
- 제출 기회 10번 모두 사용하기
나) 오늘 나는 내 학습목표를 달성하기 위해 무엇을 어떻게 했나요?
- Mask, Gender, Age별로 모델을 각각 학습 후, 통합
- accuracy : 75.67%, f1 : 0.68%
- 18-class classifier single model
'train': transforms.Compose([
transforms.CenterCrop(256),
transforms.ColorJitter(brightness=(0.5, 1.5),
contrast=(0.5, 1.5),
saturation=(0.5, 1.5)),
transforms.RandomAffine(30),
transforms.RandomHorizontalFlip(p=0.5),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])- accuracy : 76.16%, f1 : 0.71%
- 데이터 전처리
- 오류 수정
- 004432_male_Asian_43
- 001498-1_male_Asian_23
- 006359_female_Asian_18
- 006360_female_Asian_18
- 006361_female_Asian_18
- 006362_female_Asian_18
- 006363_female_Asian_18
- 006364_female_Asian_18
- accuracy : -%, f1 : -%
- 실수...
- 18-class classifier single model
'train': transforms.Compose([
transforms.CenterCrop(384),
transforms.ColorJitter(brightness=(0.5, 1.5),
contrast=(0.5, 1.5),
saturation=(0.5, 1.5)),
transforms.RandomAffine(10),
transforms.RandomHorizontalFlip(p=0.5),
transforms.ToTensor(),
transforms.Normalize([0.56019358, 0.52410121, 0.501457], [0.23318603, 0.24300033, 0.24567522])
])- accuracy : -%, f1 : -%
- 실수...
- lr=0.001 -> lr=0.0001, epoch=7 -> epoch=20
- accuracy : 77.02%, f1 : 0.69%
- 데이터 전처리
- 오류 수정
- 004432_male_Asian_43
- 001498-1_male_Asian_23
- 006359_female_Asian_18
- 006360_female_Asian_18
- 006361_female_Asian_18
- 006362_female_Asian_18
- 006363_female_Asian_18
- 006364_female_Asian_18
- accuracy : 77.44%, f1 : 0.70%
- 5-fold cross-validation, ensemble
- accuracy : 78.40%, f1 : 0.72%
- 3-fold cross-validation, ensemble
- accuracy : 78.92%, f1 : 0.72%
- 5-fold cross-validation, ensemble
- accuracy : 78.81%, f1 : 0.72%
다) 오늘 나는 어떤 방식으로 모델을 개선했나요?
- 5-fold cross-validation, ensemble을 사용
라) 오늘 내가 한 행동의 결과로 어떤 지점을 달성하고, 어떠한 깨달음을 얻었나요?
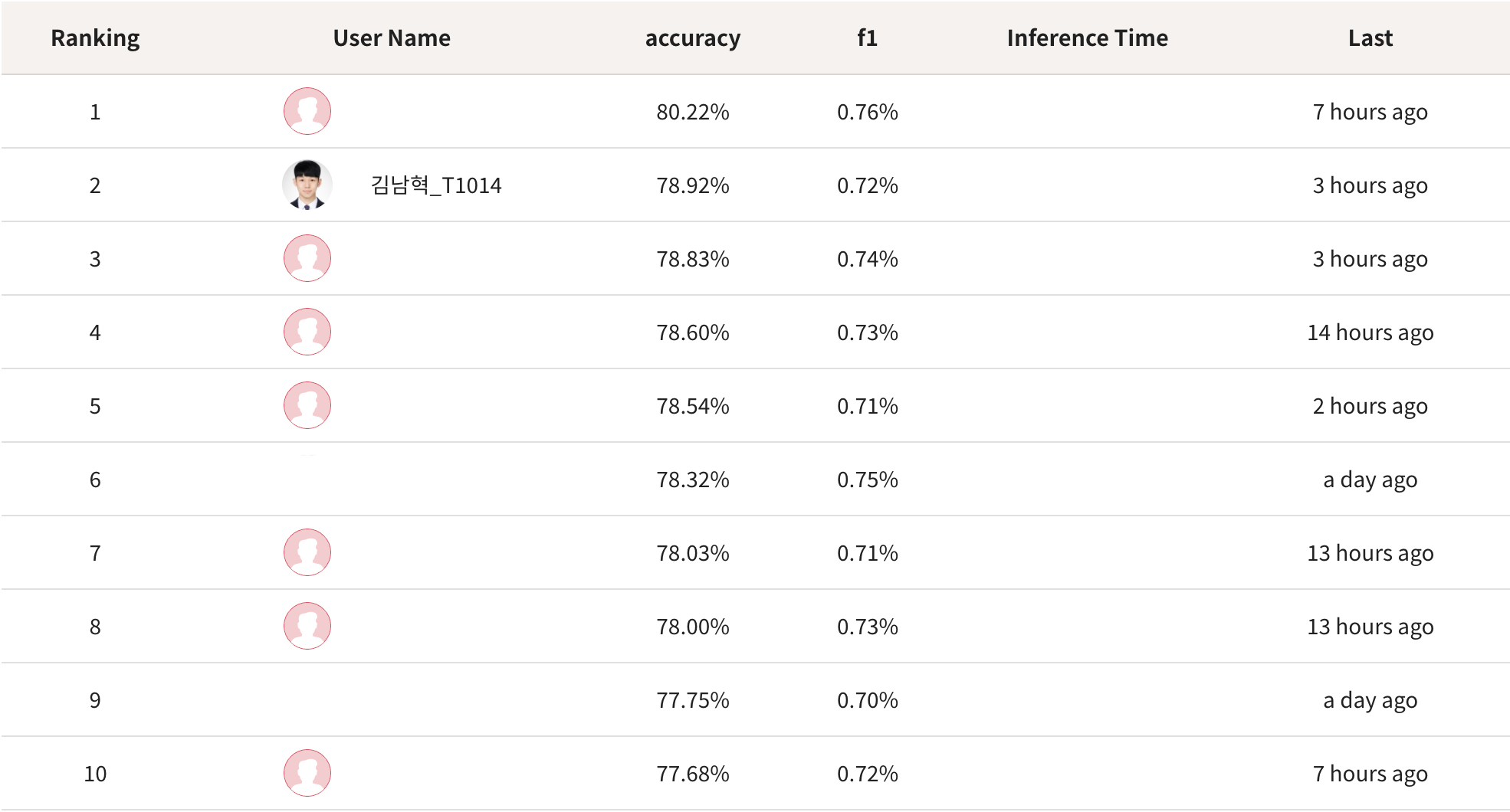
- Mask, Gender, Age 별로 모델을 각각 학습 후, 통합하는 것보다는 18-class classifier single model이 더 나은 것 같다.
- 다양한 Data Augmentation을 적용하는 것 보다, CenterCrop() 하나만 사용하는 것이 더 좋은 결과를 보여줬다.
- 256 size보다는 384(max) size가 더 좋은 결과를 보여줬다.
- 데이터 오류 수정 전이 더 좋은 결과를 보여줬다.
- lr=0.001 > lr=0.0001이고 epoch < 10 이하일 때, 더 좋은 결과를 보여줬다.
- 5-fold cross-validation, ensemble을 사용하면 안정적이다.
마) 오늘 나의 학습과 시도가 크게 성공적이지 않아서 아쉬운 것은 무엇인가요? 내일은 어떻게 다르게 시도해보실 수 있을까요?
- 3X2X3-class classifier multi model test, 다양한 Data Augmentation 적용이 생각보다 성공적이지 않아서 아쉬웠습니다.
- 내일은 사람을 기준으로 train과 test 데이터로 나눈 뒤, 시도해볼 계획입니다.
마무리
오늘보다 더 성장한 내일의 저를 기대하며, 내일 뵙도록 하겠습니다.
읽어주셔서 감사합니다!

PLUS ULTRA